
Sử dụng HyDE để cải thiện hiệu năng RAG cho LLM
Như các bạn đã biết, Retrieval Augmented Generation (RAG) là một phương pháp hiệu quả giúp các mô hình ngôn ngữ lớn có thể truy cập vào cơ sở dữ liệu thông tin bên ngoài mà không cần phải fine-tune mô hình. Một pipeline RAG cơ bản bao gồm một truy vấn từ người dùng (user query), một mô hình embedding có nhiệm vụ chuyển đổi văn bản thành các embedding (các vector số học trong không gian nhiều chiều), một bước truy xuất (retrieval) nhằm tìm kiếm các tài liệu có liên quan tới truy vấn của người dùng trong không gian embedding, và một mô hình ngôn ngữ lớn (LLM) sử dụng các tài liệu đã được truy xuất để tạo ra câu trả lời cho truy vấn người dùng [1].
Trong thực tế, bước truy xuất đóng vai trò rất quan trọng trong RAG pipeline. Nếu bộ truy xuất (retriever) không tìm được tài liệu chính xác trong tập văn bản (corpus), mô hình ngôn ngữ lớn sẽ không thể tạo ra câu trả lời chắc chắn và chính xác.
Một vấn đề trong bước truy xuất có thể là truy vấn của người dùng là một câu hỏi rất ngắn, bị sai ngữ pháp, chính tả, dấu câu,… trong khi tài liệu tương ứng lại là một đoạn văn dài, được viết chỉn chu và chứa thông tin mà chúng ta cần tìm.

HyDE là một kỹ thuật được đề xuất nhằm cải thiện bước truy xuất trong RAG bằng cách chuyển đổi truy vấn của người dùng thành một văn bản giả định (hypothetical document).
Trong bài này, mình sẽ nói về kỹ thuật HyDE và cách bạn có thể sử dụng nó để cải thiện pipeline RAG của bạn.
Truy xuất HyDE
Hypothetical Document Embeddings (HyDE) được đề xuất lần đầu trong bài báo "Precise Zero-Shot Dense Retrieval without Relevance Label" vào năm 2022 [2].
Mục đích của HyDE là chuyển đổi truy vấn người dùng thành một “văn bản” để giúp cho retriever có thể hoạt động tốt hơn.
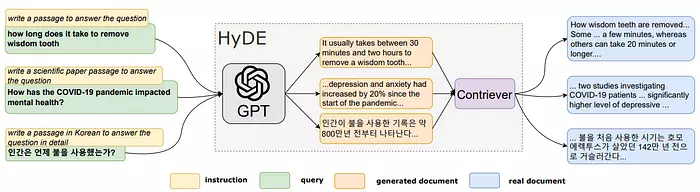
HyDE sử dụng một mô hình ngôn ngữ lớn có sẵn (Như ChatGPT, Claude, Llama,…) với một prompt đơn giản như “Viết một văn bản để trả lời câu hỏi này” để sinh ra một văn bản giả từ truy vấn người dùng. Việc chuyển đổi từ một truy vấn ngắn của người dùng thành một văn bản dài hơn, mang tính giả định, là ý tưởng chính của HyDE.
Văn bản giả này rất có thể sẽ chứa các con số ảo và những thông tin sai lệch (hallucinations). Tuy nhiên, điều này không quan trọng vì văn bản giả sẽ được mã hoá thành các vector embedding bởi mô hình embedding và sau đó được sử dụng để tìm kiếm dựa trên sự tương đồng ngữ nghĩa (semantic similarity search).
Theo bài báo về HyDE, mô hình embedding đóng vai trò như một bộ nén mất mát thông tin (lossy compressor) giúp lọc bỏ đi các chi tiết ảo và thông tin sai lệch trong văn bản giả. Kết quả thu được là một vector embedding có độ tương đồng cao với các embedding của tài liệu thật.
