The Quality of Software Design ~Kỳ 5~
Bài đăng này đã không được cập nhật trong 4 năm
Part 5. Efficiency, Entrance of the dark abyss
Từ đầu đến số trước, tôi đã nói về vấn đề trừu tượng hóa design dựa trên Reusability. Lần này, tôi muốn các bạn thử suy nghĩ về Efficiency. Trước khi vào chủ đề chính tôi có vài lời trước gửi tới các bạn. Chủ đề lần này rất khó. Các bạn không cần phải hiểu toàn bộ logic hay coding mà chỉ cần nắm được từ khóa là mục đích và phương pháp luận của nó cũng được. Nếu có cơ hội, tôi muốn các bạn học thêm về phần này.
Đầu tiên chúng ta hãy bắt đầu từ chỗ Efficiency là gì? Việc định nghĩa "hiệu suất" thực ra không hề đơn giản chút nào. Nếu cứ cố gắng đơn giản hóa nó đi thì ví dụ trong trường hợp nói là "Làm sao để kết thúc xử lý "với hiệu suất tốt"" thì sẽ gặp phải vấn đề "Nhìn từ đâu thấy hiệu suất tốt?". Điều thường được nghĩ đến đầu tiên là "Nhìn từ phía User thấy hiệu suất tốt". Điều này vô cùng dễ hiểu. Khi con người ta muốn làm điều gì đó thì nếu việc đó càng kết thúc nhanh, người ta càng cảm thấy có hiệu suất tốt. Đây là [hiệu suất thời gian trong hiệu suất công việc]
Trong khi đó trên phương diện [Hiệu suất nhìn từ CPU] thì thực ra khá phức tạp. Bởi vì việc đánh giá dựa trên tiêu chuẩn nào thực ra chưa rõ ràng. Đại khái thì có 2 tiêu chuẩn đánh giá.
- Trường hợp lấy hiệu suất thời gian làm tiêu chuẩn đánh giá Nghĩa là việc đánh giá hiệu suất xử lý dựa trên việc xử lý đó tiêu tốn bao nhiêu thời gian của CPU. Điểm khác nhau của tiêu chuẩn này với "hiệu suất thời gian nhìn từ phía User" mà tôi nêu vừa nãy là việc đánh giá dựa trên quan điểm của CPU chứ không phải của User. Chẳng hạn như nếu chỉ có 1 CPU (hoặc là máy tính liên quan) và CPU này không kết nối mạng thì hiệu suất thời gian trong trường hợp này gần như tương tự với hiệu suất thời gian nhìn từ phía User. Nhưng, thời đại ngày nay hầu như các hệ thống đều là dạng multicore, multiCPU, client server, cloud v.v.. nghĩa là không chỉ gói gọn trong phạm vi 1 CPU nên hiệu suất thời gian của CPU không giống với hiệu suất thời gian nhìn từ phía user.
- Trường hợp lấy tài nguyên tiêu hao làm tiêu chuẩn đánh giá Vốn dĩ "tài nguyên" ở đây là chỉ những tài nguyên nói chung của máy tính như "thời gian sử dụng CPU, memory, disk space" nhưng do giá cả bộ nhớ, ổ đĩa giảm khiến cho người ta ngày càng không mấy quan tâm đến vấn đề này. (Tất nhiên là với những hệ thống như hệ thống nhúng nghĩa là phải phát triển trên cơ sở điều kiện tài nguyên có hạn thì đến nay đây vẫn là tiêu chuẩn đánh giá quan trọng). Vì vậy, gần đây xuất hiện cách nghĩ lấy "Điện năng tiêu hao của hệ thống" làm tiêu chuẩn đánh giá tài nguyên. Có thể nói đây là cách nghĩ phát sinh cùng với việc đẩy mạnh hoạt động cắt giảm lượng khí thải do hiệu ứng nhà kính. Đây là suy nghĩ lấy tiêu chuẩn là tiêu hao tài nguyên của không chỉ CPU, memory, disk space mà của cả thiết bị mạng, thiết bị hiển thị nữa. Tuy nhiên, cách nghĩ này cũng chưa phổ biến.
Những quan điểm này nếu nhìn qua sẽ không thấy khác nhau nhiều lắm. Nhưng nếu thử xét ở một trường hợp cụ thể thì có thể thấy được sự khác nhau.
