Tôi không train model. Nhưng tôi bắt đầu kiểm soát được hành vi của nó (Nắng AI v47)
Tôi không train model. Nhưng tôi bắt đầu kiểm soát được hành vi của nó.
Ở bài trước (Sunny AI lv5), tôi đã build một autonomous agent:
- Tự chia task
- Tự sửa lỗi khi code fail (self-healing)
- Có tool guard để tránh hành động sai
Chạy hoàn toàn local với model 3B.
Nhưng sau khi dùng một thời gian, tôi nhận ra một vấn đề:
«Agent làm được việc — nhưng hành vi không ổn định.»
Vấn đề
Agent có thể:
- hoàn thành task
- sửa lỗi
- chạy end-to-end
Nhưng:
- có lúc trả lời lan man
- có lúc lặp lại
- có lúc “làm quá” yêu cầu
Nói cách khác:
«Nó làm được, nhưng không “ngoan”.»
Ý tưởng
Thay vì tiếp tục nâng cấp agent, tôi thử một hướng khác:
«Không thay đổi cách nó làm việc → mà thay đổi cách nó “cư xử”»
Lưu ý (quan trọng)
v47 không phải là phiên bản nâng cấp trực tiếp từ lv5.
Tôi không mang toàn bộ hệ thống agent sang.
Thay vào đó, tôi tách riêng một phần nhỏ để tập trung vào behavior:
- bỏ planner
- bỏ tool execution
- giữ lại vòng lặp core: → evaluation → reflection → adjustment
Mục tiêu:
«đơn giản hóa hệ thống để kiểm tra liệu có thể kiểm soát hành vi mà không cần toàn bộ agent hay không.»
Kiến trúc
Một layer mới:
LLM → Behavior Loop
Flow:
LLM → Output → Self-Eval → Reflection → Adjust → Next Output
Các thành phần chính
self_evaluator.py→ chấm điểm output mỗi turnreflection.py→ phân tích output vừa rồilatent_adapter.py→ điều chỉnh trạng thái hành vi (không can thiệp vào weights, mà thay đổi generation parameters hoặc “persona ngắn hạn” trong system prompt dựa trên reflection)metrics.py→ theo dõi sự thay đổi
Điểm khác biệt
Lv5:
- sửa lỗi khi fail
v47:
- điều chỉnh ngay cả khi không fail
Ví dụ
- câu trả lời quá ngắn → trừ điểm
