TorchServe, công cụ hỗ trợ triển khai mô hình PyTorch
Bài đăng này đã không được cập nhật trong 5 năm
Lời mở đầu
Hôm nay tôi sẽ giới thiệu sơ qua cho các bạn công cụ triển khai mô hình dành riêng cho mô hình PyTorch. Công cụ này gọi là TorchServe, mới phát triển gần đây nên repo ít sao hơn Tensorflow Serving và bug cũng nhiều hơn  . Link Git repo: https://github.com/pytorch/serve
. Link Git repo: https://github.com/pytorch/serve
Sơ đồ hệ thống TorchServe
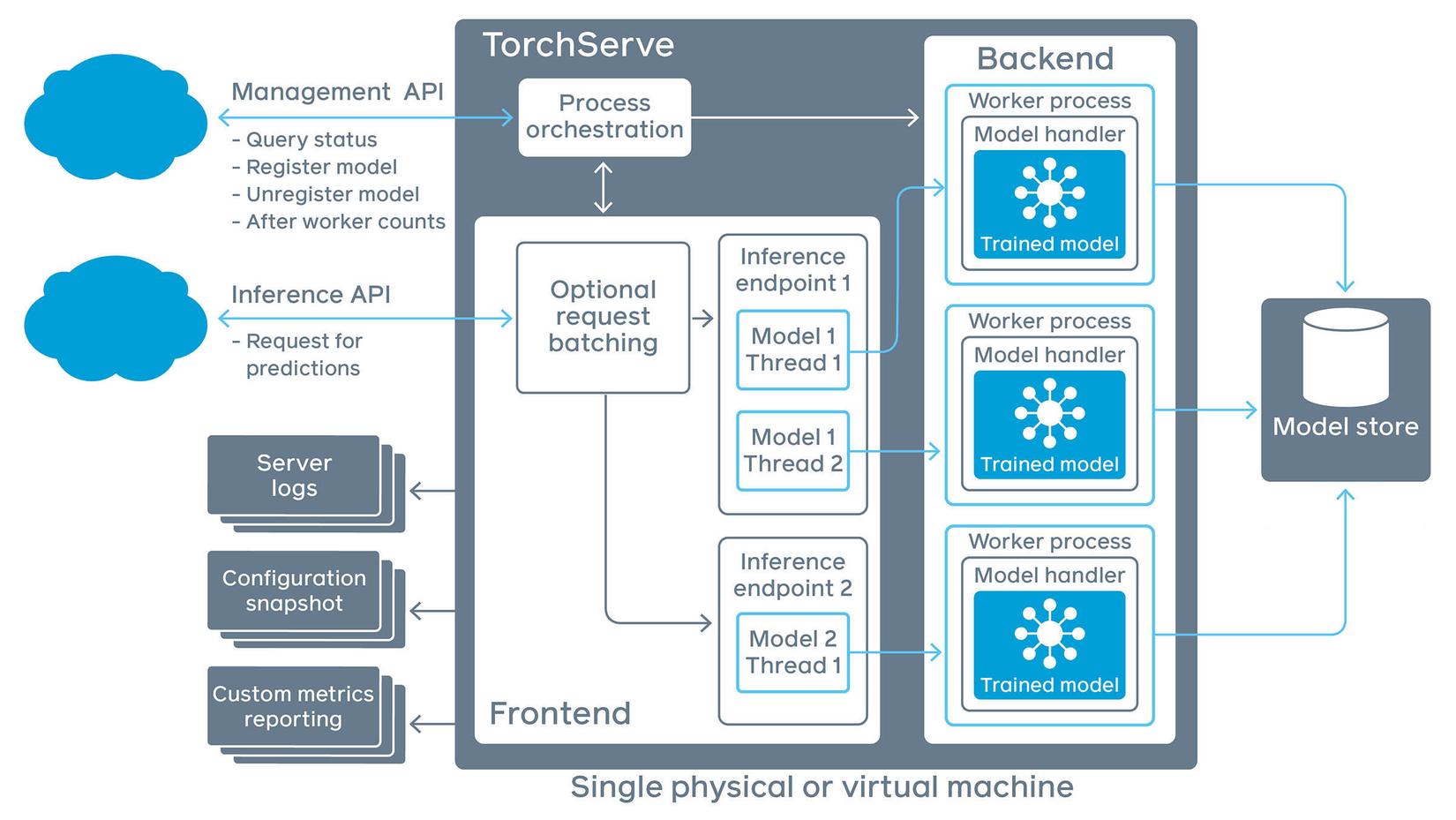
Như hình trên, hệ thống TorchServe chia là 3 phần: API, Core ( Backend & Frontend ), Model Storage.