Cuối cùng, bộ retriever sử dụng văn bản giả đã được sinh ra để tìm kiếm các tài liệu thật gần nhất trong không gian embedding. Quá trình này thường được thực hiện thông qua tích vô hướng (dot product) hoặc cosine similarity.
Tóm lại, thay vì thực hiện tìm kiếm dựa trên độ tương đồng giữa truy vấn người dùng và tài liệu trong không gian embedding, HyDE thực hiện tìm kiếm dựa trên độ tương đồng giữa tài liệu giả định (hypothetical document) và tài liệu thực tế trong không gian embedding.
Contriever
Contriever là gì và tại sao HyDE lại sử dụng nó?
Ý tưởng cho bài báo về HyDE được thúc đẩy mạnh mẽ bởi một thực tế rằng không phải lúc nào cũng có đủ dữ liệu lớn để đào tạo một bộ truy xuất (retriever) cho việc tìm kiếm tương đồng (similarity search) giữa truy vấn và tài liệu.
Contriever là một bộ truy xuất (mô hình embedding) được đào tạo bằng phương pháp học đối kháng (contrastive learning). Học đối kháng là một hình thức của học tự giám sát (self-supervised learning), trong đó ta không cần sử dụng nhãn cho tập dữ liệu huấn luyện [3]. Đây là một phương pháp hữu ích khi ta không có đủ lượng dữ liệu có gán nhãn lớn, chẳng hạn như khi ta đào tạo mô hình embedding cho ngôn ngữ khác ngoài tiếng Anh.
Mô hình embedding được đào tạo bằng phương pháp học đối kháng sẽ cố gắng phân biệt giữa văn bản có nghĩa tương tự (điểm cao) và văn bản có nghĩa không tương tự (điểm thấp).
Trong quá trình đào tạo đối kháng, các cặp văn bản được chọn từ cùng một tài liệu (positive pair) hoặc từ các tài liệu khác nhau (negative pair). Bộ retriever sau đó được huấn luyện để phân biệt giữa các cặp tài liệu positive và negative.
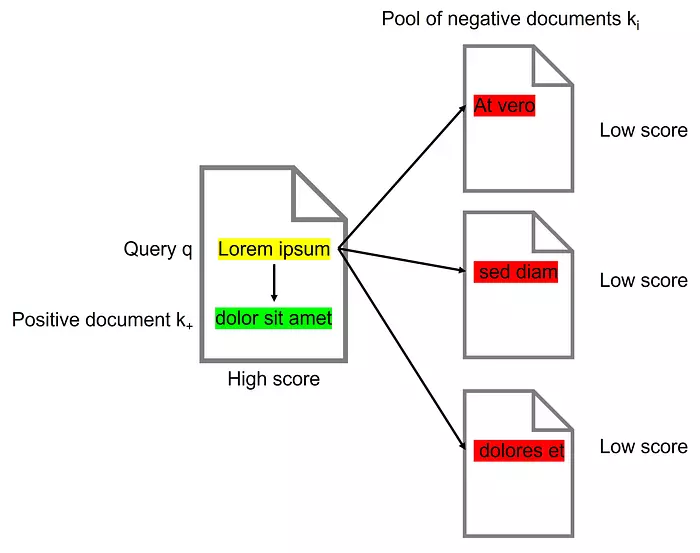
Contriever đã được huấn luyện sau đó có thể được sử dụng ngay lập tức hoặc có thể được sử dụng để tiếp tục fine-tune với dữ liệu có gán nhãn.
Bộ contriever được đào tạo theo cách tự giám sát bằng cách tìm kiếm sự tương đồng giữa các tài liệu, tức là không cần dữ liệu có nhãn. Và prompt của HyDE giúp chuyển đổi các truy vấn của người dùng sang không gian tài liệu này bằng cách tạo ra các tài liệu giả định.
Khi nào thì sử dụng HyDE?
