Tìm hiểu thư viện face-api thông qua viết ứng dụng Face Recognition
Bài đăng này đã không được cập nhật trong 5 năm
Face-api là một thư viện giúp cho chúng ta thực hiện các công việc như phát hiện khuôn mặt và nhận diện khuôn mặt trên trình duyệt và nó được triển khai trên lõi của tensorFlow.js

Face-api.js model
Trước khi bắt đầu với việc làm demo thì mình muốn giới thiệu một chút về các model của thư viện Face-api.js. Hiện tại thì chúng ta có thể sử dụng được 5 model mà face-api cung cấp đó là:
Face Detection:SSD Mobilenet V1: Sử dụng để phát hiện khuôn mặt, bằng cách sử dụng SSD (Single Shot Multibox Detector) dựa trên MobileNetV1. Nó sẽ trả về một ô vuông giới hạn khuôn mặt và xác suất cho mỗi gương mặt mà nó phát hiệnđược. Model này giúp cho việc phát hiện khuôn mặt được nhanh hơn và có độ chính xác cao hơn. Kích cỡ của model khoảng 5.4 MB (ssd_mobilenetv1_model). Model này được "trained" bởi WIDERFACE datasetTiny Face Detector: hỗ trợ realtime face detector với thời gian nhanh hơn, kích thước nhỏ hơn, tốn ít tài nguyên hơn để so sánh với SSD Mobilenet V1 face detector, đổi lại nó hoạt động kém hơn khi phát hiện các khuôn mặt nhỏ. Model này cực kỳ thân thiện với model và web, phù hợp với các thiết bị hạn chế tài nguyên. Kích cỡ 190KB (tiny_face_detector_model).
Face Landmark Detection: nó giúp phát hiện 68 điểm trên khuôn mặt của bạn một cách cực kỳ nhẹ và nhanh chóng mà lại còn chính xác nữa chứ. Kích cỡ 350KB (face_landmark_68_model) và model nhỏ chỉ 80KB (face_landmark_68_tiny_model). Cả 2 model được "trained" trong bộ dữ liệu ~35k hình ảnh khuôn mặt được gắn nhãn với 68 mốc khuôn mặt.Face Recognition: Xử dụng cho việc nhận diện khuôn mặt, một kiến trúc gần giống như ResNet-34 được triển khai để tính toán một bộ mô tả khuôn mặt (mộ vectơ đặc trưng có 128 giá trị) từ các hình ảnh khuôn mặt đã được cung cấp, cái mà sử dụng để mô tả các nét đặc trưng của khuôn mặt. Model này không giới hạn ở bộ khuôn mặt được sử dụng để "training", có nghĩa là bạn có thể sử dụng nó để nhận dạng khuôn mặt của bất kỳ người nào, chẳng hạn như khuôn mặt của bạn. Bạn có thể xác định sự giống nhau của hai khuôn mặt tùy ý bằng cách so sánh các mô tả khuôn mặt của chúng. Ví dụ bằng cách tính khoảng cách euclide hoặc sử dụng bất kỳ bộ phân loại nào khác mà bạn chọn. Kích cỡ của model này là 6.2MB (face_recognition_model).Face Expression Recognition: Model này