Token-Based Chunking trong AI – Cơ chế cắt dữ liệu theo token cho hệ thống NLP & RAG
Trong các pipeline xử lý ngôn ngữ tự nhiên và ứng dụng AI Agent, việc chia nhỏ văn bản thành các đơn vị có kích thước ổn định là một bước bắt buộc trước khi đưa vào LLM. Một trong những kỹ thuật được sử dụng rộng rãi là Token-Based Chunking, vốn cắt văn bản dựa trên số token thay vì ký tự hoặc câu. Phương pháp này đặc biệt phù hợp khi cần kiểm soát chặt chẽ dung lượng input và đảm bảo tương thích với giới hạn token của mô hình.
Bài viết dưới đây phân tích chi tiết cơ chế hoạt động, tham số quan trọng và cách triển khai bằng RecursiveCharacterTextSplitter trong LangChain, công cụ mà lập trình viên thường sử dụng khi xây dựng hệ thống RAG hoặc chatbot.
Token-Based Chunking là gì?
Dữ liệu văn bản trong hệ thống AI thường có độ dài lớn hơn nhiều so với mức mà mô hình có thể tiếp nhận trong một lượt xử lý. Vì vậy, chunking giúp phân đoạn văn bản thành các phần nhỏ, dễ vector hóa và truy vấn.
Khác với cắt theo độ dài ký tự (character-based) hoặc theo cấu trúc câu (sentence-based), Token-Based Chunking dựa hoàn toàn vào tokenizer của mô hình. Điều này giúp:
- Kiểm soát chính xác kích thước input theo token.
- Tránh lỗi “input too long” khi gọi API.
- Hạn chế chi phí khi embedding hoặc sinh nội dung.
Lưu ý rằng token không phải từ: một token có thể là cả từ, một phần của từ hoặc ký tự đặc biệt.
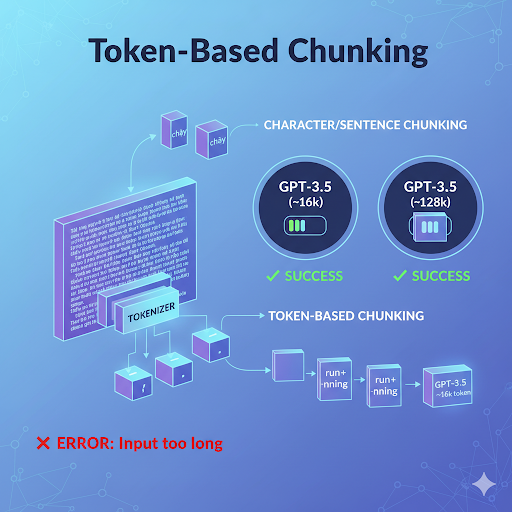
RecursiveCharacterTextSplitter – Cơ chế cắt token theo ngữ cảnh
Trong LangChain, RecursiveCharacterTextSplitter là wrapper phổ biến giúp cắt văn bản “mềm”, không chia giữa chừng câu hoặc phá vỡ ngữ cảnh. Thay vì cắt cứng theo token, splitter sẽ thử các điểm chia ưu tiên như xuống dòng, dấu chấm, khoảng trắng… trước khi fallback sang cắt thô.
Quy trình tổng quát:
- Xác định
chunk_size(giới hạn token). - Duyệt danh sách
separatorstheo thứ tự ưu tiên. - Nếu không tìm được điểm tách hợp lý → cắt cứng.
- Sinh ra các đoạn có
chunk_overlapđể giữ liền mạch ngữ nghĩa.
Nhờ vậy, developer có thể tạo chunk gọn, sạch, đúng token và vẫn đảm bảo mạch nội dung liền lạc.
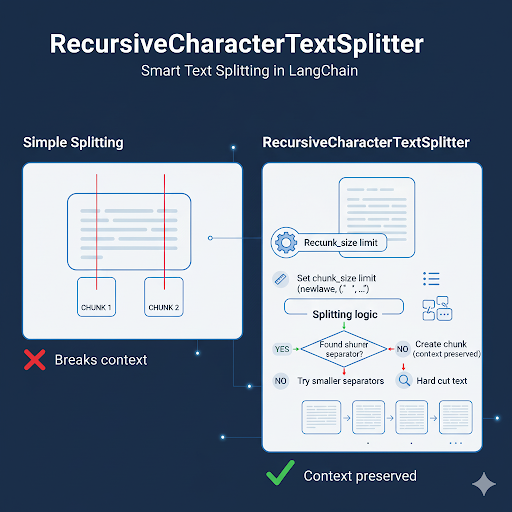
Các tham số quan trọng khi cấu hình TextSplitter
chunk_size — Kích thước tối đa mỗi đoạn
Xác định số token tối đa cho một chunk.
- Đặt quá lớn: dễ vượt limit mô hình.