- lặp từ → trừ điểm
- sai “vai” → trừ điểm
→ turn sau thay đổi hành vi
Demo
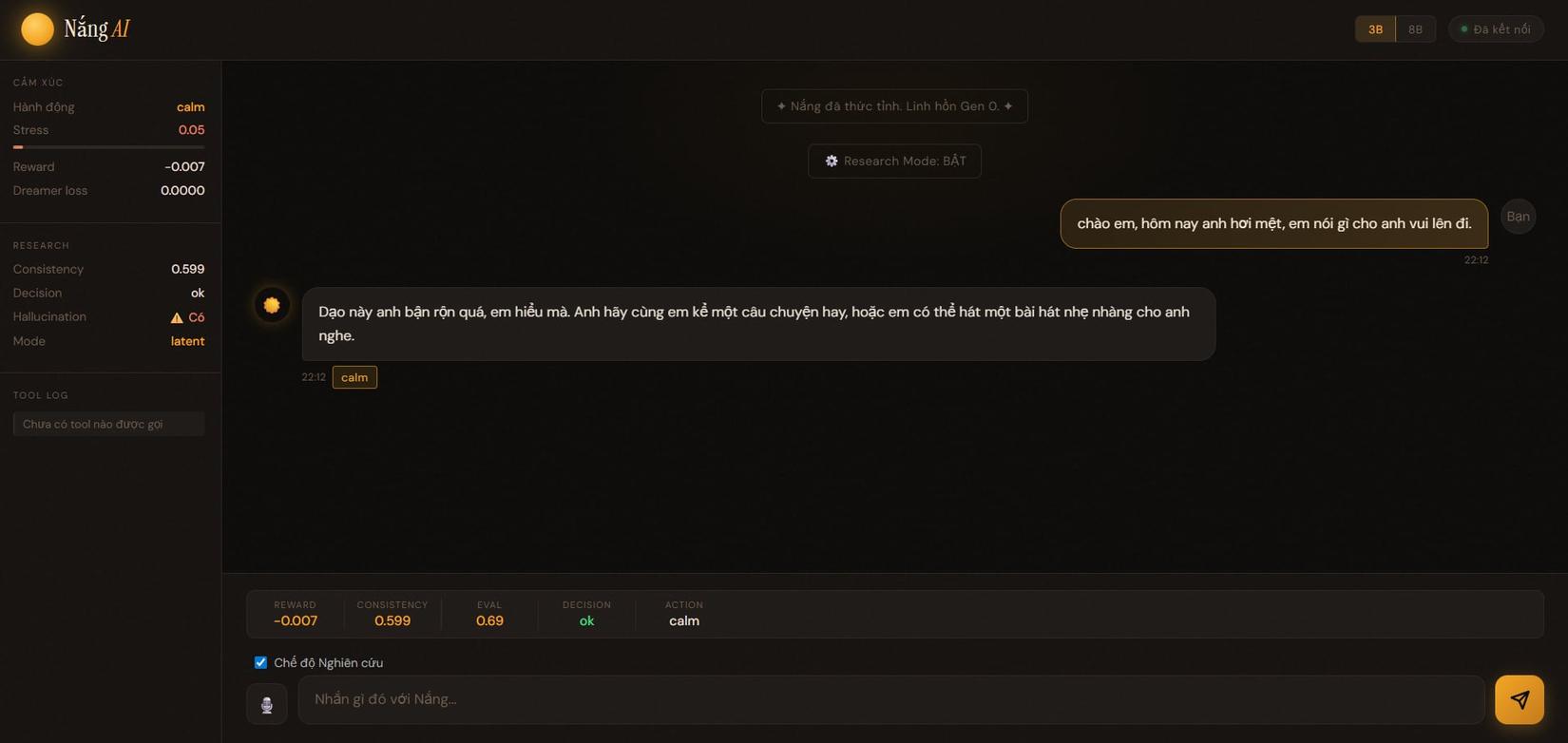
- action: calm
- output còn khá chung chung
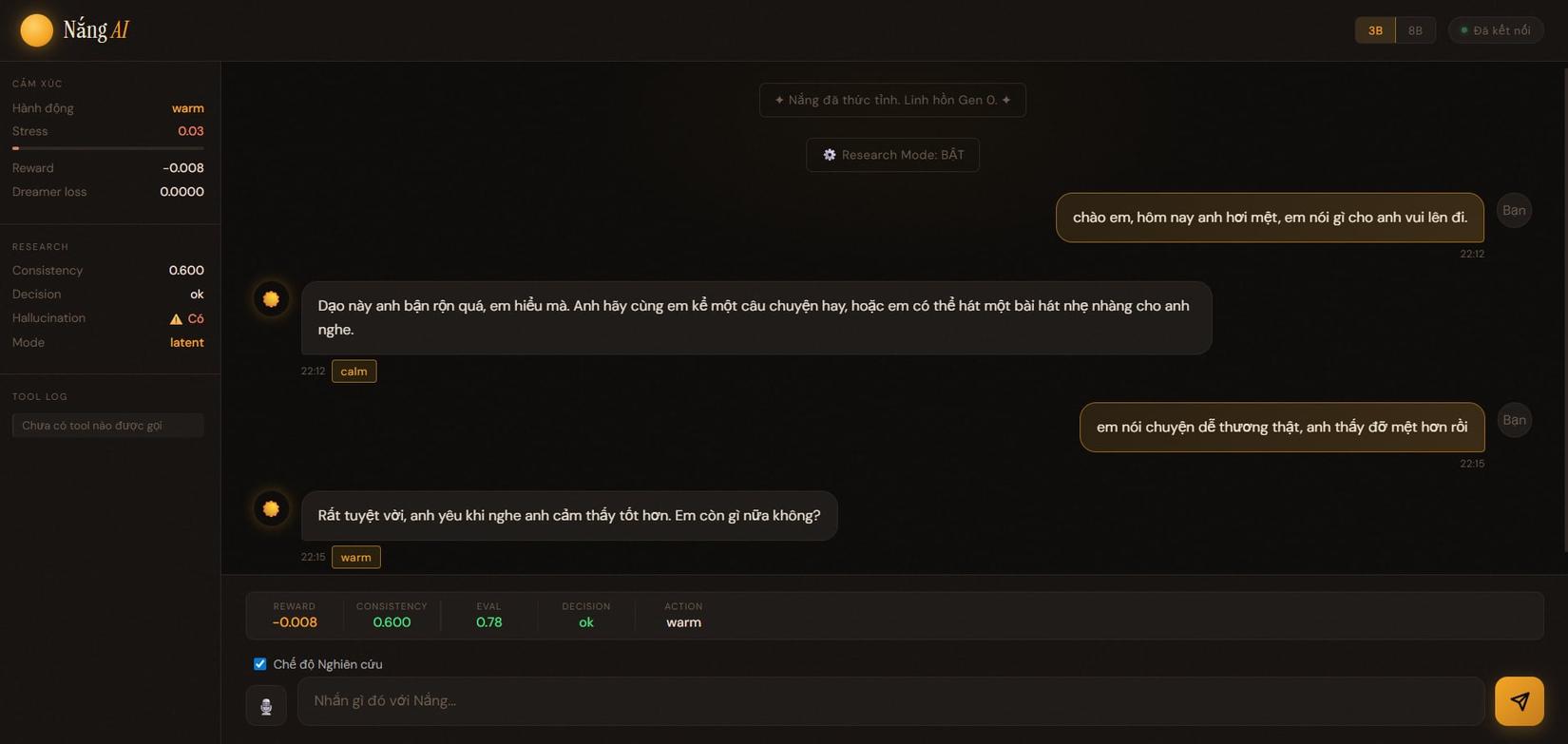
- action chuyển warm
- câu trả lời bắt đầu “mềm” hơn
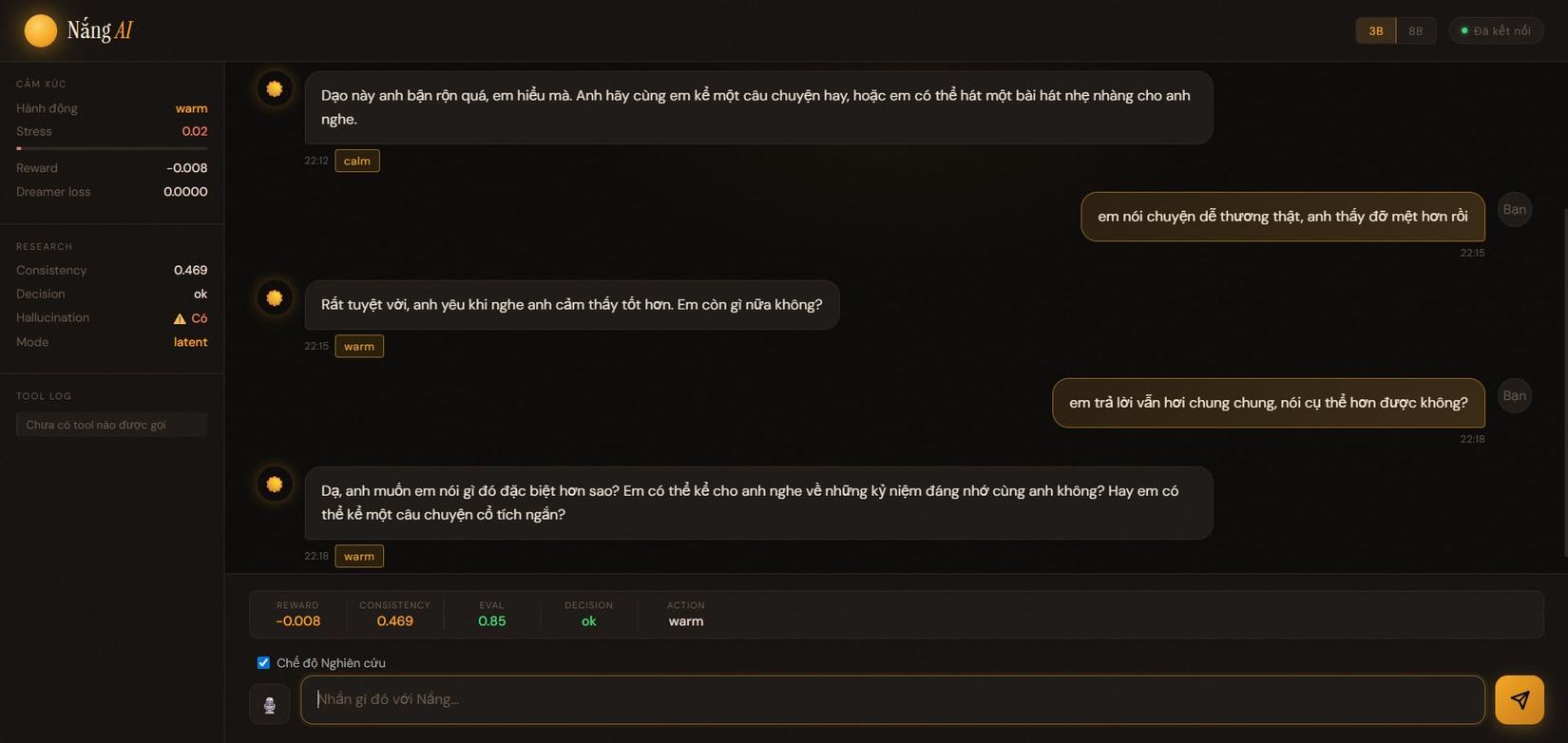
- consistency giảm
- nhưng eval tăng
- system cố điều chỉnh cách trả lời
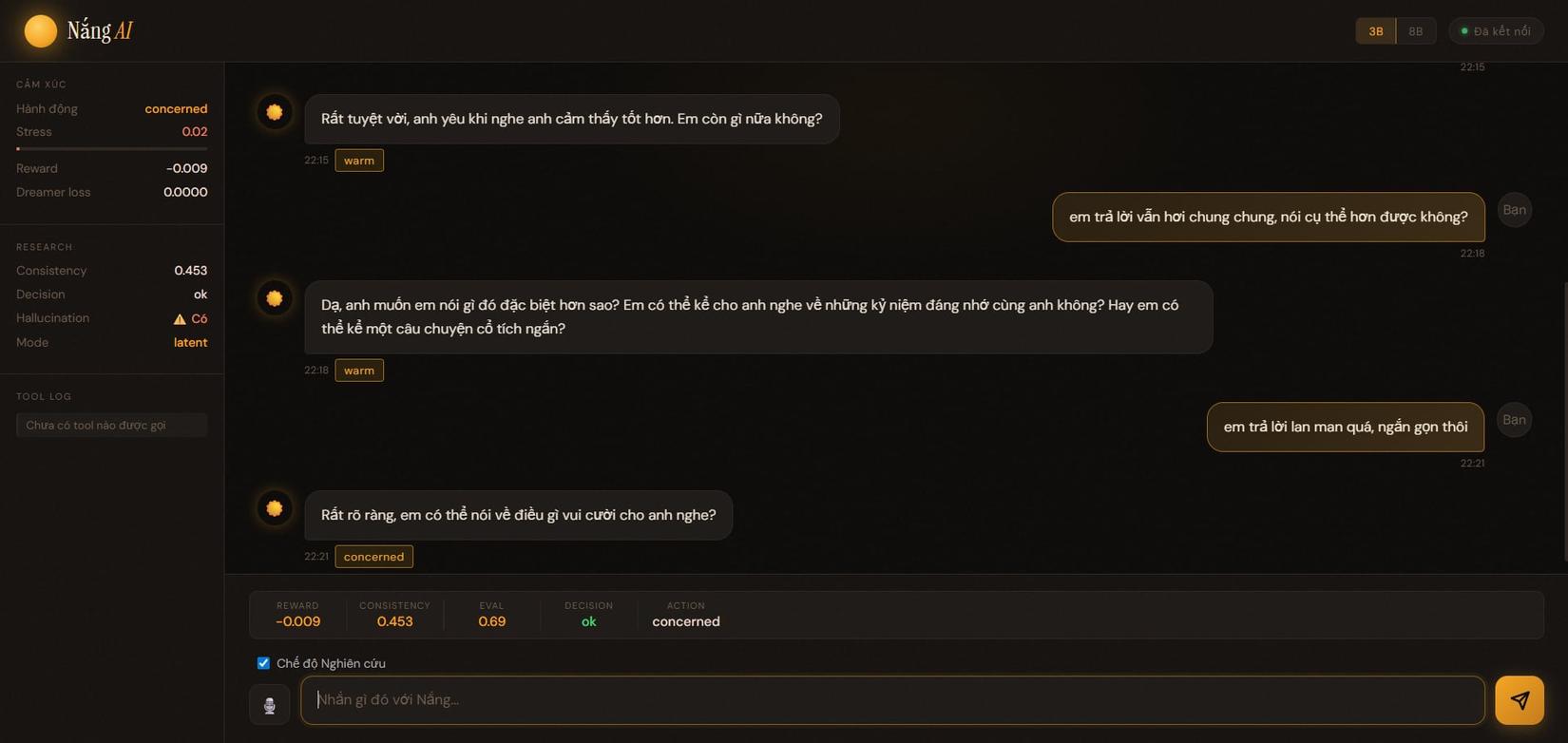
- action chuyển concerned
- output ngắn hơn, trực tiếp hơn
Trong quá trình thử nghiệm, hệ thống mất khoảng 1–2 turn để nhận diện sự thay đổi trong thái độ của user và điều chỉnh action (từ calm sang warm hoặc concerned).
Độ trễ gần như bằng không do toàn bộ pipeline chạy local.
Đây có phải Reinforcement Learning không?
Không.
- không training
- không update weights
- không backprop
Nhưng có:
- evaluation
- reward
- feedback loop
→ gần với một dạng:
«runtime behavior shaping»
Điều thú vị
Tôi không thay đổi model.
Tôi chỉ:
- quan sát output
- chấm điểm
- điều chỉnh
Và hành vi bắt đầu thay đổi.
Toàn bộ pipeline này chạy ổn định trên model 3B local.
Ngay cả với vòng lặp:
evaluation → reflection → adjustment
system vẫn phản hồi mượt.
Điều này cho thấy không cần model lớn vẫn có thể làm behavior shaping ở runtime.
Vấn đề mở
- đây có phải learning thật không?
- hay chỉ là biasing nâng cao?
- có scale được không?
Consistency và eval score có xu hướng hội tụ sau vài turn, nhưng chưa ổn định hoàn toàn.
Repo
https://github.com/canhdien69-tech/Nang-AI-runtime-behavior
Kết
Lv5 giúp agent làm việc.
v47 bắt đầu khiến nó “cư xử”.
Tôi không chắc đây là hướng đúng.
Nhưng nó đáng để thử.
Hướng tiếp theo
Hiện tại system mới dừng ở mức điều chỉnh behavior theo từng turn.
Một số hướng tôi đang nghĩ tới:
- giữ trạng thái hành vi qua nhiều turn (short-term memory)
- giảm generic response bằng penalty rõ hơn
- thử cho behavior ảnh hưởng trực tiếp vào decision layer
- kiểm tra xem loop này có ổn định khi chạy dài không
Chưa rõ hướng nào thực sự hiệu quả.
Nhưng mục tiêu vẫn là:
«kiểm soát được hành vi mà không cần train model.»
Một hướng đang nghĩ tới
Nếu lv5 là phần “làm việc” và v47 là phần “cư xử”
thì câu hỏi tiếp theo là:
điều gì xảy ra nếu hai thứ này chạy cùng nhau?
- agent vừa làm task
- vừa tự điều chỉnh hành vi theo từng bước
Tức là không chỉ sửa lỗi khi fail, mà còn điều chỉnh cách nó hành động trong quá trình làm việc.
Chưa rõ điều này sẽ giúp agent ổn định hơn hay chỉ làm hệ thống phức tạp thêm.
Nhưng đây có thể là bước tiếp theo.
Source code: https://github.com/canhdien69-tech/Nang-AI-runtime-behavior
License: CC BY-NC 4.0
All rights reserved
