SHIFT JIS và Rank MS932
Bài đăng này đã không được cập nhật trong 4 năm
Mở đầu:
Một trong những vấn đề phức tạp khi làm việc với các dự án của Nhật, hoặc các dự án có liên quan đến Tiếng Nhật là việc kiểm tra xem kí tự có phải là tiếng Nhật hay không?
Chúng ta thường nghe nhiều đến các khái niệm Unicode, UTF-8, UTF-16, hay Shift-JS.
Thường các bảng mã hiện nay chủ yếu sử dụng UTF-8, UTF-16 để mã hoá, nhưng với tiếng Nhật thường sử dụng kiểu mã hoá Shift JIS.
Trong hướng dẫn này, chúng ta sẽ tìm hiểu khái niệm về charset, UTF-8, UTF-16, Shift JIS là gì?. Và triển khai rõ ràng một bài toán kiểm tra kí tự tiếng Nhật và có thuộc rank MS932 hay không?
Nội dung
- Charset, hay bảng mã kí tự
- Encode character, hay mã hoá kí tự
- Unicode
- UTF-8
- UTF-16
- Khái niệm về Shift JIS
- Các nhóm kí tự thuộc rank MS932
- Thuật toán xử lí
- Triển khai source code trong Android
- Authors
Charset, hay bảng mã kí tự
Bảng mã kí tự (char code table) là một bảng dùng để đánh chỉ số cho một tập kí tự (char) ,sao cho mỗi kí tự được ánh xạ từ số duy nhất (code). Hiểu nôm nà là mỗi mã kí tự sẽ được đánh số bởi 1 mã số code duy nhất, các máy tính, các hệ điều hành dựa vào code này để có thể hiểu nó là kí tự nào. Ví dụ:
- Như bảng mã ASCII chả hạn: Là bộ ký tự và bộ mã ký tự dựa trên bảng chữ cái La Tinh được dùng trong tiếng Anh hiện đại và các ngôn ngữ Tây Âu khác.
Encode character, hay mã hoá kí tự
Máy tính chỉ làm việc với các bit 0 và 1 (hay chính xác hơn là các trạng thái ON/OFF của transitor trong bo mạch), lưu dữ liệu lên bộ nhớ, đọc dữ liệu, truyền dữ liệu, tất cả đều thao tác với các bit 0 1. Để có thể lưu trữ được dữ liệu lên bộ nhớ, cần một phương pháp để chuyển từ các chữ cái, ký tự,... sang bit 0 1, phương pháp được nhắc tới đó được gọi là encode, và việc mã hóa một ký tự sang các bit được gọi là character encoding.
Unicode
Unicode (hay gọi là mã thống nhất; mã đơn nhất) là bộ mã chuẩn quốc tế được thiết kế để dùng làm bộ mã duy nhất cho tất cả các ngôn ngữ khác nhau trên thế giới, kể cả các ngôn ngữ sử dụng ký tự tượng hình phức tạp như chữ Hán của tiếng Trung Quốc, tiếng Nhật, chữ Nôm của tiếng Việt, v.v. Unicode là bảng mã chứa gần như toàn bộ các kí tự của hầu hết các ngôn ngữ trên toàn cầu.
=> Chắc ít nhiều khi làm việc với lập trình bạn đã nghe hoặc dùng đến unicode rồi!!
Nhưng vấn đề là, một số nước sử dụng riêng của chính họ. Lấy ví dụ với JP (Nhật bản), ta có Shift-JIS và EUC-JP.
UTF-8
UTF-8 Là phương thức Encoding rất phổ biến để miêu tả bảng mã Unicode trên bộ nhớ.
Một trong những điểm hút khách của UTF-8 là nó tương thích hoàn toàn với ASCII, encoding cơ sở cho tất cả các encoding khác. Mọi ký tự có trong ASCII đều chỉ cần đến 1 byte trong UTF-8 và nó cũng có giá trị y như trong ASCII. Nói cách khác, mọi ký tự trong ASCII đều được bê nguyên vào UTF-8. Những ký tự không có trong ASCII sẽ mất 2 byte hoặc nhiều hơn trong UTF-8. Đối với hầu hết các ngôn ngữ lập trình có khả năng đọc ASCII, bạn có thể đưa trực tiếp text UTF-8 vào chương trình của bạn luôn.
