Semantic Search Based on Domain Ontology Using Apache Spark
Bài đăng này đã không được cập nhật trong 4 năm

What is SEMANTIC ANALYSIS?****
The word semantic is a Linguistic term. It means something related to meaning in a language or logic.
In a natural language, semantic analysis is relating the structures and occurrences of the words, phrases, clauses, paragraphs etc and understanding the idea of what’s written in particular text. Does the formation of the sentences, occurrences of the words make any sense?
The challenge we face in the technologically advanced world is to make the computer understand the language or logic as much as the human does.
Semantic analysis requires rules to be defined for the system. These rules are same as the way we think about a language and we ask the computer to imitate. For example, “apple is red” is a simple sentence which a human understands that there is something called as Apple and it is red in color and the human knows that red means color.
For a computer, this is an alien language. The concept of linguistics here is this sentence formation has a structure in it. Subject-Predicate-object or in short form s-p-o. Where "apple" is subject, "is" is predicate and "red" are objects. Similarly, there are other linguistic nuances that are used in the semantic analysis.
Need for Semantic Analysis****
The reason why we want the computer to understand as much as we do is that we have a lot of data and we have to make the most out of it.
Let us strictly restrict ourselves to text data. Extracting appropriate data (results) based on the query is one of the challenging tasks. This data can be a whole document or just an answer to a query and that depends on the query itself.
Assume that we have million text documents in our database and if we have a query for which the answer is in the documents. The challenges are
-
Getting the appropriate documents
-
Listing them in the ranked order
-
Giving the answer to the query if it is specific
Difference between Keyword-based Search and Semantic Search****
In a search engine, a keyword based search is the searching technique which is implemented on the text documents based on the words that are found in the query. The query is initially processed for text cleaning and preprocessing and then based on the words used in the query the searching is done on the documents.
The documents are returned based on the most number of matches of the query words with documents.
In semantic search, we take care of the frequency of the words, syntactic structure of the natural language and other linguistic elements. In semantic search, the system understands the exact requirement of the search query.
When we search for “Usain Bolt” in Google, it returns the most appropriate documents and web pages regarding the famous athlete despite much more people with the same name since the search engine understands that we are searching for an athlete.
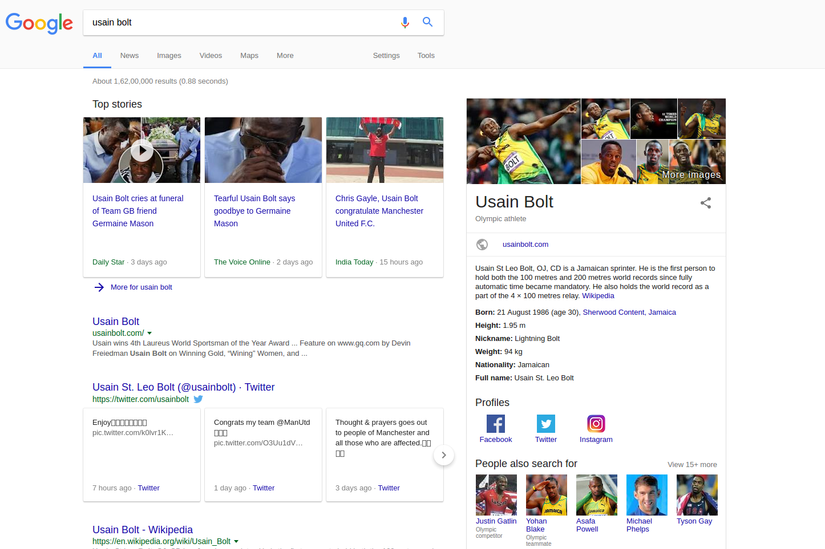
Now, if we are a little specific in our search and search for Usain Bolt birthday, Google returns it as,
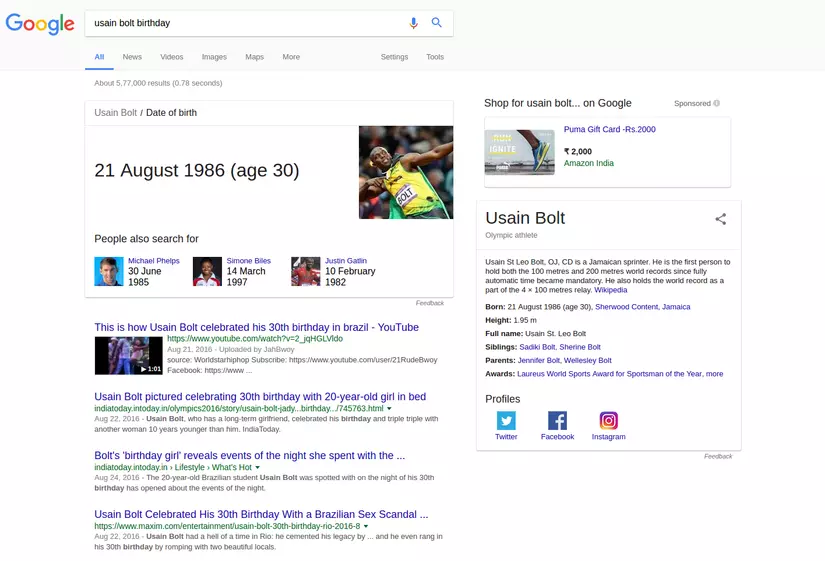
So, since Usain Bolt is quite a famous figure it might not be a surprising aspect for us. But there are a large number of other famous personalities and it is close to impossible to store all the information manually and show up accurately when a query is given by the user.
