
Tìm hiểu về giải pháp Digital Humans phần 3: Tìm hiểu về Digital Humans trong thực tế
Bài đăng này đã không được cập nhật trong 2 năm
Giới thiệu chung về digital Human
Digital Human hay còn gọi là nhân vật ảo, đã và đang trở thành một xu hướng quan trọng trong lĩnh vực AI và công nghệ thông tin. Đây là những nhân vật được tạo ra hoàn toàn bằng kỹ thuật số có khả năng tương tác giống như con người. Trong năm qua, sự kết hợp giữa AI Avatar và các mô hình ngôn ngữ lớn (LLMs) đã mở ra khả năng mới cho việc tạo ra các avatar AI không chỉ mang lại trải nghiệm mới mẻ và thú vị mà còn mở ra nhiều cơ hội trong nhiều lĩnh vực, từ giáo dục, giải trí đến dịch vụ khách hàng và marketing.
Ứng dụng
Một Digital Human không chỉ dừng lại ở việc biểu đạt mà còn có khả năng tư duy và tương tác với môi trường xung quanh. Digital Human có thể được sử dụng trong nhiều lĩnh vực khác nhau như giải trí, giáo dục, chăm sóc khách hàng,... Ví dụ, chúng có thể làm người dẫn chương trình, giáo viên ảo, trợ lý ảo hoặc bạn đồng hành trong các trò chơi điện tử. Thậm trí tái hiện những người thân đã khuất 🙂

Mọi người có thể tham khảo thêm các usecase tại đây
Phân Loại
Dựa trên nguyên lý hoạt động, Digital Human có thể được chia thành 2 loại :
-
Digital Human không tương tác: Ở dạng này, hệ thống sẽ tạo ra âm thanh và video của nhân vật dựa trên kịch bản và văn bản có sẵn, sau đó hợp nhất chúng để hiển thị cho người dùng. Ví dụ như tổng hợp video cho các bài giảng online.
-
Digital Human có tương tác: Tại đây, phần tương tác trực tiếp với người dùng yêu cầu phản hồi theo thời gian thực, vì thế nguyên lý hoạt động cũng có phần khác và có thể yêu cầu tích hợp cả LLM để cho ra phản hồi tốt nhất.
Ngoài ra, chúng ta cũng có thể phân loại con người kỹ thuật số dựa trên cách thể hiện nhân vật với người dùng. Các loại chính bao gồm:
- nhân vật 2D
- nhân vật 3D
- 3D có độ thực cao
- hình ảnh người thật

Mỗi loại biểu diễn nhân vật đều sử dụng các kỹ thuật khác nhau để mang lại trải nghiệm vô cùng độc đáo và sống động. Hãy cùng mình khám phá một số loại nhân vật tiêu biểu nhé:






