Crawl toàn bộ Comment Facebook Plugin của Phimmoi.net
Intro
Phimmoi sử dụng Plugin Comment Facebook và ở bài Thu thập comment của Phimmoi mình đã hướng dẫn cách thu thập comment của 1 link phim cụ thể, nhưng cách lấy id (fb) của phim một cách tự động mình chưa giới thiệu.
Bài này, mình sẽ hướng dẫn cách lấy toàn bộ comment của tất cả các phim trên Phimmoi.net
Do it
Inspect
Mình lấy ví dụ phim: http://www.phimmoi.net/phim/spongebob-bot-bien-dao-tau-9881/
Vào link phim và F12 inspect trình duyệt, thấy rằng phần hiển thị comment nằm ở trong 1 iframe.
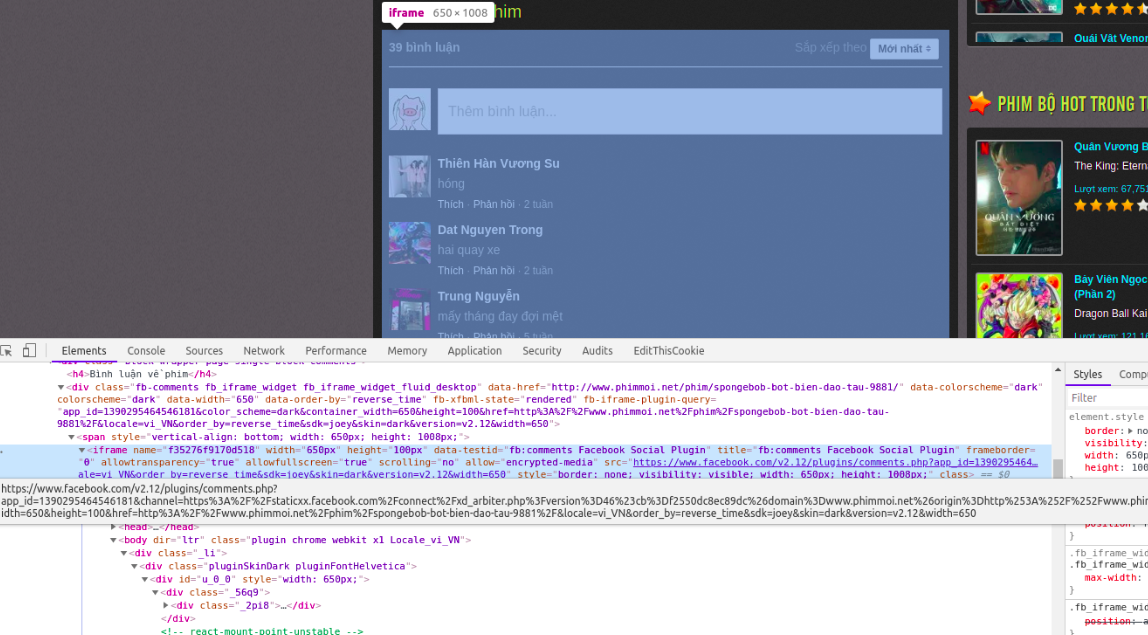
Copy source (thuộc tính src của iframe) và mở trong tab mới
https://www.facebook.com/plugins/feedback.php?app_id=1390295464546181&channel=https%3A%2F%2Fstaticxx.facebook.com%2Fconnect%2Fxd_arbiter.php%3Fversion%3D46%23cb%3Df2550dc8ec89dc%26domain%3Dwww.phimmoi.net%26origin%3Dhttp%253A%252F%252Fwww.phimmoi.net%252Ff82032e0f8b8cc%26relation%