Trong API sẽ chia ra 2 phần: Management API và Inference API, cái đầu sẽ quản lí trạng thái của query, trạng thái của mô hình, số lượng worker , cái sau là nơi tiếp nhận request của người dùng.
Trong core của TorchServe chia ra 2 phần: Frontend và Backend. Frontend tiếp nhận request của người dùng nếu nhiều request thì sẽ được batching và trả về các log thông báo trạng thái requests. Các batch request này thông qua inference endpoint để tới Backend, ở đây Backend chia các batch request đến từng tiến trình worker, mỗi worker quản lí một instance của mô hình đã huấn luyện.
Vậy mô hình lấy ở đâu? Tất nhiên trong model storage rồi, ở đây chứa nhiều mô hình dùng cho các task khác nhau: Classification, Detection, Segmentation, ... Mỗi mô hình sẽ có nhiều phiên bản khác nhau. TorchServe sẽ tự động load mô hình dựa trên config của người dùng.
Cài đặt TorchServe và torch-model-archiver
Đầu tiên bạn cần clone repo về đã:
git clone https://github.com/pytorch/serve
cd serve
Dựa trên môi trường mà bạn cần, có các lựa chọn cài đặt sau:
- Với CPU cho Torch 1.7.1
python ./ts_scripts/install_dependencies.py
- Với GPU và Cuda 10.2
python ./ts_scripts/install_dependencies.py --cuda=cu102
- Với GPU và Cuda 10.1
python ./ts_scripts/install_dependencies.py --cuda=cu101
- Với GPU và Cuda 9.2
python ./ts_scripts/install_dependencies.py --cuda=cu92
=> Cài đặt các dependencies cần thiết
Tiếp đó cài 2 thư viện quan trọng: torchserve và torch-model-archiver có thể bằng conda hoặc pip
- Với Conda
conda install torchserve torch-model-archiver -c pytorch
- Với Pip
pip install torchserve torch-model-archiver
Lưu mô hình bằng TorchServe
Tạo 1 folder ở đâu cũng được, đặt tên là model_store
mkdir model_store
Tải về 1 mô hình mẫu để triển khai và dự đoán xem sao. Ở đây tôi dùng densene161
wget https://download.pytorch.org/models/densenet161-8d451a50.pth
Dùng thư viện torch-model-archive để lưu lại mô hình dưới format mà TorchServe hỗ trợ
torch-model-archiver \
--model-name densenet161 \
--version 1.0 \
--model-file ./serve/examples/image_classifier/densenet_161/model.py \
--serialized-file densenet161-8d451a50.pth \
--export-path model_store \
--extra-files ./serve/examples/image_classifier/index_to_name.json \
--handler image_classifier
Giải thích các tham số trong câu lệnh trên:
model-name: tên mô hìnhversion: phiên bản bao nhiêumodel-file: model file, nếu bạn lưu mô hình bằng torch save thì không cần ( Optional )serialized-file: bắt buộc, mô hình đã huấn luyện chờ convert, ở đây typing đường dẫn tới mô hìnhexport-path: nơi xuấtextra-files: file json chứa label ( Optional )handler: bắt buộc, file xử lý ( tiền xử lý, hậu xử lý dữ liệu ), có thể thừa kế từ các class có sẵn trong repo hoặc custom lại theo đúng ý mình.
Kết quả:
Chạy server TorchServe
Sau khi có file trên thì bạn dùng command này. Command này sẽ mở endpoint cho request của người dùng cũng như thực thi các tiến trình ẩn bên trong để serve mô hình.
