Tạo API server trên Node.js với Express và MongoDB (part 2)
Bài đăng này đã không được cập nhật trong 4 năm
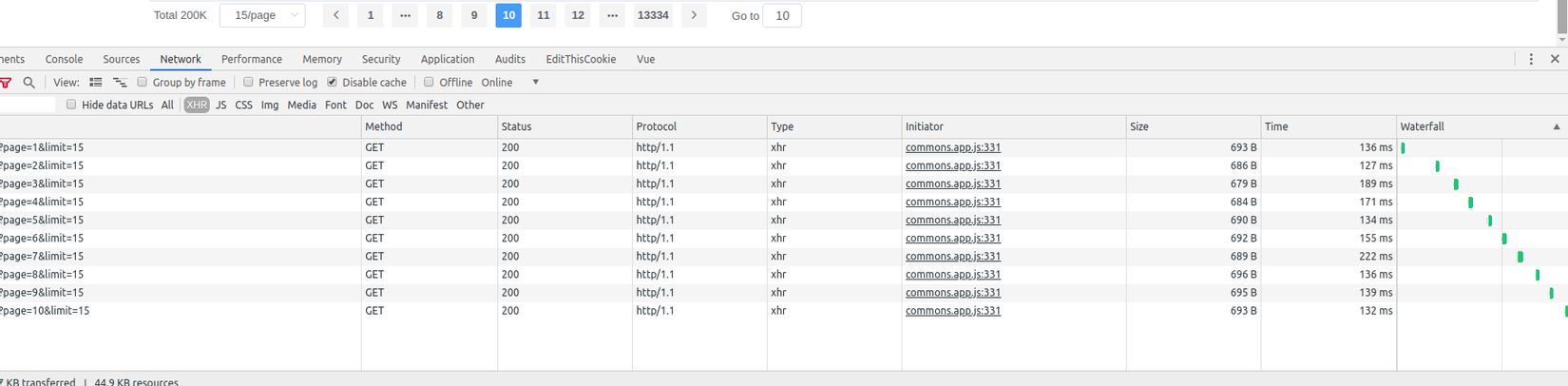
Ảnh minh họa: Khi collection có 200 nghìn documents
Xin chào mọi người, tiếp tục với bài viết lần trước: Tạo API với Express.js + Mongodb. Mình cũng nhận được request như muốn hướng dẫn build cả API và giao diện trọn vẹn. Tuy nhiên mình cũng chưa viết thành tut được.
Ngoài ra cũng có một issue mà mình và một số bạn có thể gặp phải qua bài viết lần trước đó là về việc phân trang khi lấy danh sách posts. Với ứng dụng lưu trữ ít, chỉ vài trăm nghìn document trong một collection thì có vẻ mọi thứ vẫn tốt đẹp như trên. Nhưng, khi kích thước tăng lên từ 1 triệu documents, bạn đã thấy khác biệt khi thời gian phản hồi tăng lên, cảm giác ứng dụng bị chậm dần. Và thực sự đúng là như vậy:
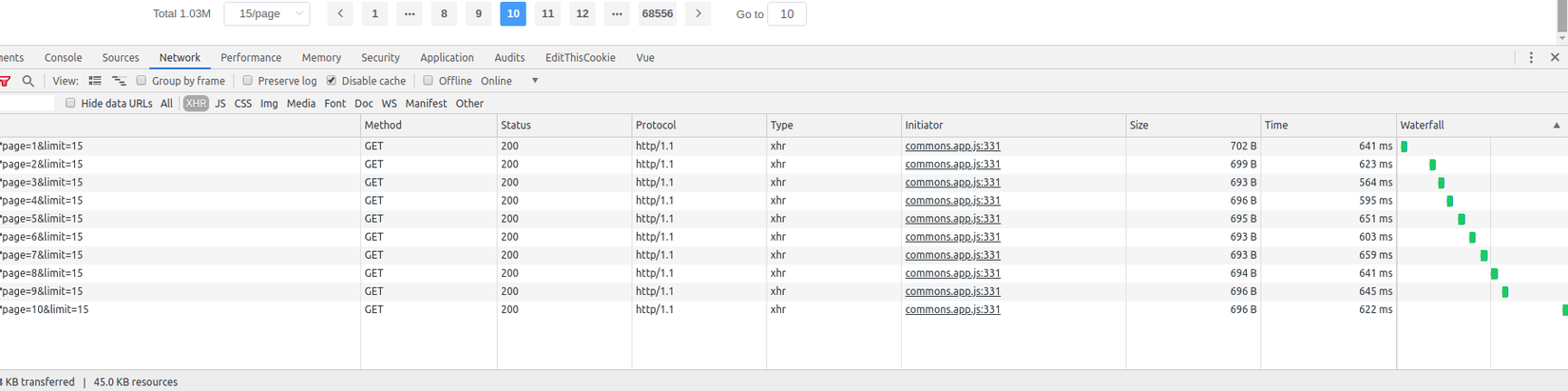
Ảnh minh họa: Khi collection có 1 triệu documents
