
Deploy "mô hình học máy" với Django Part 1
Bài đăng này đã không được cập nhật trong 6 năm
Lời mở đầu
Chao xìn các bạn, hôm nay tôi quay trở lại với một trong các vấn đề thường gặp phải hiện giờ trong làng AI:
- Biến 1 mô hình Machine Learning trở thành 1 sản phẩm thực tế chứ không còn là 1 PoC chỉ cần show cho khách hàng độ chính xác nữa
Nếu chỉ làm PoC thì chỉ cần theo luồng ở hình dưới là ok. Nhưng để làm sản phẩm thì còn thiếu chút chút

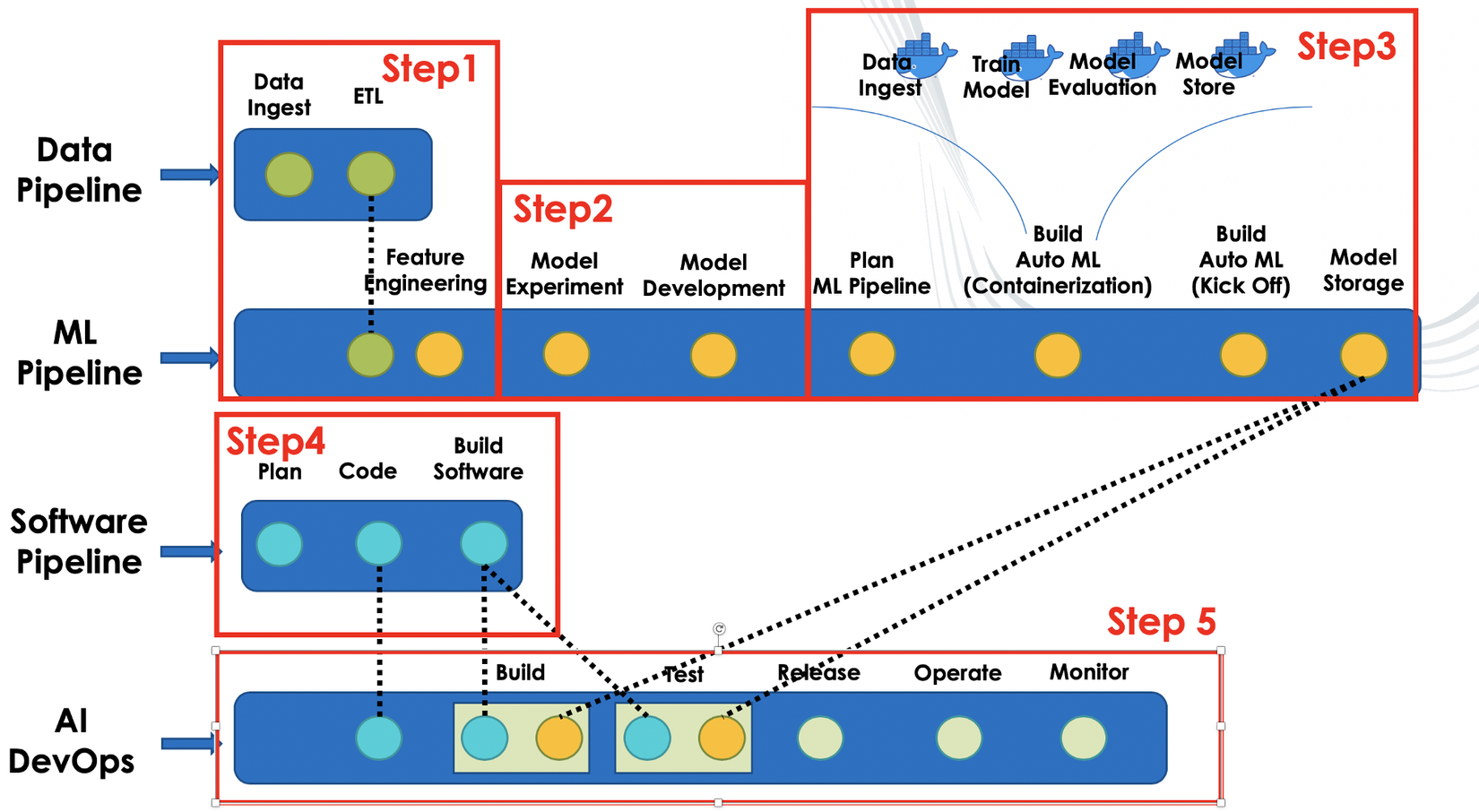
Hình dưới tôi mới chôm đc đâu đó trên google, show cho chúng ta thấy quy trình trong AI DevOps. Ở