torchserve \
--start --ncs \
--model-store model_store \
--models densenet161.mar
start: bắt đầu phiên làm việc của TorchServestop: kết thúc phiên làm việc của TorchServemodel-store: nơi chứa mô hình, cụ thể là folder chứa file có đuôi.marban nãymodels: mô hình cần load, ví dụdensenet161.marlog-config: file config cho logts-config: file config đặc biệt cho TorchServe, như điều chỉnh port chẳng hạnforeground: show log khi chạy trên terminal, nếu disable ts sẽ chạy ẩnncs: disable snapshot
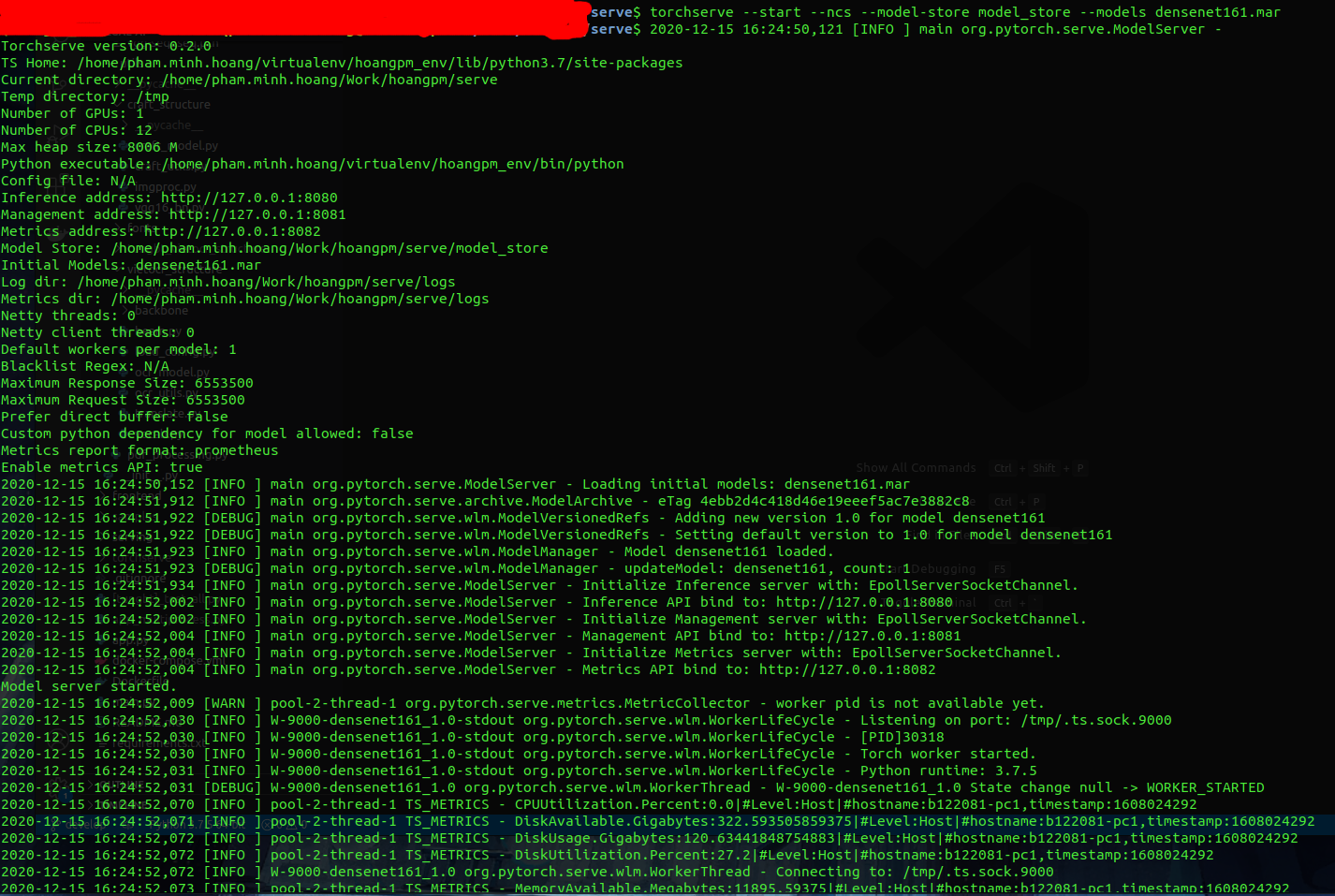
Link Inference API: http://127.0.0.1:8080
Link Management API: http://127.0.0.1:8081
Link Metric API: http://127.0.0.1:8082
2 cái link dưới chưa đề cập đến, chúng ta cùng tìm hiểu link đầu nào. Link này dùng để dự đoán kết quả bằng REST API
Tải về 1 ảnh trước đã:
curl -O https://raw.githubusercontent.com/pytorch/serve/master/docs/images/kitten_small.jpg

Dùng command line để gửi image request có method POST tới TorchServe endpoint
curl http://127.0.0.1:8080/predictions/densenet161 -T kitten_small.jpg
Output:

{
"tabby": 0.5237820744514465,
"tiger_cat": 0.18530139327049255,
"lynx": 0.15431317687034607,
"tiger": 0.056817926466464996,
"Egyptian_cat": 0.04702862352132797
}
Dự đoán qua gRPC
- Trước hết tải về các thư viện hỗ trợ giao thức gRPC đã
pip install -U grpcio protobuf grpcio-tools
- Trong folder
serve, dùng proto file để gen gRPC client stub
python -m grpc_tools.protoc \
--proto_path=frontend/server/src/main/resources/proto/ \
--python_out=ts_scripts \
--grpc_python_out=ts_scripts frontend/server/src/main/resources/proto/inference.proto frontend/server/src/main/resources/proto/management.proto
- Đăng ký mô hình sử dụng
python ts_scripts/torchserve_grpc_client.py register densenet161
- Dự đoán 1 mẫu bằng gRPC python client
python ts_scripts/torchserve_grpc_client.py infer densenet161 examples/image_classifier/kitten.jpg
- Hủy đăng ký mô hình
python ts_scripts/torchserve_grpc_client.py unregister densenet161
Mặc định, TorchServe chiếm 2 port 7070 cho gRPC Inference API và 7071 cho gRPC Management API
Kết quả thì tôi chưa thử gRPC nên cũng không show ra cho các bạn xem được ( thực ra thử rồi nhưng dính bug, phương thức dự đoán này mới được cập nhật trên repo của torchserve nên lỗi cũng là chiện bình thường  )
