Quản lý mô hình ML với BentoML - Phần 1
Bài đăng này đã không được cập nhật trong 5 năm
Lời mở đầu
Trước khi tìm hiểu về BentoML, các bạn có thể tìm hiểu 1 chút khái niệm về deploy mô hình mà tôi đã giới thiệu trong bài viết trước (https://viblo.asia/p/deploy-mo-hinh-hoc-may-voi-django-part-1-6J3ZgPkWlmB).
Tôi dám chắc có 80% các bạn đọc bài viết này có hứng thú tìm hiểu sau khi build xong model rồi sẽ phải làm gì, 10% đọc bài vì tác giả là tôi (tự sướng tí  ), 10% còn lại là người qua đường tiện thể ghé vào xem 1 chút
), 10% còn lại là người qua đường tiện thể ghé vào xem 1 chút  . P/S: hoặc có thể là tôi ảo tưởng
. P/S: hoặc có thể là tôi ảo tưởng  .
.
Thôi nói nhảm đủ rồi, như các bạn biết thì để xây dựng 1 model thì ta cần trải qua các bước như: crawl dữ liệu, xử lý dữ liệu, xây dựng mô hình, train mô hình, evaluate model, predict model. Ok nếu chỉ làm chơi chơi thì mọi thứ đều ổn, nhưng ...
- Trong trường hợp nội bộ: chúng ta không thể nào nhét model vào 1 thư mục nào đó và sau một thời gian thì quên béng địa chỉ thư mục ở đâu hoặc là quên hẳn luôn mô hình mà mình đã từng train, vì vậy bạn cần phải có một nơi lưu trữ pretrained model cũng như thông tin của model này để tiện bảo trì và nâng cấp.
- Trong trường hợp làm việc với khách hàng: công ty của bạn và của khách hàng là 2 công ty khác nhau nên không có chung đường truyền mạng và bạn cũng không thể nào quay video bởi như thế không đáng tin, vì vậy bạn cần gửi 1 API endpoint cho khách hàng vào test, để làm được điều này còn cần thêm sự hỗ trợ của infra hoặc chỉ đơn giản mở 1 cái port, đăng ký 1 domain, kết nối với internet.
Tôi đề cập tới 2 ví dụ kể trên chỉ để làm bài viết dài ... à làm lời giới thiệu cho 1 framework mã nguồn mở, hỗ trợ việc deploy, quản lý, monitor mô hình ML. Yep như tiêu đề: framework BentoML. Vậy BentoML giúp gì được cho chúng ta.
- Tạo API endpoint giúp predict pretrained model chỉ với vài dòng code.
- Hỗ trợ nhiều framework ML như Keras, Sklearn, PyTorch, ...
- Hỗ trợ micro-batching (sẽ giải thích sau).
- Lưu metadata của mô hình, cung cấp Web UI và CLI.
- Deploy đơn giản, tương thích với Docker, Kubernetes, AWS, ...
Trên đây là 1 vài công dụng của BentoML. Chúng ta cùng đi vào đào sâu nghiên cứu nào.
Setup
- Requirement:
python3.6 - Install by:
pip install bentoml
Nếu bạn đang dùng Notebook thì có thể xem hướng dẫn của BentoML trên này bằng cách download notebook.
pip install jupyter
git clone http://github.com/bentoml/bentoml
jupyter notebook bentoml/guides/quick-start/bentoml-quick-start-guide.ipynb
Xong đơn giản chỉ thế thôi.
Hướng dẫn cơ bản
Inference Step
Đầu tiên bạn cần tạo 1 class phục vụ cho việc predict mô hình, kế thừa từ class BentoService, bạn dùng mô hình của framework nào thì cần artifact của framework đấy, artifact ở đây là 1 abtract model. Cụ thể như sau:
# https://github.com/bentoml/BentoML/blob/master/guides/quick-start/iris_classifier.py
import bentoml
from bentoml.adapters import DataframeInput
from bentoml.artifact import SklearnModelArtifact
@bentoml.env(auto_pip_dependencies=True)
@bentoml.artifacts([SklearnModelArtifact('model')])
class IrisClassifier(bentoml.BentoService):
@bentoml.api(input=DataframeInput())
def predict(self, df):
# Optional pre-processing, post-processing code goes here
return self.artifacts.model.predict(df)
Chúng ta đi từng dòng 1 vậy.
