
Tóm tắt vài mô hình Text-To-Speech (p2) - FastSpeech
Bài đăng này đã không được cập nhật trong 4 năm
1. Autogressive và Non-Autogressive model
- Autogressive model hiểu đơn giản chỉ là 1 feed-forward model mà dự đoán các giá trị tương lai dựa trên các giá trị quá khứ. Các kiến trúc TTS tiêu biểu cho Autogressive model có thể kể đến mô hình Tacotron và Tacotron2 được giới thiệu trong bài viết trước của mình

- Non-autogressive model sẽ sinh ra các token của chuỗi một cách song song, giúp tốc độ sinh chuỗi nhanh hơn các Autogressive models, đổi lại độ chính xác sẽ thấp hơn. Các kiến trúc TTS tiêu biểu cho Non-autogressive model có thể kể đến mô hình FastSpeech và FastSpeech2

2. FastSpeech
a. Ra đời:
b. Ý tưởng:
Các mô hình trước đó thường có điểm chung: đầu vào là text, sinh ra âm thanh từ mel-spectrogram thông qua các vocoder như Griffin-Lim, WaveNet, Parallel WaveNet,... Chúng đều là các hệ thống dựa trên nền tảng Neural Net, và vượt xa các phương pháp cổ điển như Statistical Parametric Synthesis
Dù vậy, do mel-spectrogram được sinh tuần tự dựa trên giá trị trước của chúng (autogressive mà) nên các hệ thống này có vài nhược điểm "cố hữu":
- Tốc độ suy luận (inference) chậm: do chuỗi mel-spectrogram thường rất dài, việc sinh mel-spectrogram tuần tự sẽ rất chậm
- Not robust: âm thanh sinh ra thường gặp các vấn đề như bỏ qua từ, lặp từ
- Không kiểm soát được ngữ điệu: âm thanh sinh ra khó kiểm soát về tốc độ, ngữ điệu, ngắt nghỉ,...
Từ đó, tác giả đề xuất mô hình FastSpeech, nhận đầu vào là 1 chuỗi âm vị (phoneme) và sinh spectrogram non-aggressively (có thể hiểu là song song, đồng thời). Một số điểm đặc biệt của FastSpeech
- Sử dụng feed-forward network dựa trên self-attention trong Transformer và 1-D Convolution giúp sinh mel-spectrogram song song, tăng tốc quá trình tổng hợp âm thanh
- Phoneme duration predictor giúp đảm bảo hard-alignment giữa phoneme và mel-spectrogram, từ đó giảm tỷ lệ mất, lặp từ
- Length regulator giúp điều chỉnh tốc độ giọng nói bằng cách kéo dài/làm ngắn độ dài âm vị, cũng như kiểm soát được 1 phần âm điệu bằng cách thêm các quãng nghỉ giữa các âm vị liền kề
Dù vậy, mô hình cũng có nhược điểm: việc sử dụng hard alignment thay vì soft alignment và automatic attention alignment như các autogressive model khiến âm thanh thiếu tự nhiên hơn
c. Kiến trúc:
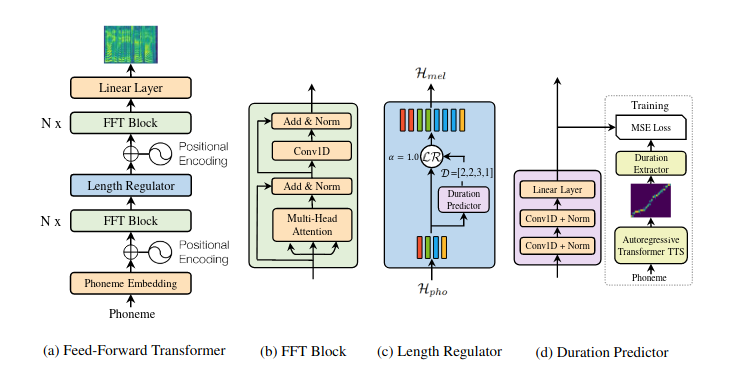
Feed-forward Transformer (hình a)
- Ngoài 2 thành phần cơ bản là Embedding (ở đây là Phoneme Embedding do input là phoneme) và Positional Encoding, Feed-Forward Transformer gồm nhiều khối FFT nhằm chuyển từ phoneme sang mel-spectrogram, chia làm 2 phần rõ rệt là Phoneme side và mel-spectrogram side, mỗi phần có N khối FFT. 2 phần được kết nối bởi Length Regulator
- Nói về khối FFT (hình b): mỗi khối FFT gồm self-attention network (thực ra là multi-head attention) + 2 lớp 1-D Convolution thay vì 2 lớp Dense trong Transformer. Tác giả giải thích rằng các trạng thái ấn liền kề thường liên quan chặt chẽ hơn trong âm vị và chuỗi mel-spectrogram - đã được đánh giá qua thực nghiệm
Length Regulator (hình c)
- Length regulator(LR) được sử dụng để giải quyết vấn đề về sự không đồng nhất giữa chuỗi âm vị và chuỗi mel-spectrogram trong Feed-Forward Transformer (do 1 âm có thể ứng với nhiều mel-spectrogram độ dài khác nhau), cũng như điều khiển tốc độ giọng và một phần âm vị.
- Tác giải nhận ra rằng độ dài chuỗi phoneme thường nhỏ hơn độ dài chuỗi mel-spectrogram, và có sự tương ứng nào đó giữa chúng - tác giả gọi là phoneme duration(thời lượng âm). Việc dự đoán phoneme duration sẽ được đề cập ở phần sau.
Giả sử ta đã có chuỗi phoneme là , phoneme duration dự đoán được là thỏa mãn với m là độ dài chuỗi mel-spectrogram.
Hàm length regulator:
với là hyperparameter để xác định độ dài chuỗi mel-spectrogram , từ đó kiểm soát tốc độ giọng nói: thì tốc độ bình thường, thì là tốc độ chậm, thì là tốc độ nhanh. Ví dụ, xét:
với
Từ đó
- Ngoài ra, LR còn có thể điều chỉnh độ dài các quãng ngắt, giúp giọng đọc sinh ra đa dạng hơn
Duration Predictor (hình d)
Duration Predictor được sử dụng để dự đoán mỗi âm vị ứng với bao nhiêu cửa sổ mel-spectrogram, chính là được đề cập ở trên. Về cơ bản, cấu trúc của Duration Predictor gồm 2 lớp 1-D Convolution, mỗi lớp sử dụng Relu activation theo sau là Batch normalization và lớp dropout. Cuối cùng là lớp Linear để chuyển output thành 1 số.
Để huấn luyện Duration Predictor, tác giả sử dụng autogressive teacher TTS model như trong hình d nhằm trích xuất phoneme duration. Các bước cụ thể:
- Huấn luyện mô hình Autogressive encoder-attention-decoder dựa trên mạng Transformer TTS
- Với mỗi cặp dữ liệu, tác giả trích xuất các decoder-to-encoder attention alignment từ mô hình trên. Để chọn head thích hợp, tác giả đặt ra hàm focus rate dựa trên thuộc tính diagonal của các head:
trong đó S và T lần lượt là chiều dài của ground-truth spectrogram và phones, chỉ phần tử ở hàng , cột trong ma trận attention. Tác giả sẽ chọn head nào có giá trị F lớn nhất.
- Cuối cùng, tác giả tính theo công thức gọi là duration extractor:
d. Kết quả:
- Chất lượng âm thanh: đạt MOS 3.84, gần bằng các hệ thống như Tacotron2 và Transformer TTS