Ví dụ trường hợp tìm kiếm trong DB chứa 100 records data. DB nào cũng được. Để dễ hình dung, chúng ta hãy chọn DB có lưu trường [Name] và [Phone number]

Nhưng nếu lấy tên thì nhiều khi không đảm bảo được tính thống nhất (nhất là ở Việt Nam!) nên chúng ta hãy chọn DB có lưu [mail address] và [Phone number]
Đơn giản nhất là chúng ta có 100 records data như thế này. Ở đây là [Hệ thống tìm kiếm phone number từ mail address]. Đầu tiên chưa nghĩ đến màn hình Input và output vội mà chúng ta hãy nghĩ về hiệu suất của riêng chức năng tìm kiếm đã.
Đầu tiên, solution đơn giản nhất trong trường hợp thực hiện tìm kiếm từ đầu đến khi tìm thấy record muốn tìm thì sẽ xử lý như thế nào. Tham chiếu đến DB bằng ID lần lượt từ 1 cho đến khi tìm thấy Data đối tượng tìm kiếm thì liên tục increment ID.
(Tham chiếu DB So sánh Output kết quả)
Nếu là logic cho chạy xử lý này cho đến khi tìm thấy record đích thì sẽ mất thời gian hồi đáp trung bình là 50 cycle (1 cycle tính bằng 1 xử lý này). Hiệu suất thời gian nhìn từ khách hàng là 50. Ngoài ra, số lần xử lý trung bình của CPU cũng là 50 nên hiệu suất thời gian nhìn từ phía CPU cũng là 50.
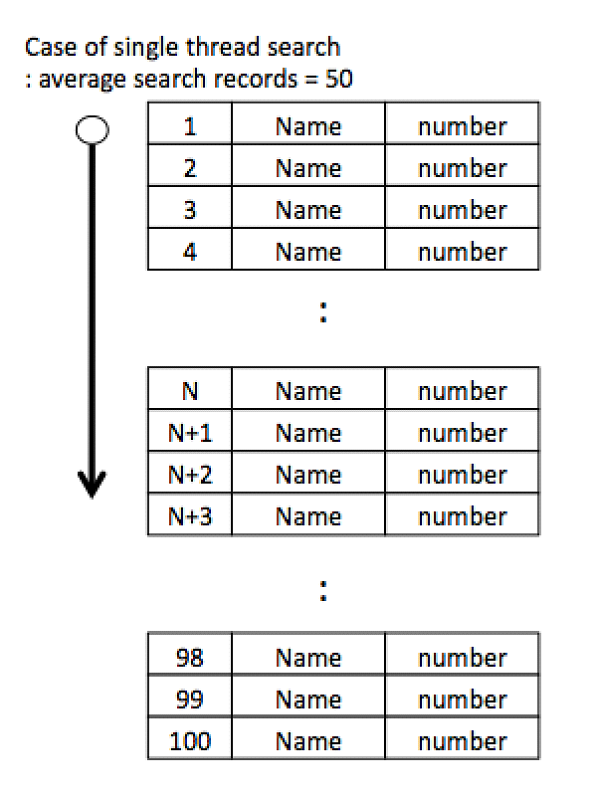
Tiếp theo hãy thực hiện xử lý search này ở 2 thread. Cụ thể là thread thứ 1 sẽ tìm kiếm từ ID 1 đến 50, thread thứ 2 tìm kiếm từ ID 51 đến 100. Nếu nói đúng ra thì cần phải có xử lý dừng thread còn lại nếu như tìm được record đối tượng ở thread kia nhưng tạm thời chúng ta chưa xét tới việc này mà chỉ xét đến thời gian response thì hẳn là các bạn có thể hieur được trung bình thời gian response là 25 đơn vị. Hay nói cách khác, hiệu suất thời gian nhìn từ quan điểm của user là 25. Nhưng còn CPU thì sao, ở đây cho 2 thread chạy đồng thời nên cuối cùng thì hiệu suất thời gian của CPU vẫn là 50. Như vậy, theo quan điểm user thì là hiệu suất tốt còn quan điểm hiệu suất thời gian của CPU thì vẫn không thay đổi.

Nếu chỉ xét trong trường hợp đơn giản như thế này thì chúng ta có thể trải nghiệm sự khác biệt của hiệu suất thời gian theo quan điểm user và hiệu suất thời gian theo quan điểm CPU.
