
Triton Inference Server Tutorial
Overview
Trong bài viết lần trước, mình đã trình bày về tổng quan lý thuyết về Triton Inference Server bao gồm kiến trúc của Triton, các tính năng chính, thông tin cơ bản và một số Triton Server Tool. Ta hãy cùng sơ lược lại một chút thông tin.
Triton Inference Server là gì ?
Triton Inference Server là một "open source inference serving software", cho phép deploy các AI model từ nhiều deep-machine learning frameworks, bao gồm TensorRT, TensorFlow, PyTorch, ONNX, OpenVINO, v.v. Triton hỗ trợ inference trên cloud, data center và thiết bị nhúng trên GPU NVIDIA, x86 và CPU ARM hoặc AWS Inferentia cũng như mang lại hiệu suất được tối ưu hóa cho nhiều loại truy vấn, bao gồm real-time, batched, ensembles và audio/video streaming. Ngoài ra, Triton còn có thể dễ dàng tích hợp với các công cụ khác như Kubernetes, Kserve, Prometheus hay Grafana. Tóm lại, đây là một nền tảng phần mềm giúp tăng tốc quy trình khoa học dữ liệu và tối đa hóa hiệu suất và hiệu quả của các ứng dụng AI.
Features
- Hỗ trợ nhiều Deep Learning Frameworks
- Dynamic Batching
- Concurrent model execution
- Cung cấp Backend API cho phép thêm Triton Custom Backends
- Ensembling models
- HTTP/REST và GRPC inference protocols
- Metrics: throughput, latency, ...
Triton Basics
- Model repository: Cấu trúc
- Model Configuration: Cấu hình và tùy chọn model
- Model management: Quản lý mô hình
Triton Tool
- Triton Performance Analyzer: CLI tool có thể giúp tối ưu hóa hiệu suất inference của các mô hình chạy trên Triton Inference Server bằng cách đo lường những thay đổi về hiệu suất khi thử nghiệm các chiến lược tối ưu hóa khác nhau
- Triton Model Analyzer: tool sử dụng Performance Analyzer để gửi yêu cầu đến mô hình trong khi đo bộ nhớ GPU và mức sử dụng điện toán. Nó tự động xác định các cấu hình mô hình tùy chọn trong Triton để tối đa hóa hiệu suất
Triton Tutorial
Ở trên là các thông tin cơ bản liên quan đến Triton Inference Server mà trong bài viết lần trước mình đã đề cập. Trong bài viết này, mình sẽ trình bày cách thức cơ bản nhất để có thể cài đặt và sử dụng Triton Inference Server.
Installation
Triton Inference Server có sẵn dưới dạng buildable open-source code, nhưng cách dễ nhất để cài đặt và chạy Triton là spre-built Docker image có trên NVIDIA GPU Cloud (NGC). Việc khởi chạy và duy trì Triton Inference Server xoay quanh việc sử dụng kho lưu trữ mô hình xây dựng. Tutorial này sẽ bao gồm:
- Tạo Model repository
- Lauching Triton
- Gửi Inference request
Tạo Model repository
Model repository là thư mục nơi bạn đặt các mô hình mà bạn muốn Triton phục vụ. Trong tutorial lần này, mình sẽ sử dụng 2 model được train từ thư viện Pytorch Lightning là resnet34 và Unet cho 2 tác vụ phân loại và segment cho bài toán xác định tàu thuyển từ ảnh chẳng hạn, nên lưu ý rằng các mô hình cần được convert thành dạng TorchScript nếu platform được sử dụng là Pytorch. Dưới đây là cấu trúc của folder model_repository và một ví dụ của file config.pbtxt cho model unet:
# model_repository structure
model_repository
├── ensemble_model
│ ├── 1
│ └── config.pbtxt
├── resnet34
│ ├── 1
│ │ └── model.pt
│ └── config.pbtxt
└── unet34
├── 1
│ └── model.pt
└── config.pbtxt
# config.pbtxt
name: "unet34"
platform: "pytorch_libtorch"
max_batch_size : 6
input [
{
name: "input_image_unet34"
data_type: TYPE_FP32
dims: [ 3, 768, 768 ]
}
]
output [
{
name: "SEGMENTATION_OUTPUT"
data_type: TYPE_FP32
dims: [ 1, 768, 768 ]
}
]
instance_group [
{
count: 2
kind: KIND_GPU
}
]
dynamic_batching {}
Trong Trong ví dụ trên mình sử dụng mô hình U-Net cho bài toán segmentation với đầu vào là 1 ảnh RGB có kích thước 768x768 với loại dữ liệu và FP32 và đầu ra sẽ là 1 mask có cùng kích thước với ảnh đầu vào.
