Tìm hiểu về Microservices - Phần 3: Quản lý cơ sở dữ liệu trên Microservices
This post hasn't been updated for 3 years
Thiết kế và thao tác với cơ sở dữ liệu như thế nào luôn là một vấn đề vô cùng đau đầu khi bạn thực hiện một dự án Microservice. Ở bài viết này, mình sẽ phân tích các pattern cho thiết kế cơ sở dữ liệu cùng với ưu nhược điểm của chúng.
Hãy tưởng tượng, bạn xây dựng một hệ thống thương mại điện tử (viết thế cho oách) với Microservice Architecture. Ta cần có một cơ sở dữ liệu ở dạng như sau:
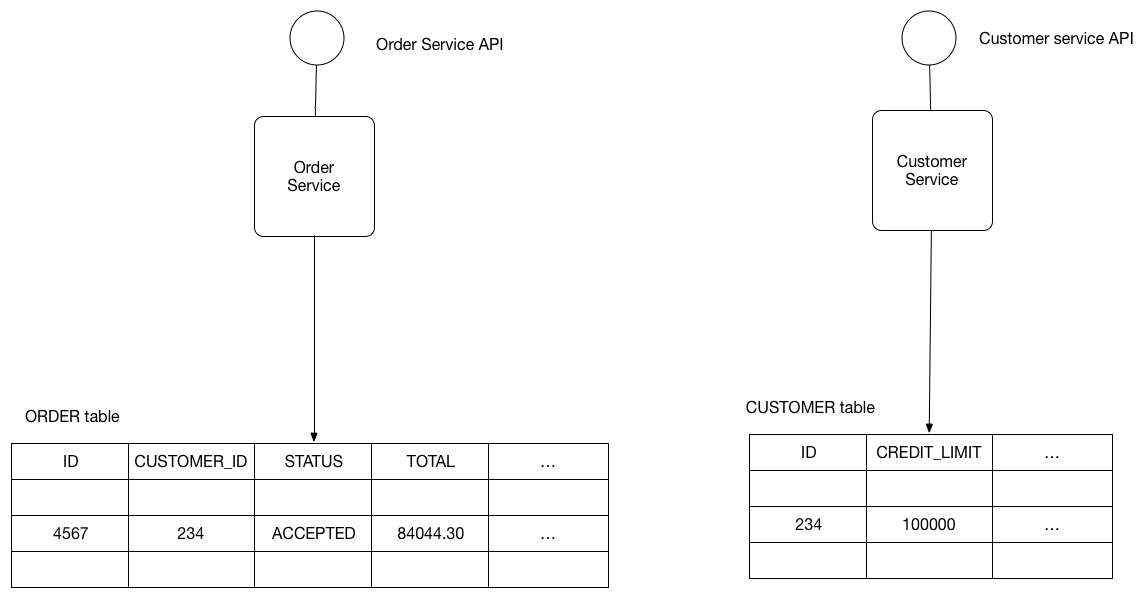
1. Yêu cầu
- Các services cần đảm bảo mối quan hệ lỏng lẻo để việc deploy, development và scale được độc lập.
- Một số business transactions cần truy vấn data thuộc sở hữu của các services khác nhau.
- Một số business transactions cần thực thi tính nhất quán và bất biến trên nhiều services. VD: Place Order cần xác minh rằng đơn hàng mới sẽ không vượt quá giới hạn tín dụng của khách hàng. Một số business transactions khác, phải cập nhật data thuộc sở hữu của của các services khác nhau.
- Một số queries cần join data thuộc sở hữu của các services khác nhau.
- Database đôi khi phải được nhân rộng hoặc phân chia để mở rộng quy mô.
- Các services khác nhau có yêu cầu lưu trữ dữ liệu khác nhau. Đối với một số services, SQL là sự lựa chọn tốt nhất. Các services khác có thể cần một cơ sở dữ liệu NoSQL như MongoDB.
