
[Từ Transformer Đến Language Model] Tổng quan về Large Language Model (phần 2)
Bài đăng này đã không được cập nhật trong 2 năm
ADAPTATION TUNING OF LLMS
Sau quá trình pretraining, tiếp đến ta sẽ cần finetune mô hình với downstream task nếu muốn mô hình hoạt động tốt với các tác vụ thực tế. Ở thời điểm hiện tại có 2 hướng finetuning chính cho LLM là : instruction tuning và alignment tuning. Cách tiếp cận đầu tiên chủ yếu nhằm mục đích nâng cao (hoặc mở khóa) khả năng của LLM, trong khi cách tiếp cận sau nhằm mục đích điều chỉnh hành vi của LLM cho phù hợp với các giá trị hoặc mong muốn của con người.
Instruction Tuning
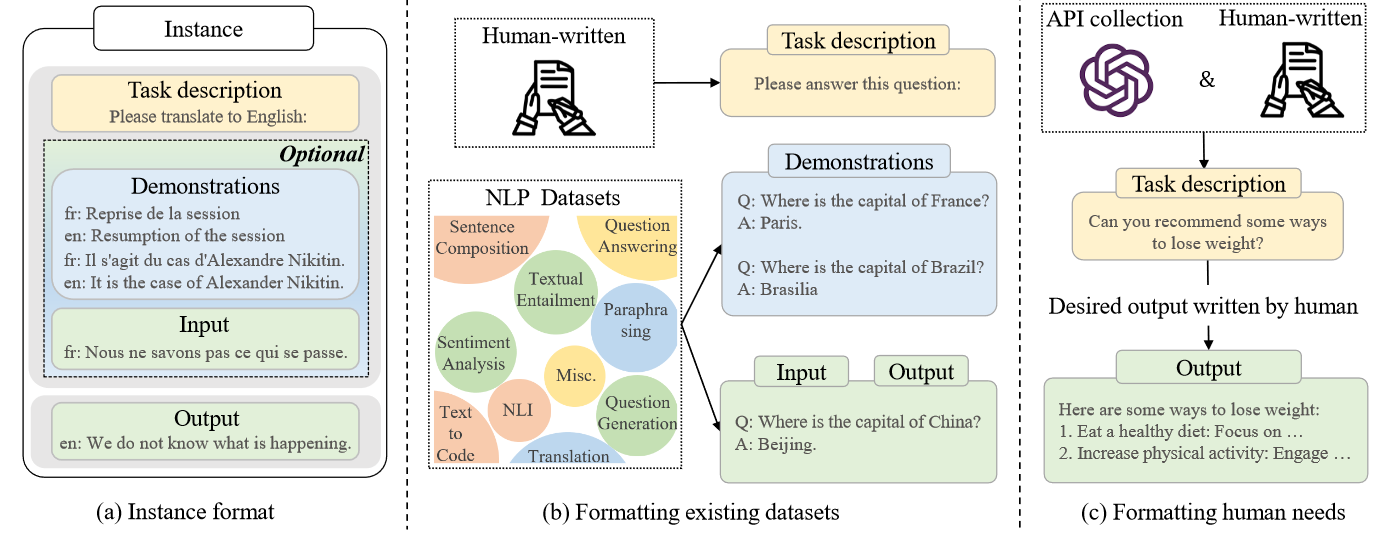 Về cơ bản thì instruction tuning khá tương đồng với supervised finetuning với dữ liệu dạng text và đây cũng là kiểu finetuning phổ biến nhất tại thời điểm hiện tại bởi nó khá dễ dàng thực hiện với sự hỗ trợ của thư viện transformers. Tuy nhiên cấu trúc dữ liệu của instruction tuning có một chút đặt biệt cần lưu ý, một mẫu dữ liệu của instruction tuning sẽ có 3 trường: instruction (task description), input, output. Instruction là mô tả về tác vụ mà chúng ta muốn LLM thực hiện, input là đầu vào của tác vụ, output là đầu ra mong muốn (có thể có thêm 1 trường nữa là demonstration để đưa ví dụ về tác vụ giúp LLM thực hiện dễ hơn) ví dụ:
Về cơ bản thì instruction tuning khá tương đồng với supervised finetuning với dữ liệu dạng text và đây cũng là kiểu finetuning phổ biến nhất tại thời điểm hiện tại bởi nó khá dễ dàng thực hiện với sự hỗ trợ của thư viện transformers. Tuy nhiên cấu trúc dữ liệu của instruction tuning có một chút đặt biệt cần lưu ý, một mẫu dữ liệu của instruction tuning sẽ có 3 trường: instruction (task description), input, output. Instruction là mô tả về tác vụ mà chúng ta muốn LLM thực hiện, input là đầu vào của tác vụ, output là đầu ra mong muốn (có thể có thêm 1 trường nữa là demonstration để đưa ví dụ về tác vụ giúp LLM thực hiện dễ hơn) ví dụ:
{
"Instruction": "Hãy dịch câu sau sang tiếng anh",
