Tìm hiểu về cơ chế Attention
Bài đăng này đã không được cập nhật trong 5 năm
Giới thiệu chung
Sự ra đời của cơ chế Attention (Attention Mechanism) trong học sâu đã mang lại hiệu quả đáng kể cho nhiều mô hình, nó đã và đang tiếp tục là một thành phần không thể thiếu trong các mô hình tiến tiến nhất. Vì lí do đó để làm việc và áp dụng hiểu quả cơ chế này, việc hiểu và "pay attention" đến cơ chế attention là điều vô cùng quan trọng.
Trước khi đi vào cơ chế attention thì chúng ta cần tìm hiểu tại sao cơ chế này lại ra đời, cụ thể hơn là trong bài toán dịch máy (NMT). Ta thường sử dụng mô hình seq2seq với hai thành phần là khối encoder và decoder, với nhiệm vụ từ một chuỗi ban đầu ở ngôn ngữ này tạo ra chuỗi đích ở ngôn ngữ khác. Hai khối này đều được tạo thành từ các lớp RNN. Khối Encoder sẽ xử lí thông tin đầu vào và đầu ra là một vector biểu diễn duy nhất, hay còn gọi quá trình này là nén thông tin. Vector biểu diễn này sẽ mang toàn bộ thông tin để khối Decoder có thể tạo ra câu đích. Thực tế, mô hình seq2seq bới kiến trúc từ RNN hoạt động rất tốt đối với các chuỗi có đồ dài ngắn, khi độ dài chuỗi tăng thì chất lượng của mô hình sẽ giảm đáng kể
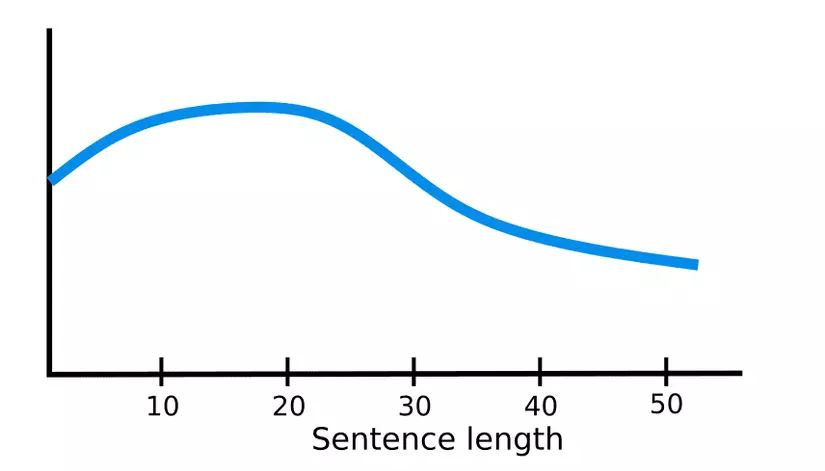
Lí do là bởi đối với chuỗi dài thì RNN gặp phải 2 vấn đề là hiện tượng tiêu biến gradient (vanishing gradient) và bùng nổ gradient (exploding gradient). LSTM mặc dù đã được ra đời từ rất lâu nhưng lại có thể khắc phục được nhược điểm của RNN. Mặc dù vậy, đúng như định lý Murphy
"Mọi giải pháp đều tạo nên vấn đề mới"

Việc sử dụng LSTM có những hạn chế sau:
- Khó huấn luyện, thời gian huấn luyện lâu do gradient path rất dài (chuỗi 100 từ có gradient như là mạng 100 lớp)
- Transfer learning không hoạt động với LSTM, điều đồng nghĩa với một bài toán mới thì ta cần huần luyện lại mô hình với bộ dữ liệu riêng biệt cho nhiệm vụ đề ra (tốn kém)
Quay lại mô hình seq2seq với RNN thì như vậy, encoder sẽ phải "nén" toàn bộ chuỗi đầu vào thành một vector duy nhất - việc này rất khó, khi mà chuỗi đủ dài và encoder buộc phải đưa toàn bộ thông tin vào 1 vector biểu diễn duy nhất này thì chắc chắn nó sẽ "quên" thông tin nào đó (bottleneck)! Ngoài ra, decoder chỉ nhìn thấy một vector biểu diễn đầu vào duy nhất, mặc dù tại mỗi time-step thì các phần khác nhau của chuỗi vào có thể có ích hơn các phần khác. Nhưng đối với mô hình hiện tại thì decoder sẽ phải trích các thông tin liên quan này từ một vector biểu diễn duy nhất - việc này cũng vô cùng khó.
