
Thiết Kế Hệ Thống Phát Hiện Gian Lận (Rule-Based Fraud Detection System Design)
Bài đăng này đã không được cập nhật trong 2 năm
Đặt Vấn Đề
Coupon, voucher hay gift là miếng bánh ngọt đối với những đối tượng gian lận (fraudsters). Những đối tượng này thường lợi dụng những kẽ hở về mặt vận hành hoặc chính sách nhằm thu thập số lượng lớn ưu đãi. Thậm chí, có hành vi rửa tiền. Do đó, các tổ chức tài chính, hệ thống tài chính như ngân hàng, cổng thanh toán, sàn thương mại, ví điện tử, … cần một hệ thống có thể phát hiện và cảnh báo kịp thời những hành vi gian lận hoặc bất thường.
Những hành vi gian lận có chung 1 mục đích thường có chung 1 mẫu (pattern). Ví dụ một số mẫu hành vi sau (chỉ mang tính minh họa):
- Đối tượng gian lận thường đăng nhập nhiều tài khoản trên cùng một thiết bị trong khoản thời gian ngắn
- Các đối tượng tổ chức đ.á.n.h bạc thường có giao dịch đột biến vào ban đêm
- Sử dụng số lượng voucher vượt ngưỡng X trong khoảng thời gian Y phút

(Linh cẩu đốm (Spotted Hyena) nổi tiếng với thói quen ăn xác động vật đã t.h.ú.i nhưng thực tế 70% thức ăn của chúng là do chúng trực tiếp đi săn và ăn luôn. Chúng thông minh, là những kẻ săn mồi có kỹ năng cao, sống bầy đàn. Chúng có thể nghe thấy tiếng rú của nhau với khoảng cách lên tới 5km, dùng để thông báo có “cái ăn”. Ngoài ra, chúng nổi tiếng với khiếu hài hước vì tiếng kêu được ví giống tiếng “cười như được mùa”)
Phân Tích Vấn Đề
Functional Requirements
Để giải quyết vấn đề trên, hệ thống phát hiện gian lận cần đáp ứng một số tính năng sau:
- Khai báo nguyên tắc gian lận (rule). Thực thi logic của rule với đầu vào là dữ liệu liên quan tới lịch sử giao dịch, khách hàng, đối tác, lái buôn (merchant), …
- Kiểm tra gian lận. Các đầu use case (authentication, payment, …) cần kiểm tra gian lận trước khi đưa ra quyết định có cho request đi qua
- Gửi thông báo khi có vi phạm tới người phụ trách xử lý
- Xử lý vi phạm. Khi có thông báo vi phạm, người phụ trách xử lý cần phải điều tra, đánh giá vi phạm đó có chính xác hay không? và đánh giá này cần duyệt qua các cấp cao hơn.
Non-functional Requirements
Đối với các tổ chức tài chính, hệ thống tài chính, họ luôn khắt khe với những yêu cầu phi tính năng. Những tính chất đặc biệt được chú ý:
- Performance (hiệu năng). Đầu ghi và đầu đọc là 2 điểm, chúng ta cần tối ưu. Đầu ghi là khối lượng dữ liệu lớn về giao dịch, khách hàng, … cần được tính toán, count, sum, … Đầu đọc là việc trả lời nhanh câu hỏi đối tượng đó có vi phạm hay không và lý do là gì. Như vậy, có 2 khía cạnh về mặt performance chúng ta cần chú ý:
- Latency. Latency thường có đơn vị đo là milliseconds (ms). Tùy vào từng ứng dụng, người ta quan tâm tới average latency hay maximum latency hay percentile latency. Ví dụ, average latency = 50 (ms) nghĩa là thời gian trung bình xử lý là 50ms; 99th-percentile - p(99) = 50 (ms) nghĩa là có 99% requests có thời gian xử lý dưới 50 ms. Như vậy, percentile latency phản ánh chính xác tính ổn định của hệ thống, còn average latency chưa phản ánh đúng tính ổn định.
- Throughput dùng để đo khả năng xử lý của một hệ thống, nó chỉ ra số lượng request mà hệ thống có thể xử lý được trong một đơn vị thời gian.
- Accuracy (tính chính xác). Mọi thứ liên quan tới tiền bạc luôn cần độ chính xác cao.
- Reliability (tính tin cậy). Đảm bảo hệ thống fail-safe. Nếu hệ thống fail thì không gây ra ảnh hưởng lớn (thiệt hại về mặt tài chính, uy tín)
- Availability (tính sẵn sàng). Bước kiểm tra gian lận nằm trong process của use case giao dịch hoặc login nên tính sẵn sàng cao của hệ thống fraud detection sẽ tương đương với những đầu use case này.