"Input": "hôm nay là một ngày đẹp trời",
"Output": "Today is a beautiful day"
}
Sự khác biệt giữa instruction tuning và finetuning thông thường nằm ở chữ instruction, trường dữ liệu instruction này giúp model hiểu được mong muốn của con người và kết nối được mong muốn này với tri thức của nó từ đó giúp nó hiểu và thực hiện tốt tác vụ, đồng thời có khả năng khái quát hóa tốt hơn với các tác vụ tương tự. Còn đối với finetune thông thường thì trường instruction sẽ không tồn tại, chỉ có input - output, ví dụ như input: "hôm nay là một ngày đẹp trời" - output: "Today is a beautiful day". Nếu như so sánh thì instruction tuning sẽ giống như dạy model cách tư duy còn finetuning thông thường dạy model cách học vẹt vậy.
Có 3 lợi ích khi chúng ta finetune pretrained LLM với instruction following task:
- Việc finetune theo tác vụ instruction following sẽ giúp LLM có khả năng hiểu và truyền đạt thông tin theo mong muốn của con người, từ đó thu hẹp khoảng cách giữa LLM và con người.
- Instruction tuning cho phép con người kiểm soát và dự đoán hành vi của LLM tốt hơn so với pretrained LLM
- Instruction tuning không tốn quá nhiều tài nguyên tính toán mà vẫn có thể giúp LLM thích ứng với lượng kiến thức mới mà không cần training lại.
Bên cạnh tính hiệu quả của nó thì instruction tuning vẫn gặp một số thách thức như:
- Để tạo ra một bộ dataset dạng instruction là không dễ vì phải đáp ứng một số tiêu chí như số lượng, tính đa dạng, tính sáng tạo
- Một số nghiên cứu chỉ ra rằng instruction tuning chỉ giúp model học được vẻ bề ngoài tức là giọng điệu, lối hành văn chứ không thực sự hiểu được nội dung của dữ liệu
Instruction Dataset Construction
Nhìn chung có 2 phương pháp chính để xây dựng tập dữ liệu instruction:
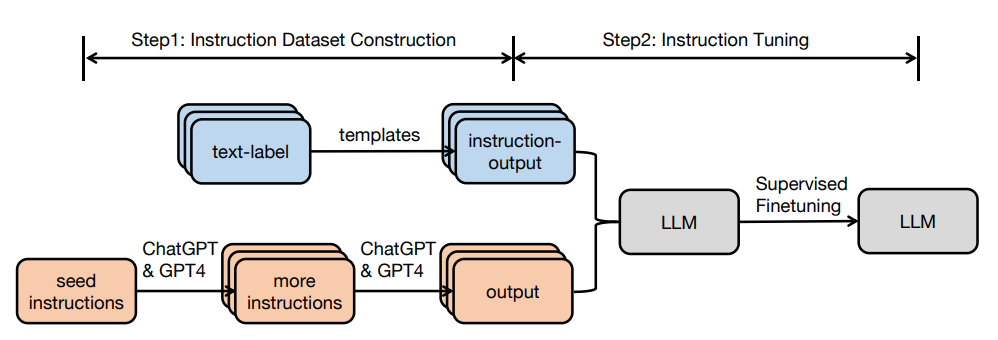
- Tận dụng các tập dataset NLP hiện tại và biến đổi sang dataset dạng instruction. Với cách này dữ liệu sẽ không có trường Input mà chỉ có cặp instruction-output, cặp này được tạo bằng cách biến đổi cặp text-label theo một template cố định.