3Dparent.parent&color_scheme=dark&container_width=650&height=100&href=http%3A%2F%2Fwww.phimmoi.net%2Fphim%2Fspongebob-bot-bien-dao-tau-9881%2F&
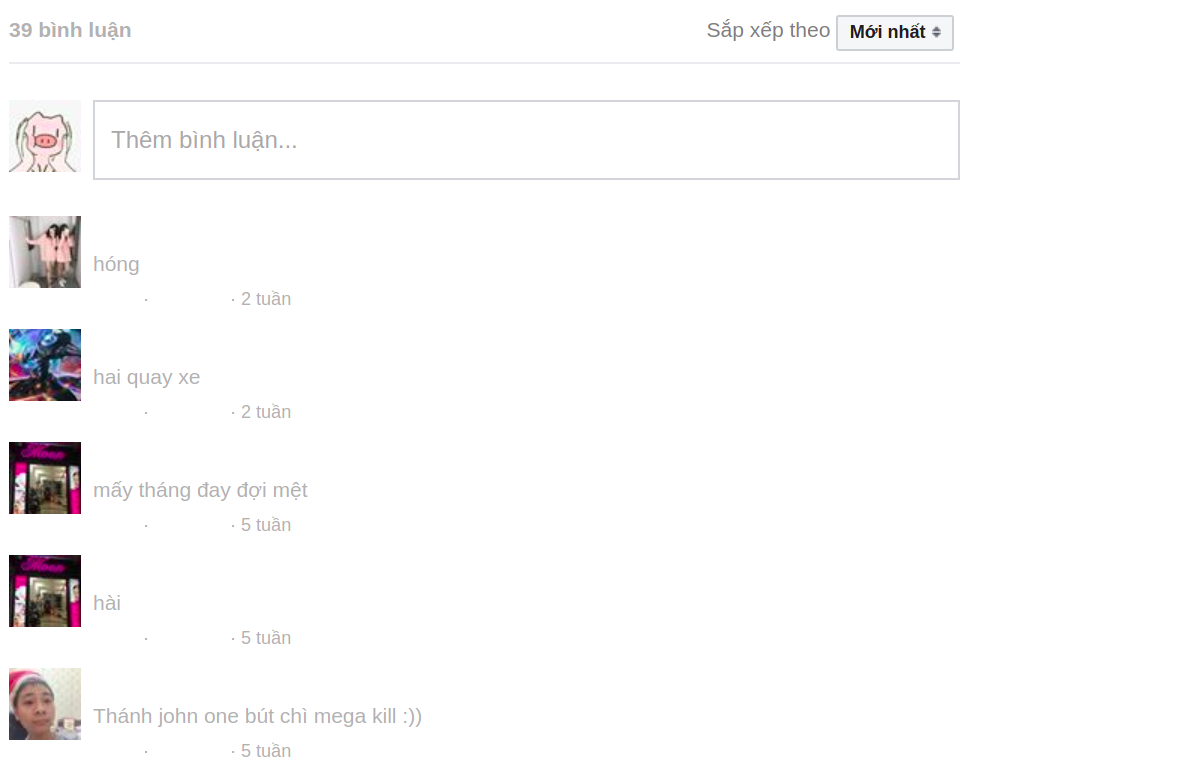
Opps, giao diện comment đây mà  )
)
Và mình lược bỏ param không cần thiết đi (lược bỏ mà vẫn có giao diện comment) thì chỉ còn lại ngắn gọn:
https://www.facebook.com/plugins/feedback.php?href=http%3A%2F%2Fwww.phimmoi.net%2Fphim%2Fspongebob-bot-bien-dao-tau-9881%2F&
với param href là url của phim đã được Url Encode
Suy ra: có url_film thì sẽ có url_plugin_comment này
Như cách thủ công của bài trước mình lấy được id_film_fb = '2669938799792443'
Từ trang giao diện của Plugin Comment trên, chuột phải xong chọn View Page Source hoặc phím tắt Ctrl + U, search trong source đó id_film_fb trên
Âu cơ, đây rồi, thì ra là nó ở đây
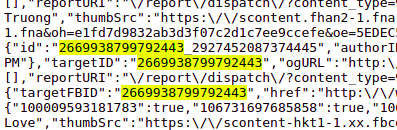
id nó nằm ở khắp mọi chỗ luôn, nhưng mình chọn giá trị của targetFBID cho dễ lấy.