Phạm Vi Thiết Kế
Để phát hiện hành vi gian lận, chúng ta có 2 cách tiếp cận chính. Một là dựa vào những quy luật, mẫu hành vi (Rule-Based), hai là dựa vào dữ liệu và học máy (Machine Learning). Cả 2 cách đều ưu nhược điểm, giờ ta cần làm một vài phép so sánh để có thể đưa ra quyết định.
Chú thích:
+: ưu điểm
-: nhược điểm
| Rule-Based Approach | Machine Learning Approach | |
|---|---|---|
| Explainability (Tính diễn giải) |
+ Dễ dàng giải thích vì sao 1 trường hợp cụ thể là vi phạm, gian lận dựa vào rule logic | - Khó giải thích vì logic trong model học máy rất phức tạp, không có pattern chung |
| Scalability (Tỉnh mở rộng) |
- Với mỗi cách thức vi phạm mới, ta cần xác định được pattern và tạo ra rule mới - Rule do con người xác định nên sẽ hạn chế về mặt con người, để lọt các case, risky patterns |
+ Tự động phát hiện những kiểu vi phạm mới + Với dữ liệu càng lớn, ML engine càng “khôn" |
| Deployment & Operation (Phát triển và vận hành) |
+ Các rule có thể dễ dàng thực hiện bởi team backend - Không yêu cầu datasets, có thể vận hành ngay từ những ngày đầu cùng với các hệ thống khác (No cold start) - Với khối lượng rule lớn, việc vận hành và tối ưu resource là một painful |
- Có thể cần cả 1 “đội quân” gồm data engineer, data scientists, MLOps để triển khai model phức tạp & hiệu quả - Yêu cầu datasets ban đầu để training model + Tính tự động cao, hạn chế công việc chân tay, dành nhiều thời gian cho research |
| Accuracy (Độ chính xác) |
+ Độ chính xác của cách tiếp cận này phụ thuộc vào kinh nghiệm của chuyên gia. Tuy nhiên, giai đoạn đầu dữ liệu chưa lớn, cách tiếp cận này đem lại độ chính xác cao | + Với khả năng tự động phát hiện những fraud patterns mới, cộng với lượng dữ liệu đủ lớn, cách tiếp cận này đem lại độ chính xác cao hơn |
Như vậy, Rule-based approach phù hợp với giai đoạn đầu phát triển hệ thống nên mình chọn hướng tiếp cận này. Để tăng độ chính xác bạn có thể kết hợp phát triển cả 2 hướng tiếp cận 😀 Để triển khai được rule-based approach, xử lý luồng (Stream Processing) là cách thức xử lý dữ liệu hiệu quả, và đáp ứng được các yêu cầu phi tính năng của hệ thống. Ở các phần sau, chúng ta sẽ tìm hiểu về Stream Processing và những khó khăn khi xử lý Stream Processing.
Ngoài ra, chúng ta sẽ đề cập về một số kỹ thuật tối ưu ở đầu ghi và đầu đọc.
Bài viết này mình xin phép không đề cập về phần xác định rule, xử lý vi phạm vì nó nặng về mặt nghiệp vụ và hướng tiếp cận machine learning vì mình không có nhiều kiến thức về ML hay AI.
