Thu thập comment của Phimmoi
Bài đăng này đã không được cập nhật trong 6 năm
Ý tưởng
Mình có thói quen xem phim, trước khi xem thường sẽ coi điểm IMDb, sau đó lướt xuống comment phía dưới xem là khen hay chê (đối với những phim nổi tiếng thì không nói  ). Và mình thấy vài người bạn của mình cũng vậy, khi cả lũ tụ tập xem phim với nhau (thường là sẽ xem phim ... ma), cũng lướt xuống comment xem có chửi phim nhiều không. Rồi nhiều lúc 30 phút vẫn chưa tìm thấy phim nào ưng ý.
). Và mình thấy vài người bạn của mình cũng vậy, khi cả lũ tụ tập xem phim với nhau (thường là sẽ xem phim ... ma), cũng lướt xuống comment xem có chửi phim nhiều không. Rồi nhiều lúc 30 phút vẫn chưa tìm thấy phim nào ưng ý.
Mình nghĩ ra nếu làm tool đánh giá phim dựa trên comment thì có thể giúp ích được phần nào (ở đây mình áp dụng đối với Phimmoi)
Chức năng lý tưởng:
- Nhập link phim, kết quả trả về sẽ làm xem hay không xem và gồm cả một vài comment tiêu biểu
- Quét hàng loạt phim, đưa ra gợi ý phim đáng xem cho từng thể loại (dựa vào một vài tiêu chí nhất định)
Cách thực hiện: trước hết cần thu thập comment trên phimmoi, sau đó phân tích cảm xúc, quan điểm của comment dựa vào bộ từ điển hoặc Học máy.
Thu thập comment của 1 phim
Với 1 link phim cụ thể lấy trên website, ở đây mình lấy link http://www.phimmoi.net/phim/365-ngay-yeu-anh-i2-10719/
Phim Mới dùng plugin comment của facebook, nên bài hướng dẫn này cũng có thể áp dụng lấy comment cho các trang sử dụng comment Facebook.
Vào link phim trên, nhấn F12 để inspect website, sau đó vào thẻ Network để theo dõi request. Lúc này, click vào nút Load thêm bình luận, sẽ thấy ngay request hiện ở thẻ Network (clear các request trước để nhìn rõ hơn)
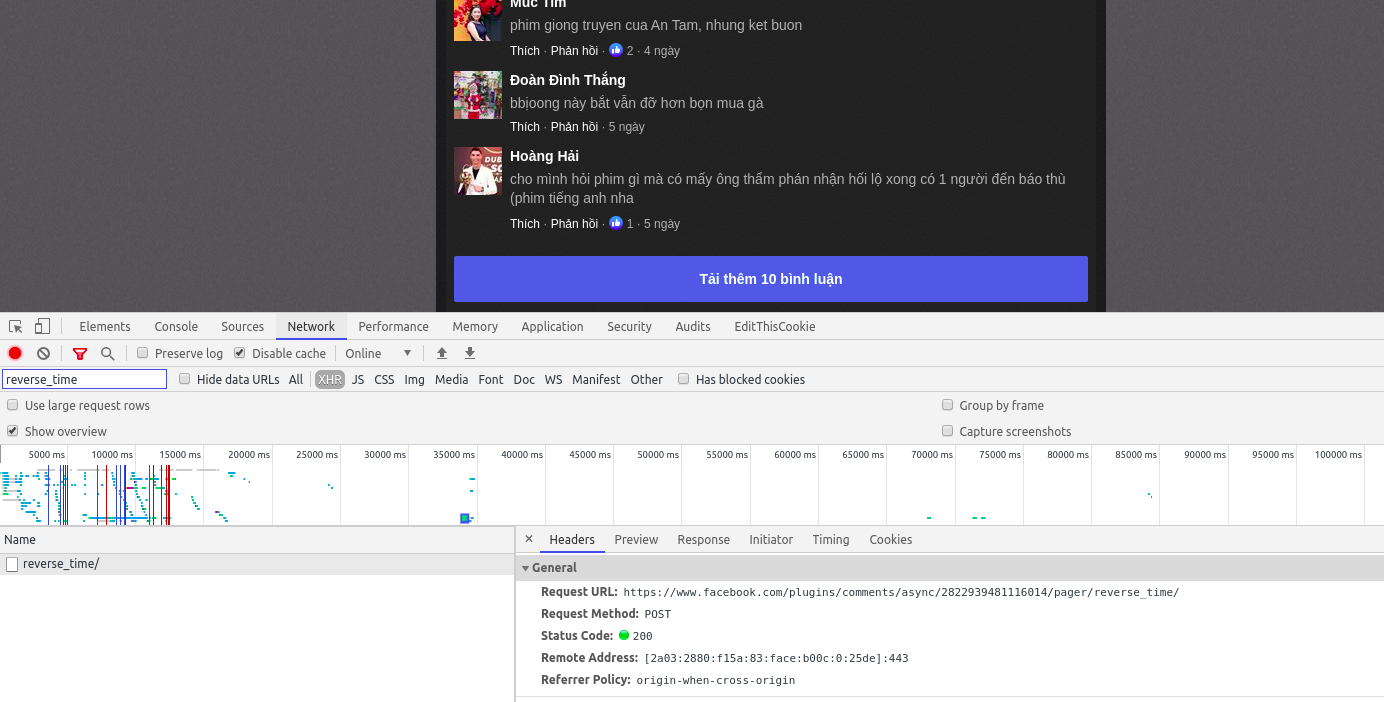
Nhấn chuột phải vào request, chọn Copy/Copy as cURL, copy toàn bộ CURL của request.