- Đặt quá nhỏ: chunk rời rạc, embedding kém hiệu quả.
Gợi ý:
- LLM training: 512–1024 token
- RAG / chatbot: 300–600 token
chunk_overlap — Token chồng lấn
Overlap giúp mô hình không mất ngữ cảnh ở phần giao nhau giữa hai chunk.
Khuyến nghị: sử dụng 10–15% chunk_size
Ví dụ:
chunk_size = 500 → chunk_overlap = 50–75
separators — Danh sách ký tự ưu tiên khi cắt
Một bộ separator tốt giúp chunk tự nhiên và không phá vỡ câu.
Ví dụ phổ biến:
["\n\n", "\n", ".", " ", ""]
\n\n→ chia theo đoạn
.→ chia theo câu
"" → fallback cuối cùng
Dev có thể tùy chỉnh:
- Log file → dùng tab, dấu phẩy
- File kỹ thuật → thêm
:,;
length_function — Hàm tính số token
Để tính token chính xác, luôn dùng tokenizer tương ứng với mô hình:
- OpenAI: tiktoken
- HuggingFace: AutoTokenizer
Ví dụ:
import tiktoken
def tiktoken_len(text):
tokenizer = tiktoken.get_encoding("cl100k_base")
return len(tokenizer.encode(text))
keep_separator — Giữ hay bỏ ký tự phân tách
Nếu True, dấu ngắt câu hoặc ký tự phân tách được giữ lại trong chunk. Điều này hữu ích khi chunk được hiển thị hoặc sử dụng trong hội thoại.
add_start_index — Gắn vị trí gốc
Thêm metadata vị trí chunk trong tài liệu ban đầu, rất hữu ích cho:
RAG truy lần lại nguồn Tạo highlight kết quả tìm kiếm
strip_whitespace — Dọn sạch khoảng trắng dư thừa
Giúp chunk sạch và nhất quán trước khi embedding.
Tóm lược nhanh cho developer
chunk_size&chunk_overlap→ tối ưu độ dài & ngữ cảnhseparators&keep_separator→ chunk tự nhiên, ít gãy ýlength_function→ tính token chuẩn theo LLMadd_start_index&strip_whitespace→ hỗ trợ indexing và làm sạch dữ liệu
Demo Token-Based Chunking bằng LangChain
from langchain.text_splitter import RecursiveCharacterTextSplitter
import tiktoken
# Token counter
def tiktoken_len(text):
tokenizer = tiktoken.get_encoding("cl100k_base")
return len(tokenizer.encode(text))
splitter = RecursiveCharacterTextSplitter(
chunk_size=500,
chunk_overlap=50,
length_function=tiktoken_len,
separators=["\n\n", "\n", ".", " ", ""]
)
text = """
Token-Based Chunking tối ưu dữ liệu đầu vào cho LLM và RAG.
Kỹ thuật này giúp kiểm soát giới hạn token và giữ ngữ cảnh ổn định.
"""
chunks = splitter.split_text(text)
for i, c in enumerate(chunks):
print(f"--- Chunk {i+1} ---")
print(c)
Kết quả:
- Văn bản được chia thành đoạn <500 token
- 50 token cuối được chồng sang chunk tiếp theo
- Ngữ cảnh liền mạch, phù hợp embedding
So sánh Character-Based vs Token-Based
| Tiêu chí | Character-Based | Token-Based |
|---|---|---|
| Đơn vị cắt | Ký tự | Token theo tokenizer |
| Độ chính xác với LLM | Thấp | Rất cao |
| Ngữ cảnh | Dễ gãy câu | Giữ mạch tốt |
| Tối ưu chi phí embedding | Kém | Tốt |
| Use cases | Log, văn bản raw | AI, NLP, RAG, Chatbot |
Ưu điểm khi sử dụng Token-Based Chunking
- Tuân thủ giới hạn mô hình → Tránh lỗi input vượt token
- Giữ mạch nghĩa tự nhiên → Nhờ chunk_overlap
- Tối ưu truy vấn RAG → Dễ vector hóa, giảm nhiễu
- Ứng dụng rộng → LLM fine-tuning, RAG, chatbot, phân tích dữ liệu
Kết luận
Token-Based Chunking là phương pháp cắt dữ liệu chi tiết và chính xác nhất khi làm việc với LLM. Với sự hỗ trợ của RecursiveCharacterTextSplitter, developer có thể kiểm soát tốt kích thước input, đảm bảo văn bản sạch, đúng token và phù hợp cho embedding hoặc training.
Khi cấu hình hợp lý chunk_size, chunk_overlap, separators và tokenizer, hệ thống AI sẽ đạt độ chính xác cao hơn, chi phí thấp hơn và tốc độ truy vấn tối ưu hơn.
Nguồn tham khảo: https://bizfly.vn/techblog/token-based-chunking-cat-du-lieu-theo-token-va-ung-dung-trong-ai.html
All rights reserved