UTF-16
Gần giống với cách Encode của UTF-8 nhưng nó dùng luôn 2 byte để encode cho cả ASCII.
Khái niệm về Shift JIS
Shift-JIS là bảng mã được sử dụng ở gần như toàn bộ các máy tính tại Nhật, được JIS đưa ra. Có lẽ việc Shift-JIS vẫn được phổ biến tại Nhật vì nó chỉ sử dụng 2byte cho việc encoding tiếng nhật thay vì 3~4byte với UTF-8.
Shift-JIS cho đến hiện nay có khá nhiều version:
- Windows-932 / Windows-31J
- MacJapanese
- Shift_JISx0213 and Shift_JIS-2004
Các nhóm kí tự thuộc rank MS932
| Phân loại | Phạm vi (Hexadecimal) | Ghi chú |
|---|---|---|
| Chữ số fullsize | 0x824F~0x825F | |
| Chữ hoa fullsize alphabet | 0x8260~0x8279 | |
| Chữ thường fullsize | 0x8281~0x829A | |
| Hiragana fullsize | 0x829F~0x82F1 | |
| Fullsize katakana | 0x8340~0x8396 0x839F~0x83B6 | |
| Ký hiệu ký tự Hy Lạp | 0x839F~0x83B6 0x83BF~0x83D6 | |
| Nga character-chữ cyrillic | 0x8440~0x8460 0x8470~0x847E 0x8480~0x8491 | |
| Ký tự đường viền | 0x849F~0x84BE | |
| Chữ kanji fullsize (tiêu chuẩn thứ 1 ・ 2 của JIS) | 0x889F~0x9872 0x989F~0xEAA4 | |
| Kí tự đặc biệt fullsize | & +/= ^ { | } ~ . ( ) < > [ ] : @ , % ' * - _ ` ; ! # $ |
|
| Ký tự mở rộng NEC | 0x8754~0x875D |  |
| Ký tự mở rộng IBM | 0xFA40~0xFA57 0xFA5C~0xFC4B |  |
| IBM lựa chọn NEC ký tự mở rộng | 0xED40~0xEEFC |  |
*Note: Các bạn thấy sử dụng fullsize nhỉ. Vậy mình giải thích thêm về, Haft width(Haftsize) hay full width (full size)