- Tạo dữ liệu thông qua LLM: đây là một cách khá nhanh và hiệu quả khi có thể sử dụng các mô hình có sẵn như GPT-4 để tạo dữ liệu thay vì tự con người phải thực hiện điều đấy. Việc chúng ta cần làm là tinh chỉnh prompt cho phù hợp để có thể tạo ra tập dữ liệu đa dạng nhất, để model có thể hiểu rõ hơn về tác vụ thì chúng ta có thể thêm một vài mẫu ví dụ để model thực hiện tốt hơn. Dưới đây là một prompt được lấy từ repo standford_alpaca:
You are asked to come up with a set of 20 diverse task instructions. These task instructions will be given to a GPT model and we will evaluate the GPT model for completing the instructions.
Here are the requirements:
1. Try not to repeat the verb for each instruction to maximize diversity.
2. The language used for the instruction also should be diverse. For example, you should combine questions with imperative instrucitons.
3. The type of instructions should be diverse. The list should include diverse types of tasks like open-ended generation, classification, editing, etc.
2. A GPT language model should be able to complete the instruction. For example, do not ask the assistant to create any visual or audio output. For another example, do not ask the assistant to wake you up at 5pm or set a reminder because it cannot perform any action.
3. The instructions should be in English.
4. The instructions should be 1 to 2 sentences long. Either an imperative sentence or a question is permitted.
5. You should generate an appropriate input to the instruction. The input field should contain a specific example provided for the instruction. It should involve realistic data and should not contain simple placeholders. The input should provide substantial content to make the instruction challenging but should ideally not exceed 100 words.
6. Not all instructions require input. For example, when a instruction asks about some general information, "what is the highest peak in the world", it is not necssary to provide a specific context. In this case, we simply put "<noinput>" in the input field.
7. The output should be an appropriate response to the instruction and the input. Make sure the output is less than 100 words.
List of 20 tasks:
Dataset dùng cho instruction tuning được chia làm 3 loại chính dựa trên mục tiêu mà con người muốn LLM hướng tới:
- Thứ nhất, dataset mang lại cho LLM khả năng hoạt động tốt với các unseen task.
- Thứ hai, dataset mang lại cho LLM khả năng follow instruction.
- Thứ ba, dataset mang lại cho LLM khả năng nói chuyện như một trợ lý ảo, có thể tham gia các hội thoại dài với con người.