Moreover, the search query may not be constant. Each individual may query differently. Semantic techniques are applied here to store the data and fetch the results upon querying.
Let us see a different way of querying the above on Google
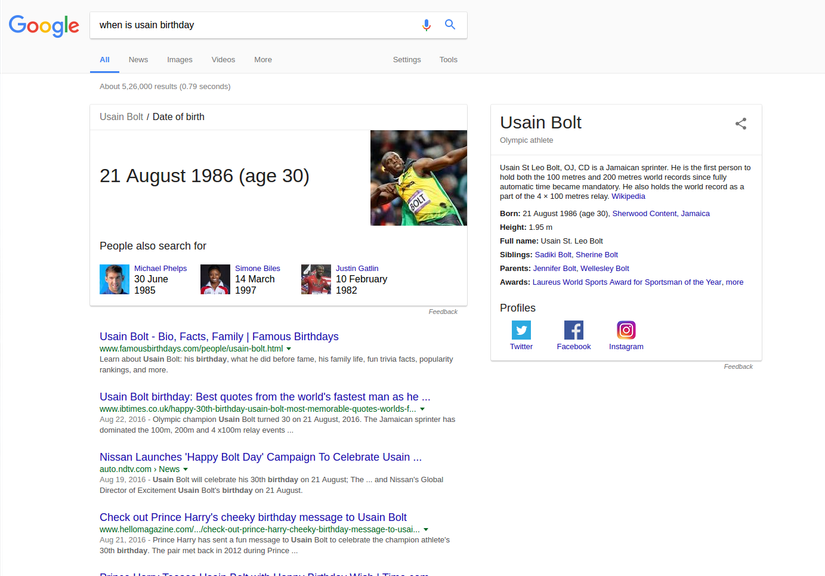
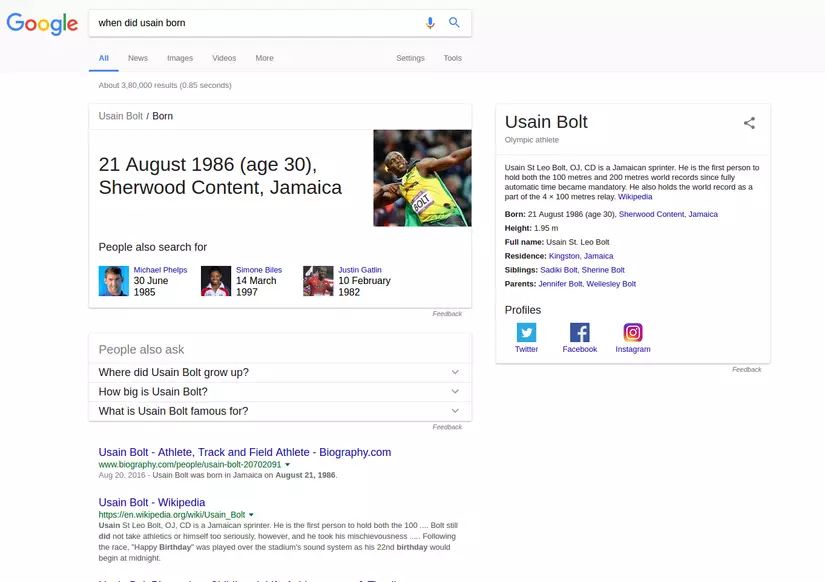
From above figures, it is evident that whatever way you give the search query, the search engine understands the intent of the user.
Semantic Search based on Domain Ontology****
Earlier, we have seen search efficiency of Google which searches irrespective of any particular domain. Searches of this kind are based on open information extraction. What if we require a search engine for a specific domain?
The domain may be anything. A college, A particular sport, a specific subject, a famous location, tourist spots etc. For example, suppose we have a college and we want to create a search engine only for that college such that any text query regarding the college is answered by the search engine. For this purpose, we create domain ontology.
What is Ontology?****
An ontology is set of concepts, their definitions, descriptions, properties, and relations. The relations here are relations among concepts and relations among relations.