giúp chúng ta có thể nhận đạng dược những biểu cảm trên khuôn mặt một cách nhanh chóng và cực kỳ nhẹ cùng với độ chính xác cao. Nó được "training" bởi các nguồn được public trên mạng. Lưu ý rằng độ chính xác có thể giảm xuống nếu bạn đeo kính. Kích cỡ 310KbAge Estimation and Gender Recognition: Model này giúp chúng ta ước lượng tuổi tác cũng như nhận diện giới tính. Kích thước 420KB
Thực hành viết chương trình nhận diện khuôn mặt
Đầu tiên bạn phải tải hết model của thử viện về thì mới có thể dùng được, bạn có thể tải nó về ở trang chủ của thư viện, ở đấy có một cái example bạn git clone nó về thì ở trong thư mục weights sẽ có tất cả các model của thư viện ở đấy
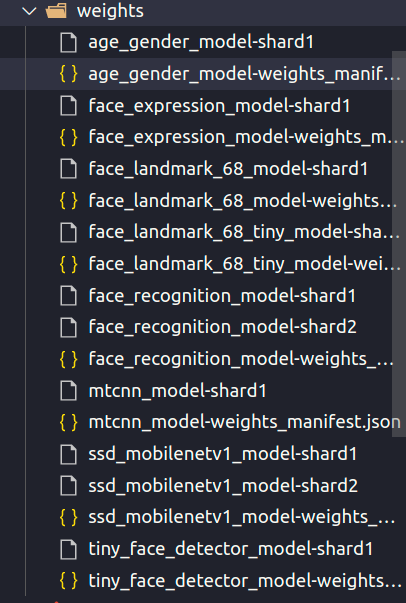
Bạn hãy tự tạo một thư mục chứa project cho mình ở đây mình tạo là Face-Recognition-JavaScript chưá các file và thư mục như hình dưới
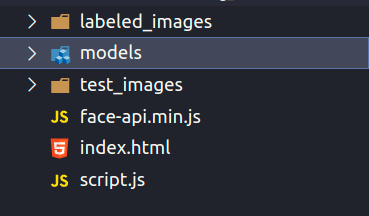
Và bỏ hết các model từ thư mục weight về thư mục models của bạn
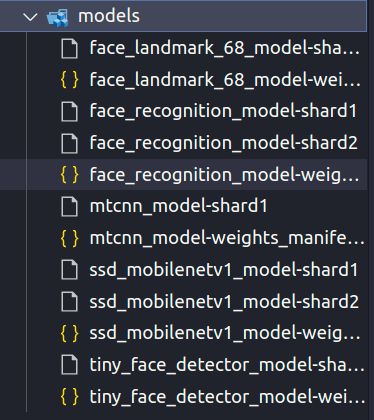
File face-api.min.js bạn có thể lấy ở đây. Trong file index.html chúng ta thêm nội dung như sau
<!DOCTYPE html>
<html lang="en">
<head>
<meta charset="UTF-8">
<meta name="viewport" content="width=device-width, initial-scale=1.0">
<meta http-equiv="X-UA-Compatible" content="ie=edge">
<script defer src="face-api.min.js"></script>
<script defer src="script.js"></script>
<title>Face Recognition</title>
<style>
body {
margin: 0;
padding: 0;
width: 100vw;
height: 100vh;
display: flex;
justify-content: center;
align-items: center;
flex-direction: column
}
canvas {
position: absolute;
top: 0;
left: 0;
}
</style>
</head>
<body>
<input type="file" id="imageUpload">
</body>
</html>
Tiếp theo ở trong file script.js chúng ta sẽ viết code ở đây để chương trình có thể chạy được
const imageUpload = document.getElementById('imageUpload')
Dòng đầu tiên trong file sẽ dùng để lấy tấm ảnh mà chúng ta tải lên bằng cách id của thẻ input chứa nó
Promise.all([
faceapi.nets.faceRecognitionNet.loadFromUri('/models'),
faceapi.nets.faceLandmark68Net.loadFromUri('/models'),
faceapi.nets.ssdMobilenetv1.loadFromUri('/models')
]).then(start)
Tiếp theo chúng ta sẽ phải load các models của thư viện cần dùng như ở đây chúng ta cần model faceRecognitionNet, faceLandmark68Net và ssdMobilenetv1. Ở đây chúng ta dùng Promise là để đợi cho đến khi load xong cả 3 models kia thì mới thực hiện tiếp (chạy hàm start).