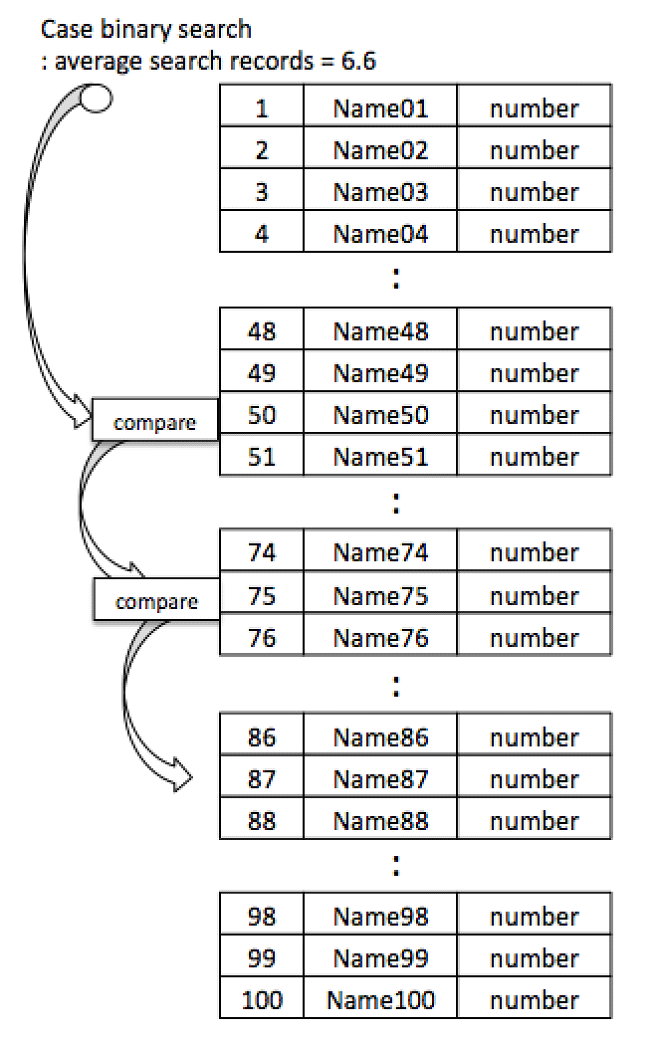
Vậy, tiếp theo thiết kế để cho DB này được sort bằng name.
Kiểu như trên. Thiết kế để áp dụng logic binary search. Vậy, xử lý sẽ thành như thế nào? Vì thời gian search khi dùng binary search là log2(N) nên nếu số lượng sample là 100 thì có thể output kết quả trong thời gian khoảng hơn 6.6 một chút. Mặc dù dùng cách này thì vẫn mất thời gian ở chỗ xử lý binary search nhưng hiệu suất thời gian theo quan điểm user lại giảm được tận 1 chữ số. Hơn nữa, hiệu suất thời gian CPU cũng được cải thiện 1 chữ số. Thật là tuyệt vời!
Nhưng…
Chúng ta không được quên tiền đề là DB này [đang được sort]. Dựa trên tiền đề đó, hiệu suất thời gian đang được cải thiện tới 1 chữ số nhưng chúng ta không được quên rằng việc "sort' cũng gây tiêu hao resource ngoài hoặc tài nguyên CPU. Tóm lại, trường hợp nếu chỉ tính hành động search không thôi thì thấy rằng hiệu suất thời gian được cải thiện đáng kể nhưng hiệu suất tiêu hao resource các phần khác so với trường hợp [không sort] thì kém hơn. Cần phải cân nhắc kỹ "Tiêu hao resource ở đâu" và "cải thiện hiệu suất thời gian ở chỗ nào" trong khi thiết kế hệ thống. Ví dụ:nếu là [DB tuyệt đối không update record] thì chỉ cần tạo DB ban đầu sau khi đã sort theo index nào đó là có thể tăng tối đa hiệu suất thời gian khi chạy. Tất nhiên, chẳng có "DB tuyệt đối không update record" nên đây là cách không hữu dụng nhưng nếu suy nghĩ solution đó cho trường hợp "cực đoan" thì cũng không phải là chuyện tồi.
Vậy, trong ví dụ tiếp theo ta sẽ xét trường hợp DB chưa sort, giả thuyết số thread là 10. Có 10 thread nghĩa là đối tượng search của mỗi thread là 10 record. Kết quả của solution này là hiệu suất thời gian theo quan điểm của user sẽ giảm xuống 5. Cách này thành công ở chỗ có hiệu suất thời gian theo quan điểm user hơn cả cách dùng binary search. Tuy nhiên, trong trường hợp này cần chú ý "đồng bộ thread". Khi tìm thấy record đối tượng ở thread nào đó thì phải dừng xử lý ở các thread khác. (À nhưng có lẽ cũng không nhất thiết phải dừng xử lý ở các thread khác. Chủ đề này chúng ta hãy bàn sau nhé.) Nếu đưa cơ chế đồng bộ vào thì 1 cycle hoạt động sẽ như sau.