How do we create Ontology?****
Before starting to create an ontology, we first choose the domain of consideration. We list out all the concepts related to that domain along with the relations. We have a data structure which is already defined to represent the ontology. Ontology is created as .owl files.
An OWL file consists of concepts as classes and for classes, there are subclasses, properties, instances, data types and much more. All this information will be in XML form. For simplicity, there are tools available to create ontologies like Protege.
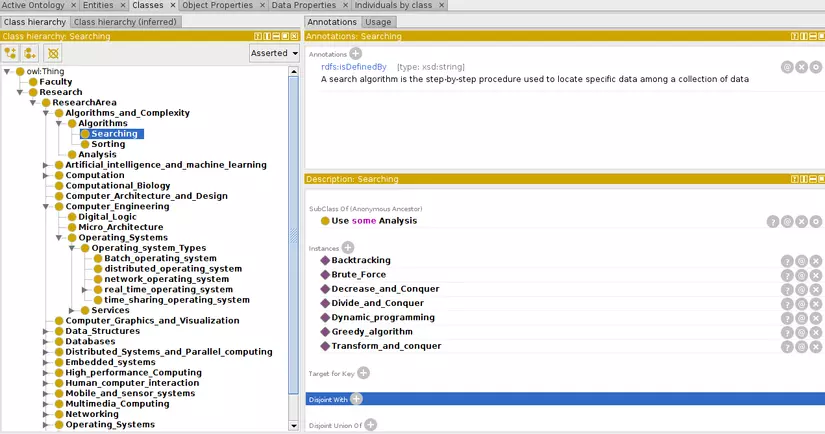
Storing the Unstructured Text Data in RDF Form****
Ontology is created based on the concepts and we are ready to use this to find out the appropriate document for the query in a search engine. The text documents which are available in unstructured form need a structure and we call it as semantic structure.
Thanks to RDF (Resource Description Framework). RDF is a structure where we store the information given in text into triples form. These triples are similar to the triples that we have discussed earlier i.e. s-p-o form.
Machine Learning and Text Analysis process is used to extract data required and store in the form of triples. This way the knowledge base is ready. Both the ontology as well as structured form of text data as RDF’s
Architecture for Real-Time Semantic Search Engine****
Implementation of the architecture on "Computer Science" Domain -
The complete architecture for the search engine would be "Platform as a Service (PAAS)". Let us consider an example for "Computer Science" as a domain. In this, the user can search for faculty CVs from the desired universities and research areas based on the query. So the steps to build a Semantic Search Engine are -
-
Crawl the documents (DOC, PDF, XML, HTML etc) from various universities and classify faculty profiles
-
Convert the unstructured text present in various formats to structured RDF form as described in earlier sections.
-
Build Ontology for Computer Science Domain
-
Store the data in Apache Jena triple store (Both Ontology and RDF's)
-
Use SparQL query language on the data
Finally, the user can search for the required data by university or research area. Additionally, if a user has a project information i.e. any project of his/her own regarding Computer Science, the user can submit the project and the system analyze the project to identify appropriate faculty profiles working in a similar subject area. Various Big Data components are necessary to make the search engine feasible to search in real-time.
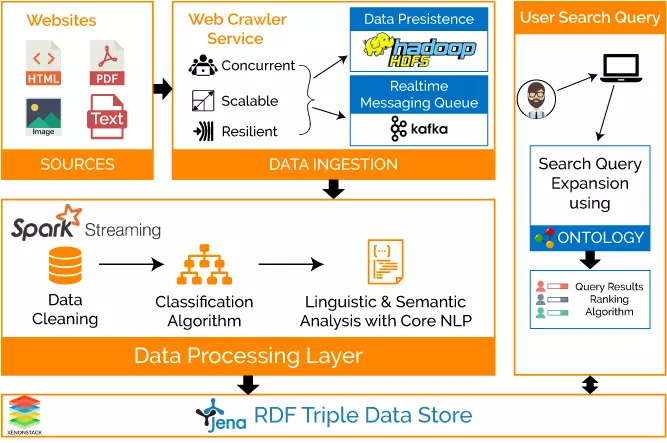
Data Ingestion using our Web Crawler Service****
Starting with the data extraction process, a web crawler was built which scrapes the content from any university or educational websites.This Web Crawler is built using Akka framework which is highly scalable, concurrent and distributed. This also supports almost all type of files like HTML, DOC, PDF, Text Files and even images.
Web Crawler supports HTTP and HTTPS protocols and proxy server support was also there.
Data Persistence using HDFS****
The extracted data from these files is saved to persistence HDFS storage system. Replication can be used to avoid node failure.
Read The Full Article At - XenonStack.com/Blog
All rights reserved