Launching Triton
Triton được tối ưu hóa để cung cấp hiệu suất suy luận tốt nhất bằng cách sử dụng GPU, nhưng nó cũng có thể hoạt động trên các hệ thống chỉ có CPU. Cách sử dụng Triton dễ nhất là thông qua Docker. Hãy đảm bảo máy bạn đã cài đặt Triton Trong cả hai trường hợp, bạn có thể sử dụng cùng một Triton Docker image. Trong tutorial lần này, mình sẽ sử dụng Triton Inference Server phiên bản 22.12, bạn có thể sử dụng phiên bản mới hơn tùy mục đích.
Để chạy hệ thống với GPUs, sử dụng câu lệnh
docker run --gpus all --rm -p8000:8000 -p8001:8001 -p8002:8002 -v ${PWD}/model_repository:/models nvcr.io/nvidia/tritonserver:22.12-py3 tritonserver --model-repository=/models
Chạy trên hệ thống chỉ có CPU, sử dụng câu lệnh dưới đây, ta sẽ bỏ flag --gpus, còn lại các tham số thì y hệt ở trên (có thể thay thế <xx.yy> bằng version khác:
docker run --rm -p8000:8000 -p8001:8001 -p8002:8002 -v ${PWD}/model_repository:/models nvcr.io/nvidia/tritonserver:<xx.yy>-py3 tritonserver --model-repository=/models
Bởi vì flag --gpus không được sử dụng, GPU sẽ không khả dụng và Triton do đó sẽ không thể tải bất kỳ cấu hình model nào yêu cầu GPU.
Nếu như trên máy local không có docker images của triton server, trong lần đầu chạy câu lệnh, Tritonserver image sẽ tự động được pull về local.
Xác minh Triton đã chạy
Sử dụng Triton's ready endpoint để xác minh rằng máy chủ và các mô hình đã sẵn sàng cho inference. Từ host system, hãy sử dụng curl để truy cập HTTP endpoint cho biết trạng thái máy chủ. Nếu HTTP request trả về status 200 nghĩa là Triton đã sẵn sàng và non-200 nghĩa là chưa sẵn sàng.
$ curl -v localhost:8000/v2/health/ready
...
* Trying 127.0.0.1:8000...
* Connected to localhost (127.0.0.1) port 8000 (#0)
> GET /v2/health/ready HTTP/1.1
> Host: localhost:8000
> User-Agent: curl/7.81.0
> Accept: */*
>
* Mark bundle as not supporting multiuse
< HTTP/1.1 200 OK
< Content-Length: 0
< Content-Type: text/plain
<
* Connection #0 to host localhost left intact
Triton Logs
Sau khi sử dụng docker run để khởi tạo và chạy Triton server , ta có thể check logs của container để kiểm tra xem các model nào đã sẵn sàng cho việc inference cũng như check các protocol sevice port, các config của triton container. Hãy cùng điểm qua một số log quan trọng và cần thiết:
I1102 04:11:21.983121 1 server.cc:633]
+----------------+---------+--------+
| Model | Version | Status |
+----------------+---------+--------+
| ensemble_model | 1 | READY |
| resnet34 | 1 | READY |
| unet34 | 1 | READY |
+----------------+---------+--------+
Nếu model đã được load thành công và sẵn sàng cho inference, Triton container sẽ log ra như trên, ta có thể thấy các mô hình đã được đánh version và status READY. Nếu không phải READY, ta có thể check status để biết vấn đề hiện tại của model.