đây việc xử lý data trở thành 1 pipeline riêng bao gồm từ việc crawl, store, pre-processing, change format, v.v... Dữ liệu từ Data Pipeline sẽ trở thành đầu vào của ML Pipeline để train, evaluation, lưu mô hình hoặc lưu weight (tùy framework mà có các định dạng khác nhau như .npy, .h5, .pb, ...), sau đó cả Data Pipeline và ML Pipeline đều được đóng gói lại bằng Docker. Còn lại Software Pipeline và AI DevOps, là công đoạn ghép mô hình vào sản phẩm.
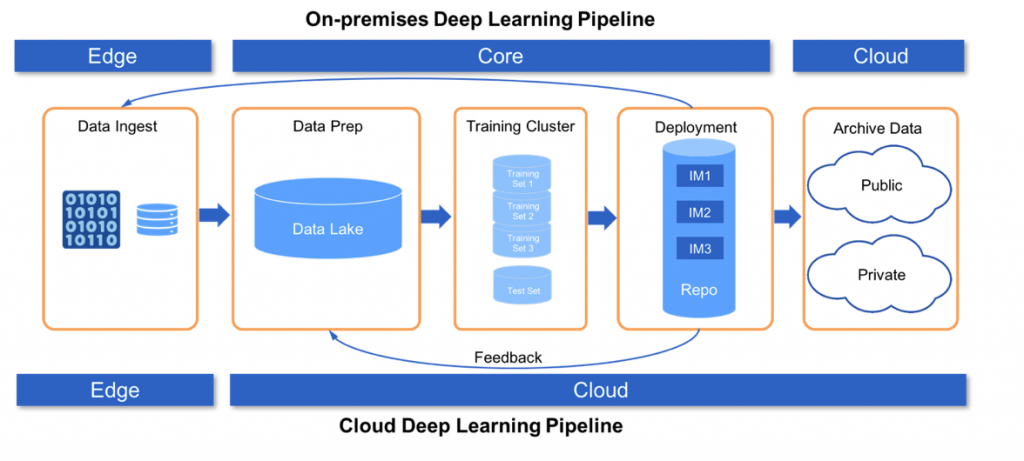
Thực ra còn một pipeline nữa tôi cảm thấy khá hay nhưng không định đề cập tới bởi pipeline này không phù hợp ở Việt Nam cho lắm: Cloud AI Pipeline