Triển khai digital Human
Trong bài viết này, mình sẽ trình bày cách tạo ra một digital Human có khả năng tương tác theo thời gian thực với hình ảnh người thật. Mô hình được sử dụng là ER-NeRF, phát triển dựa trên ý tưởng kết xuất của NeRF, kết hợp thêm các đặc trưng âm thanh để điều khiển khuôn mặt có thể nói chuyện, đặc biệt là phần cử động miệng.
Dưới đây là sơ đồ hoạt động của hệ thống:
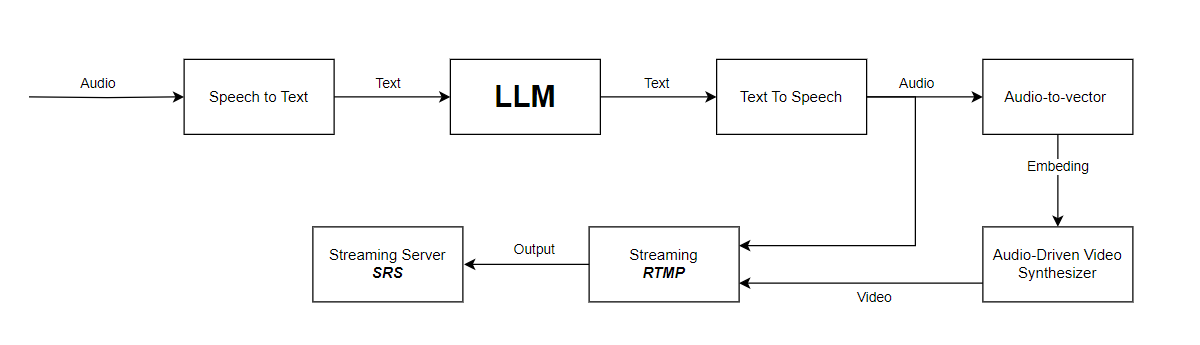
Mô-đun chuyển Audio thành Văn Bản (Speech-to-Text)
Âm thanh đầu vào sẽ được xử lý qua một dịch vụ chuyển đổi giọng nói thành văn bản (STT - Speech to Text), biến âm thanh thành văn bản.
Xử Lý câu trả lời (LLM)
Văn bản sau đó sẽ được chuyển vào một mô hình ngôn ngữ lớn (LLM) hoặc một API chatbot cụ thể để lấy câu trả lời.
Nếu câu trả lời của LLM quá dài, điều này có thể ảnh hưởng đến tốc độ phản hồi của quá trình. Do đó, chúng ta có thể thêm một bước xử lý để rút gọn văn bản trước khi đưa vào mô-đun chuyển văn bản thành giọng nói (TTS - Text to Speech), trong khi câu trả lời đầy đủ vẫn sẽ được in ra màn hình.
Mô-đun Text-to-Speech (TTS)
Ở đây mình sử dụng ViXTTS( một mô hình mình rất thích, nó có khả năng sao chép cực nhanh giọng nói của bất cứ ai chỉ với một đoạn âm thanh 15s). Chất lượng giọng cũng tương đối tốt, cũng có sẵn code stream audio từ tác giả coqui 😁
Tuy nhiên bạn có thể thay thế bằng mô-đun TTS khác như OpenAI-TTS, FPT-TTS,... để giảm độ trễ và sử dụng thêm các mô hình clone âm thanh để digital human trở nên thực tế hơn.
Trích Xuất đặc trưng Âm Thanh (Audio-to-Vector)
Mô hình wav2vec được sử dụng để trích xuất các đặc trưng âm thanh, chuyển âm thanh thành các vector nhúng (embedding). Wav2vec cũng được dùng để trích xuất các đặc trưng âm thanh khi đào tạo mô hình ER-NeRF, giúp mô hình tạo ra hình ảnh tương ứng với hình dạng miệng dựa trên các đặc điểm âm thanh đầu vào.
Tổng hợp video (Audio-Driven Video Synthesizer)
Ở đây mình sử dụng ER-NeRF, một mô hình tổng hợp chân dung nói chuyện với độ chân thực cao, cách hoạt động cũng tương tự như RAD-NeRF nhưng cho kết quả tốt hơn. Mọi người có thể tham khảo ở đây, hoặc đọc về RAD-NeRF ở phần 2 😆
Streaming
Sau khi đã tổng hợp được phần âm thanh và từng khung hình, bước tiếp theo là đẩy chúng sao cho đồng bộ để tạo thành một luồng stream hoàn chỉnh. Điều này rất quan trọng để đảm bảo trải nghiệm người dùng mượt mà. Hãy chú ý đến thời gian thừa giữa các khung hình, đặc biệt nếu bạn sử dụng card đồ họa mạnh🤑. Ví dụ, với tốc độ khung hình là 25 khung hình/giây thì mỗi khung hình sẽ tương ứng với 40ms. Nếu quá trình sinh ảnh mất 25ms, bạn sẽ cần gọi time.sleep(0.015) để chờ đúng 15ms còn lại.
Cuối cùng, bạn cần đẩy link stream lên một server stream. Có nhiều lựa chọn như SRS (Simple Realtime Server) hoặc sử dụng OBS.
Xử lý khi không có đầu vào: Khi không có đầu vào văn bản, một chuỗi âm thanh toàn số 0 sẽ được nhập vào để điều khiển hình dạng miệng và duy trì tính liên tục của video stream.
Như vậy với các bước trên, bạn có thể tạo ra một digital human có khả năng tương tác theo thời gian thực, mang lại trải nghiệm người dùng chân thực và sống động. Hy vọng bài viết này sẽ giúp bạn hiểu rõ hơn digital human.
Kết Luận
Để có thể xây dựng một Digital human tốt đòi hỏi rất nhiều yếu tố từ việc chuẩn bị data đến việc kết hợp nhiều kỹ thuật một lúc. Nhưng kết quả rất tuyệt với, hệ thống này mang lại nhiều trải nghiệm mới lạ cho người dùng. Đồng thời đây cũng là một lĩnh vực đầy tiềm năng và thú vị, mở ra nhiều cơ hội mới trong việc ứng dụng công nghệ vào cuộc sống.
Nếu bạn có bất kỳ thắc mắc hay cần thêm thông tin, đừng ngần ngại để lại bình luận bên dưới nha. Cảm ơn bạn đã đọc tới đây 😆😆. Nếu thấy bài viết có ích, đừng quên cho mình một upvate nha ❤️❤️
Reference
https://www.linkedin.com/pulse/rise-ai-video-avatars-david-cronshaw-9cxpf/
All rights reserved