curl 'https://www.facebook.com/plugins/comments/async/2822939481116014/pager/reverse_time/' \
-H 'authority: www.facebook.com' \
-H 'pragma: no-cache' \
-H 'cache-control: no-cache' \
-H 'user-agent: Mozilla/5.0 (X11; Linux x86_64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/81.0.4044.129 Safari/537.36' \
-H 'content-type: application/x-www-form-urlencoded' \
-H 'accept: */*' \
-H 'origin: https://www.facebook.com' \
-H 'sec-fetch-site: same-origin' \
-H 'sec-fetch-mode: cors' \
-H 'sec-fetch-dest: empty' \
-H 'referer: https://www.facebook.com/plugins/feedback.php?app_id=1390295464546181&channel=https%3A%2F%2Fstaticxx.facebook.com%2Fconnect%2Fxd_arbiter.php%3Fversion%3D46%23cb%3Df22c06d636c2008%26domain%3Dwww.phimmoi.net%26origin%3Dhttp%253A%252F%252Fwww.phimmoi.net%252Ff1e67bc90558f88%26relation%3Dparent.parent&color_scheme=dark&container_width=650&height=100&href=http%3A%2F%2Fwww.phimmoi.net%2Fphim%2F365-ngay-yeu-anh-10719%2F&locale=vi_VN&order_by=reverse_time&sdk=joey&skin=dark&version=v2.12&width=650' \
-H 'accept-language: en-US,en;q=0.9,vi;q=0.8' \
-H 'cookie: fr=0shZ5eUbOjaYtgLs0..BeuWpJ...1.0.BeuWpJ.' \
--data 'app_id=1390295464546181&after_cursor=Y29tbWVudF9jdXJzb3I6MjkwMDAzODU4NjczOTQzNjoxNTg4OTg1MzE0&limit=10&iframe_referer=http%3A%2F%2Fwww.phimmoi.net%2Fphim%2F365-ngay-yeu-anh-i2-10719%2F&__user=0&__a=1&__dyn=7xe6EgU4e3W3mbwKBAodo6C2i5U4e2W6Uuxq8zEdEc88EW3u1kwXwiUcEfE6u3y4o3Bw5VCwjE2-yU5C1wxO0SobEa84u0gO0AbAy85-0jx0Fwg85m0j60SU2swdq1iwmE&__csr=&__req=1&__beoa=0&__pc=PHASED%3Aplugin_feedback_pkg&dpr=1&__ccg=EXCELLENT&__rev=1002108352&__s=%3A%3Amhf4ok&__hsi=6825603818203150027&__comet_req=0&locale=vi_VN&__sp=1'
Copy curl này vào Terminal (trên Ubuntu), nhấn Enter thì ta được kết quả response giống hệt trên Website.