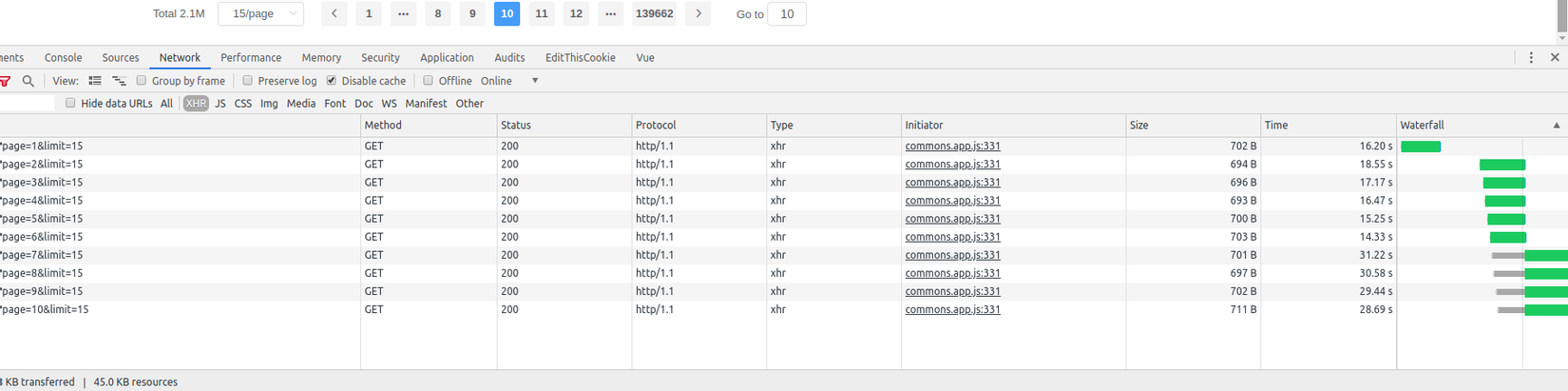
Ảnh minh họa: Khi collection đạt tới 2 triệu documents
Trời ơi tin được không, một request mà mất tới 16s mới có response. Thật không thể tin được  . Vậy nên bài này mình sẽ viết và cùng các bạn tìm hiểu và resolve issue trên nhé.
. Vậy nên bài này mình sẽ viết và cùng các bạn tìm hiểu và resolve issue trên nhé.
Mức độ ảnh hưởng
Như vậy, nó sẽ ảnh hưởng như nào tới hệ thống của chúng ta nhỉ?
- Gây ảnh hưởng trực tiếp tới trải nghiệm người dùng khi sử dụng chức năng có dùng trực tiếp API trên.
- Ngoài ra, cũng gián tiếp ảnh hưởng tới các service khác dùng chúng vì có time khá lớn.
- Nghiêm trọng hơn, nếu số lượng documents tăng lên 3 triệu, 5 triệu, 10 triệu thì không bao lâu, cái API kia thậm chí sẽ quá timeout và không có response luôn. Khi bị gọi quá nhiều, memory cũng sẽ tăng lên cao và số lượng request được xử lý bị giảm đi. Khi tới cực đại, sẽ có các request bị "từ chối" vì quá tải.