Thiết Kế Tổng Quát
Dựa vào những yêu cầu trên, mình xin phép đưa ra một thiết kế sau:
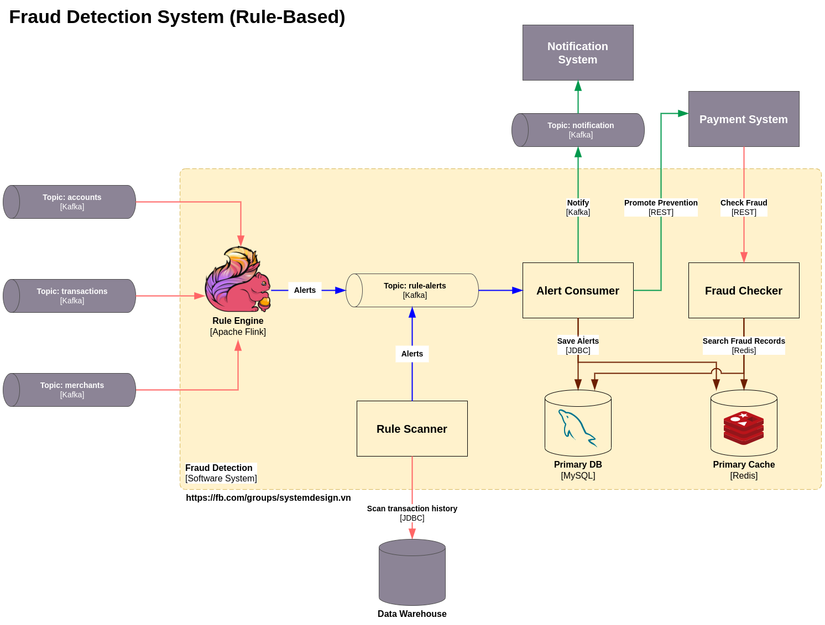
Logic của các rule được thực thi trên Rule Engine với đầu vào là các stream nguồn, cụ thể là các topic Kafka về transactions, accounts, merchants, … đầu ra là những cảnh báo (alert) được bắn vào topic rule-alerts. Ở đây, Rule Engine không trực tiếp đẩy alert vào Database chính (Primary DB) vì khi phát sinh vi phạm, chúng ta cần thực hiện một số hành động nghiệp vụ khác. Do đó, Alert Consumer sẽ bắt alert rồi thực hiện lưu vào Cache, Primary DB rồi gửi thông báo tới người phụ trách xử lý vi phạm thông qua Notification System. Với một số vi phạm đặc biệt, Alert Consumer cần gửi lệnh chặn thanh toán, đăng nhập, … tới đầu use case tương ứng như Payment System, IAM System, … Ngoài ra, không phải tất cả rule đều có yêu cầu latency nhỏ, đối với rule không khắt khe về mặt latency, chúng ta có thể định kỳ chạy job trên Rule Scanner quét những vi phạm dự vào lịch sử giao dịch được lưu ở Database hoặc Data Warehouse rồi sau đó đẩy vi phạm vào topic rule-alerts. Fraud Checker phơi API cho các đầu use case (Payment System) gọi vào để kiểm tra có đối tượng gian lận không.
Rule Engine ở đây sử dụng công nghệ Apache Flink. Apache Flink là hệ thống xử lý luồng phân tán (a distributed stream processing system). Vậy Stream Processing là gì? Trước khi tìm hiểu khái niệm này, mình muốn đề cập tới khái niệm streaming bởi vì chính mình trước đây nhầm lẫn và đánh đồng hai khái niệm này làm một. Streaming ám chỉ quá trình truyền tải dữ liệu liên tục thông qua mạng máy tính. Mặt khác, Stream Processing là quá trình xử lý dữ liệu được truyền tải dưới dạng stream liên tục. Ví dụ trong nhà nước nước ngọt, Streaming tương ứng với băng truyền, có nhiệm vụ truyền tải chai nước (gói tin) tới các máy hoặc robot để được xử lý. Còn Stream Processing tương ứng với quá trình xử lý chai nước, đong nước hoặc quá trình đóng thùng của các máy, robot.
Tại sao dùng Stream Processing? Để trả lời câu hỏi này, chúng ta cần làm một vài phép so sánh với 2 cách xử lý dữ liệu truyền thống là Request/Response Processing và Batch Processing.
| Request/Response Processing |
Batch Processing | Stream Processing | |
|---|---|---|---|
| Latency | Low (real-time) |
High (depend on scheduled time) |
Medium (near real-time) |
| Throughput | Low | High | High |
Dựa vào bảng trên, Stream Processing đáp ứng được yêu cầu về Latency và Throughput của 1 hệ thống phát hiện gian lận.
Đến đây, hẳn nhiều bạn sẽ nảy ra 1 câu hỏi khác: Vậy với latency thấp, throughput cao, tại sao không dùng Stream Processing để thay thế Request/Response Processing hoặc Batch Processing cho các use case khác? Để đạt được metric như trên, một hệ thống Stream Processing tốn nhiều tài nguyên để quản lý state và xử lý song song với throughput lớn so với 2 cách xử lý còn lại. Dẫn đến, vận hành một 1 hệ thế Stream Processing lớn không đơn giản và tốn kém. Vậy chúng ta cập nhật lại bảng trên như sau:
| Request/Response Processing |
Batch Processing | Stream Processing | |
|---|---|---|---|
| Latency | Low (real-time) |
High (depend on scheduled time) |
Medium (near real-time) |
| Throughput | Low | High | High |
| Operation | Medium | Low | High |
| Resource | Medium | Low | High |
Tại sao dùng Flink? Flink được thiết kế với khả năng mở rộng cao, tính chịu lỗi tốt, phù hợp với xử lý khối lượng dữ liệu lớn. Một số tiêu chí nổi bật:
- Rich features: nhiều tính năng về dataflow, savepoints, dashboard, …
- Big community: Apache Flink open source vào năm 2014, có cộng đồng mạnh, nhiều công ty lớn sử dụng như Netflix, Uber, AWS, Apple, Pinterest, Stripe, …
- Configurability: Flink có phép cấu hình nhiều thuộc tính để tunning theo yêu cầu về performance, reliability, recoverability, …
- True Stream Processing: so với Apache Spark, Spark được thiết kế cho việc xử lý micro-batch với high throughput, dataset lớn. Trong khi Flink được thiết kế xử lý data stream với low latency, high throughput.