I1102 04:11:22.028262 1 grpc_server.cc:4819] Started GRPCInferenceService at 0.0.0.0:8001
I1102 04:11:22.028982 1 http_server.cc:3477] Started HTTPService at 0.0.0.0:8000
I1102 04:11:22.070508 1 http_server.cc:184] Started Metrics Service at 0.0.0.0:8002
W1102 04:11:23.023508 1 metrics.cc:603] Unable to get power limit for GPU 0. Status:Success, value:0.000000
Ngoài ra ta cũng có thể thấy được GRPCInferenceService được mở port 8001, Metrics Service port 8002 và HTTPService được mở port 8000 để truy cập cho inference request.
Gửi Inference Request
Vậy là ta đã đi qua bước khởi tạo là launching Triton Inference Server, bước tiếp theo sẽ là gửi inference request đến server đã được run ở trên.
Tutorial từ Triton Documentation
Để thử gửi inference request, bạn có thể follow step-by-step được cung cấp bởi Triton Documention. Sử dụng docker pull để lấy client libraries và examples images từ NGC. Trong đó, <xx.yy> là vervion của Triton được pull như mình đã đề cập ở trên.
$ docker pull nvcr.io/nvidia/tritonserver:<xx.yy>-py3-sdk
Để run client image:
$ docker run -it --rm --net=host nvcr.io/nvidia/tritonserver:<xx.yy>-py3-sdk
Từ bên trong image nvcr.io/nvidia/tritonserver:<xx.yy>-py3-sdk, hãy chạy image-client application để thực hiện phân loại hình ảnh bằng densenet_onnx model. Để gửi request tới densenet_onnx model sử dụng hình ảnh từ đường dẫn /workspace/images. trong trường hợp này, mình sẽ tìm top 3 lớp phân loại:
$ /workspace/install/bin/image_client -m densenet_onnx -c 3 -s INCEPTION /workspace/images/mug.jpg
Request 0, batch size 1
Image '/workspace/images/mug.jpg':
15.346230 (504) = COFFEE MUG
13.224326 (968) = CUP
10.422965 (505) = COFFEEPOT
Để gửi yêu cầu cho mô hình dennnet_onnx, hãy sử dụng hình ảnh từ thư mục /workspace/images. Trong trường hợp này, chúng tôi yêu cầu 3 phân loại hàng đầu. Phía trên là bản hướng dẫn cơ bản và dễ thao tác được Triton cung cấp, bạn có thể tìm đọc để có các bước chạy chi tiết hơn từ Documentation của họ.
Python Package Installer
Một cách khác để gửi inference request tới Triton Inference Server, ta có thể sử dụng Python code. Đảm bảo máy bạn có sẵn pip hoặc anaconda, tạo môi trường và cài đặt các thư viện cần thiết, bao gồm:
pip install tritonclient[all]
Trước tiên, hãy import các thư viện cần thiết, đặc biệt là tritonclient để bắt đầu cách mà ta có thể gửi inference request tới triton server:
import tritonclient.http as httpclient
import tritonclient.grpc as grpcclient
from tritonclient.utils import triton_to_np_dtype
import numpy as np
from torchvision import transforms
..........
Ở phần trên thì mình đã có file config.pbtxt ví dụ cho mô hình unet để phân đoạn xem vùng nào trong ảnh là thuyền. Dưới đây là ảnh minh họa cho tác vụ phân đoạn:
 Trước tiên, ta có thể tiền xử lý ảnh một chút trước khi gửi inference request tới mô hình (code có thể không clean mong mọi người đừng oán trách):
Trước tiên, ta có thể tiền xử lý ảnh một chút trước khi gửi inference request tới mô hình (code có thể không clean mong mọi người đừng oán trách):
def preprocess(image_path):
image= Image.open(image_path).convert("RGB")
image = np.array(image)
transform = Compose(
[
A.Resize(768, 768),
A.Normalize(mean=[0.485, 0.456, 0.406], std=[0.229, 0.224, 0.225]),
ToTensorV2(),
]
)
return transform(image=image)["image"].numpy()
Tiếp theo ta có thể gửi request tới triton server. Trong đó, ta có thể xác định batch_size cụ thể để có thể gửi nhiều ảnh trong 1 lần request. Tùy thuộc vào GPU mà batch_size tối đa có thể khác nhau.