Attention đã được ra đời vào năm 2015 Bahdanau2015 với mục đích giải quyết vấn đề kể trên. Với cơ chế này, tại mỗi time-step khác nhau, mô hinh sẽ tập trung vào các phần khác nhau của đầu vào.
Cơ chế Attention cho mô hình seq2seq
Như vậy cơ chế attention được ra đời để giải quyết các vấn đề của mô hình seq2seq (transformer và cơ chế attention ra đời để thay cho seq2seq không cần đến các mạng nơ-ron hồi tiếp) , với ý tưởng sử dụng một vector bối cảnh có thể tương tác với toàn bộ vector trạng thái ẩn của encoder thay vì chỉ sử dụng vector trạng thái ẩn cuối cùng để tạo ra vector biểu diễn cho decoder. Cụ thể hơn, mô hình seq2seq khi áp dụng cơ chế attention vào sẽ có cấu trúc như sau (các khối màu xanh dương là encoder, màu đỏ là decoder):
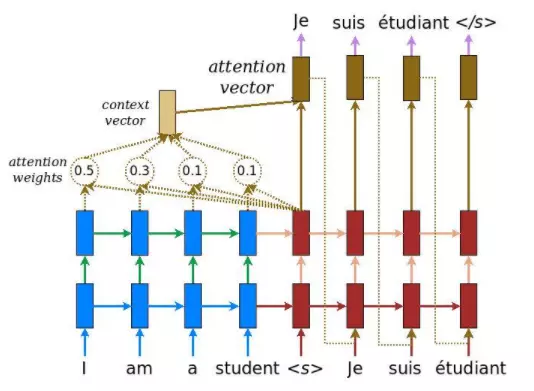
Chi tiết các bước, tại mỗi time-step ở phía decoder:
- Bước 1: Nhận vector trạng thái ẩn của decoder và tất cả các vector trạng thái ẩn của encoder
- Bước 2: Tính điểm attention. Với mỗi vector trạng thái ẩn của encoder thì ta cần tính điểm thể hiện sự liên quan với vector trạng thái ẩn của decoder. Cụ thể, ta sẽ áp dụng một phương trình tính điểm "attention" với đầu vào là vector trạng thái ẩn decoder - và một vector trạng thái ẩn của encoder - và trả về một giá trị vô hướng .
- Bước 3: Tính trọng số attention. Áp dụng hàm softmax với đầu vào là điểm attention
- Bước 4: Tính toán vector bối cảnh là tổng của các trọng số attention nhân với vector trạng thái ẩn của decoder tại time-step tương ứng
Cuối cùng, các vector attention dùng để đưa ra đầu ra được tính dựa trên vector bối cảnh và vector trạng thái ẩn ở decoder .
Ý tưởng chính của cơ chế là một mạng của thể học được rằng tại mỗi time-step thì phần vào của đầu vào quan trọng. Mô hình với cơ chế attention có thể được huấn luyện end-to-end mà không cần phải chỉ định mô hình chọn từ nào - chính mô hình sẽ tự học để làm điều đó!
Các loại cơ chế Attention
Sự ra đời của cơ chế attention đã loại bỏ sự phục thuộc về khoảng cách của chuỗi đầu vào và đầu ra. Với attention thì lĩnh vực dịch máy đã có nhiều cải tiến đáng kể, ngày càng có nhiều các dạng khác nhau của cơ chế attention Dưới đây là một vài cơ chế attention cũng với hàm tính score:
| Tên | Hàm tính score | Trích dẫn |
|---|---|---|
| Content-base attention | Graves2014 | |
| Additive | Bahdanau2015 | |
| Dot-Product | Luong2015 | |
| General | Luong2015 |
Rộng hơn thì các cơ chế attention được chia thành 3 loại sau
- Self-attention
- Global/Soft attention
- Local/Hard attention
Self-Attention
Self-attention hay còn biết đến là intra-attention, là một cơ chế attention chỉ dùng cho một câu. Có thể hiểu rằng ta sẽ tự tạo một ma trận với hàng và cột đều là cùng một câu để hiểu được những phần nào của câu sẽ liên quan đến nhau. Cơ chế này đã chứng minh được sự hiệu quả trong các ứng dụng tóm tắt văn bản, tạo caption cho hình ảnh, đọc máy... Cùng với self-attention là sự ra đời của kiến trúc tranformer, cho phép thay thế hoàn toàn kiến trúc mạng nơ-ron hồi tiếp RNN bằng các mô hình fully conneted và vẫn mang lại kết quả rất tốt. Đây là một cột mốc quan trọng cho việc áp dụng cơ chế attention cho các bài toán về NLP. Ví dụ như hình dưới, các từ hiện tại (chữ đỏ) và các từ được bôi xanh thể hiện sự ảnh hưởng của nó lên từ hiện tại.