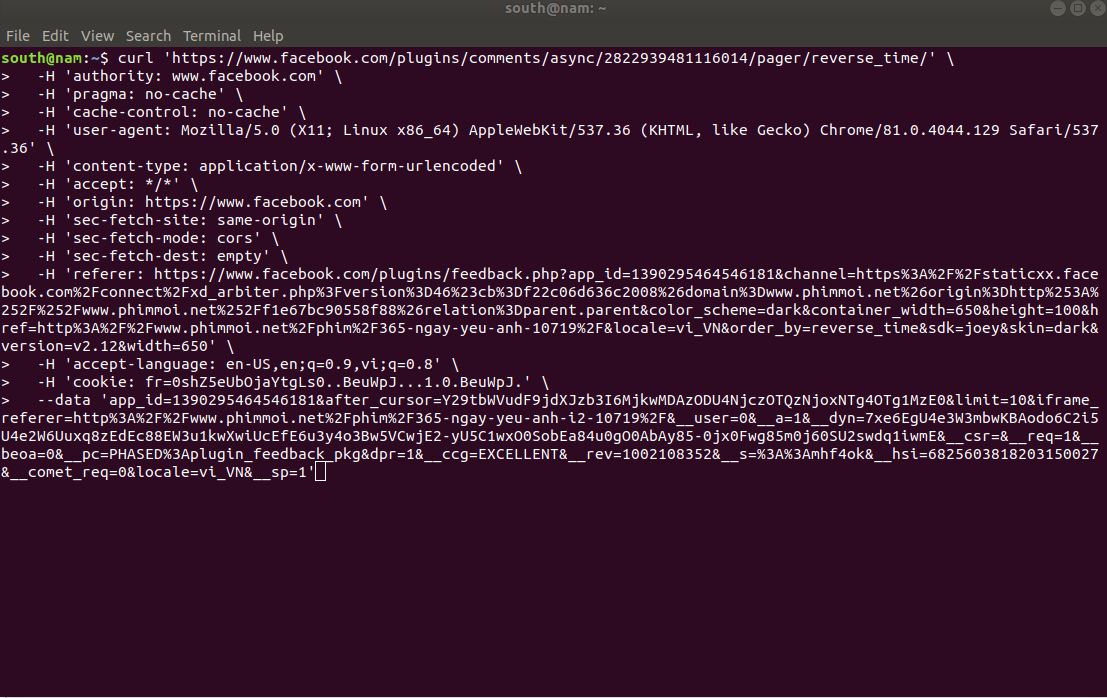
Thực ra, request trên nhiều cái thừa, nên mình loại bỏ những cái thừa bằng cách xóa lần lượt rồi thử với Terminal, nếu response trả về không đổi thì xóa nó đi, nếu response khác hoặc không trả về gì thì giữ nó lại. Và kết quả thu được khá gọn và có thể phân tích ý nghĩa:
curl 'https://www.facebook.com/plugins/comments/async/2822939481116014/pager/reverse_time/' -H 'cookie: fr=0shZ5eUbOjaYtgLs0..BeuWpJ...1.0.BeuWpJ.' --data 'after_cursor=Y29tbWVudF9jdXJzb3I6MjkwMDAzODU4NjczOTQzNjoxNTg4OTg1MzE0&limit=10&__a=1'
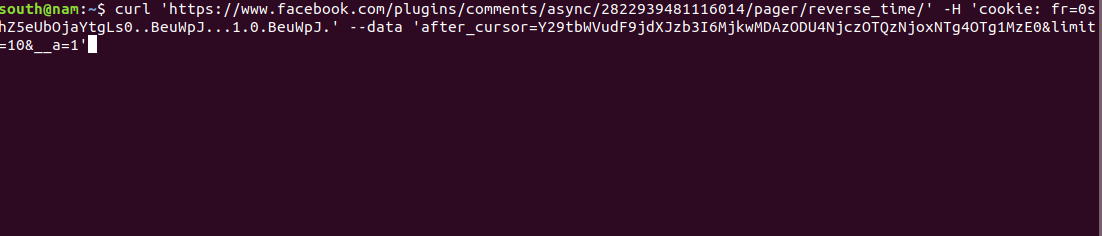
Với:
2822939481116014là id (fb) của phim hiện tại (cần phải tìm cách lấy)cookiegiá trị mặc định như trên hoặc có thể tự lấy với trình duyệt của bạn- Data gửi lên:
after_cursor: dùng cho việc next page, nếu là trang đầu tiên thì có thể để trống hoặc bỏ đilimit: số lượng comment cho 1 request (per page)__a: giá trị mặc định = 1, không có ý nghĩa, nhưng nếu bỏ đi thì không request được
Phân tích đủ rồi, bắt tay code thôi, mình sử dụng requests của Python 3 để gửi request.