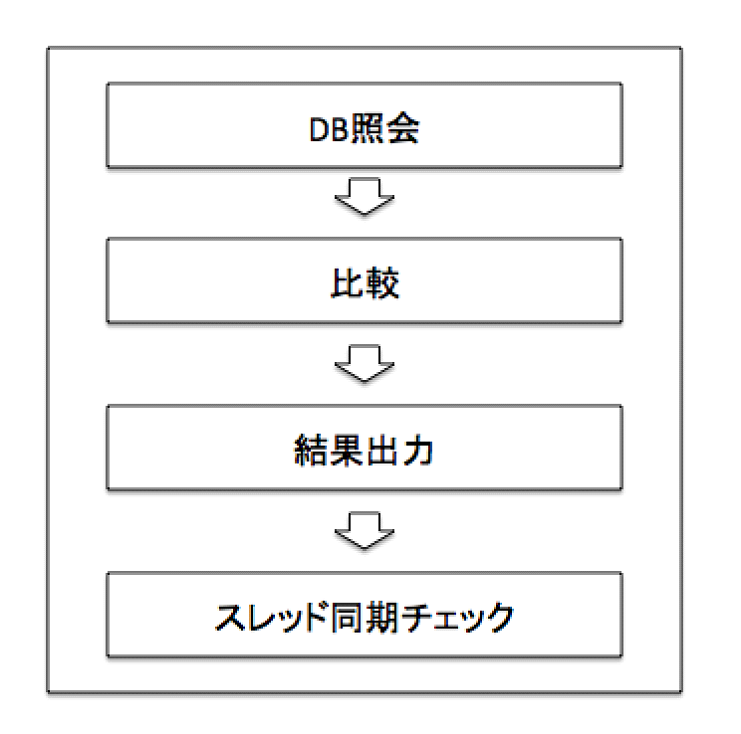
(Tham chiếu DB So sánh Output kết quảCheck đồng bộ thread)
Trong xử lý check đồng bộ thread sẽ thực hiện check xem có tín hiệu (signal) dừng từ các thread khác hay không, nếu có tín hiệu được truyền về thì sẽ dừng loop thread. Ngoài ra, thread tìm thấy record đối tượng sẽ generate ra tín hiệu dừng để dừng các thread khác.
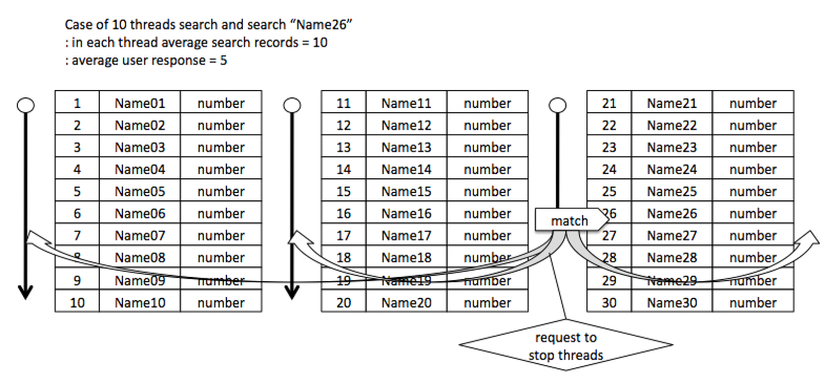
Dựa trên cơ sở đưa cơ chế như vậy vào thì sẽ cần 50 cycle để chạy cho đến khi kết thúc search nên sẽ thu được kết quả là [Hiệu suất thời gian CPU là 50 + (Hiệu suất thời gian check đồng bộ threadx50)]. Tóm lại, cách này sẽ có thời gian thực hiện chỉ bằng 1/10 so với cách tìm từng record 1 ở các thread đơn nhưng tiêu hao thời gian CPU lại tăng lên.
Hãy giả thuyết trường hợp hi hữu hơn nữa. Giả sử có 100 thread tìm kiếm. Như vậy xử lý sẽ như thế nào? Như vậy hiệu suất thời gian theo quan điểm User sẽ bằng 1/100. Nhưng trường hợp này cần phải có các bước chuẩn bị như generate của thread, allocate resource v.v.. nên tất nhiên không đơn giản để có thể biến hiệu suất thời gian thành như vậy. Tuy nhiên, kể cả trong trường hợp như vậy vẫn có thể thấy được rằng có thể cải thiện ở mức tương đương. Trong trường hợp này thì hiệu suất thời gian CPU như thế nào? Mỗi thread trong 100 thread chạy 1 cycle là kết thúc nên hiệu suất thời gian CPU là 100. Thực tế như vậy là đã tệ hơn gấp đôi so với tình trạng ban đầu. Vậy, hãy xét về xử lý đồng bộ thread trong trường hợp có 100 thread này. Vốn dĩ chia 100 record cho 100 thread nên không cần loop. Tóm lại là nếu kết thúc 1 cycle thì chỉ cần kết thúc không vấn đề gì là được. Cho nên tất nhiên là không cần xử lý đồng bộ.