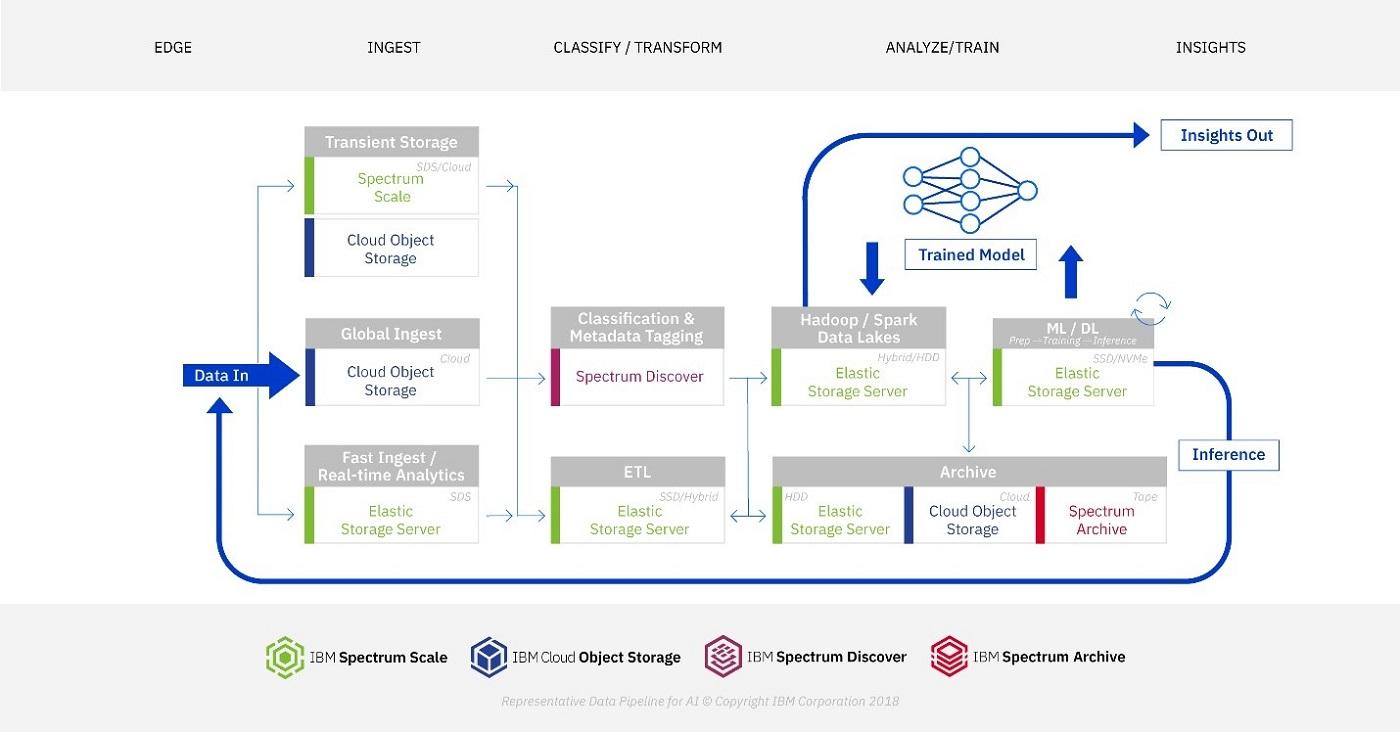
IBM-Nvidia AI data pipeline
Việc lưu trữ và truy xuất dữ liệu trên Cloud cần mạng ngon mà đường cáp quang ở Việt Nam dăm ba bữa có cá mập cắn hay bị bóp băng thông thì có vẻ không khả thì lắm  , à mà không kể các nhà cung cấp dịch vụ Cloud ở Việt Nam.
, à mà không kể các nhà cung cấp dịch vụ Cloud ở Việt Nam.
Lan man đủ rồi, như tiêu đề hôm nay tôi sẽ viết 1 bài về deploy mô hình ML với Django. Thực ra là dịch và viết theo ý hiểu dựa trên 1 blog, sẽ cập nhật link ở cuối bài.