2. Shared database
Đây là dạng một Database được chia sẻ cho nhiều services. Các services được tự do truy cập các bảng của nhau để đảm bảo ACID transaction.
Ví dụ: OrderService và CustomerService tự do truy cập các bảng của nhau. OrderService có thể sử dụng ACID transaction sau để đảm bảo rằng một đơn đặt hàng mới sẽ không vi phạm giới hạn tín dụng của khách hàng.
BEGIN TRANSACTION
…
SELECT ORDER_TOTAL
FROM ORDERS WHERE CUSTOMER_ID = ?
…
SELECT CREDIT_LIMIT
FROM CUSTOMERS WHERE CUSTOMER_ID = ?
…
INSERT INTO ORDERS …
…
COMMIT TRANSACTION
Lợi ích
- Một single database là đơn giản hơn để hoạt động.
- Các developers dễ dàng sử dụng ACID transaction để thực thi tính nhất quán dữ liệu.
Hạn chế
- Development time coupling. Ví dụ: Sự thay đổi schema của DB sẽ gây ảnh hưởng đến nhiều services do chúng truy cập trực tiếp vào các tables, và trong khi các lập trình viên cho mỗi service là khác nhau thì rõ ràng coupling này làm chậm quá trình development.
- Runtime coupling: tất cả các services truy cập vào cùng một cơ sở dữ liệu, chúng có khả năng can thiệp lẫn nhau. Ví dụ: nếu một CustomerService transaction chạy mất nhiều thời gian và lock ORDER table thì OrderService sẽ bị chặn.
- Thực tế đối với các hệ thống lớn, một DB đơn lẻ không thể đáp ứng đủ yêu cầu về lưu trữ và truy cập dữ liệu của tất cả các services.
3. Database per service
Đây là dạng Database giành riêng cho mỗi serivce. Các services khác nếu muốn thao tác với DB này thì cần phải thông qua API của service quản lý DB đó.
Với ví dụ ban đầu, ta có sơ đồ cho cấu trúc của pattern này như sau:
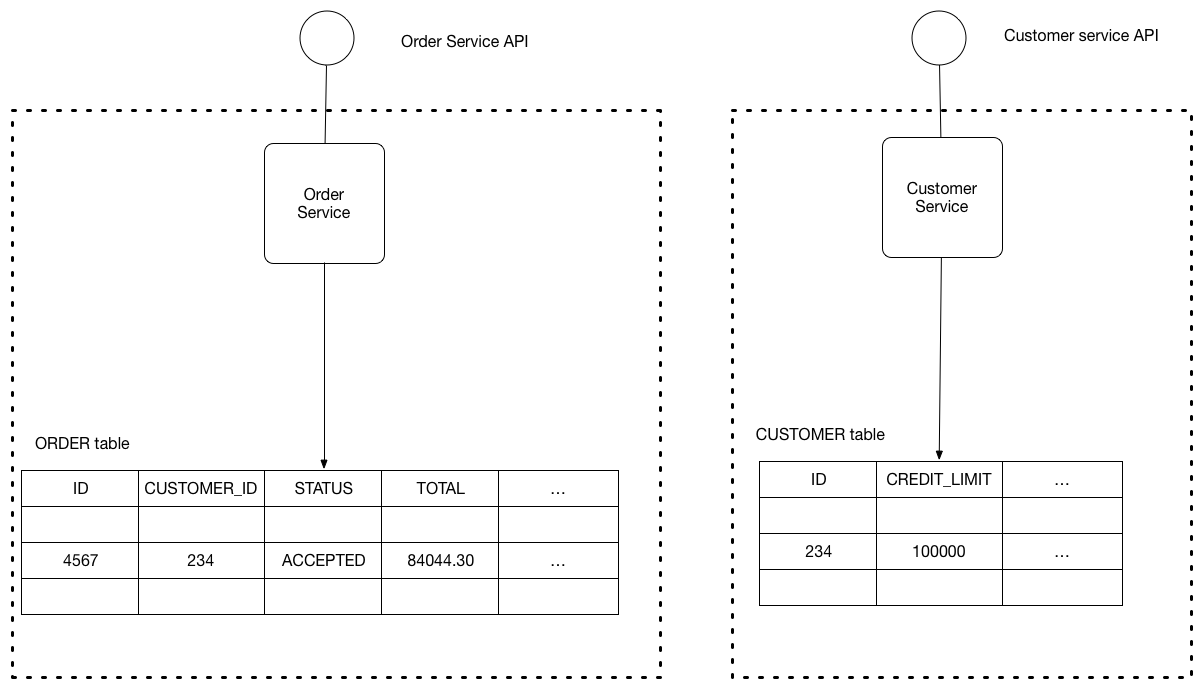
Cơ sở dữ liệu của service là một phần của việc triển khai service đó. Nó không thể được truy cập trực tiếp bởi các services khác.