async function start() {
const container = document.createElement('div')
container.style.position = 'relative'
document.body.append(container)
const labeledFaceDescriptors = await loadLabeledImages()
const faceMatcher = new faceapi.FaceMatcher(labeledFaceDescriptors, 0.6)
let image
let canvas
document.body.append('Loaded')
imageUpload.addEventListener('change', async () => {
if (image) image.remove()
if (canvas) canvas.remove()
image = await faceapi.bufferToImage(imageUpload.files[0])
container.append(image)
canvas = faceapi.createCanvasFromMedia(image)
container.append(canvas)
const displaySize = { width: image.width, height: image.height }
faceapi.matchDimensions(canvas, displaySize)
const detections = await faceapi.detectAllFaces(image).withFaceLandmarks().withFaceDescriptors()
const resizedDetections = faceapi.resizeResults(detections, displaySize)
const results = resizedDetections.map(d => faceMatcher.findBestMatch(d.descriptor))
results.forEach((result, i) => {
const box = resizedDetections[i].detection.box
const drawBox = new faceapi.draw.DrawBox(box, { label: result.toString() })
drawBox.draw(canvas)
})
})
}
function loadLabeledImages() {
const labels = ['Black Widow', 'Captain America', 'Captain Marvel', 'Hawkeye', 'Jim Rhodes', 'Thor', 'Tony Stark']
return Promise.all(
labels.map(async label => {
const descriptions = []
for (let i = 1; i <= 2; i++) {
const img = await faceapi.fetchImage(`https://raw.githubusercontent.com/WebDevSimplified/Face-Recognition-JavaScript/master/labeled_images/${label}/${i}.jpg`)
const detections = await faceapi.detectSingleFace(img).withFaceLandmarks().withFaceDescriptor()
descriptions.push(detections.descriptor)
}
return new faceapi.LabeledFaceDescriptors(label, descriptions)
})
)
}
Tiếp theo sẽ là 2 function này mình sẽ bắt đầu giải thíc với function loadLabeledImages trước sau đó sẽ là function start
Với function loadLabeledImages
function loadLabeledImages() {
const labels = ['Black Widow', 'Captain America', 'Captain Marvel', 'Hawkeye', 'Jim Rhodes', 'Thor', 'Tony Stark']
return Promise.all(
labels.map(async label => {
const descriptions = []
for (let i = 1; i <= 2; i++) {
const img = await faceapi.fetchImage(`https://raw.githubusercontent.com/WebDevSimplified/Face-Recognition-JavaScript/master/labeled_images/${label}/${i}.jpg`)
const detections = await faceapi.detectSingleFace(img).withFaceLandmarks().withFaceDescriptor()
descriptions.push(detections.descriptor)
}
return new faceapi.LabeledFaceDescriptors(label, descriptions)
})
)
}
Bắt đầu chúng ta sẽ tạo một hằng chứa tên các nhân vật trong avenger ví dụ như Black Widow, Captain America, ... Đây sẽ là tên được hiện ra nếu hệ thống nhận diện được hình ảnh của người đó có tên là gì? Những hình ảnh của người này sẽ được lưu trong thư mục labeled_images, và với mỗi thứ mục tên người dùng bên trong sẽ chứa những ảnh của người đó để hệ thống có thể xác nhận người đấy. Càng nhiều ảnh của người đấy thì hệ thống nhận diện càng chính xác.
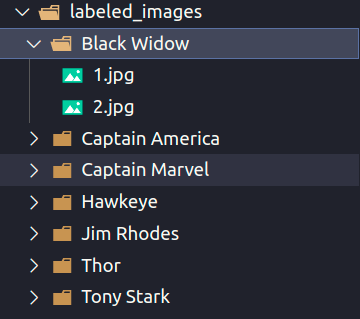
Ở đây chúng ta dùng Promise sẽ giúp chúng ta không rơi vào callback hell vì chúng ta sẽ load tất cả những hình ảnh khác nhau và thực hiện việc nhận diện khuôn mặt trong những bức ảnh đấy. bên trong chúng ta tạo một vòng lặp for để kiểm tra từng ảnh một
const img = await faceapi.fetchImage(https://raw.githubusercontent.com/WebDevSimplified/Face-Recognition-JavaScript/master/labeled_images/{i}.jpg)
Ở đây ở đây mình dùng một link chứa thư mục ảnh vì dùng thông qua live server. Bạn có thể chuyền vào thư mục labeled_images để sử dụng cũng được không sao.