@bentoml.env(auto_pip_auto_pip_dependencies=True): đây là 1 dạng decorator của bentoml hỗ trợ việc predict của mô hình, cụ thể là khi predict mà có thiếu dependencies thì bentoml sẽ cài đặt về bằng thư viện pip.@bentoml.artifacts([SklearnModelArtifact('model')]): gọi tới abtract model có cùng framework của pretrained model, giả sử như build mô hình Sklearn thì sử dụngSklearnModelArtifact, hỗ trợ save, load, pack mô hình. Các framework hỗ trợ:SklearnModelArtifactPytorchModelArtifactKerasModelArtifactFastaiModelArtifactXgboostModelArtifact
@bentoml.api(input=DataframeInput()): tạo API endpoint cho mô hình predict, đầu vào làDataframeInput()tức là API này sẽ chuyển đổi request của client từ HTTP JSON thành DataFrame của pandas.
Training Step To Save Step
Bên trên là 1 ví dụ về việc predict bằng BentoML, nhưng để predict thì ta cần có model. BentoML hỗ trợ việc lưu trữ model vào registry cho chúng ta nhưng về việc tiền xử lý, hậu xử lý, huấn luyện mô hình thì ... bất lực. 
from sklearn import svm
from sklearn import datasets
from iris_classifier import IrisClassifier
if __name__ == "__main__":
# Load training data
iris = datasets.load_iris()
X, y = iris.data, iris.target
# Model Training
clf = svm.SVC(gamma='scale')
clf.fit(X, y)
# Create a iris classifier service instance
iris_classifier_service = IrisClassifier()
# Pack the newly trained model artifact
iris_classifier_service.pack('model', clf)
# Save the prediction service to disk for model serving
saved_path = iris_classifier_service.save()
Ở đây tôi import class IrisClassifier từ iris_classfier.py, chính là đoạn code predict trên kia kìa. Như vậy ta không cần import thêm BentoService hay Artifact bởi class IrisClassifier đã kế thừa tất cả rồi.
Như tôi đã nói ở trên, BentoML không hỗ trợ phần tiền xử lý và training đâu nên chúng ta bỏ qua phần này đi, ở đây tôi gọi tới 1 instance của class IrisClassifier. Instance này có phương thức pack() dùng để đóng gói model, có 2 param là tên model và model, cũng có thể coi như wrap model vào bento service, điều kiện bắt buộc là model save phải đúng artifact .
Ok cuối cùng là lưu model bằng cách sử dụng phương thức save(). Nơi lưu trữ model mặc định của hàm này là local storage - tức là ở trên máy tôi hiện giờ, cụ thể model và metadata được lưu vào folder ~/bentoml. Các bạn cũng có thể customize lại nơi lưu trữ dữ liệu, chẳng hạn như AWS S3, GCS, ...
save(base_path=None, version=None, labels=None)
Để lưu trữ cả code, dependencies, configs, v.v... bạn có thể dùng:
save_to_dir(path, version=None)
Cùng xem thử BentoML đã làm gì trong tiến trình save này nhé:
- Lưu mô hình dựa vào framework của mô hình và artifact tương ứng.
- Tự động trích xuất thư viện pip mà mình sử dụng, lưu vào trong file
requirements.txt. - Lưu tất cả python code dependencies.
- Gom hết các file tự động generate vào 1 folder.
