Tìm hiểu những kiến thức cơ bản về Big Data testing
Bài đăng này đã không được cập nhật trong 7 năm
Trong vài năm gần đây thuật ngữ "Big data" đang dần trở nên quen thuộc, khi mà công nghệ thông tin đang phát triển nhanh chóng, đi thèm theo đó là sự gia tăng về dữ liệu cần lưu trữ. Và tất nhiên, việc kiểm thử Big data là rất cần thiết, Big Data Testing đang nằm trong list những xu hướng kiểm thử phần mềm năm 2019. Trong bài viết này, mình sẽ ghi lại những điều mình đã tìm hiểu được về "Big data" và "Big Data testing".
1. Big data là gì?
Big data đề cập đến khối lượng dữ liệu lớn, không thể được lưu trữ bằng cơ sở dữ liệu truyền thống (relational databases). Thường các doanh nghiệp sử dụng các cơ sở dữ liệu truyền thống như Oracle, MySQL, SQL Server để lưu trữ và xử lý dữ liệu. Tuy nhiên, khi lượng dữ liệu quá lớn, có thể ở bất kỳ định dạng nào như hình ảnh, tệp, âm thanh,... có cấu trúc và định dạng của mỗi bản ghi là khác nhau,... thì cơ sở dữ liệu truyền thống không thể xử lý được.
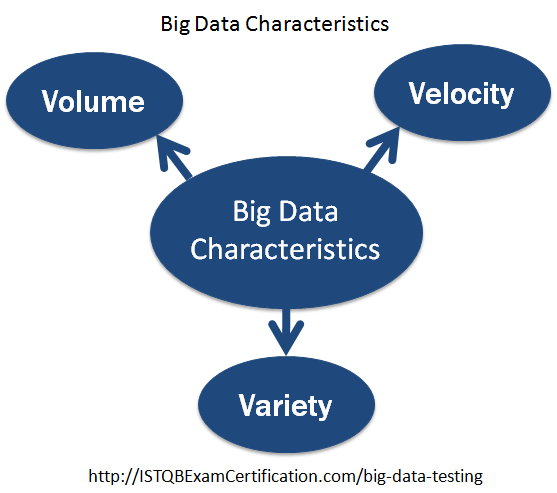
Việc tăng trưởng dữ liệu có thể được mô tả theo ba chiều (3V):
- Tăng về dung lượng (volume).
- Tăng về tốc độ (velocity): Dữ liệu được tạo ra ở tốc độ cao và phải được xử lý nhanh chóng.
- Sự khác nhau về định dạng (variety).
Ví dụ về Big data: Các trang mạng xã hội tạo ra lượng dữ liệu khổng lồ về hình ảnh, video, số lượt thích, bài đăng, nhận xét ... Không chỉ lưu trữ dữ liệu trong nền tảng big data, mà còn xử lý và phân tích để cung cấp các đề xuất, phản hồi nội dung mà người dùng yêu cầu.

Giả sử bạn vừa tìm kiếm một hãng thời trang nào đó trên Instagram, ngay sau đó bạn sẽ thấy gợi ý về hãng thời trang đó và hàng loạt các hãng thời trang khác trên Facebook.
=> Đây là trường hợp sử dụng dữ liệu lớn, lưu trữ và xử lý thông tin này để hiển thị đúng quảng cáo cho đúng người dùng không thể được thực hiện bằng các cơ sở dữ liệu truyền thống trong cùng một khoảng thời gian. Một người dùng tìm kiếm quần áo, váy đầm thì có nhiều khả năng gặp quảng cáo của các hãng thời trang hơn quảng cáo của các hãng sữa, Tivi, tủ lạnh.
Thuật ngữ liên quan đến kiểm thử Big data:
- Hadoop: Hadoop là một framework mã nguồn mở. Nó được sử dụng để xử lý phân tán và lưu trữ các tập dữ liệu lớn bằng cách sử dụng các cụm (cluster) máy. Nó có thể mở rộng từ một máy chủ đến hàng ngàn máy chủ. Nó cung cấp tính sẵn sàng cao bằng cách xác định các lỗi phần cứng và xử lý chúng ở tầng ứng dụng.
- MapReduce: MapReduce là mô hình lập trình để xử lý song song các tập dữ liệu lớn
2. Chiến lược kiểm thử Big data
Việc kiểm thử một ứng dụng Big data thường tập trung vào các tiến trình xử lý/ phân tích dữ liệu (process) hơn là tập trung vào các tính năng của ứng dụng (features). Vì thế khi nói đến kiểm thử Big data là nhắc đến kiểm thử chức năng (functional testing) và kiểm thử hiệu năng (performance testing).
3. Kiểm thử cơ sở dữ liệu trong các ứng dụng big data
Trong kỹ thuật kiểm thử Big data, kiểm thử viên cần test luồng xử lý của hàng TeraByte dữ liệu trên các cluster khác nhau.