Sự lựa chọn mô hình embedding của bạn đóng vai trò rất quan trọng trong việc quyết định xem khi nào nên sử dụng HyDE để cải thiện khả năng truy xuất của RAG.
Lấy ví dụ về một mô hình embedding tổng quát, đa năng và miễn phí là mô hình all-MiniLM-L12-v2 trong package sentence-transformers được lưu trữ trên HuggingFace. Trên model card của mô hình này trên HuggingFace, ta có thể đọc được thông tin sau về bối cảnh của mô hình:
The project aims to train sentence embedding models on very large sentence level datasets using a self-supervised contrastive learning objective. We used the pretrained microsoft/MiniLM-L12-H384-uncased model and fine-tuned in on a 1B sentence pairs dataset.
Ta có thể thấy, mô hình này được đào tạo trên tập dữ liệu không gán nhãn, sử dụng phương pháp học đối kháng tự giám sát trên các cặp văn bản như đã đề cập ở trên. Đây chính xác là loại mô hình phù hợp với mục đích của HyDE. Do đó, HyDE sẽ có khả năng cải thiện hiệu năng truy xuất của mô hình này.
Mặt khác, bạn không cần sử dụng HyDE nếu mô hình embedding của bạn đã được đào tạo có giám sát cho mục đích tìm kiếm ngữ nghĩa, đặc biệt là tìm kiếm ngữ nghĩa không đối xứng (Asymmetric semantic search). Tìm kiếm ngữ nghĩa không đối xứng nghĩa là bạn có một câu hỏi ngắn và bạn cần tìm kiếm một văn bản dài hơn để trả lời câu hỏi đó. Đây là use case thường thấy của RAG. Một bộ dataset phổ biến cho loại mô hình embedding này là MS MARCO dataset - bộ dataset hỏi đáp chứa các câu hỏi thực tế từ Bing và các câu trả lời do con người tạo ra. Các mô hình embedding từ thư viện sentence-transformers như các model "msmarco-*" và "multi-qa-*" đã được đào tạo trên dữ liệu có gán nhãn về câu hỏi - tài liệu và do đó (trên lý thuyết) sẽ không được hưởng lợi từ việc sử dụng HyDE.
Đối với hầu hết các mô hình embedding thương mại như các mô hình text-embedding của OpenAI, ta không biết được chúng được huấn luyện theo phương pháp nào, do đó HyDE có thể hoặc có thể không cải thiện hiệu năng truy xuất của các mô hình này.
HyDE Implementation
Bây giờ chúng ta sẽ implement một phiên bản cơ bản của HyDE trong Python.
Trước tiên các bạn cần tạo môi trường Python ảo mới và nhập câu lệnh sau vào Terminal để cài đặt các thư viện cần thiết:
pip install transformers sentence-transformers torch
Tiếp theo, ta sẽ tạo một class LLM. Trong class này, ta sẽ khởi tạo mô hình Qwen2.5–0.5B-Instruct trên local. Mô hình này rất nhẹ và có thể chạy trên CPU nếu máy tính của các bạn không có sẵn GPU.
from transformers import AutoModelForCausalLM, AutoTokenizer
import torch
class LLM:
def __init__(
self,
model_name="Qwen/Qwen2.5-0.5B-Instruct",
):
self.device = "cuda" if torch.cuda.is_available() else "cpu"
self.model = AutoModelForCausalLM.from_pretrained(
model_name,
torch_dtype="auto",
).to(self.device)
self.tokenizer = AutoTokenizer.from_pretrained(model_name)
def generate(self, prompt, temperature=0.7, max_new_tokens=256):
messages = [{"role": "user", "content": prompt}]
text = self.tokenizer.apply_chat_template(
messages, tokenize=False, add_generation_prompt=True
)
model_inputs = self.tokenizer([text], return_tensors="pt").to(self.device)
generated_ids = self.model.generate(
**model_inputs,
max_new_tokens=max_new_tokens,
do_sample=True,
temperature=temperature,
)
generated_ids = [
output_ids[len(input_ids) :]
for input_ids, output_ids in zip(model_inputs.input_ids, generated_ids)
]
return self.tokenizer.batch_decode(generated_ids, skip_special_tokens=True)[0]
Tiếp theo, ta cần một mô hình mã hoá để tính toán các embedding. Để sử dụng mô hình contriever all-MiniLM-L12-v2 trên local, ta chỉ cần vài dòng code với thư viện sentence_transformers:
from sentence_transformers import SentenceTransformer
encoder_model = SentenceTransformer("all-MiniLM-L12-v2", device="cpu")
Với hai mô hình này, ta đã có thể tính toán embedding cho văn bản giả định:
llm = LLM()
question = "was ronald reagon a democrat?"
