Tóm Tắt : YOLOv10: Real-Time End-to-End Object Detection
Tổng quan những cải tiến chính của YOLOv10 bao gồm có:
- NMS-Free Training
- Spatial-channel decoupled downspamling
- Rank-guided box design
- Lightweight classification head
1 . NMS-Free Training Các mô hình YOLO trước sau khi huấn luyện sẽ có bước hậu xử lý là NMS để loại bỏ các bounding box dư thừa. Về cơ bản NMS sẽ đảm bảo mỗi đối tượng sẽ chỉ được biểu thị bằng một bounding box duy nhất. Tuy nhiên hạn chế của NMS chính là chi phí tính toán (computationally expensive) và thời gian suy luận (inference time) của nó, đặc biệt khi mà số lượng bounding càng nhiều sẽ càng làm tăng inference time ở bước hậu xử lý.

Trong quá trình huấn luyện thông thường YOLO sẽ sử dụng phương pháp gọi là Task-Aligned Learning để gán nhãn cho quá trình huấn luyện, TAL này sẽ sử dụng phương pháp gọi là one-to-many label assignment .Ví dụ, nếu một dự đoán của mô hình chứa một phần của một con chó và một phần của một con mèo, thì cả hai nhãn "chó" và "mèo" có thể được gán nhãn xếp chồng nên nhau cho dự đoán của đó. Điều này cho phép mô hình học được cách nhận diện và phân biệt giữa nhiều đối tượng trong một dự đoán duy nhất giúp tăng cường hiệu suất của mô hình. Nhưng đồng thời phương pháp này cũng làm tăng thêm bước hậu xử lý huấn luyện gọi là "non-maximum suppression" (NMS) => làm tăng inference time ⇒ Tác giả đề xuất sử dụng chiến lược Dual labels assignment và consistance matching metric.
Chúng ta có bảng so sánh 2 phương pháp one-to-many label assignment và one-to-one label assignment:
-One-to-many label assignment:
Ưu điểm: Cung cấp nhiều thông tin tín hiệu giám sát, giúp mô hình học tốt hơn, tốc độ hội tụ nhanh hơn.
Nhược điểm: Cần phải xử lý NMS sau khi huấn luyện, tốn thời gian triển khai và tính toán ở bước hậu xử lý.
-One-to-one label assignment:
Ưu điểm: Tránh việc phải xử lý NMS (non-maximum suppression) sau khi huấn luyện, giúp đơn giản hóa và tăng tốc độ triển khai mô hình.
Nhược điểm: Tín hiệu giám sát sát yếu hơn, dẫn đến độ chính xác và tốc độ hội tụ không tối ưu.
=> Tận dụng những ưu điểm của 2 phương pháp trên tác giả sử dụng phương pháp Dual labels assignment.
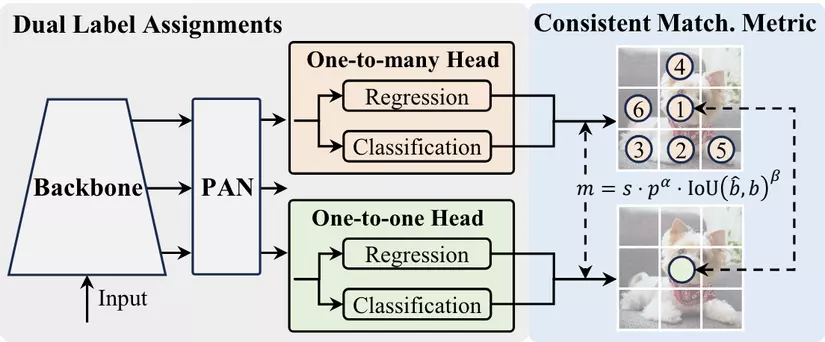
Cách Dual labels assignment hoạt động về cơ bản trong quá trình huấn luyện thì sẽ sử dụng 2 head để tận dụng điểm mạnh của 2 phương pháp nhưng đến khi inference thì sẽ chỉ sử dụng 1 head là one-to-one để dự đoán tránh việc phải xử NMS. Còn Consistent math metrics là độ đo để đánh giá dự đoán và nhãn thực tế. Hơn nữa ở phương pháp one-to-one tác giả còn kết hợp với phương pháp top one selection ( giúp chọn dự đoán có điểm số cao nhất đối với mỗi object) thay vì sử dụng Hungarian matching mà vẫn đạt được hiệu suất cao (HM là một thuật toán tối ưu hóa được sử dụng để giải bài toán gán nhãn, đảm bảo rằng tổng mức độ thích hợp giữa các dự đoán và các object là cao nhất)
2. Spatial-channel decoupled downspamling
Phương pháp hiện tại trong YOLOs:
- Sử dụng tích chập 3x3 với bước nhảy (stride) là 2.
- Sử dụng Spatial Downsampling để HxW thành H/2 x W/2.
- Tăng số Channel từ C lên 2C.
 YOLOs: điều chỉnh kích thước kênh và kích thước không gian trong cùng một bước -> chi phí tính toán cao do đó YOLOv10 sẽ thực hiện 2 bước này một cách riêng biệt.