)
Management API
Khi bạn có nhiều mô hình, đây là lúc bạn cần một công cụ quản lý hiệu quả và tất nhiên torchserve hỗ trợ cái này thông qua API endpoint. Các chức năng được hỗ trợ
- Đăng ký 1 mô hình
- Tăng/giảm số lượng worker cho một mô hình chỉ định
- Mô tả trạng thái của mô hình
- Hủy đăng ký mô hình
- Show các mô hình đã đăng ký
- Chỉ định một phiên bản mô hình làm mặc định
Đăng ký mô hình
Dùng phương thức POST: POST /models
Liệt kê các tham số:
- url: đường dẫn tới mô hình có đuôi
.marhoặc đường dẫn tải mô hình từ Internet. Ví dụ: https://torchserve.pytorch.org/mar_files/squeezenet1_1.mar - model_name: tên mô hình
- handler: hãy chắc rằng handler có trong PYTHONPATH. Format: module_name: method_name
- runtime: mặc định PYTHON
- batch_size: mặc định 1
- max_batch_delay: thời gian chờ batch, mặc định 100 ms
- initial_workers: số lượng worker khởi tạo, mặc định 0, TorchServe sẽ không chạy khi không có worker
- synchronous: tạo worker đồng bộ hay không đồng bộ, mặc định
false - response_timeout: thời gian chờ, mặc định 120 s
curl -X POST "http://localhost:8081/models?url=https://torchserve.pytorch.org/mar_files/squeezenet1_1.mar"
{
"status": "Model \"squeezenet_v1.1\" Version: 1.0 registered with 0 initial workers. Use scale workers API to add workers for the model."
}
Đăng ký mô hình cùng với tạo worker
curl -v -X POST "http://localhost:8081/models?initial_workers=1&synchronous=false&url=https://torchserve.pytorch.org/mar_files/squeezenet1_1.mar"
* Trying 127.0.0.1...
* TCP_NODELAY set
* Connected to localhost (127.0.0.1) port 8081 (#0)
> POST /models?initial_workers=1&synchronous=false&url=https://torchserve.pytorch.org/mar_files/squeezenet1_1.mar HTTP/1.1
> Host: localhost:8081
> User-Agent: curl/7.58.0
> Accept: */*
>
< HTTP/1.1 202 Accepted
< content-type: application/json
< x-request-id: 61d2b2b4-2a3a-49d4-84c9-e6f2f92cd36d
< Pragma: no-cache
< Cache-Control: no-cache; no-store, must-revalidate, private
< Expires: Thu, 01 Jan 1970 00:00:00 UTC
< content-length: 47
< connection: keep-alive
<
{
"status": "Processing worker updates..."