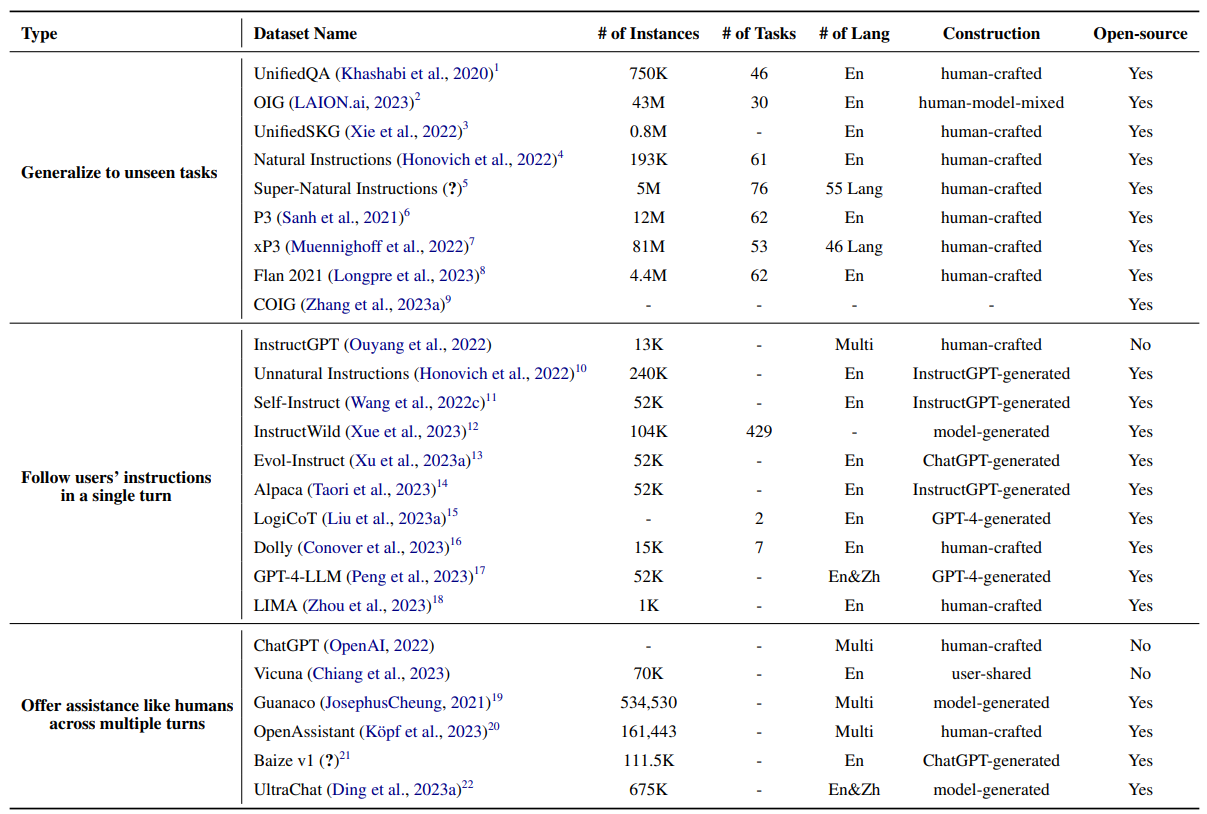
Dưới đây là bảng tổng hợp một số instruction dataset phổ biến hiện nay:
Instruction Tuning Strategies
Đến thời điểm hiện tại instruction tuning không chỉ gói gọn trong lĩnh vực text nữa mà nó còn bao quát cả image, video, audio để biến LLM thành multi-modality. Trong quá trình tuning, ngoài việc quan tâm đến những chi tiết nhỏ như batch size, learning rate,... thì có 2 khía cạnh khá quan trọng cần cân nhắc là:
Cân bằng phân phối tập dữ liệu: Bởi vì dataset instruction tuning bao gồm sự kết hợp của nhiều tác vụ khác nhau, vậy nên phải đảm bảo cân bằng tỷ lệ các tác vụ trong quá trình xây dựng dataset. Phương pháp thường được sử dụng để xử lý vấn đề này là examples-proportional mixing, kết hợp tất cả các tập dữ liệu và lấy mẫu từng trường hợp bằng nhau từ các tập dữ liệu hỗn hợp.
Kết hợp dữ liệu instruction tuning và pretraining: Để làm cho quá trình tuning hiệu quả và ổn định hơn, người ta có thể sẽ kết hợp cả pretraining data vào dữ liệu instruction finetune và coi đây như là regularization cho model.
Effect of Instruction Tuning
Ở phần này ta sẽ bàn đến ảnh hưởng của instruction tuning đến model ở 2 khía cạnh: performance và generalization.