Thiết Kế Chi Tiết
Đầu tiên, API kiểm tra gian lận (đầu đọc) cần được tối ưu do các đầu use case quan trọng gọi vào. Logic kiểm tra có thể phức tạp, kiểm tra nhiều đối tượng, nhiều nguồn cùng lúc. Ví dụ trong một giao dịch, cần kiểm tra cả người gửi và gửi nhận, mỗi user gian lận sẽ có 1 key trong cache. Như vậy, thay vì check từng key trong Redis thì để hạn chế gọi I/O, ta có thể dùng command MGETS hoặc KEYS để lấy nhiều key cùng 1 lúc. Trường hợp, có thêm các nguồn check gian lận khác so với primary cache, ta nên xử lý concurrency để giảm latency. Ngoài ra, để tăng throughput cho API, chúng ta có thể áp dụng thêm cơ chế nonblock.
Tiếp theo tới đầu ghi, chúng ta cần trả lời được tại sao Stream Processing lại đạt được performance tốt nói chung và đối với Apache Flink nói riêng. So sánh với cách truyền thống là dựng consumer consume các topic đầu vào và thực hiện 1 job ứng với mỗi request/event. Trong đó, 1 job gồm nhiều bước (về mặt logic) được thực hiện trên cùng 1 thread và dữ liệu của từng bước lại được lấy từ hoặc lưu xuống Database. Cách này có hạn chế về khả năng mở rộng và latency. Stream Processing lại có 1 cách tiếp cận khác, 1 job được chia thành nhiều task nhỏ (về mặt physic), 1 logical step có thể tương ứng với 1 hoặc nhiều task. Các task có thể đặt ở các thread khác nhau, các máy khác nhau.
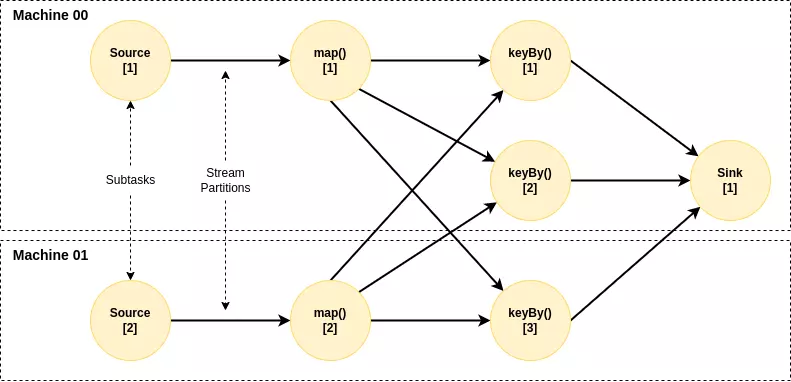
Việc tách job ra thành nhiều task nhỏ có 2 mục đích chính:
- Giúp tăng khả năng mở rộng: khả năng xử lý song song, khả năng phân tán.
- Tối ưu resources. Bạn thử tưởng tượng resource của 1 máy tương ứng với khoảng trống của 1 cái lọ. 1 job truyền thống như 1 viên sỏi liền khối, còn 1 task nhỏ của Stream Processing như những hạt cát. Cho đầy cái lọ thứ nhất bằng sỏi, cho đầy lọ thứ hai bằng cát. Dễ thấy cái lọ với sỏi để lộ ra nhiều khoảng trống hơn nhiều so với cái lọ với cát.
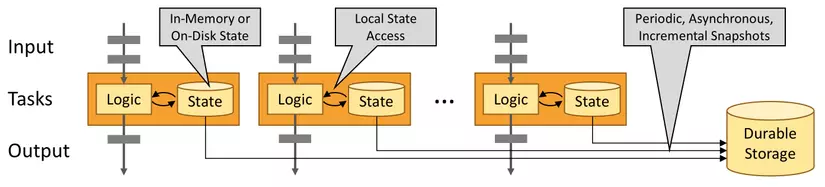
Có nhiều kỹ thuật để giảm latency trong Stream Processing, 1 kỹ thuật chính đó là mỗi task quản lý một local state tương ứng (tập dữ liệu con của dataset/state và không trùng giữa các task/operator) giúp giảm thời gian tìm kiếm và (có thể) được đặt cùng máy vật lý với task giúp giảm network latency khi gọi lấy dữ liệu.