client = grpcclient.InferenceServerClient(url="localhost:8001")
for i in range(0, len(image_files), batch_size):
if i + batch_size < len(image_files):
batch_images = np.array(list((preprocess(f"{folder_path}{image_files[j]}") for j in range(i, i + batch_size))))
else:
batch_images = np.array(list((preprocess(f"{folder_path}{image_files[j]}") for j in range(i, len(image_files)))))
# GRPC
inputs = grpcclient.InferInput("input_image_unet34", batch_images.shape, datatype="FP32")
inputs.set_data_from_numpy(batch_images)
outputs = grpcclient.InferRequestedOutput("SEGMENTATION_OUTPUT")
# Querying the server
results = client.infer(model_name="unet34", inputs=[inputs])
inference_output = results.as_numpy('SEGMENTATION_OUTPUT').squeeze()
Trong đoạn code mẫu trên, ta sẽ đọc ảnh từ folder và tiền xử lý chúng trước. Request sẽ được gửi thông qua giao thức grpcclient (hoặc có thể chỉnh sửa thành httpclient nếu muốn test). Trong đó, input_image_unet34 là tên đầu vào đã được xác định trong file cấu hình config.pbtxt ở phía trên và SEGMENTATION_OUTPUT là tên đầu ra, model_name là tên model được inference.
Sau khi nhận được kết quả trả về, mình sẽ visualize một chút cho dễ nhìn:

Ngoài ra, trong cấu trúc folder model_repository ở trên mình có đề cập, bạn có thể thấy mình cũng có chuẩn bị file config cho ensemble_model. Và đây là file ví dụ cho tác vụ phân loại xem ảnh có tàu không và phân đoạn vị trí của tàu:
name: "ensemble_model"
platform: "ensemble"
max_batch_size: 4
input [
{
name: "IMAGE"
data_type: TYPE_FP32
dims: [ 3, 768, 768 ]
}
]
output [
{
name: "CLASSIFICATION"
data_type: TYPE_FP32
dims: [ -1 ]
},
{
name: "SEGMENTATION"
data_type: TYPE_FP32
dims: [ 1, 768, 768 ]
}
]
ensemble_scheduling {
step [
{
model_name: "resnet34"
model_version: -1
input_map {
key: "input_image_resnet34"
value: "IMAGE"
}
output_map {
key: "CLASSIFICATION_OUTPUT"
value: "CLASSIFICATION"
}
},
{
model_name: "unet34"
model_version: -1
input_map {
key: "input_image_unet34"
value: "IMAGE"
}
output_map {
key: "SEGMENTATION_OUTPUT"
value: "SEGMENTATION"
}
}
]
}
Trong đó, ảnh đầu vào INPUT sẽ được gửi tới cả 2 model resnet34 và unet và giá trị đầu ra của chúng sẽ tương ứng với output.
Và đó cũng là kết thúc cho Inference Request Tutorial mà mình có chuẩn bị. Các bạn hoàn toàn có thể dựa trên các file mẫu để tùy chỉnh dựa theo model, tác vụ của mình hoặc nếu bài viết của mình chưa đủ, bạn có thể đọc sâu hơn trong Triton Documentation và Github của họ mà mình có để link ở cuối.