Nguyên nhân
Trước tiên, chúng ta cùng nhìn lại đoạn code cũ xử lý việc lấy danh sách posts ra nha:
router.get('/posts', async (req, res) => {
try {
const options = {
sort: { _id: -1 },
limit: parseInt(req.query.limit || 20, 10),
page: parseInt(req.query.page || 1, 10)
}
const posts = await Post.paginate({}, options)
return res.send(posts)
} catch (e) {
return handlePageError(res, e)
}
})
Trong bài viết trước, đoạn code API lấy danh sách documents trong collection posts đưa ra khá ngắn gọn và đơn giản. Chỉ sử dụng một method paginate cung cấp bởi plugin cho mongoose là mongoose-paginate-v2. Như vậy, issue này rất có thể do logic phân trang bên trong plugin. Cũng không ngoại trừ khả năng là do collection này được khai báo và có vấn đề gì đó, nên khi query data ra bị chậm.
Tìm hiểu và khắc phục
Để xen vấn đề do đâu, chúng ta hãy thử cách khác để lấy dữ liệu cho một trang nhé. Dùng cách truyền thống với find và limit như sau coi tốc độ query ra sao:
// ....
const posts = await Post.find().limit(20)
return res.send(posts)
Tốc độ truy vấn rất nhanh, chưa đầy 30ms đã có response về. Bây giờ, có thể khẳng định là do việc phân trang với plugin trên có vấn đề. Cách đơn giản nhất là chúng ta tự thực hiện phân trang luôn mà không cần dùng tới plugin để ứng dụng chạy trơn chu trở lại. Ngoài ra, cũng có thể tạo issue và pull request để fix lỗi cho plugin trên.
Mình sẽ viết thực hiện phân trang luôn nhé. Có một số cách hữu hiệu để phân trang nhanh collection như sau:
C1: Sử dụng find, skip và limit
Sử dụng thuật toàn phân trang với skip và limit. Trong đó:
limitđể lấy đúng số lượng documents trong một trangskipđể bỏ qua số documents ở các trang trước trang hiện tại.
Lúc này, đoạn code sẽ trở thành như sau:
router.get('/posts', async (req, res) => {
try {
const perPage = parseInt(req.query.limit || 20)
const page = parseInt(req.query.page || 1)
const query = Post.find().sort({ _id: -1 })
const data = await query.skip((page - 1) * limit).limit(perPage)
const totalDocuments = await query.countDocuments()
const totalPage = Math.ceil(totalDocuments / perPage);
return res.send({
data,
meta: {
page,
perPage,
totalDocuments,
totalPage,
}
})
} catch (e) {
return handlePageError(res, e)
}
})
Ở đoạn code trên có thực hiện thêm một truy vấn để đếm tổng số documents. Nếu không cần thiết bạn có thể bỏ truy vấn này cũng được.
C2: Đơn giản với find và limit
Một cách khác, chúng ta không dựa vào số trang hiện tại nữa. Mà sẽ dùng id của document cuối cùng trong lần request trước đó. Logic sẽ hiểu kiểu như này: "Lấy 20 documents tiếp theo sau document có id là xxx".
Cách triển khai như sau:
router.get('/posts', async (req, res) => {
try {
const lastDocumentId = req.query.last_doc_id
const perPage = parseInt(req.query.limit || 20)
const query = Post.find({ _id: { $gt: lastDocumentId } }).sort({ _id: -1 })
const data = await query.limit(perPage)
return res.send({ data })
} catch (e) {
return handlePageError(res, e)
}
})
Tổng kết
Sau khi áp dụng một trong 2 cách trên, request sẽ có response trong ~40ms. Nhanh như lúc mới đầu . Tới đây chúng ta đã resolve được issue về thời gian phản hồi của request trong part 1. Nếu có bất kỳ vấn đề gì, mời các bạn cùng comment góp ý phía bên dưới bài viết nhé. Rất cảm ơn các bạn đã quan tâm và đón đọc bài viết của mình.
 Nếu thấy nội dung này bổ ích, hãy mời tôi một tách cà phê nha! https://kimyvgy.webee.asia
Nếu thấy nội dung này bổ ích, hãy mời tôi một tách cà phê nha! https://kimyvgy.webee.asia
All rights reserved