hypothetical_document = llm.generate(
f"Write a paragraph that answers the question. Question: {question}"
)
print(hypothetical_document)
Bằng cách in ra văn bản giả định, ta được kết quả như sau (Lưu ý rằng văn bản giả định của các bạn có khả năng cao sẽ không giống với văn bản giả định dưới đây do đặc tính của các mô hình ngôn ngữ lớn):
Ronald Reagan, a prominent American politician and former president of the United States, was indeed a Democrat. Born on September 6, 1924, in Yonkers, New York, Reagan began his political career as a Republican Party member before transitioning to the Democratic Party later in his life. He served two terms as President of the United States from 1981 to 1989, during which he implemented several significant economic reforms aimed at reducing government spending and increasing tax revenues.
Reagan's approach to governance was characterized by his commitment to fiscal responsibility and his belief in the power of collective action over individual choice. His policies included the deregulation of industries, increased social welfare programs, and the promotion of family values. Reagan's presidency is often considered one of the most transformative periods in U.S. history, marked by the end of the Cold War and the rise of the global economy.
Throughout his tenure, Reagan maintained a strong connection with the Democratic Party despite its changing composition and focus on issues such as civil rights and environmental protection. His ability to navigate the complex landscape of American politics while still representing the interests of his party earned him the nickname "The Great Communicator" and contributed significantly to the consolidation of the Democratic Party's influence.
Nếu nhìn lướt qua, văn bản này có vẻ giống như được sinh ra từ Wikipedia. Tuy nhiên, văn bản này (thường) có thể chứa nhiều thông tin sai lệch (hallucinations) trong đó. Tuy nhiên, điều này có thể chấp nhận được do đây không phải tài liệu thực tế.
Kế tiếp, ta sẽ lấy một đoạn văn bản từ Wikipedia và tính toán embedding của truy vấn, của đoạn văn Wikipedia và của văn bản giả định.
wikipedia = """Ronald Wilson Reagan[a] (February 6, 1911 – June 5, 2004) was an American politician and actor who served as the 40th president of the United States from 1981 to 1989.
A member of the Republican Party, he became an important figure in the American conservative movement, and his presidency is known as the Reagan era. """
hypothetical_document_embedding = encoder_model.encode(hypothetical_document)
question_embedding = encoder_model.encode(question)
wikipedia_embedding = encoder_model.encode(wikipedia)
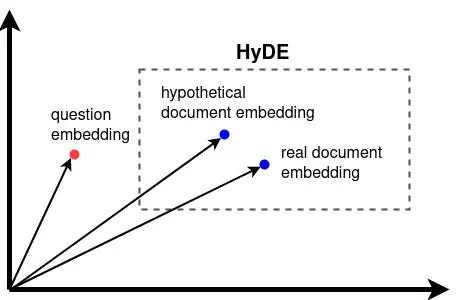
Bây giờ, chúng ta có thể kiểm tra xem embedding của tài liệu giả định có thực sự gần hơn với embedding của tài liệu thực so với embedding của câu hỏi hay không. Ta có thể sử dụng hàm có sẵn trong thư viện sentence_transformers để tính toán cosine similarity nhằm so sánh độ tương đồng giữa các embedding. Cosine similarity có giá trị từ -1 đến +1, trong đó -1 có nghĩa là các vector embedding hướng về hai phía đối lập, 0 có nghĩa là chúng vuông góc với nhau, và +1 có nghĩa là chúng cùng hướng.