Triton Model Analyzer (Optional)
Trong bài viết lần trước, mình cũng có nói đến một Triton tool là Triton Model Analyzer nhỉ. Nhắc lại một chút, đây là tool sử dụng Performance Analyzer để gửi yêu cầu đến mô hình trong khi đo bộ nhớ GPU và mức sử dụng điện toán. Nó tự động xác định các cấu hình mô hình tùy chọn trong Triton để tối đa hóa hiệu suất. Nó thể giúp bạn tìm cấu hình tối ưu hơn, trên một phần cứng nhất định, cho các mô hình single, multiple, ensemble hoặc BLS chạy trên Triton Inference Server. Model Analyzer cũng sẽ tạo báo cáo để giúp bạn hiểu rõ hơn về sự cân bằng giữa các cấu hình khác nhau cùng với các yêu cầu về điện toán và bộ nhớ của chúng. Vậy thì ta cũng thử đi qua cách sử dụng Model Analyzer cơ bản. c
Do Docker không có sẵn triton_model_analyzer image nên ta phải tự build thôi. Trước tiên mọi người cần clone repository của model analyzer về trước:
git clone https://github.com/triton-inference-server/model_analyzer.git
cd model_analyzer/
Tiếp theo ta sẽ build image trên local:
docker build --pull -t model-analyzer .
Sau một thời gian chờ đợi, ta cần run image đó lên:
docker run -it --rm --gpus all -v $(pwd):/workspace --net=host model-analyzer
cd workspace/
Ở trong container, trước tiên ta sẽ cần tạo 1 configuration file cho biết model analyzer sẽ cấu hình và gửi output vào đâu. Mình sẽ tạo configuration file cơ bản để cho model đọc model_repository của mình. Ta sẽ tạo 1 file perf.yaml để cấu hình:
vi perf.yaml
model_repository: /workspace/model_repository
profile_models:
- unet34
Tiếp theo ta sẽ sử dụng câu lệnh tiếp theo để bắt đầu quá trình tìm các config và đo lường hiệu năng của chúng. Lưu ý rằng, tùy thuộc vào khả năng của GPU mà config cũng sẽ khác nhau, thời gian chạy quá trình analyzer cũng rất tốn thời gian. Tuy nhiên, các bạn có thể tham khảo thêm các cách Search khác của Model analyzer được đề cập trong Documentation.
model-analyzer profile --output-model-repository-path /workspace/output/ -f perf.yaml --override-output-model-repository
Trong đó, tham số --output-model-repository sẽ là nơi các config được lưu lại khi config đó được chạy xong trong quá trình analyzer. Dưới đây là đoạn logs minh họa cho mỗi config được chạy:
[Model Analyzer] Initiliazing GPUDevice handles
[Model Analyzer] Using GPU 0 NVIDIA GeForce RTX 3050 Ti Laptop GPU with UUID GPU-a4c58681-b808-f91d-0254-f4bc9d22e81a
[Model Analyzer] WARNING: Overriding the output model repo path "/workspace/output/"
[Model Analyzer] Starting a local Triton Server
[Model Analyzer] Loaded checkpoint from file /workspace/checkpoints/5.ckpt
[Model Analyzer] Profiling server only metrics...
[Model Analyzer]
[Model Analyzer] Creating model config: unet34_config_0
[Model Analyzer] Enabling dynamic_batching
[Model Analyzer] Setting instance_group to [{'count': 1, 'kind': 'KIND_GPU'}]
[Model Analyzer] Setting max_batch_size to 1
[Model Analyzer]
Sau quá trình chạy, điểm khá hay là model analyzer có khả năng export cho mình các thông số liên quan đến mức độ điện toán, latency,GPU power, ... Các bạn có thể kiểm tra trong folder results. Trong đó sẽ có 3 file csv được export như sau:
results
├── metrics-model-gpu.csv
├── metrics-model-inference.csv
└── metrics-server-only.csv
Hơn nữa, nếu các bạn muốn export thành các file PDF theo format dễ nhìn dễ đọc lại còn có thêm cả biểu đồ visualize và bảng nữa thì có thể sử dụng câu lệnh được recommend bởi Model Analyzer sau khi quá trình Analyze hoàn tất. Ví dụ:
model-analyzer report --report-model-configs unet34_config_5,unet34_config_default,unet34_config_6 --export-path /workspace --config-file perf.yaml
Khi đó, một folder mới reports xuất hiện tại Pwd (do đã mount từ khi chạy model analyzer container), cấu trúc của folder như sau:
reports/
├── detailed
│ ├── unet34_config_5
│ │ └── detailed_report.pdf
│ ├── unet34_config_6
│ │ └── detailed_report.pdf
│ └── unet34_config_default
│ └── detailed_report.pdf
└── summaries
└── unet34
└── result_summary.pdf
Trong đó, folder detailed sẽ bao gồm các thông số cụ thể và chi tiết của từng config (top 3 config cho kết quả tốt nhất) và folder summaries sẽ bao gồm so sánh và tổng hợp của các config đã được phân tích. Dưới đây là vài ví dụ minh họa của file PDF detailed:
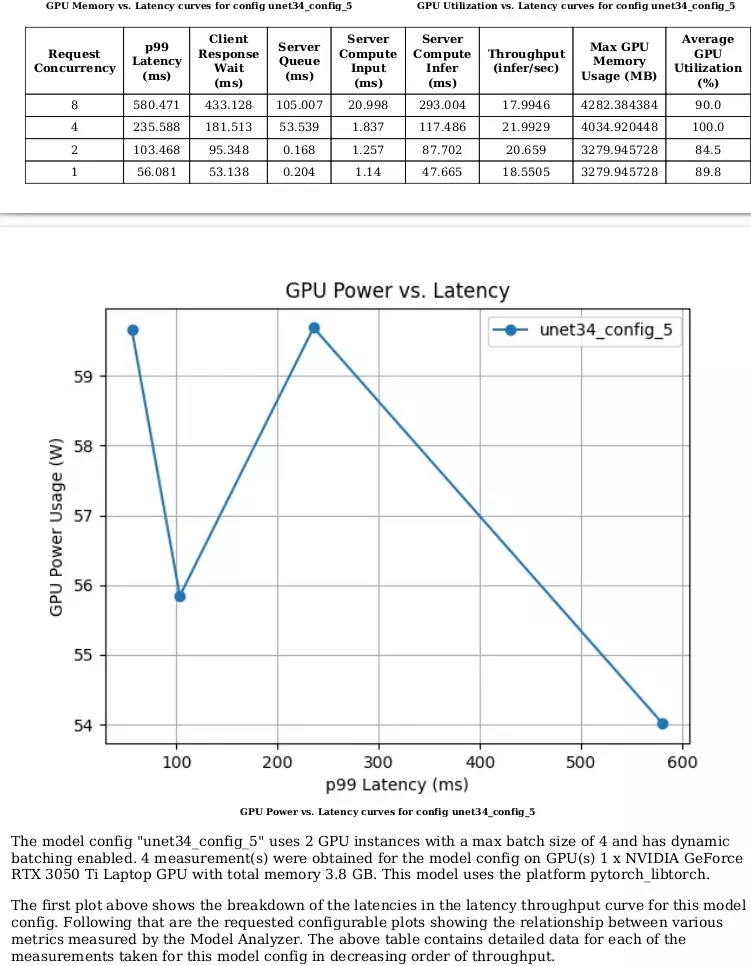
Và dưới đây là PDF summaries cho các config:
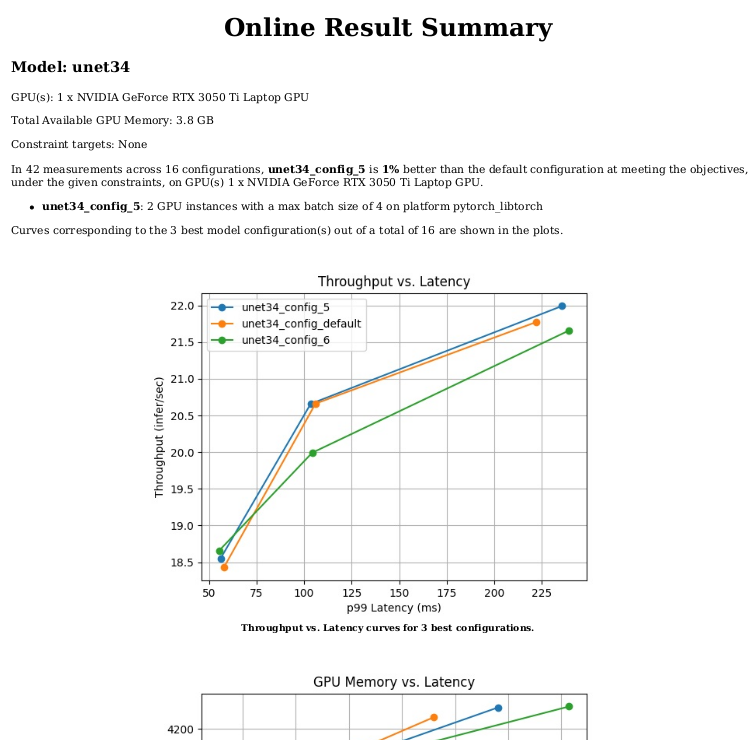
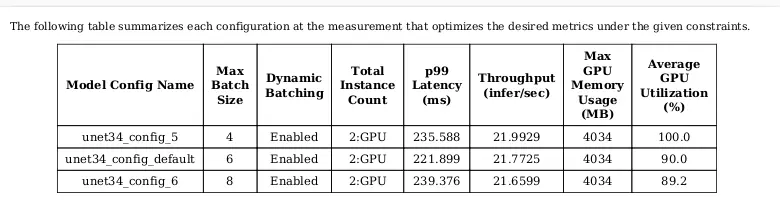