Có một số cách khác nhau để giữ DB của mỗi service là private. Bạn không cần phải cung cấp một máy chủ cơ sở dữ liệu cho mỗi service. Ví dụ đối với SQL:
- Private-tables-per-service: mỗi service sở hữu một tập các tables chỉ được truy cập bởi services đó.
- Schema-per-service: mỗi service có một schema riêng tư với service đó.
- Database-server-per-service: mỗi service có một database server riêng.
Private-tables-per-service và Schema-per-service sẽ có chi phí thấp nhất và việc sử dụng Schema-per-service là tốt hơn vì nó làm cho quyền sở hữu trở nên rõ ràng. Trong khi đó, một số services có lượng truy cập cao sẽ cần có database server của riêng nó (Database-server-per-service).
Lợi ích
- Giúp đảm bảo rằng các services được kết nối lỏng lẻo. Việc thay đổi cơ sở dữ liệu của một service không làm ảnh hưởng đến bất kỳ services nào khác.
- Mỗi dịch vụ có thể sử dụng loại cơ sở dữ liệu phù hợp nhất với nhu cầu của nó. Ví dụ: service tìm kiếm có thể sử dụng ElasticSearch. Trong khi đó các services khác có thể sử dụng MySQL, MongoDB hay Neo4j,...
Hạn chế
- Việc thực hiện các transaction trải rộng trên nhiều serivces không đơn giản. Các transaction phân tán nên được hạn chế vì định lý CAP. Hơn nữa, nhiều cơ sở dữ liệu hiện đại (NoSQL) không hỗ trợ chúng.
- Việc thực hiện các queries cần join data có trong nhiều cơ sở dữ liệu là một thách thức.
- Sự phức tạp của việc quản lý nhiều cơ sở dữ liệu SQL và NoSQL.
Có nhiều patterns/solutions khác nhau để giải quyết bài toán query và transaction trên nhiều services:
- Để thực hiện transaction trên nhiều services ta có thể sử dụng Saga pattern.
- Để thực hiện query trên nhiều serivces ta có thể sử dụng: API Composition hoặc Command Query Responsibility Segregation (CQRS)
4. Saga pattern
Đối với các hệ thống lựa chọn mô hình Database per Service, mỗi service sẽ có một Database riêng. Tuy nhiên một số transaction cần trải rộng trên nhiều serivces. Bạn cần một cơ chế để đảm báo tính thống nhất của dữ liệu trên các serivces.
Giải pháp được đưa ra như sau: Ta sẽ coi mỗi một transaction trải rộng trên nhiều services là một Saga. Và mỗi một Saga là một chuỗi các transaction cục bộ trên từng serivce khác nhau. Nếu một transaction cục bộ thất bại thì Saga sẽ thực hiện một loạt các transactions để rollback lại các thay đổi đã được thực hiện trước đó.