Stato
Một số yêu cầu cần thiết khi deploy mô hình ML trong 1 sản phẩm thực tế:
- Tự động triển khai thuật toán ML
- Continuous Integration (không biết dịch ra sao để đủ ý
 thôi thì giữ nguyên)
thôi thì giữ nguyên) - Khả năng tái lập của mô hình
- Giám sát hành vi của mô hình (xem có chết ở luồng nào không)
- Khả năng mở rộng
- Khả năng tích hợp
Còn trong bài viết này tôi sẽ giới thiệu:
- Cách xử lý nhiều API endpoints (các API url đấy)
- Mỗi endpoint có một hoặc nhiều mô hình ML với đa phiên bản
- Code lưu trên git (tất nhiên r)
- Hỗ trợ triển triển khai nhanh và liên tục build (CI)
- Hỗ trợ A/B tests
- Triển khai với containers (Docker)
- Có giao diện người dùng
Thiết lập Git Repository
Tạo môi trường
Bởi hệ điều hành máy tôi dùng là Linux/Ubun16.04 nên tôi dùng thư viện virtualenv khởi tạo 1 môi trường ảo có python based 3.6
virtualenv venv --python=python3.6
source venv/bin/activate
Cài đặt Django Module
Phiên bản Django tôi dùng ở đây là:
pip3 install django==2.2.4
Khởi tạo Django project
mkdir backend
cd backend
django-admin startproject server
Test thử xem có chạy không
cd server
python manage.py runserver
Đẩy lên Git
git status
git add backend/
git commit -m "setup django project"
git push origin master
Xây dựng mô hình học máy
Như tiêu đề đã nói deploy mô hình học máy thì phải có mô hình chứ nhỉ. Tôi dùng 1 thư viện hỗ trợ các mô hình học máy cổ điển là sklearn, dùng thư viện pandas để visualize, tùy biến dữ liệu và đóng gói mô hình hoặc dữ liệu bằng thư viện joblib.
pip3 install numpy pandas sklearn joblib
import json
import numpy as np
import pandas as pd
from sklearn.preprocessing import LabelEncoder
from sklearn.ensemble import RandomForestClassifier
from sklearn.ensemble import ExtraTreesClassifier
import joblib
Tôi cứ mặc định bạn có kiến thức về học máy rồi nhé nên sẽ không giải thích các đoạn import module bên trên. 2 mô hình học máy ở đây tôi dùng là RandomForest và một extension của DecisionTree là ExtraTrees
Load dữ liệu
Dữ liệu mà tôi dùng ở đây là Adult Income data set (https://archive.ics.uci.edu/ml/datasets/adult). Giới thiệu 1 chút về bộ dữ liệu: dùng để dự đoán thu nhập của một người trưởng thành có vượt quá 50k usd/ 1 năm hay không. Ok, trước hết trong folder backend tôi dùng câu lệnh touch test.py tạo 1 file test.py để code thử nghiệm, rồi chúng ta đến phần load dữ liệu:
- First, download dữ liệu gốc, bao gồm: train, test và label.
wget https://archive.ics.uci.edu/ml/machine-learning-databases/adult/adult.data
wget https://archive.ics.uci.edu/ml/machine-learning-databases/adult/adult.test
wget https://archive.ics.uci.edu/ml/machine-learning-databases/adult/adult.names
- Second, liệt kê các features của dữ liệu:
features = ["age", "workclass", "fnlwgt", "education", "education-num", "marital-status", "occupation", "relationship", "race" , "sex", "capital-gain", "capital-loss", "hours-per-week", "native-country", "income"]
- , combine lại dữ liệu và label, dùng pandas đọc cho rõ ràng.
data_train = pd.read_csv("adult.data", sep=" ", header=None)
data_train.columns = features
print(data_train.head())

- , lấy features các cột trừ cột income, bởi cột income là cột label.
X_train = data_train[features[:-1]]
y_train = data_train["income"]
print(X_train.shape, y_train.shape)
(32561, 14) (32561,)
- , xử lý bộ test tương tự bộ train.
data_test = pd.read_csv("adult.test", sep=", ", header=None)
data_test.columns = features
X_test = data_test[features[:-1]]
y_test = data_test["income"]
print(X_test.shape, y_test.shape)
(16281, 14) (16281,)
Tiền xử lý dữ liệu
Dữ liệu này không được đầy đủ, a.k.a thiếu giá trị ở 1 vài cột nên tôi fill bằng các giá trị có tần số xuất hiện nhiều nhất ở các cột.
train_mode = dict(X_train.mode().iloc[0]) # mode() để lấy giá trị xuất hiện nhiều và iloc để xác định vị trí
X_train = X_train.fillna(train_mode) # fill giá trị NaN, Na, Null, ... bằng param đưa vào
Giờ thì ở các cột chứa số, tôi không cần quan tâm vì máy hiểu mà, nhưng ở các cột categorical thì phải có bước đưa về number. Ở đây tôi dùng LabelEncoder.
features_categorical = ['workclass', 'education', 'marital-status', 'occupation', 'relationship', 'race', 'sex','native-country']
encoders = {}
for col in features_categorical:
X_train[column] = LabelEncoder().fit_transform(X_train[column])
encoders[column] = LabelEncoder()
print(X_train.head())
 Quên mất, dữ liệu ở các cột age, fnlwgt, education-num, ... đang có dtype là string, nên tôi phải chuyển về dạng int64.