Soft vs Hard Attention
Hai cơ chế này được áp dụng đới với ứng dụng tạo caption cho ảnh. Ảnh đầu tiên sẽ được xử lí bới CNN để trích ra các đặc trưng sau đó mạng LSTM kết hợp với cơ chế attetion sẽ thực hiện nhiệm vụ decode các đặc trứng đó để tạo ra caption. Hai cơ chế soft attention và hard attention được phân biệt như sau:
- Soft attention: sử dụng điểm attention như là trọng số để tính toán ra vector bối cảnh và nó là hàm khả vi nên có thể sử dụng gradient decense kết hợp backpropagation để huấn luyện. Tuy nhiên, vì tính toán trên toàn bộ đầu vào thì đối với ứng dụng liên quan đến ảnh chi phí tính toán sẽ rất tốn kém khi ảnh lớn.
- Hard attention: thay vì tính trung bình trọng số của tất cả các vector trạng thái ẩn thì nó sử dụng điểm attention để lựa chọn vị trí của vector trạng thái ẩn thích hợp nhất. Hard attention thường được huấn luyện bằng các sử dụng phương pháp học tăng cường (Reinforcement Learning). Ưu điểm của cơ chế là chi phi tính toán thấp hơn, tuy nhiên cần nhiều kĩ thuật phức tạp để huấn luyện.
Global vs Local Attention
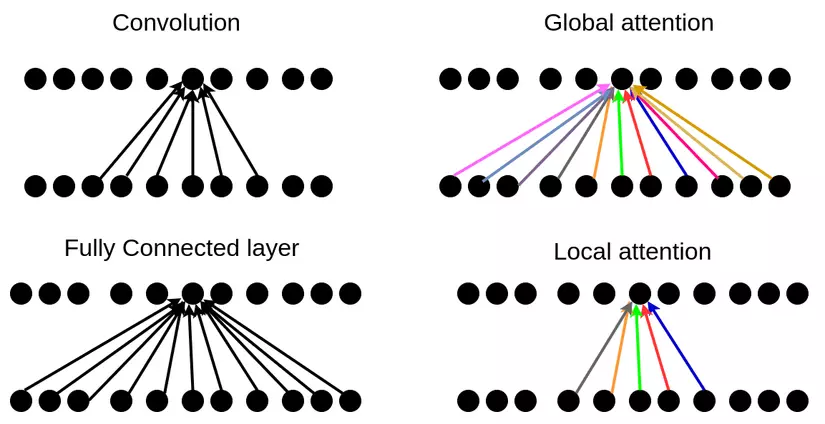
Trong bài này, cụ thể là với mô hình seq2seq cho dịch máy thì ta đang mặc định rằng cơ chế attention sẽ tính toán dựa trên toàn bộ đầu vào (global attention). Mặc dù vậy, cho các bài toán khác thì việc tính toán có thể tốn kém và không cần thiết. Do đó, đã có những paper đưa ra giải pháp là sử dụng local attention - chỉ quan tâm tới một phần của đầu vào. Local attention có thể coi giống như là hard attention. Ngoài ra, có thể so sánh global attention giống như là lớp fully connected, trong khi đó local attention thì lại giống như là lớp convolution.
Kết luận
Có thể thấy rằng cơ chế attention này không hề phức tạp nhưng mang lại hiệu quả rất cao. Đặc biệt là với self-attention và sự ra đời của mô hình Tranformer. Qua bài này, hi vọng có thể chia sẻ được vài nét về cơ chế attention và áp dụng được nó cho các bài toán của mình.
All rights reserved