Lưu ý trong response đoạn đầu là string: for (;;);, nếu loại bỏ string này thì response sẽ là dạng json và có cấu trúc như hình. Lấy giá trị['payload']['idMap']. Trong list giá trị này mình thấy có 2 type là user và comment, thu thập cả 2 type này, ngoài ra còn có type ogobject là film (hình như chỉ xuất hiện ở request page đầu).
Toàn bộ source code (mình có comment giải thích code):
import requests
import json
import time
start_time = time.time()
film_id = '2822939481116014'
limit = 20
url = 'https://www.facebook.com/plugins/comments/async/'+ film_id +'/pager/reverse_time/'
headers = {
'cookie': 'fr=0shZ5eUbOjaYtgLs0..BeuWpJ...1.0.BeuWpJ.'
}
def get_page(after_cursor = ''):
data = {
'after_cursor': after_cursor,
'limit': limit,
'__a': '1'
}
r = requests.post(url, headers=headers, data=data)
response = r.text[9:]
res_obj = json.loads(response)
list_comment = res_obj['payload']['idMap']
r = []
film_name = ''
for key in list_comment:
user_id = ''
user_name = ''
user_uri = ''
item = list_comment[key]
# 3 loại
if item['type'] == 'user':
user_id = item['id']
user_name = item['name']
user_uri = item['uri']
if item['type'] == 'ogobject':
if film_name == '':
film_name = item['name']
film_uri = item['uri']
if item['type'] == 'comment':
comment_user = item['authorID']
comment_content = item['body']['text']
comment_timestamp = item['timestamp']
temp = {
'comment_user': comment_user,
'comment_content': comment_content,
'comment_timestamp': comment_timestamp,
'film_id': film_id
}
r.append(temp)
return {
'data': r,
'next': res_obj['payload']['afterCursor'],
'film_name': film_name
}
film_name = ''
after_cursor = ''
results = []
while 1:
print('after_cursor: ' + after_cursor)
res = get_page(after_cursor)
# nếu không có comment nào nữa thì thoát
if len(res['data']) == 0:
break
# nếu không thì + vào results và request next page dựa vào after_cursor
results += res['data']
after_cursor = res['next']
# tên file, lấy ra để lưu tên file cho dễ quan sát
if film_name == '':
film_name = res['film_name']
end_time = time.time()
total_time = end_time - start_time
with open(film_name + '_' + film_id +'.json', 'w') as outfile:
json.dump(results, outfile, indent=4, ensure_ascii=False)
print(total_time)
Kết quả comment lưu dạng:
{
"comment_user": "100001672685808",
"comment_content": "1:07:00 cho fan",
"comment_timestamp": {
"time": 1589203130,
"text": "06:18, 11 tháng 5, 2020"
},
"film_id": "2822939481116014"
}
Kết luận
Ok, bài này mình hướng dẫn cách lấy toàn bộ comment của một phim, mình sẽ viết tiếp hướng dẫn làm sao để lấy film_id từ link phim, cách quét toàn bộ comment của Phimmoi, bài toán khai phá cảm xúc, quan điểm.
Link phần 2 đây nhé: Crawl toàn bộ Comment Facebook Plugin của Phimmoi.net
Ae có đóng góp gì comment phía dưới nhé
Update: Phimmoi sập rồi ông giáo ạ 
All rights reserved