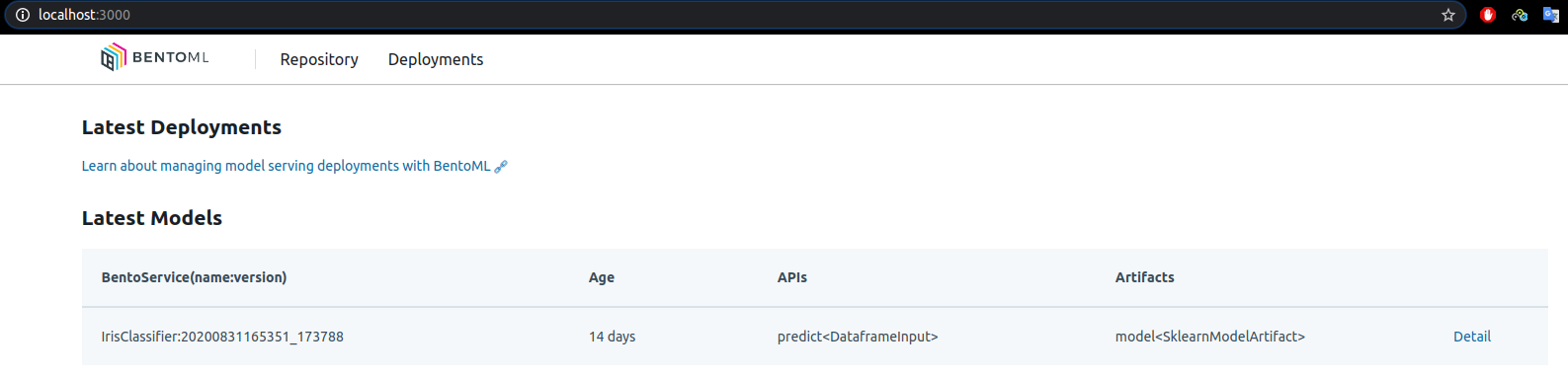
Để quản lý model, BentoML cung cấp 2 cách quản lý: thông qua dashboard web UI hoặc dùng CLI commands.
- Với CLI:
Để liệt kê các ML Model đã lưu, dùng câu lệnh:
bentoml list

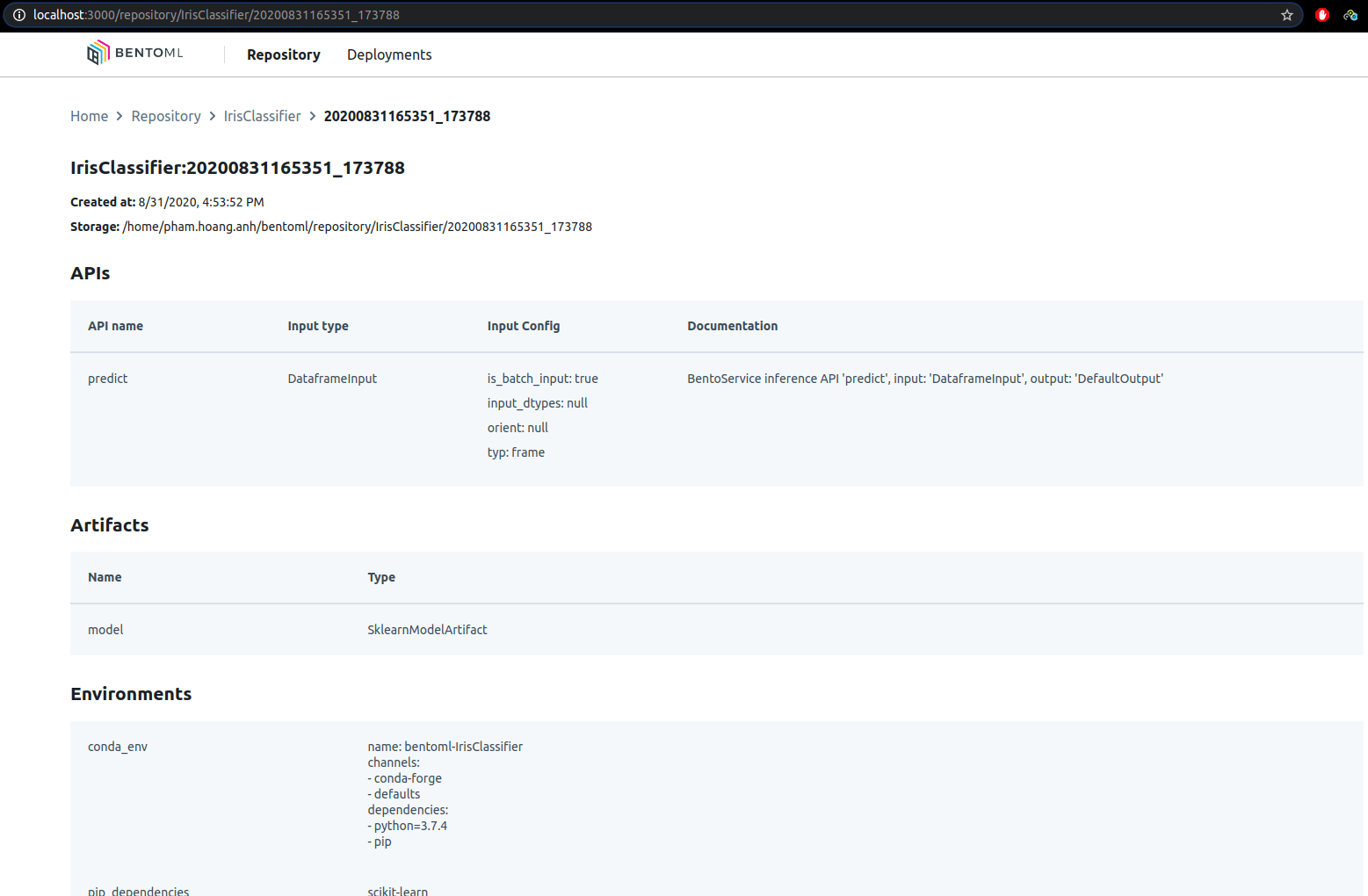
Để liệt kê các ML Model đã lưu cũng như metadata và môi trường của model, ta dùng câu lệnh:
- Với UI:
# port mặc định là 3000, nếu muốn chạy UI trên port chỉ định, chỉ cần thêm --ui-port {your_port}
bentoml yatai-service-start
Nếu dùng docker, để mở Yatai UI trong container bạn dùng câu lệnh này:
docker run -v ~/bentoml:/root/bentoml -p 3000:3000 -p 50051:50051 bentoml/yatai-service
Chú ý: port 1 là UI port, port 2 là grc port.
Model Serving thông qua REST API
Như code ở trên, tôi đã define api bằng decorator của python cho hàm predict() có đầu vào là data frame (json), cho nên bây giờ tôi có thể test mô hình bằng API.
Chạy câu lệnh này để mở model serving
# port mặc định là 5000, chuyển port bằng cách thêm --port {your_port}
bentoml serve IrisClassifier:latest --port 5001
Tên model là IrisClassifier, tag ở phía sau chỉ phiên bản gần đây nhất của mô hình. Sau khi chạy câu lệnh này sẽ hiện lên url api với port mặc định là 5000, điền url lên trình duyệt sẽ được đưa tới trang swagger doc.