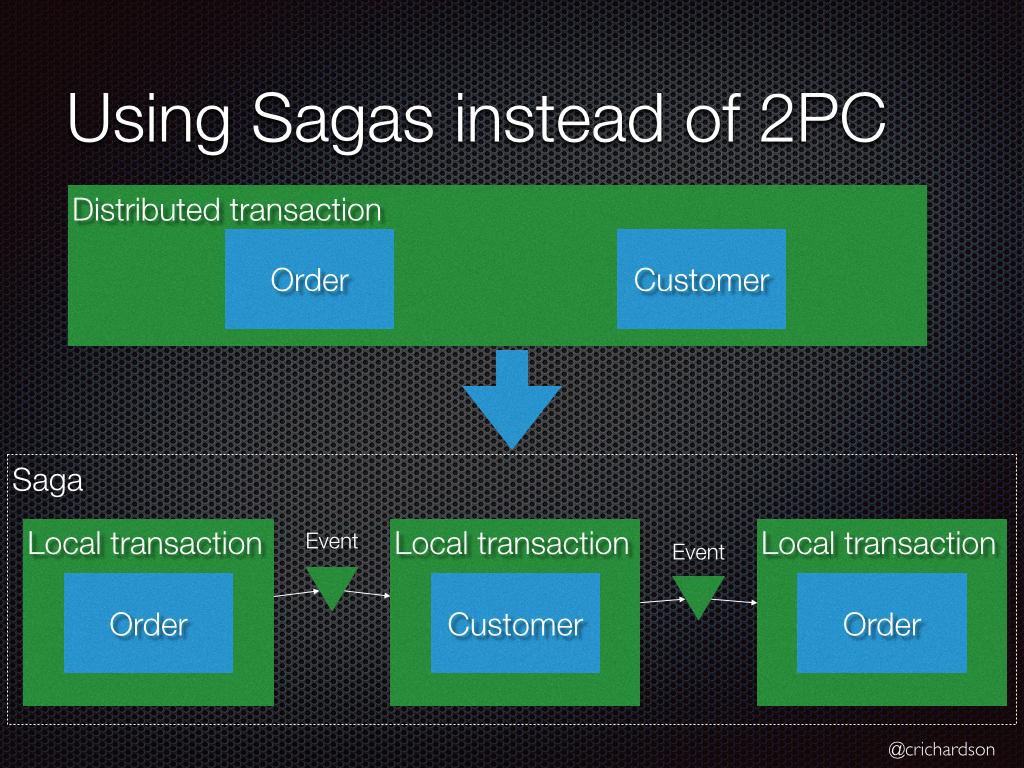
Có 2 cách để triển khai Saga.
a. Events/Choreography-based saga
Service đầu tiên thực hiện transaction và sau đó publish một event. Event này được lắng nghe bởi một hoặc nhiều services thực hiện các transactions cục bộ và publish (hoặc không) các event mới.
Transaction phân tán kết thúc khi service cuối cùng thực hiện transaction cục bộ của nó và không publish bất kỳ event nào hoặc event được publish không được nghe thấy bởi bất kỳ services nào của saga.
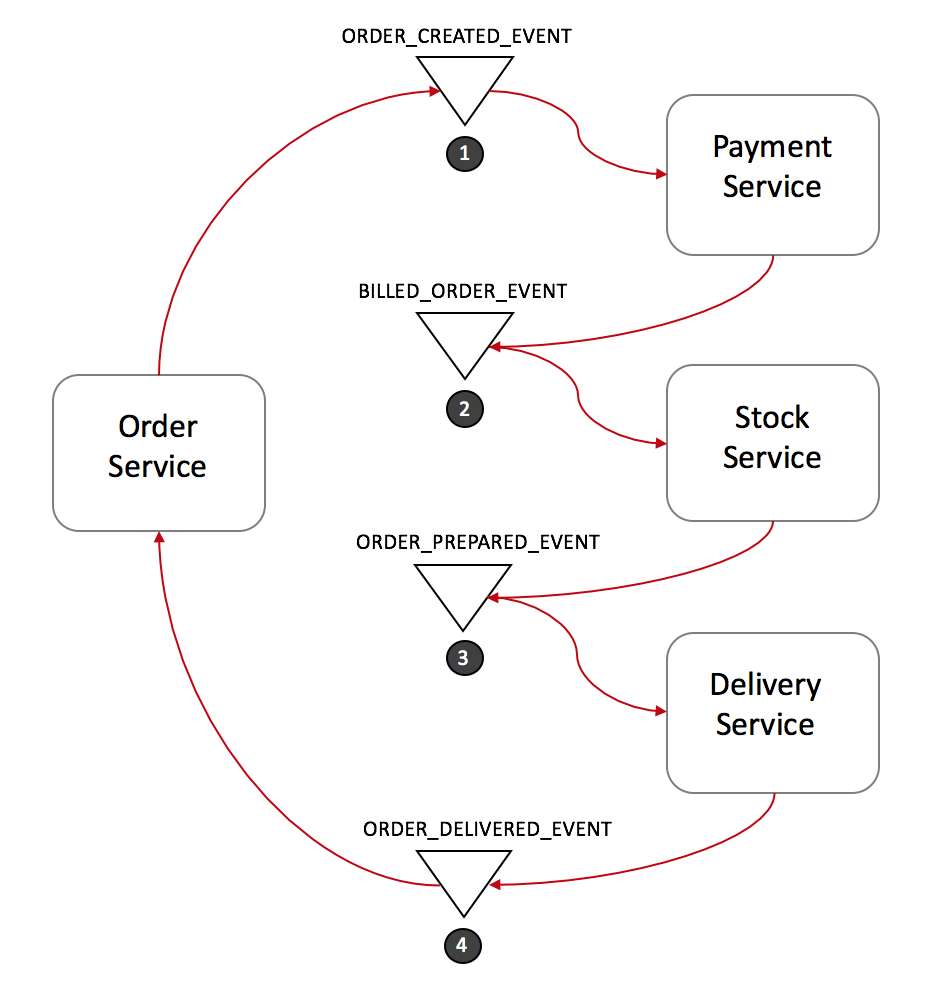
Trong ví dụ này, hệ thống thương mại điện tử sẽ tạo ra đơn đặt hàng như sau:
- Order Service sẽ tạo ra một đơn hàng ở trạng thái pending và gửi đi ORDER_CREATED_EVENT.
- Payment Service lắng nghe ORDER_CREATED_EVENT, trừ tiền của khách hàng và gửi đi BILLED_ORDER_EVENT.
- Stock Service lắng nghe BILLED_ORDER_EVENT, cập nhật lại stock, chuẩn bị các sản phẩm và gửi đi ORDER_PREPARED_EVENT.
- Delivery Service lắng nghe ORDER_PREPARED_EVENT, sau đó nhận và giao sản phẩm. Cuối cùng nó gửi đi ORDER_DELIVERED_EVENT.
- Order Service lắng nghe ORDER_DELIVERED_EVENT và đặt lại trạng thái của đơn hàng.
Trong trường hợp trạng thái của đơn hàng cần cập nhật liên tục thì Order Service sẽ lắng nghe tất cả các sự kiện và cập nhật trạng thái cho đơn hàng.
Trong trường hợp có một lỗi xảy ra trong chuỗi transaction cục bộ. Bạn phải rollback những gì đã thay đổi.