Performance Improvement: Nếu như bạn để ý hoặc hay ra vào trang chủ huggingface thì bạn sẽ nhận thấy 1 điều rằng cứ 3-5 ngày sẽ có một model mới phá đảo các thể loại benchmark với một tập instruction tuning mới :v Điều này đã một phần thể hiện tính hiệu quả của instruction tuning đối với LLM. Nhiều nghiên cứu đã chỉ ra rằng language models ở tất cả các kích thước (77M -> 540B) đều có thể cải thiện hiệu năng với instruction tuning. Hơn thế nữa, model nhỏ được instruction tuning hoàn toàn có thể outperform model lớn không được finetune. Bên cạnh kích thước mô hình, instruction tuning còn cho thấy sự hiệu quả nhất quán đối với đa dạng các loại model architecture, pretraining objectives và model adaptations.
Task Generalization: Instruction tuning khuyến khích mô hình hiểu các hướng dẫn bằng ngôn ngữ tự nhiên và tri thức vốn có để hoàn thành nhiệm vụ. Nó mang lại cho LLM khả năng (emergent abilities) hiểu được hướng dẫn của con người để thực hiện các nhiệm vụ cụ thể mà không cần miêu tả cụ thể, ngay cả đối với các tác vụ chưa từng gặp. Bên cạnh đó, instruction tuning còn được chứng minh rằng có tác dụng giảm bớt một số nhược điểm của LLM như: lặp từ liên tục, tạo output ngẫu nhiên không liên quan đầu vào. Ngoài ra các mô hình huấn luyện với instruction tuning còn có khả năng hoạt động tốt với các tác vụ đa ngôn ngữ. Ví dụ như mô hình BLOOMZ-P3 được finetune trên model gốc là BLOOM với tập dataset P3 thuần tiếng anh, thế nhưng vẫn có thể đạt được sự cải thiện hơn 50% điểm số trong các tác vụ đa ngôn ngữ so với BLOOM.
Alignment Tuning
LLM đã thể hiện khả năng vượt trội trong nhiều tác vụ NLP sau khi được instruction tuning. Tuy nhiên, những mô hình này đôi khi có thể thể hiện những hành vi ngoài ý muốn, ví dụ: bịa đặt thông tin sai lệch, theo đuổi các mục tiêu không chính xác và làm ra những biểu hiện có hại, gây hiểu lầm hoặc mang tính thiên vị. Vì vậy để biến LLM thành trợ lý đáng tin cậy, người ta đề xuất có thêm 1 bước tinh chỉnh để "uốn nắn" hành vi model sao cho phù hợp với giá trị cốt lõi của con người. Không giống như pretraining hay instruction finetuning, bước tinh chỉnh này đòi hỏi phải xem xét nhiều tiêu chí khác nhau như tính hữu ích, tính trung thực, tính vô hại,... Để hiện thực hóa mục tiêu này thì các nhà nghiên cứu đã cho ra đời Alignment Tuning, phương pháp này gồm 2 bước tuần tự: instruction learning thông qua supervised fine-tuning (SFT) (chính là instruction tuning) và preference learning - reinforcement learning with human feedback (RLHF).
Cách mà giáo viên dạy học sinh thường thấy gồm 2 bước: dạy kiến thức, làm bài kiểm tra và đánh giá. Bước đầu tiên: dạy kiến thức, đây chính là bước tích lũy kiến thức cơ bản cho học sinh vậy nên nó tương đương với quá trình pretraining model. Bước thứ 2: làm bài kiểm tra và đánh giá, điểm đặc biệt cần chú ý ở đây là sau khi học sinh làm bài kiểm tra thì sẽ được giáo viên đánh giá điểm số sau đó đưa ra feedback hoặc chữa bài để học sinh tiếp thu và cải thiện điểm số ở những lần kiểm tra tiếp theo, với pipeline finetuning thông thường thì vẫn đang ở bước thứ nhất. Để tiến sang bước thứ 2 thì ta sẽ cần đến human feedback nhằm đánh giá output của model và để model cải thiện bản thân dựa trên feedback đó. Human feedback yêu cầu phải đến từ những người có trình độ học vấn cao, làm việc theo tiêu chí đánh giá rõ ràng và phải trải qua nhiều quy trình sàng lọc nghiêm ngặt để đảm bảo tập dữ liệu có chất lượng tốt. Tiếp theo đây ta sẽ tìm hiểu xem RLHF được thực hiện như thế nào nhé.