from sentence_transformers import util
print(util.pytorch_cos_sim(hypothetical_document_embedding, wikipedia_embedding))
>> tensor([[0.7793]])
print(util.pytorch_cos_sim(question_embedding, wikipedia_embedding))
>> tensor([[0.4560]])
Như chúng ta có thể thấy, embedding của tài liệu giả định gần hơn nhiều so với embedding của tài liệu thực trong không gian embedding của chúng ta. Do đó, HyDE đã thành công trong việc giảm thiểu khoảng cách giữa truy vấn và tài liệu. Tuy nhiên, việc tạo ra tài liệu giả định sử dụng mô hình ngôn ngữ lớn (LLM) của chúng ta cũng đã tốn thêm một lần gọi đến LLM, nghĩa là ta cần phải thực hiện tính toán nhiều hơn. Đây là nhược điểm của việc sử dụng HyDE.
Có đáng để triển khai HyDE không?
Một nghiên cứu gần đây có tên "Searching for Best Practices in Retrieval-Augmented Generation" [4] đã xem xét các phương pháp truy xuất khác nhau cho RAG. Nghiên cứu này phát hiện rằng HyDE cải thiện hiệu năng truy xuất so với việc sử dụng mô hình embedding cơ bản. Một điều thú vị là việc kết hợp truy vấn người dùng với văn bản giả định còn có thể tạo ra kết quả tốt hơn nữa. Thêm vào đó, nếu sử dụng kỹ thuật Hybrid search kết hợp với HyDE thì sẽ tạo ra kết quả tốt nhất theo như nghiên cứu.
Considering the best performance and tolerated latency, we recommend Hybrid Search with HyDE as the default retrieval method. Taking efficiency into consideration, Hybrid Search combines sparse retrieval (BM25) and dense retrieval (Original embedding) and achieves notable performance with relatively low latency [4]
Mặt khác, HyDE làm tăng độ trễ và chi phí do yêu cầu thêm các lần gọi LLM bổ sung để chuyển đổi mỗi truy vấn thành một văn bản giả định.
Kết luận
HyDE là một kỹ thuật đơn giản mà hiệu quả để cải thiện bước truy xuất trong pipeline RAG. Bằng cách tạo ra các tài liệu giả định từ một truy vấn, chúng ta có thể thực hiện tìm kiếm tương đồng trong không gian embedding giữa các tài liệu, thay vì trong không gian embedding giữa câu hỏi và tài liệu. HyDE được đề xuất cho use case mô hình embedding chưa được tinh chỉnh cho tìm kiếm ngữ nghĩa với dữ liệu có gán nhãn về câu hỏi-tài liệu.
Vì HyDE chỉ yêu cầu một vài lần gọi LLM bổ sung, nên rất dễ để triển khai. Vì vậy, bạn có thể thử nghiệm và xem liệu HyDE có thể cải thiện khả năng truy xuất RAG của bạn hay không nhé!
References
[1] P. Lewis et al., Retrieval-Augmented Generation for Knowledge-Intensive NLP Tasks (2021), arXiv:2005.11401
[2] L. Gao, X. Ma, J. Lin, J. Callan, Precise Zero-Shot Dense Retrieval without Relevance Labels (2022), arXiv:2212.10496
[3] G. Izacard et al., Unsupervised Dense Information Retrieval with Contrastive Learning (2022), Transactions on Machine Learning Research (08/2022)
[4] X. Wang et al., Searching for Best Practices in Retrieval-Augmented Generation (2024), arXiv:2407.01219
https://towardsdatascience.com/how-to-use-hyde-for-better-llm-rag-retrieval-a0aa5d0e23e8
All rights reserved