Nếu các bạn cần các ảnh biểu đồ phục vụ cho mục đích nào đó, Model Analyzer cũng phân tích và trả về các ảnh cho bạn trong folder plots.
plots/
├── detailed
│ ├── unet34_config_5
│ │ └── latency_breakdown.png
│ ├── unet34_config_6
│ │ └── latency_breakdown.png
│ └── unet34_config_default
│ └── latency_breakdown.png
└── simple
├── unet34
│ ├── gpu_mem_v_latency.png
│ └── throughput_v_latency.png
├── unet34_config_5
│ ├── cpu_mem_v_latency.png
│ ├── gpu_mem_v_latency.png
│ ├── gpu_power_v_latency.png
│ └── gpu_util_v_latency.png
├── unet34_config_6
│ ├── cpu_mem_v_latency.png
│ ├── gpu_mem_v_latency.png
│ ├── gpu_power_v_latency.png
│ └── gpu_util_v_latency.png
└── unet34_config_default
├── cpu_mem_v_latency.png
├── gpu_mem_v_latency.png
├── gpu_power_v_latency.png
└── gpu_util_v_latency.png
Ở trên, ta mới chạy qua các config mặc định, ta cũng có thể xác định thêm các ràng buộc khi phân tích cấu hình. Nếu ta muốn limit latency là 50 ms cho response. Điều thú vị của Model Analyzer là mình ko cần chạy lại toàn bộ parameters. Ta chỉ cần chạy lại cái analysis cuối cùng mà được sinh bởi các reported trên mà ta thấy.
Ta sẽ tạo 1 configuration file mới, xác định model cần analyze và xác định constraints với max latency:
# Analysis
vi analyze.yaml
analysis_models:
unet34:
constraints:
perf_latency_p99:
max: 50
model-analyzer analyze --config-file analyze.yaml
Lưu ý
Các version của Triton Inference Server image và Model Analyzer của mình có thể đã hơi cũ do mình cũng chưa update các version mới. Khi các bạn thử trải nghiệm các version mới có thể sẽ gặp một chút xung đột bởi các câu lệnh có thể chưa được update. Nhưng nhìn chung, bài viết này cũng có mô tả cách thức cách thức cơ bản để sử dụng và trải nghiệm Triton Inference Server và Triton Tool.
Tổng kết
Qua 2 bài viết tổng quan về Triton Inference Server và Triton Tutorial mà mình đã dành thời gian tổng hợp, hy vọng các bạn đã có cái nhìn khái quát về cách Triton Inference Server hoạt động và cách sử dụng cơ bản nhất của nó. Bài viết có thể chưa được đầy đủ toàn bộ thông tin, các bạn có thể tìm đọc thêm và trải nghiệm dựa trên Triton Documentation mà mình sẽ đính kèm ở phần Reference.
Reference
All rights reserved