Reinforcement Learning from Human Feedback
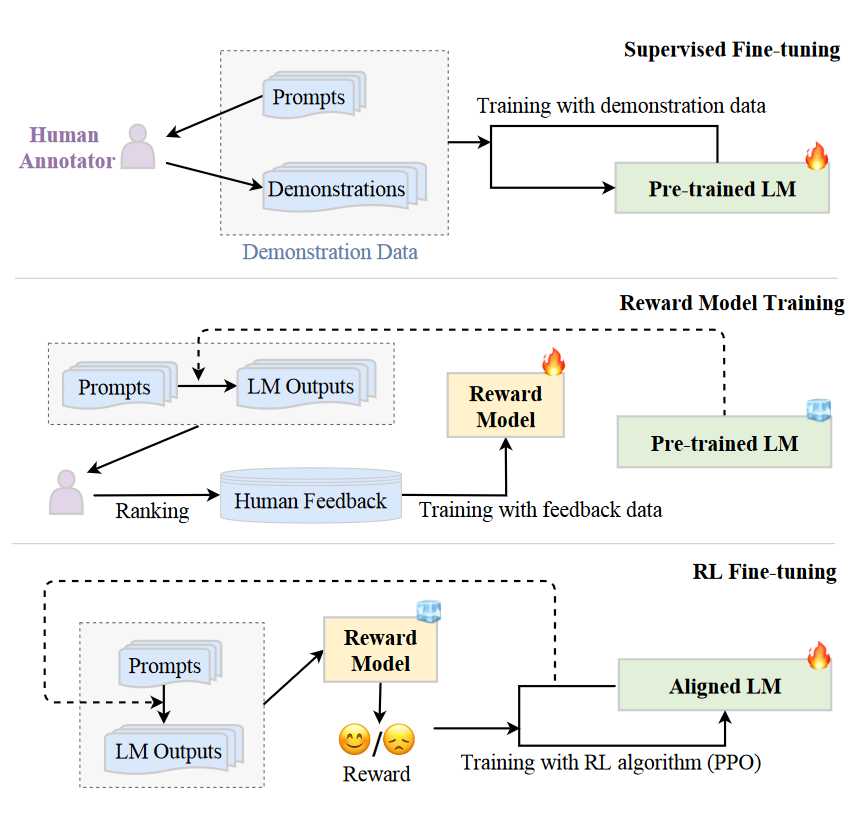 RLHF system có 3 phần chính: một pretrained LLM, một reward model được học human feedback từ trước và thuật toán RL để huấn luyện pretrained LLM. Pretrained LLM thì có lẽ không cần giới thiệu nhiều, nó đơn giản chỉ là model chính trong hệ thống, đã được pretrain với dữ liệu text khổng lồ. Reward model đóng vai trò thay thế con người để đưa ra hướng dẫn cho model chính, đầu ra của model này chỉ đơn giản là một số vô hướng. Cuối cùng để tối ưu hóa pretrained LLM với signal từ reward model, người ta sẽ sử dụng một thuật toán RL đặc biệt được thiết kế cho việc tuning các model lớn, thuật toán này thường được biết đến với tên gọi Proximal Policy Optimization (PPO).