Có 2 cách để bạn test thử API này:
- Cách 1: dùng CURL
curl -i \
--header "Content-Type: application/json" \
--request POST \
--data '[[5.1, 3.5, 1.4, 0.2]]' \
http://localhost:5001/predict
- Cách 2: dùng thư viện requests và code trên python native
import requests
response = requests.post("http://127.0.0.1:5000/predict", json=[[5.1, 3.5, 1.4, 0.2]])
print(response.text)
-
Cách 3: chỉ dùng để test trên Web UI của BentoML
![]()
-
Cách 4: dùng câu lệnh CLI (có hỗ trợ dataframe, json file, csv file)
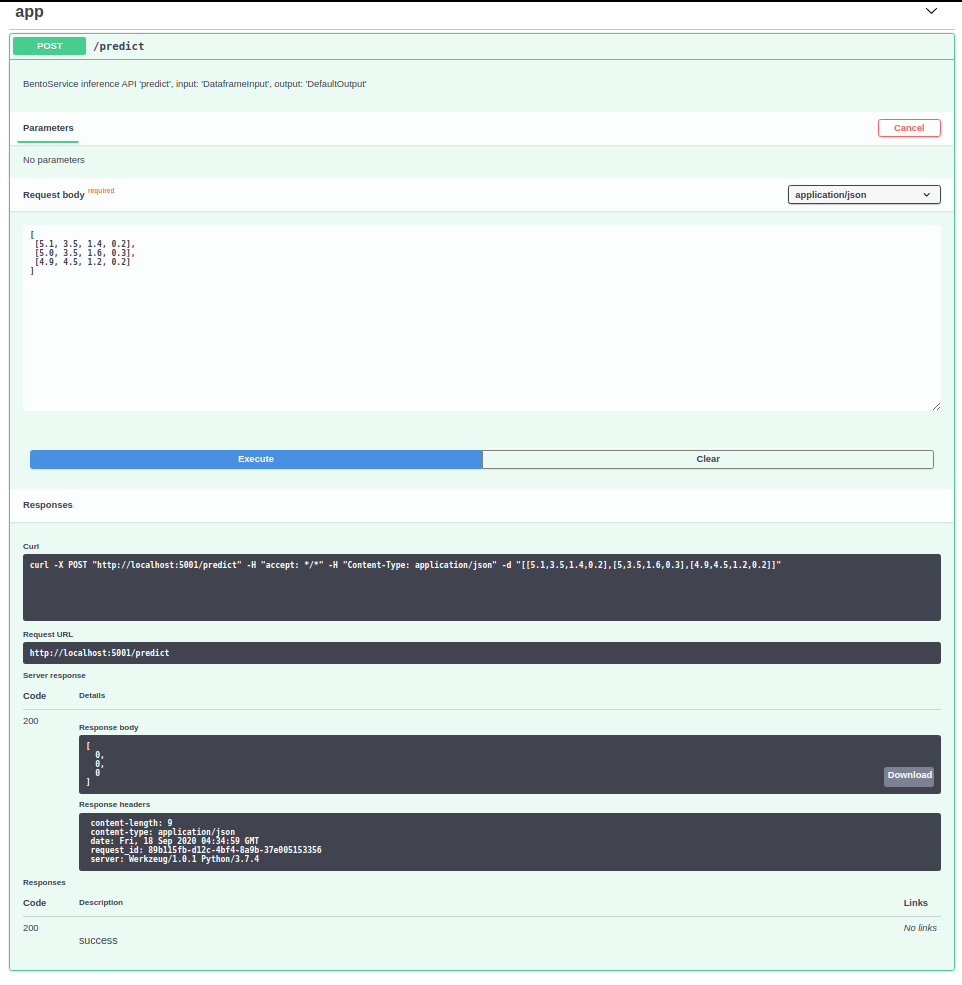
bentoml run IrisClassifier:latest predict --input='[[5.1, 3.5, 1.4, 0.2]]'
bentoml run IrisClassifier:latest predict --input='./iris_data.csv'
Đóng gói Model API Server
Để deploy thành sản phẩm, trước đấy bạn phải đóng gói model lại đã, nếu bạn rảnh có thể vọc vào thư mục lưu trữ model của bentoml, bên trong có chứa các file config như: dockerfile, entrypoint.sh, requirement.txt, ...