- Haft width(Haftsize): Tức là 1 kí tự được đại diện bởi 1 byte
- Full width (full size): 1 kí tự được đại diện bởi 2 byte
- Ví dụ: ァ (Haft width), ア (Full width) đây là chữ a haft size, full size trong tiếng Nhật
Thuật toán xử lí
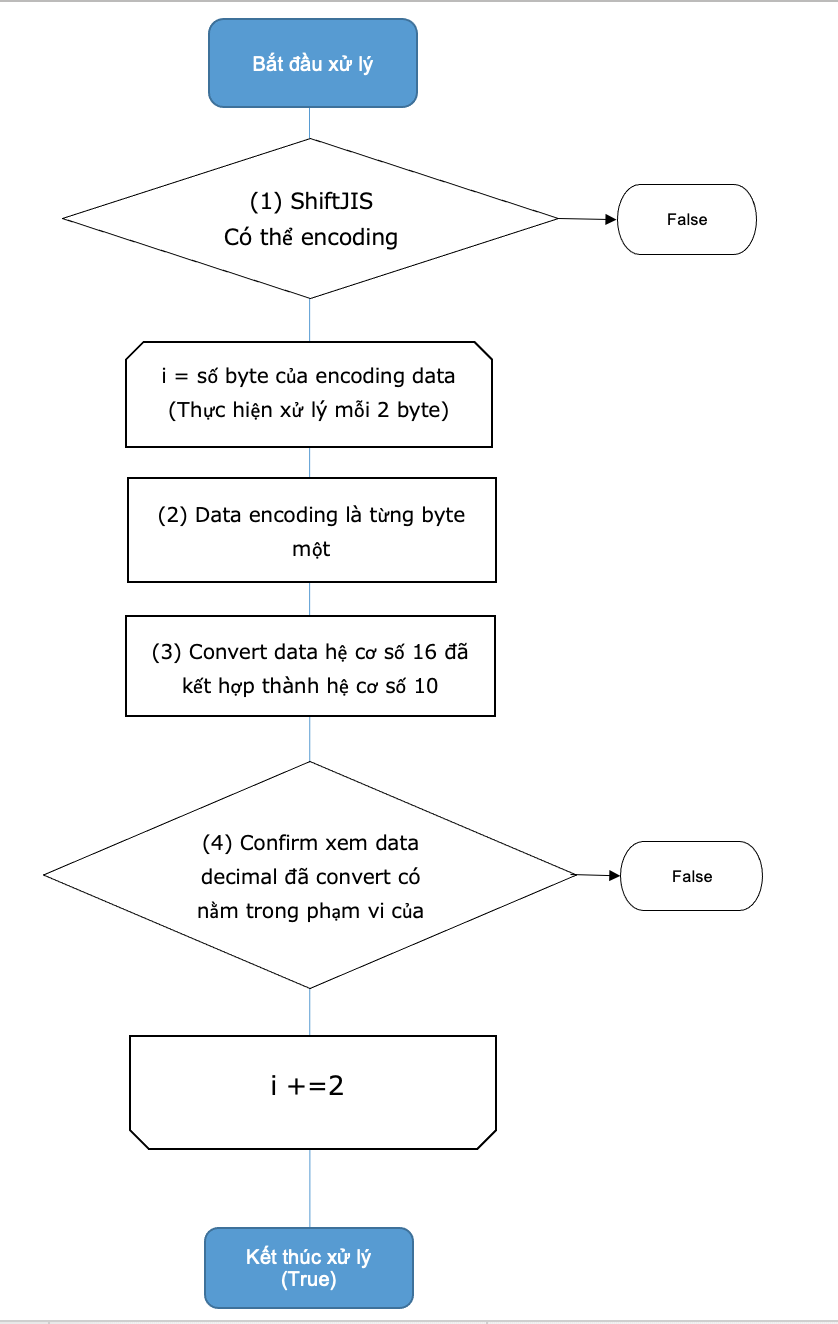
Với thuật toán trên các bạn hiểu đơn giản gồm các bước sau:
- Kiểm tra xem kí tự có thể encoding với ShiftJIS
- Data encoding là từng byte một.
- Convert thành hệ cơ số 16, cho kết hợp với mỗi 2 byte (Vì mỗi kí tự với ShiftJIS đại diện bởi 2 byte)
- Confirm xem data decimal đã convert có nằm trong phạm vi của Japanese ・ specific symbol của MS932 không
Triển khai source code trong Android
- Data encoding là từng byte một.
public static String byteArrayToHexString(byte[] a) {
StringBuilder sb = new StringBuilder(a.length * 2);
for (byte b : a) {
sb.append(String.format("%02x", b));
}
return sb.toString();
}
- Convert thành hệ cơ số 16, cho kết hợp với mỗi 2 byte (Vì mỗi kí tự với ShiftJIS đại diện bởi 2 byte)
public static int hexStringToInt(String from) {
String str = from.toUpperCase();
int sum = 0;
byte[] convertUTF8 = str.getBytes(StandardCharsets.UTF_8);
for (byte index : convertUTF8) {
sum = sum * 16 + (int) index - 48;
if (index >= 65) {
sum -= 7;
}
}
return sum;
}
- Confirm xem data decimal đã convert có nằm trong phạm vi của Japanese ・ specific symbol của MS932 không?