RLHF system có 3 phần chính: một pretrained LLM, một reward model được học human feedback từ trước và thuật toán RL để huấn luyện pretrained LLM. Pretrained LLM thì có lẽ không cần giới thiệu nhiều, nó đơn giản chỉ là model chính trong hệ thống, đã được pretrain với dữ liệu text khổng lồ. Reward model đóng vai trò thay thế con người để đưa ra hướng dẫn cho model chính, đầu ra của model này chỉ đơn giản là một số vô hướng. Cuối cùng để tối ưu hóa pretrained LLM với signal từ reward model, người ta sẽ sử dụng một thuật toán RL đặc biệt được thiết kế cho việc tuning các model lớn, thuật toán này thường được biết đến với tên gọi Proximal Policy Optimization (PPO).
Cách thực hiện RLHF được chia thành 3 bước như hình trên:
B1: Supervised fine-tuning: Đầu tiên ta cần huấn luyện để pretrained LLM hiểu được mệnh lệnh của con người và cho đầu ra tương ứng giống như giáo viên dạy học sinh cách sử dụng kiến thức đã học để hoàn thành 1 bài kiểm tra sao cho đúng format vậy. Đây chính là bước instruction tuning như đã nói ở phần trước.
B2: Reward model finetuning: bước thứ 2 là huấn luyện reward model với human feedback data. Dữ liệu để training reward model được tạo ra bằng cách inference prompt có sẵn với 2 LLM để có 2 response khác nhau, sau đó human labeler sẽ phân loại output này là tốt hay không tốt dựa trên nhiều tiêu chí cho sẵn. Như vậy dữ liệu training reward model sẽ có dạng (prompt, winning_response, losing_response). Sau khi training thì reward model sẽ có khả năng thay thế con người để đánh giá generated text của LLM khác dựa trên prompt đầu vào. Quá trình finetune reward model có biểu diễn toán học như sau:
- : reward model được mô hình hóa bởi bộ tham số .
- Training data format:
- : prompt
- : winning response
- : losing response
- Với mỗi training sample :
- : score của reward model cho winning response
- : score của reward model cho losing response
- Loss: . Hàm loss này sẽ đảm bảo cho chúng ta 1 điều là winning response sẽ luôn có score cao hơn losing response
B3: RL fine-tuning: Ở bước cuối cùng này pretrained LM sẽ đóng vai trò là policy nhận đầu vào là prompt và cho đầu ra là text, không gian hoạt động chính là toàn bộ token trong bộ từ vựng của model và không gian quan sát là phân phối các chuỗi token đầu vào có thể có, state được mã hóa từ chuỗi token đầu ra và reward sẽ được tạo bởi reward model. Quá trình fine-tune RL model được mô hình hóa như sau:
- : reward model được train ở bước 2
- : model được supervised finetune ở bước 1
- : model SFT sau khi được finetune với thuật toán RL
- : prompt
- : tập dataset chứa prompt cho để finetune với RL
- : tập dataset pretrain
Với mỗi , ta sẽ sử dụng để sample ra một response: . Hàm objective thứ nhất sẽ được tính như sau:
Thành phần trong hàm objective trên chính là hàm KL divergence, mục đích là nhằm đảm bảo rằng mô hình RL không lệch quá xa mô hình SFT.
Với mỗi , ta cũng sẽ dùng để sample ra một response: . Hàm objective thứ hai được tính như sau:
Hàm objective này được thêm vào để đảm bảo rằng RL model không bị mất khả năng thực hiện tác vụ text completion đã được học ở giai đoạn pretrain.
Hàm objective cuối cùng sẽ là tổng của 2 hàm trên. Với RL, ta sẽ đi maximize chứ không phải minimize hàm objective như các bài toán khác.
Lời kết
Qua bài viết này, mình đã chia sẻ đến các bạn các phương pháp adaption tuning với LLM, trong quá trình đọc có thấy sai sót mong mọi người tích cực góp ý để mình cải thiện hơn ở các bài viết sau. Nếu thấy bài hữu ích có thể tặng mình một Upvote để mình có thêm động lực chuẩn bị cho một số bài viết khác sắp tới. Cảm ơn mọi người đã ủng hộ.
References
All rights reserved