Nếu bạn đã config docker, có thể dùng luôn câu lệnh đóng gói của bentoml:
bentoml containerize IrisClassifier:latest -t iris-classifier
Để chạy container đã build bằng câu lệnh trên thì bạn phải chạy bằng câu lệnh của docker:
docker run -p 5000:5000 iris-classifier:latest --workers=1 --enable-microbatch
Sau khi đóng gói model, bạn cần deploy container này. Với 1 sản phẩm, tôi cần nó có thể scale được, có thể A/B testing, có thể canary rollout, ..., thế nên có vẻ Kubeflow, Kubernetes là platform mà tôi cần. Bạn hoàn toàn có thể deplout ML Model đóng gói bởi BentoML với các platform kể trên.
Các lựa chọn trong quá trình deploy
BentoML cung cấp khá nhiều dịch vụ trong các trường hợp khác nhau:
- Nếu team bạn không mạnh về DevOps -> thử tự động deploy với BentoML CLI, hỗ trợ bởi AWS Lambda, AWS SageMaker, Azure Functions:
- https://docs.bentoml.org/en/latest/deployment/aws_lambda.html
- https://docs.bentoml.org/en/latest/deployment/aws_sagemaker.html
- https://docs.bentoml.org/en/latest/deployment/azure_functions.html
- Nếu bạn không xài cloud platform kể trên thì cố gắng deploy bằng "tay" BentoML pkg trên các cloud khác:
- https://docs.bentoml.org/en/latest/deployment/aws_ecs.html
- https://docs.bentoml.org/en/latest/deployment/google_cloud_run.html
- https://docs.bentoml.org/en/latest/deployment/azure_container_instance.html
- https://docs.bentoml.org/en/latest/deployment/heroku.html
- Nếu bạn có một team đủ mạnh về DevOps hay ML engineer thì có thể thử Kubernetes hoặc OpenShift:
- https://docs.bentoml.org/en/latest/deployment/kubernetes.html
- https://docs.bentoml.org/en/latest/deployment/knative.html
- https://docs.bentoml.org/en/latest/deployment/kubeflow.html
- https://docs.bentoml.org/en/latest/deployment/kfserving.html
- https://docs.bentoml.org/en/latest/deployment/clipper.html
Biến một Model thành thư viện pip
Toẹt vời, bạn có thể thử 1 trong 2 cách Cách 1: vào thư mục lưu trữ model của BentoML và dùng câu lệnh này:
python setup.py sdist upload
Cách 2: dùng BentoMl CLI để lấy đường dẫn của thư mục lưu trữ và ...:
saved_path=$(bentoml get IrisClassifier:latest --print-location --quiet)
pip install $saved_path
Giải thích một chút về micro batching
Micro batching
Đầu tiên tôi sẽ đề cập tới 3 lý thuyết là Độ trễ, Thông lượng (lưu lượng đầu vào) và Batching
Latency (Độ trễ)
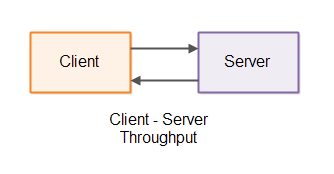
Latency là một phép đo thời gian trễ của một hệ thống. Trong hệ thống client-server, độ trễ đại biểu cho nhiều thứ xảy ra như độ trễ của mạng chính là khoảng thời gian client gửi 1 request tới phía server, độ trễ của server là khoảng thời gian server cần để xử lý request và trả về kết quả.
 Công thức tính độ trễ
Công thức tính độ trễ
network latency + server latency + network latency = 2 * network latency + server latency
Throughput (Thông lượng)
Throughput là một phép đo bao nhiêu request server có thể xử lý trong khoảng thời gian nhất định. Trong hệ thống client-server, throughput đo số lượng requests mà một server có thể xử lý trong 1s (mặc định như thế), mỗi một request tương ứng với 1 client. Tương tự server gửi về client được bao nhiêu response.