Và tiếp theo chúng ta cũng phải xác định được khuôn mặt của người đó trong ảnh và lưu facedecriptor của nó và chúng ta sẽ lưu nó lại ở trong mảng descriptions. và cuối cùng là trả về label và descriptions của nó
return new faceapi.LabeledFaceDescriptors(label, descriptions)
Tiếp theo sẽ là hàm start
async function start() {
const container = document.createElement('div')
container.style.position = 'relative'
document.body.append(container)
const labeledFaceDescriptors = await loadLabeledImages()
const faceMatcher = new faceapi.FaceMatcher(labeledFaceDescriptors, 0.6)
let image
let canvas
document.body.append('Loaded')
imageUpload.addEventListener('change', async () => {
if (image) image.remove()
if (canvas) canvas.remove()
image = await faceapi.bufferToImage(imageUpload.files[0])
container.append(image)
canvas = faceapi.createCanvasFromMedia(image)
container.append(canvas)
const displaySize = { width: image.width, height: image.height }
faceapi.matchDimensions(canvas, displaySize)
const detections = await faceapi.detectAllFaces(image).withFaceLandmarks().withFaceDescriptors()
const resizedDetections = faceapi.resizeResults(detections, displaySize)
const results = resizedDetections.map(d => faceMatcher.findBestMatch(d.descriptor))
results.forEach((result, i) => {
const box = resizedDetections[i].detection.box
const drawBox = new faceapi.draw.DrawBox(box, { label: result.toString() })
drawBox.draw(canvas)
})
})
}
Chúng ta sẽ gọi hàm image ở đây const labeledFaceDescriptors = await loadLabeledImages() và gán giá trị nhận được vào biến labeledFaceDescriptors và tiếp theo chúng ta sẽ sử dụng hàm FaceMatcher ở đây tham số đầu tiên là labeledFaceDescriptors sẽ bao gồm tên mà mô tả gương mặt của người ấy, tham số thứ 2 là phần trăm gương mặt giống với mô tả ở đây đang để là 0,6 tương ứng với 60%.
image = await faceapi.bufferToImage(imageUpload.files[0])
Ở đây chúng ta sẽ chỉ nhận 1 file ảnh được up lên và convers nó bằng hàm bufferToImage để thư viện có thể đọc được.
container.append(image)
canvas = faceapi.createCanvasFromMedia(image)
container.append(canvas)
const displaySize = { width: image.width, height: image.height }
faceapi.matchDimensions(canvas, displaySize)
Đoạn này sẽ giúp chúng ta có thể vẽ được một hình vuông xung quanh khuôn mặt mà ta có thể thấy được trong bức ảnh
const detections = await faceapi.detectAllFaces(image).withFaceLandmarks().withFaceDescriptors() Ở đây chúng ta sẽ gọi hàm detectAllFaces(image) và truyền vào đó bức ảnh mà chúng ta upload lên để xem bên trong có tất cả toàn bộ bao nhiêu gương mặt và chúng ta làm điều này với withFaceLandmarks() Điều này sẽ giúp cho thuật toán có thể phân biệt được các khuôn mặt khác nhau và withFaceDescriptors() sẽ giúp chúng ta vẽ một hình vuông xung quanh khuôn mặt nhận dạng được
const resizedDetections = faceapi.resizeResults(detections, displaySize) Hàm này sẽ giúp chúng ta resize lại hình vuống với kích cỡ mà mình mong muốn
const results = resizedDetections.map(d => faceMatcher.findBestMatch(d.descriptor)) ở đây chúng ta sẽ goi faceMactcher sẽ so sánh từng khuôn mặt trong ảnh và mẫu với kết quả tốt nhất (findBestMatch(d.descriptor)) để ra kết quả nhận diện
results.forEach((result, i) => {
const box = resizedDetections[i].detection.box
const drawBox = new faceapi.draw.DrawBox(box, { label: result.toString() })
drawBox.draw(canvas)
})
Cuối cùng thì chỉ cần loop qua từng kết quả và in ra màn hình thôi
Nguồn tham khảo
https://github.com/justadudewhohacks/face-api.js https://www.youtube.com/watch?v=AZ4PdALMqx0
All rights reserved