Một trong những cách học thiết kế hệ thống hiệu quả đó là tìm hiểu kiến trúc lõi (internal architect) và cách thức hoạt động bên trong của các hệ thống open source nổi tiếng. Để tăng performance, đảm bảo reliability, accuracy, Apache Flink áp dụng nhiều kỹ thuật và công nghệ như RocksDB, Credit Based Flow Control, Task Chaining, Checkpoints, … Mình sẽ trình bày về kiến trúc và các cơ chế này của Flink ở các bài viết khác.
Trước khi quyết định áp dụng một công nghệ, ta cần đánh giá kỹ nhược điểm và những khó khăn khi làm việc với công nghệ đó. Dưới đây ta điểm lại những khó khăn chính khi làm việc với Apache Flink:
- Learning Curve: Có thể là khó và mất chút thời gian đối với beginner để hiểu được những khái niệm của Stream Processing. Đối với những ứng dụng đơn giản, chúng ta có thể sử dụng high-level API của Flink (Table API, SQL) để giảm learning curve cho dev.
- Debugging: Do các components trong một ứng dụng Flink được chạy trên nhiều máy khác nhau nên dev cần làm quen với Flink web dashboard và log để debug.
- Tối ưu State: Dev cần hiểu cách thức quản lý state (state backend) để cấu hình state strategy làm sao cho phù hợp với yêu cầu về scalability, reliability và recoverability và tránh leaking state.
- Resource Management: Đối với những ứng dụng với scale size lớn, làm sao để đảm bảo tất cả các tasks được chia đều trong cluster và mỗi task có đủ resources để vận hành trơn tru. Việc quản lý resources khá phức tạp, tuy nhiên Flink tích hợp với nhiều tools như YARN, Ververica, Kubernetes, … giúp cho việc quản lý này trở nên đơn giản hơn nhiều,
- Performance Tuning: Cần hiểu cách sắp xếp các task, data transfer giữa các task và thiết kế một dataflow tinh gọn để đạt được performance tốt nhất.
Quay lại với rule, có một lưu ý là bất kể ai cũng có thể là gian lận, từ khách hàng cho đến đối tác, kể “người trong nhà”. Do đó, cần xác định tập rule cho từng đối tượng để giảm thiểu thiệt hại.
Định Hướng Phát Triển
- Cung cấp một Domain Specific Language (DSL) hoặc giao diện ở mức high level làm giảm learning curve cho dev hoặc cho chuyên gia có thể tự khai báo những rule mới.
- Tích hợp thêm Machine Learning để tăng độ chính xác và tự động bắt được những fraud pattern mới.
- Quản lý, phê duyệt vi phạm.
- Đồng bộ Datasource với Cache.
Tổng Kết
Qua bài viết chúng ta nắm được những yêu cầu phi tính năng và thiết kế của một hệ thống phát hiện gian lận. Thêm vào đấy là những kỹ thuật để tối ưu đầu đọc và đầu ghi. Cuối cùng, chúng ta tìm hiểu một số khái niệm cơ bản của Stream Processing và Apache Flink.
Cám ơn anh em đã đọc hết bài viết 🙏
Nếu anh em thấy hay thì cho mình xin 1 upvote và 1 share nhé. Cám ơn anh em rất nhiều 🙏
📚️ Ronin Engineer: https://ronin-engineer.github.io/register-post
🏢 System Design VN: https://fb.com/groups/systemdesign.vn
Tham Khảo
- Book Stream Processing with Apache Flink by Fabian Hueske, Vasiliki Kalavri
- https://nightlies.apache.org/flink/flink-docs-master/docs/concepts/flink-architecture/
- Ververica Youtube Channel: https://www.youtube.com/@ververica
- https://data-flair.training/blogs/comparison-apache-flink-vs-apache-spark/
- https://stackshare.io/stackups/flink-vs-spark
- https://shopify.engineering/optimizing-apache-flink-applications-tips
⚠️ Nhóm mình đang tuyển writer và graphic designer nếu anh em có hứng thú thì comment ở dưới giúp mình nhé. Khi tham gia anh em có quyền lợi sau:
- Trau dồi kỹ năng viết, kỹ năng chuyên môn
- Được chia sẻ tài liệu nghiên cứu
- Kết nối, học hỏi từ anh em trong nhóm
All rights reserved