Batching
Batching là 1 kỹ thuật làm tăng lưu lượng của 1 hệ thống. Thay vì xử lý 1 task, giờ đây các task gộp lại thành 1 nhóm và được xử lý đồng thời.
VD: Client có 10 request. Giả sử anh ta gửi từng request một, vậy server sẽ phải xử lý từng request một và trả về từng response một cho request đó. Ta có công thức:
10 * (network latency + server latency + network latency) = 20 * network latency + 10 * server latency
Nhưng nếu 10 request đó được gộp thành 1 nhóm và gửi đi đúng 1 lần thì server chỉ cần xử lý 1 lần trả về 10 response:
network latency + 10 * server latency + network latency = 2 * network latency + 10 * server latency
Ta có thể thấy độ trễ của hệ thống giảm đi kha khá ... Nhưng có thật là độ trễ bị giảm đi thật không. Kỹ thuật này có 1 khuyết điểm là cần thời gian gộp request thành 1 nhóm.
VD: giả sử client cần 2h chỉ để gộp 10 request thành 1 batch => tăng độ trễ của hệ thống. Server cần chờ 2h mới nhận được request và trả về kết quả.
Cho nên batching chỉ là kỹ thuật tăng throughput của hệ thống chứ không giảm latency của hệ thống.
Better Solution ?
Micro batching là một biến thể của batching nhưng lại có trade-off giữa latency và throughput tốt hơn batching. Cơ chế như sau: micro batching sẽ chờ trong 1 khoảng thời gian ngắn để nhóm các tasks lại trước khi xử lý chúng. Và chúng ta có thể define khoảng thời gian hợp lí nhất (1s hoặc 0.5s).
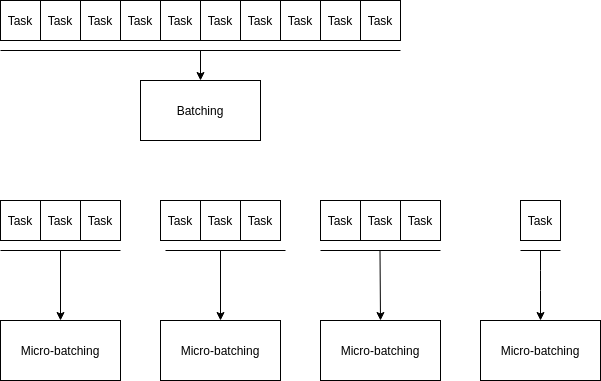
Trong trường hợp này BentoML đã trích dẫn 1 câu tôi thấy khá hay
While serving a TensorFlow model, batching individual model inference requests together can be important for performance. In particular, batching is necessary to unlock the high throughput promised by hardware accelerators such as GPUs. (https://github.com/tensorflow/serving/blob/master/tensorflow_serving/batching/README.md)
Cấu trúc hệ thống micro-batching của BentoML
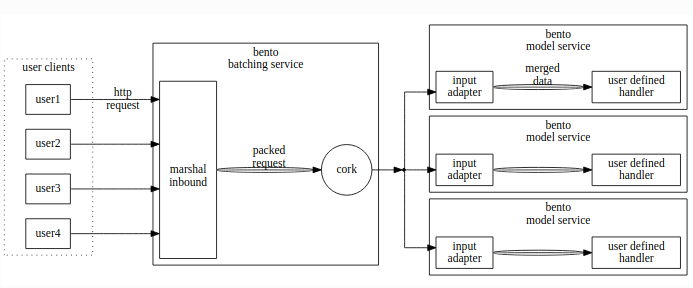
Kết luận
Cám ơn các bạn đã xem đến tận đây. Bài viết còn sơ sài, vẫn chưa hướng dẫn và phân tích sâu hơn core của BentoML. Cho nên mình lại để dành cho phần 2 vậy (chỉ khi có hứng  ).
).
References
https://docs.bentoml.org/en/latest/index.html
http://tutorials.jenkov.com/java-performance/micro-batching.html
All rights reserved