YOLOs: điều chỉnh kích thước kênh và kích thước không gian trong cùng một bước -> chi phí tính toán cao do đó YOLOv10 sẽ thực hiện 2 bước này một cách riêng biệt.
Để giải quyết vấn đề chi phí tính toán ở các phiên bản YOLOs trước đó YOLOv10 sử dụng phương pháp gọi là Spatial-channel decoupled downspamling giúp giảm chi phí tính toán và tối đa hóa việc giữ lại các thông tin quan trọng của ảnh, phương pháp này sẽ bao gồm 2 quá trình được thực hiện một cách riêng biệt:
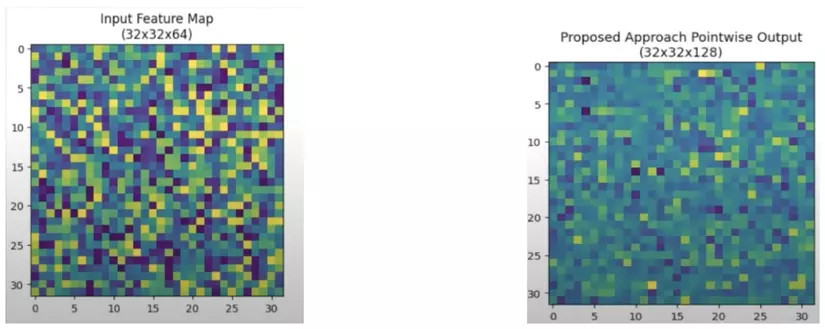
- Tích chập điểm-pointwise convolution (1x1 convolution): Điều chỉnh kích thước kênh (channel). Hình minh hoạ bên dưới thể hiện khi input feature map được áp dụng pointwise convolution thì chiều dài và rộng vẫn được giữ nguyên trong khi số kênh đã tăng lên 128.
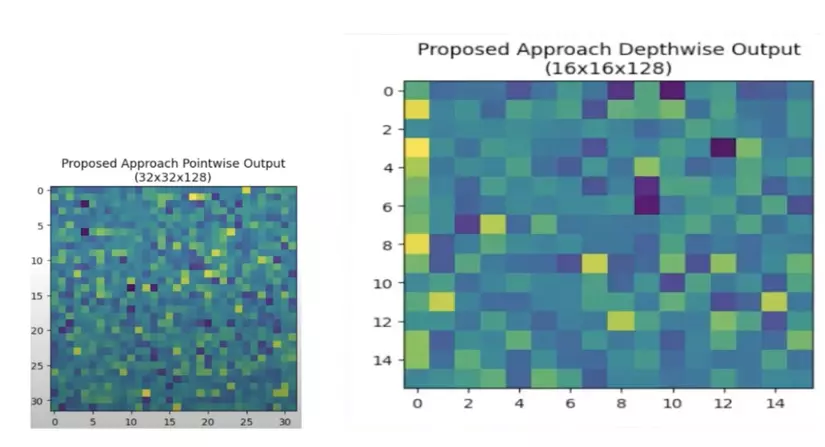
- Tích chập độ sâu - depthwise convolution(3x3 convolution with stride 2): Thực hiện giảm kích thước không gian. Hình minh hoạ bên dưới mô tả quá trình thực hiện depthwise convolution sau khi thực hiện bước 1 là pointwise convolution lúc này kích thước đã giảm từ 32x32 thành 16x16 mà vẫn giữ nguyên channel.
3. Rank-guided box design YOLO sử dụng cùng một thiết kế khối xây dựng cơ bản cho tất cả các giai đoạn của mô hình, như khối bottleneck trong YOLOv8. Ở đó intrinsic rank sẽ được sử dụng để đo lường tính dư thừa của các giai đoạn khác nhau trong mô hình ( khối có thông tin dư thừa càng nhiều thì sẽ có rank càng cao và ngược lại). Intrinsic rank được tính toán bằng cách đếm các singular values nếu lớn hơn một ngưỡng trong tích chập cuối cùng của mỗi khối cơ bản. Kết quả cho thấy ở mỗi giai đoạn khác nhau của mạng sẽ có mức độ thông tin dư thừa khác nhau (thông tin dư thừa là thông tin được lặp đi lặp lại hoặc thông tin ít quan trọng), tác giả của YOLOv10 đã thay thế những khối đem lại thông tin dư thừa nhiều bằng Compact Inverted Block (CIB) để giải quyết vấn đề này.
- Cách phương pháp thực hiện:
+Bước 1: Sắp xếp các stage dựa trên intrinsic rank theo thứ tự tăng dần
+Bước 2: Thay thế các basic block tại stage tương ứng có thông tin dư thừa cao ( lower rank) bằng CIB.
4. Lightweight classification head: Giúp giảm khối lượng tính toán mà không giảm hiệu suất của mô hình.
5. Thực Nghiệm
Dưới đây là kết quả khi huấn luyện Yolov10 với 50 epoch trên google colab với tập tập train là 5128 ảnh, valid là 1233 ảnh, link chi tiết (https://colab.research.google.com/drive/1gL324hE5QiaZ2JasTsiVdfxHgNf_W8pR?usp=sharing)

All rights reserved