}
* Connection #0 to host localhost left intact
Scale workers
Dùng phương thức PUT: PUT /models/{model_name}
Liệt kê tham số:
- min_worker: (Optional) số lượng worker nhỏ nhất, mặc định 1
- max_worker: (Optional) số lượng worker nhiều nhất, mặc định 1, TorchServe sẽ không tạo worker vượt quá con số này
- number_gpu: (Optional) số GPU worker tạo, mặc định 0, nếu số worker vượt qua số GPU có trên máy thì các worker còn lại sẽ chạy trên CPU
- synchronous: mặc định
false - timeout: thời gian chờ worker hoàn thành các pending requests. Nếu vượt qua con số này, worker sẽ dừng hoạt động. Giá trị
0sẽ dừng tiến trình worker ngay lập tức. Giá trị-1sẽ đợi vô thời hạn. Mặc định-1
curl -v -X PUT "http://localhost:8081/models/squeezenet1_1/?min_worker=3"
* Trying 127.0.0.1...
* TCP_NODELAY set
* Connected to localhost (127.0.0.1) port 8081 (#0)
> PUT /models/squeezenet1_1/?min_worker=3 HTTP/1.1
> Host: localhost:8081
> User-Agent: curl/7.58.0
> Accept: */*
>
< HTTP/1.1 202 Accepted
< content-type: application/json
< x-request-id: b508190b-ef7d-4e7a-a361-6dac1036d2bd
< Pragma: no-cache
< Cache-Control: no-cache; no-store, must-revalidate, private
< Expires: Thu, 01 Jan 1970 00:00:00 UTC
< content-length: 47
< connection: keep-alive
<
{
"status": "Processing worker updates..."
}
* Connection #0 to host localhost left intact
Nếu mô hình có nhiều phiên bản: PUT /models/{model_name}/{version}
curl -v -X PUT "http://localhost:8081/models/squeezenet1_1/1.0?min_worker=3"
Mô tả mô hình
Dùng phương thức GET: GET /models/{model_name}
curl http://localhost:8081/models/squeezenet1_1
[
{
"modelName": "squeezenet1_1",
"modelVersion": "1.0",
"modelUrl": "https://torchserve.pytorch.org/mar_files/squeezenet1_1.mar",
"runtime": "python",
"minWorkers": 3,
"maxWorkers": 3,
"batchSize": 1,
"maxBatchDelay": 100,
"loadedAtStartup": false,
"workers": [
{
"id": "9001",
"startTime": "2020-12-16T15:13:43.722Z",
"status": "READY",
"gpu": true,
"memoryUsage": 2044100608
},
{
"id": "9002",
"startTime": "2020-12-16T15:52:52.561Z",
"status": "READY",
"gpu": true,
"memoryUsage": 2045640704
},
{
"id": "9003",
"startTime": "2020-12-16T15:52:52.561Z",
"status": "READY",
"gpu": true,
"memoryUsage": 2060914688
}
]
}
]
Nếu mô hình có nhiều phiên bản: GET /models/{model_name}/all
Hủy đăng ký mô hình
Dùng phương thức Delete: DELETE /models/{model_name}/{version}
curl -X DELETE http://localhost:8081/models/squeezenet1_1/1.0
{
"status": "Model \"squeezenet1_1\" unregistered"
}
Liệt kê các mô hình đăng ký
Dùng phương thức GET: GET /models
Các tham số:
- limit: (Optional) số item trả về, mặc định 100
- next_page_token: (Optional) trang thứ mấy
curl "http://localhost:8081/models"
{
"models": [
{
"modelName": "densenet161",
"modelUrl": "densenet161.mar"
},
{
"modelName": "squeezenet1_1",
"modelUrl": "https://torchserve.pytorch.org/mar_files/squeezenet1_1.mar"
}
]
}
Set mô hình mặc định
Dùng phương thức PUT: PUT /models/{model_name}/{version}/set-default
curl -v -X PUT http://localhost:8081/models/squeezenet1_1/1.0/set-default
* Trying 127.0.0.1...
* TCP_NODELAY set
* Connected to localhost (127.0.0.1) port 8081 (#0)
> PUT /models/squeezenet1_1/1.0/set-default HTTP/1.1
> Host: localhost:8081
> User-Agent: curl/7.58.0
> Accept: */*
>
< HTTP/1.1 200 OK
< content-type: application/json
< x-request-id: 6db1cff1-7517-4826-b146-0e8605ecfd36
< Pragma: no-cache
< Cache-Control: no-cache; no-store, must-revalidate, private
< Expires: Thu, 01 Jan 1970 00:00:00 UTC
< content-length: 93
< connection: keep-alive
<
{
"status": "Default vesion succsesfully updated for model \"squeezenet1_1\" to \"1.0\""
}
* Connection #0 to host localhost left intact
Kết luận
Hôm nay viết đến đây thôi, ai có hứng thú thì lên repo của TorchServe để vọc vạch nhé.
References
All rights reserved