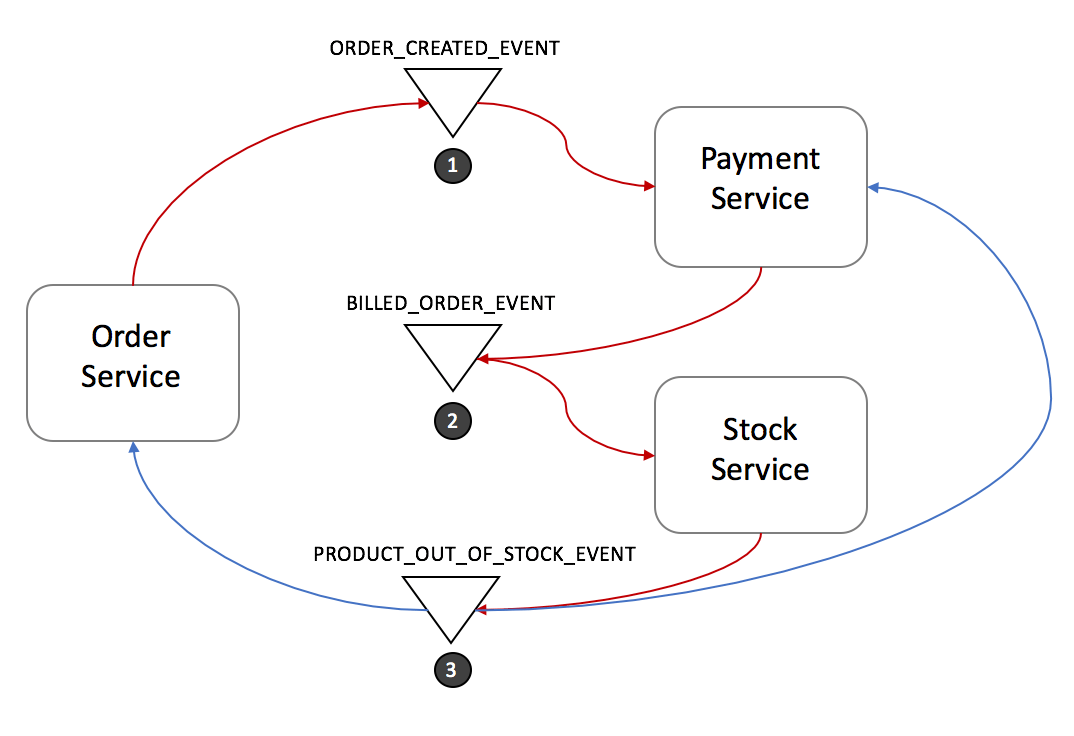
Ví dụ một lỗi ở Stock Service:
- Stock Service sẽ gửi đi PRODUCT_OUT_OF_STOCK_EVENT.
- Order Service và Payment Service lắng nghe PRODUCT_OUT_OF_STOCK_EVENT: Payment Service hoàn trả tiền cho khách hàng còn Order Service cập nhật trạng thái đơn hàng là không thành công.
Mô hình này thực sự rất dễ hiểu và các services có sự kết nối là vô cùng lỏng lẻo. Nếu transaction của bạn chỉ có từ 2 đến 4 bước thì đây sẽ là sự lựa chọn tuyệt vời. Tuy nhiên, chúng sẽ trở nên khó khăn khi bạn muốn bổ sung, mở rộng transaction. Nó cũng gây khó khăn cho testing vì bạn phải chạy tất cả các services.
b. Command/Orchestration-based saga
Sẽ có một service mới chịu trách nhiệm điều phối các logic của Saga. Nó chịu trách nhiệm duy nhất là nói cho mỗi service phải làm gì và khi nào. Saga service giao tiếp với từng service theo kiểu command/reply để cho chúng biết thực hiện thao tác nào.