Nhân tiện, ở đây chúng ta hãy cùng xem xép trường hợp 10 thread mà ban nãy tôi đã nói là "sẽ thảo luận sau". Giả sử như không check đồng bộ thread mà chạy loop thôi thì sẽ như thế nào? Thực ra thì sẽ chẳng có gì xảy ra. Thread tìm thấy matched record sẽ output kết quả là xong nhưng những thread khác sẽ tiếp tục tìm cho đến khi không còn record được assign nữa. Về mặt hệ thống thì đã tìm thấy record đối tượng rồi nhưng các thread khác lại không biết điều đó nên chúng sẽ tiếp tục chạy xử lý tìm kiếm mà chắc sẽ không tìm thấy được record cần tìm. Khi đã duyệt hết những record được assign rồi thì sẽ được kết quả là "Rất tiếc nhưng không tìm thấy" và kết thúc xử lý.
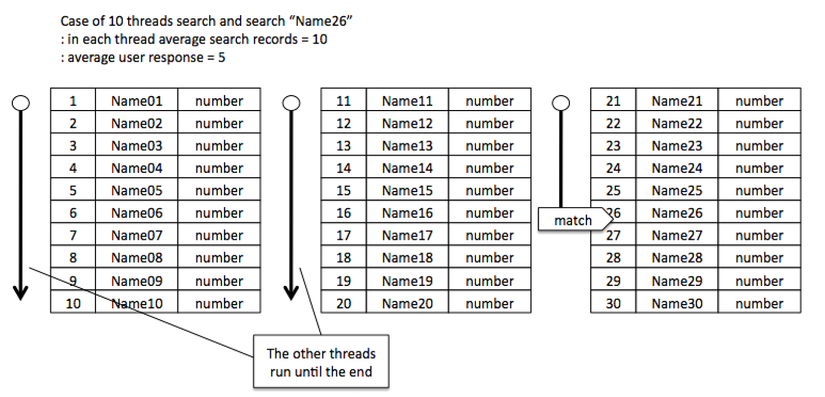
Nếu đo hiệu suất thời gian CPU trong trường hợp này [từ lúc bắt đầu hoạt động đến lúc lấy được kết quả] thì vẫn sẽ là 50. Tuy nhiên, ngay cả sau khi output kết quả thì các thread khác vẫn tiếp tục chạy. Thread chứa record cần tìm trung bình chạy 5 cycle còn 9 thread khác thì bắt buộc phải chạy hết cả 10 cycle nên kết quả là hiệu suát tài nguyên "từ lúc bắt đầu hoạt động đến khi kết thúc chạy" là 95. Nếu không cần quan tâm gì đến việc tiết kiệm năng lượng thì có thể cân nhắc đến cách code này. Thực ra điều này còn phải phụ thuộc vào kết quả so sánh chi phí trong trường hợp có thực hiện đồng bộ thread và trường hợp không thực hiện. Nếu kết quả là thời gian thực hiện xử lý tìm kiếm của các thread vô cùng ngắn, thấp hơn chi phí để check đồng bộ thì cũng có thể thiết kế mà không thực hiện check đồng bộ. Nói chung, các bạn cần hiểu được rằng không thể nói là dùng cách nào thì tốt hơn. Tất nhiên, chúng ta không thể quên trường hợp không check đồng bộ thread thì khi đang search toàn bộ record (một cách lãng phí) mà có request mới phát sinh thì các thread đó không thể response ngay.
Không biết các bạn có thể thử trải nghiệm một lần suy nghĩ về logic tìm kiếm trong DB có số record tối đa là 100 được không? Bởi vì khi bắt đầu suy nghĩ đến việc đưa ra vấn đề về "hiệu suất" thì ngay cả với model đơn giản này cũng có thể có rất nhiều cách tiếp cận khác nhau. Trong lập trình hiện nay, model càng phức tạp thì cách tiếp cận càng đa dạng, phức tạp hơn.
Trong số báo lần này tôi đã đi từ vấn đề định nghĩa nguyên gốc "hiệu suất" là gì đến chuyện hiệu suất thời gian theo logic và dùng multi-thread để cải thiện hiệu suất thời gian. Lần tới, tôi định sẽ nói chuyện về [Cache], [dự đoán phân nhánh]. Đây là nội dung còn khó hơn nhưng các bạn hãy tiếp tục đón đọc nhé.
All rights reserved