public static boolean tobeValidate(int shortValue) {
boolean toBe;
Integer[] symbols = {
33173, 33147, 33118, 33153, 33096, 33103, 33135, 33122, 33136, 33120,
33092, 33129, 33130, 33155, 33156, 33133, 33134, 33094, 33175, 33091,
33171, 33164, 33174, 33148, 33105, 33101, 33095, 33097, 33172, 33168
};
List<Integer> list = Arrays.asList(symbols);
if (shortValue == 33111 || shortValue == 33112) {
//33111 OR 33112
toBe = true;
} else if (shortValue == 33115) {
// 0x815B
toBe = true;
} else if (shortValue >= 33359 && shortValue <= 33375) {
// 0x824F~0X825F
toBe = true;
} else if (shortValue >= 33376 && shortValue <= 33401) {
// 0x8260~0X8279
toBe = true;
} else if (shortValue >= 33409 && shortValue <= 33434) {
// 0x8281~0X829A
toBe = true;
} else if (shortValue >= 33439 && shortValue <= 33521) {
// 0x829F~0x82F1
toBe = true;
} else if (shortValue >= 33600 && shortValue <= 33686) {
// 0x8340~0x8396
toBe = true;
} else if (shortValue >= 33695 && shortValue <= 33718) {
// 0x839F~0x83B6
toBe = true;
} else if (shortValue >= 33727 && shortValue <= 33750) {
// 0x83BF~0x83D6
toBe = true;
} else if (shortValue >= 33856 && shortValue <= 33888) {
// 0x8440~0x8460
toBe = true;
} else if (shortValue >= 33904 && shortValue <= 33918) {
// 0x8470~0x847E
toBe = true;
} else if (shortValue >= 33920 && shortValue <= 33937) {
// 0x8480~0x8491
toBe = true;
} else if (shortValue >= 33951 && shortValue <= 33982) {
// 0x849F~0x84BE
toBe = true;
} else if ((shortValue >= 34975 && shortValue <= 39026) ||
(shortValue >= 39071 && shortValue <= 60068)) {
// JSC
toBe = true;
} else if (list.contains(shortValue)) {
toBe = true;
} else if (shortValue >= 34644 && shortValue <= 34653) {
// 0x8754~0x875D
toBe = true;
} else if ((shortValue >= 64064 && shortValue <= 64087) ||
(shortValue >= 64092 && shortValue <= 64587)) {
// IBM: 0xFA40~0xA57 0xA5C~0xFC4B
toBe = true;
} else {
// NEC: 0xED40~0xEEFC
toBe = shortValue >= 60736 && shortValue <= 61180;
}
return toBe;
}
- Viết hàm kiểm tra
public static boolean isMS932(String string) {
// Kiểm tra xem kí tự có thể encoding với ShiftJIS
if (TextUtils.isEmpty(string)) {
// is not rank MS932
return false;
}
boolean validate = true;
try {
byte[] data = string.getBytes(CHART_SET_932);
String byteArrayToHexString = byteArrayToHexString(data);
// Kiểm tra xem kí tự có thể encoding với ShiftJIS
if (byteArrayToHexString.length() < 4) {
// is not rank MS932
return false;
}
for (int index = 0; index < byteArrayToHexString.length(); index += 4) {
String sjisCode = byteArrayToHexString.substring(index, index + 4);
int sjis = hexStringToInt(sjisCode);
if (!tobeValidate(sjis)) {
validate = false;
break;
}
}
} catch (UnsupportedEncodingException e) {
// is not rank MS932
return false;
}
return validate;
}
Đây là git ví dụ về MS932 triển khai ở trên. Các bạn hãy tham khảo nhé
- Android Java: https://github.com/cuongnvitdev/ms932-character-jp
- Android Kotlin: https://github.com/cuongnvitdev/ms932-character-jp-kotlin
Nguồn tham khảo về Shift_JIS(MS932): https://en.wikipedia.org/wiki/Code_page_932_(Microsoft_Windows)
Authors
All rights reserved