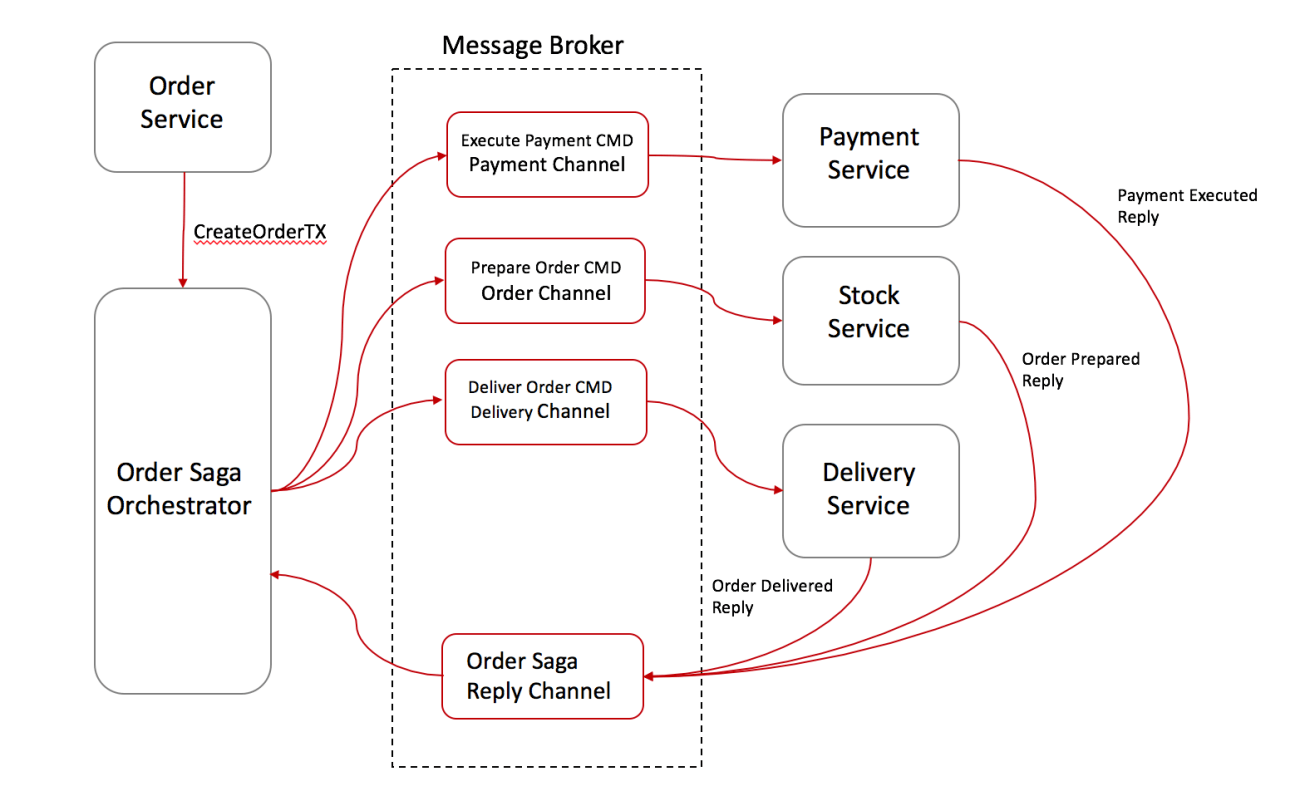
Trong ví dụ này, hãy cùng tìm hiểu cách mà hệ thống thương mại điển tự hoạt đông với Command/Orchestration:
- Order Service tạo ra một đơn hàng ở trạng thái pending và yêu cầu Order Saga Orchestrator (OSO) bắt đầu một order transaction.
- OSO gửi lệnh Execute Payment đến Payment Service, và Payment Service trả lời bằng tin nhắn Payment Executed đối với Oder Saga Reply Channel.
- OSO gửi lệnh Prepare Order đến Stock Service, và Stock Service trả lời bằng message Order Prepared.
- OSO gửi lệnh Deliver Order đến Delivery Service, và nhận lại Order Delivered message.