Đã hoàn thành được một nửa, bắt tay vào code nào
Process
Tự động get id film và comment của phim dựa
Các bước xử lý:
- Encode
url_filmđể có đượcurl_plugin_comment(request với paramhref=url_film) - request đến
url_plugin_commentđể lấyid_film_fbtừtargetFBID - Thu thập comment với
id_film_fbđã biết
và có 3 hàm:
get_id_film: lấy raid_film_fbget_page: lấy ra comment của 1 pageget_all_of_film: lấy toàn bộ comment của 1 phim vớiurl_film
def get_id_film(url_film):
params = {'href': url_film}
plugin_comment_root = 'https://www.facebook.com/plugins/feedback.php'
# request với param href = url_fillm
r = requests.get(plugin_comment_root, params=params)
resp = r.text
# tìm index targetFBID
start_index = resp.find('"targetFBID":"') + 14
# tìm dấu nháy tiếp theo
end_index = resp.find('"', start_index)
# crop :)
id_film_fb = resp[start_index:end_index]
return id_film_fb
Xem full source code: github
Lấy danh sách phim và tất cả các comment tương ứng
Ở đây mình lấy danh sách phim theo thể loại và lặp theo page Ví dụ: thể loại Phim hành động sẽ có link là: http://www.phimmoi.net/the-loai/phim-hanh-dong/page-1.html
Request đến link trên và sử dụng BeautifulSoup để tách url phim ra (easy)
def get_film_of_cate(cate, page):
domain = 'http://phimmoi.net/'
url_cate_film = 'http://www.phimmoi.net/the-loai/'+cate+'/page-'+str(page)+'.html'
r = requests.get(url_cate_film)
resp = r.text
soup = BeautifulSoup(resp, features="html.parser")
films = soup.findAll('a', {'class': 'block-wrapper'})
results = []
for item in films:
href = domain + item['href']
title = item['title'].replace('/', ' ')
results.append({
'href': href,
'title': title
})
return results
Rồi chạy vòng for lặp page là xong (trong code mình demo 1 page), data mình lưu dưới dạng file json cho tiện xử lý.
Done
Kết quả chạy page 1 cho thể loại phim-hanh-dong
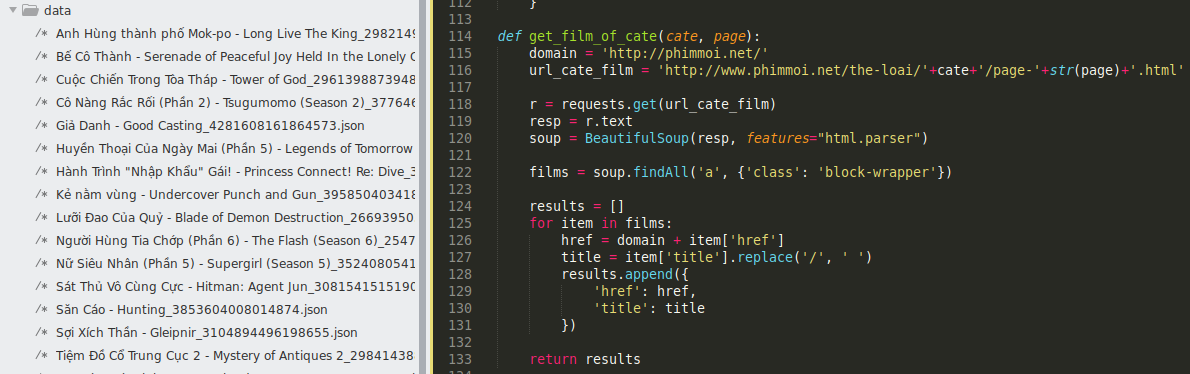
muốn lấy toàn bộ comment của phimmoi thì chỉ cần list hết các thể loại (xử lý lặp phim: một phim có thể thuộc nhiều thể loại), rồi lặp page cho từng thể loại. Cũng sẽ khá mất thời gian, ở đây cần xử lý đa luồng chạy nhiều page cùng 1 lúc, nhiều phim cùng 1 lúc.
Link đẩy đủ source code: Github
Lưu ý: chạy source code cần tạo folder data để lưu comment )
All rights reserved