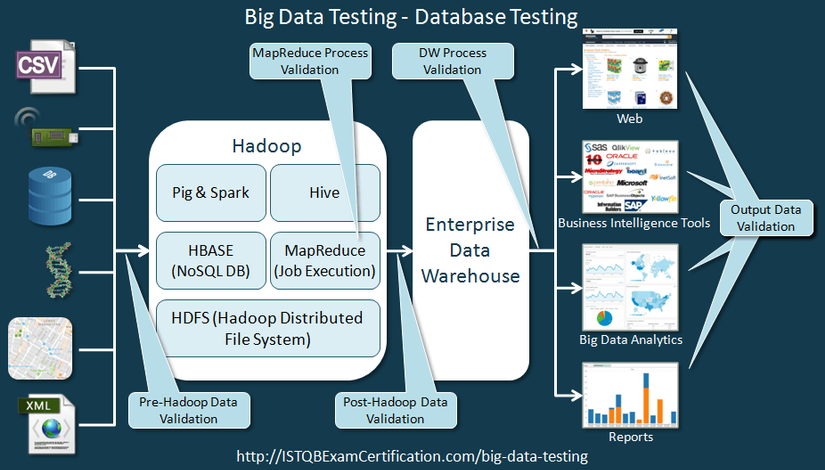
Có thể mô tả thành 3 bước như hình sau:

Bước 1: Kiểm thử dữ liệu đầu vào
Data Staging Validation (Xác thực dữ liệu) : xác thực dữ liệu được lấy từ nhiều nguồn khác nhau như cảm biến, scanner, logs,... xem dữ liệu được đẩy vào Hadoop (hoặc các frameworks khác) hay chưa? có đầy đủ và chính xác?
- Dữ liệu từ nhiều nguồn khác nhau : RDBMS, weblogs, social media… cần phải được kiểm tra để đảm bảo dữ liệu đầu vào cho hệ thống là chính xác.
- So sánh dữ liệu đầu vào với dữ liệu đã được đẩy vào database hadoop
- Đảm bảo dữ liệu được bóc tách (extract) và đẩy (load) vào vị trí HDFS chính xác
Bước 2: Kiểm thử quá trình phân tích dữ liệu MapReduce
Process Validation (Xác nhận quá trình) : xác nhận rằng dữ liệu thu được sau khi xử lý thông qua big data là chính xác. Điều này cũng bao gồm việc kiểm tra tính chính xác của dữ liệu được tạo . Đảm bảo quá trình dữ liệu chạy qua từng node khác nhau và khi chạy qua nhiều node là chính xác.
- Để kiểm tra ứng dụng Big Data, Tester sử dụng test data. Dữ liệu có sẵn trong Hadoop rất lớn nên không thể sử dụng tất cả dữ liệu để kiểm thử. Chúng ta chọn một tập con của dữ liệu để thử và gọi đó là test data.
- Tester sẽ kiểm thử ứng dụng sử dụng testdata như dữ liệu thật, theo yêu cầu của khách hàng.
- Sau đó so sánh nó với kết quả xử lý từ ứng dụng big data để xác nhận rằng ứng dụng đang xử lý dữ liệu chính xác.
- Để xử lý testdata, cần một số kiến thức về lập trình để viết script trích xuất và xử lý dữ liệu cho kiểm thử.
Bước 3: Kiểm thử kết quả đầu ra
Output Validation (Xác nhận đầu ra) : xác nhận rằng đầu ra từ ứng dụng big data được lưu trữ chính xác trong kho dữ liệu. Đồng thời xác minh rằng dữ liệu được thể hiện chính xác trong hệ thống thông tin nghiệp vụ hoặc bất kỳ giao diện người dùng mục tiêu nào khác.
4. Kiểm thử chức năng của ứng dụng Big data
Kiểm thử chức năng của các ứng dụng big data được thực hiện bằng cách dựa trên giao diện người dùng, có thể là một ứng dụng web có giao diện Hadoop (hoặc một framework tương thích với back-end).
Sau đó, kết quả nhận được từ giao diện sẽ được so sánh với kết quả mong đợi.
Kiểm thử chức năng của các ứng dụng gần giống với kiểm thử chức năng thông thường của ứng dụng phần mềm khác.
5. Kiểm thử hiệu năng trong ứng dụng Big data
Các ứng dụng big data liên quan đến việc xử lý/ phân tích một lượng lớn dữ liệu chỉ trong một khoảng thời gian ngắn. Vì thế đòi hỏi nguồn tài nguyên máy tính luôn sẵn sàng và luồng dữ liệu trơn tru, mượt mà.
Các vấn đề về kiến trúc hệ thống có thể dẫn đến tắc nghẽn trong quá trình thực hiện, có thể ảnh hưởng đến tính khả dụng của ứng dụng. Điều này có thể ảnh hưởng đến thành công của dự án.
Kiểm thử hiệu năng của hệ thống Big data là rất cần thiết, giúp tránh các rủi ro trên. Ở đây chúng ta đo lường các số liệu như băng thông (throughput), khả năng sử dụng bộ nhớ, sử dụng CPU, thời gian phản hồi một request,...
Tester cần check thêm case khi chuyển đổi dữ liệu để xác nhận tính chịu lỗi của hệ thống và đảm bảo rằng nếu lỗi xảy ra ở một số node thì các node khác sẽ không ảnh hưởng trong quá trình xử lý.
Nguồn tham khảo: http://tryqa.com/big-data-testing/
All rights reserved