Việc rollback lại Saga trở nên dễ dàng hơn nhiều khi bạn có một Orchestration điều khiển mọi thứ:
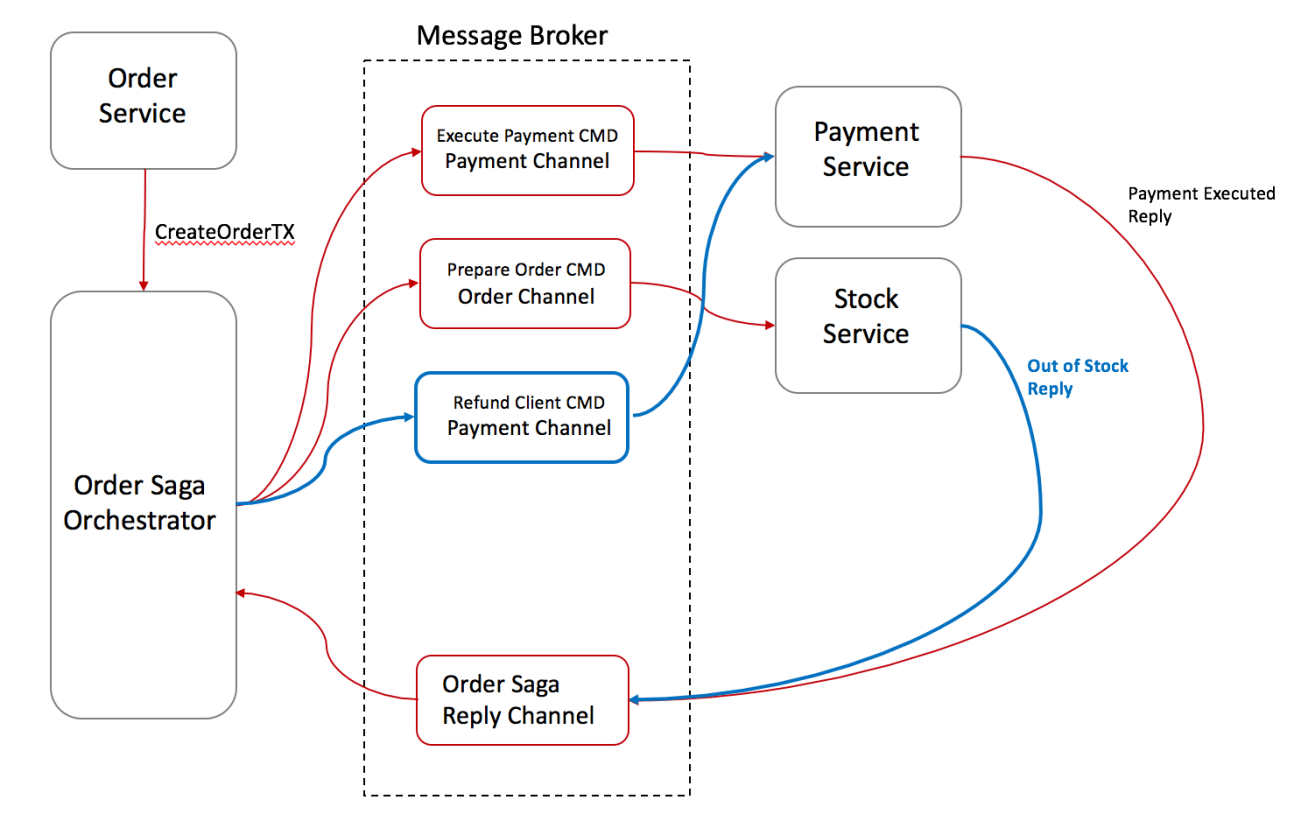
- Stock Service gửi cho OSO một Out-Of-Stock message;
- OSO nhận ra rằng transaction thất bại và bắt đầu rollback. Trong trường hợp này chỉ một thao tác duy nhất được thực hiện thành công trước khi thất bại, nên OSO sẽ gửi lệnh Refund Client đến Payment Service và đặt trạng thái của đơn hàng là không thành công.
Rõ ràng cách tiếp cận này là tốt hơn vì nó tập trung vào việc điều phối các transactions phân tán, làm giảm sự phức tạp của các services vì chúng chỉ cần quan tâm execute/reply các lệnh. Chúng cũng làm việc implement, testing hay quản lý rollback trở nên dễ dàng hơn. Đồng thời làm giảm độ phức tạp khi bạn muốn thêm các steps mới vào transaction.
Chúng ta đã tìm hiểu xem cách thiết kế và thao tác với cơ sở dữ liệu đối với một hệ thống áp dụng microservices architecture. Hi vọng bài viết này sẽ giúp các bạn có cái nhìn tổng quan cũng như hiểu hơn về cách hoạt động của các hệ thống microservices.
All Rights Reserved
