Tổng quan về Apache Kafka
Bài đăng này đã không được cập nhật trong 6 năm
Kafka hoạt động như thế nào?
Kafka được xây dựng dựa trên mô hình publish/subcribe, tương tự như bất kỳ hệ thống message nào khác. Các ứng dụng (đóng vai trò là producer) gửi các messages (records) tới một node kafka (broker) và nói rằng những messages này sẽ được xử lý bởi các ứng dụng khác gọi là consumers. Các messages được gửi tới kafka node sẽ được lưu trữ trong một nơi gọi là topic và sau đó consumer có thể subcribe tới topic đó và lắng nghe những messages này. Messages có thể là bất cứ thông tin gì như giá trị cảm biến, hành động người dùng, …
Top 10 Apache Kafka Features
- Scalability: Apache Kafka có thể xử lý khả năng mở rộng ở cả bốn chiều, tức là event producers, event processors, event consumers và event connectors. Nói cách khác, có khả năng mở rộng dễ dàng.
- High-Volume: Kafka có thể dễ dàng xử lí khối lượng dữ liệu khổng lồ (huge volume of data streams)
- Data Transformations: Data Transformations Kafka offers provision for deriving new data streams using the data streams from producers.
- Fault Tolerance: The Kafka cluster can handle failures with the masters and databases.
- Reliability: Vì Kafka được phân tán(distributed), phân vùng (partitioned), nhân bản (replicated) và chịu lỗi (fault tolerant), nên nó rất đáng tin cậy (Reliable).
- Durability: Nó bền (durable) bởi vì Kafka sử dụng Distributed commit log, điều đó có nghĩa là các messages vẫn tồn tại trên disk (messages persists on disk as fast as possible).
- Performance: Đối với cả publishing và subscribing messages, Kafka đều có thông lượng cao. Ngay cả khi nhiều TB messages được lưu trữ, nó vẫn duy trì hiệu suất ổn định.
- Zero Downtime: Kafka rất nhanh và đảm bảo zero downtime và zero data loss.
- Extensibility: Có nhiều cách để các ứng dụng có thể tích hợp và sử dụng
- Replication: Bằng cách sử dụng các pipelines, nó có thể sao chép các sự kiện (By using ingest pipelines, it can replicate the events.).
Các thuật ngữ và khái niệm của Apache Kafka
1. Kafka Broker
Xử lý tất cả các yêu cầu từ client (produce, consume, metadata) và giữ dữ liệu được sao chép trong cụm. Có thể có một hoặc nhiều broker trong một cụm.
2. Kafka Broker Clusters
Một máy có thể chạy nhiều server kafka, mỗi server như vậy gọi là một broker. Các broker này cùng trỏ tới chung 1 zookeeper thì chúng là 1 cụm broker(Clusters).
3. Kafka ZooKeeper
Kiểm soát trạng thái của cluster (brokers, topics, users, …)
4. Kafka Topics
Về cơ bản, Kafka duy trì nguồn cấp tin nhắn trong các categories. Và, messages được lưu trữ cũng như được xuất bản trong một category/feed name. Chúng được gọi là topics. Ngoài ra, tất cả các messages trong Kafka thường được tổ chức thành các Kafka topics.
Tóm lại, một topic là một category hoặc feed name nơi mà messages được publish.
Nhìn về mặt database thông thường thì topic giống như một table trong CSDL SQL. Topic là nơi chứa message. Mỗi message giống như record trong table (Chỉ khác là chúng NoSql).
5. Kafka Partitions
Với mỗi broker trong Kafka, chúng được chia thành các partition. Các partition trong Kafka có thể là leader hoặc là bản sao (replica) của một topic. Leader partition chịu trách nhiệm cho tất cả các tác vụ đọc ghi của topic. Nếu leader partition bị hỏng, replica partition sẽ đảm nhận vai trò leader partition mới.
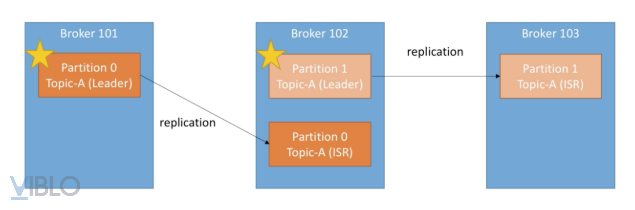
Tại bất kỳ thời điểm nào thì chỉ có một broker làm leader các partition còn lại. Và chỉ có leader partition mới nhận và xử lý data. Giả sử như broker 101 sập. in-sync replica ở broker 102 sẽ thay thế làm leader. Tiếp tục xử lý data. Khi broker 101 được khởi động lại nó lại làm replica, đồng bộ dữ liệu với leader hiện tại ở 102. Cho đến khi trở thành lại làm leader. Việc làm leader sẽ phụ thuộc vào Zookepper quyết định.
Ngoài ra partion là nơi lưu trữ message của topic. Một topic có thể có nhiều partition. Khi khởi tạo topic cần set số partition cho topic đó. Partition càng nhiều thì khả năng làm việc song song cho đọc và ghi được thực hiện nhanh hơn. Các message trong partition được lưu theo thứ tự bất biến(offset). Một partition sẽ có tối thiểu 1 replica để đề phòng trường hợp bị lỗi. Số lượng replica luôn nhỏ hơn số lượng broker.
6. Kafka Producers
Là nơi đẩy dữ liệu từ người dùng vào các partition của topic. Tùy vào việc có chỉ định rõ ghi vào phân vùng nào không thì producer sẽ gửi đến phân vùng của topic đó hoặc phân bố đều vào các partition.
Nói một cách đơn giản, các quy trình publish messages tới Kafka được gọi là Producer.
7. Kafka Consumers
Các quy trình subscribe topics và đọc nguồn cấp dữ liệu của các published messages, được gọi là Consumer.
Mỗi consumer phụ trách 1 vài partition của topic. Nhiều consumer có thể sử dụng chung 1 nhóm (group consumer) để hỗ trợ cho việc xử lý nhanh các dữ liệu. Có nhiều group consumer xử lý cùng 1 topic theo các điểm start offset khác nhau. Điều này có thể phục vụ cho việc bạn có 2 process riêng biệt, một phục vụ cho việc duy trì hệ thống với dữ liệu mới đẩy vào, một phục vụ cho việc re-process lại toàn bộ data.
8. Offset in Kafka
Các message khi được đẩy vào thì sẽ qua các partition. Trong mỗi partition, dữ liệu được đẩy vào sẽ có một định danh ID tự tăng, hay còn gọi là offset — một khái niệm quan trọng của Kafka.
Nguồn tham khảo
- https://viblo.asia/p/hang-doi-thong-diep-apache-kafka-jvEla6145kw
- https://www.tutorialspoint.com/apache_kafka/apache_kafka_cluster_architecture.htm
- https://blog.vu-review.com/kafka-la-gi.html
- https://viblo.asia/p/kafka-apache-WAyK8pa6KxX
- https://data-flair.training/blogs/kafka-architecture/
- https://www.cloudkarafka.com/blog/2016-11-30-part1-kafka-for-beginners-what-is-apache-kafka.html
- https://www.facebook.com/notes/cộng-đồng-big-data-việt-nam/tiếp-cận-kafka-thông-qua-confluent-platform/884414712076055/
All rights reserved