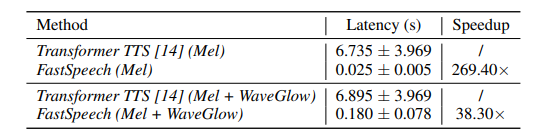
- Tốc độ suy luận: sinh mel-spectrogram nhanh gấp 269.40 lần Transformer TTS. Kể cả có dùng vocoder WaveGlow, tốc độ sinh audio của FastSpeech vẫn hơn 38.3. lần so với Transformer TTS
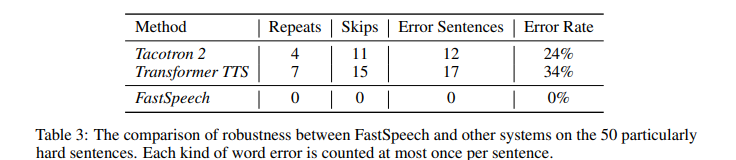
- Robustness: FastSpeech đã hạn chế được các vấn đề lặp hay mất từ ở các autogressive model
- Length Control: FastSpeech có thể điều chỉnh tốc độ âm thanh bằng cách điều chỉnh độ dài phoneme duration, cũng như thêm ngắt nghỉ giữa các từ bằng cách kéo dài thời lượng của các ký tự cách (space).
Reference
https://www.georgeho.org/deep-autoregressive-models/
https://arxiv.org/pdf/2004.10454.pdf
https://viblo.asia/p/tim-hieu-kien-truc-text2speech-fastspeech-V3m5WRexlO7
https://viblo.asia/p/bo-doi-anh-em-nha-fast-speech-ong-vua-moi-ke-vi-tacotron-phan-2-924lJRzmlPM
All rights reserved