Quên mất, dữ liệu ở các cột age, fnlwgt, education-num, ... đang có dtype là string, nên tôi phải chuyển về dạng int64.
for c in features[:-1]:
if X_train[c].dtypes != "int64":
X_train[c] = X_train[c].apply(lambda x: x.split(',')[0]).astype('int')
Ok được rồi đấy, train thôi
Train model
Quá trình train khá đơn giản do sklearn đã hỗ trợ tận răng rồi 
# train the Random Forest algorithm
rf = RandomForestClassifier(n_estimators = 100) # n_estimators: số lượng trees
rf = rf.fit(X_train, y_train)
# train the Extra Trees algorithm
et = ExtraTreesClassifier(n_estimators = 100)
et = et.fit(X_train, y_train)
Sau khi đã có mô hình, ta save weights mô hình bằng joblib, tại sao tôi dùng joblib chứ không phải pickle => mời bạn tham khảo link này (https://stackoverflow.com/questions/12615525/what-are-the-different-use-cases-of-joblib-versus-pickle).
# save preprocessing objects and weights
joblib.dump(train_mode, "./train_mode.joblib", compress=True)
joblib.dump(encoders, "./encoders.joblib", compress=True)
joblib.dump(rf, "./random_forest.joblib", compress=True)
joblib.dump(et, "./extra_trees.joblib", compress=True)
Đẩy lên git
# execute in project main directory
git add research/
git commit -am "add ML code"
git push origin master
Django models
Trong mục trước, tôi đã làm 3 việc sau:
- Tạo git
- Khởi tạo dự án Django
- Load, xử lý dữ liệu và train 2 mô hình
Giờ tôi sẽ tạo Django models để lưu thuật toán học máy vào cơ sở dữ liệu và tạo 1 API endpoint để truy xuất từ CSDL.
Khởi tạo Django models
Trước hết phải tạo app trong project đã
# in backend/server directory
python manage.py startapp app
Đăng ký app trong file settings.py a.k.a backend/server/server/settings.py của Django
INSTALLED_APPS = [
'django.contrib.admin',
'django.contrib.auth',
'django.contrib.contenttypes',
'django.contrib.sessions',
'django.contrib.messages',
'django.contrib.staticfiles',
'app'
]
Trong app/models.py, khởi tạo table
from django.db import models
class Endpoint(models.Model):
'''
Attributes:
name: tên của endpoint dùng trong API URL,
owner: tên người sở hữu,
created_at: ngày khởi tạo endpoint.
'''
name = models.CharField(max_length=128)
owner = models.CharField(max_length=128)
created_at = models.DateTimeField(auto_now_add=True, blank=True)
class MLModel(models.Model):
'''
Attributes:
name: tên mô hình.
description: giới thiệu về mô hình.
version: quản lý phiên bản.
owner: chủ sở hữu.
created_at: ngày khởi tạo mô hình.
parent_endpoint: khóa ngoại của bảng Endpoint.
'''
name = models.CharField(max_length=128)
description = models.CharField(max_length=1000)
version = models.CharField(max_length=128)
owner = models.CharField(max_length=128)
created_at = models.DateTimeField(auto_now_add=True, blank=True)
parent_endpoint = models.ForeignKey(Endpoint, on_delete=models.CASCADE)
class MLModelStatus(models.Model):
'''
The MLAlgorithmStatus represent status of the MLAlgorithm which can change during the time.
Attributes:
status: Trạng thái của mô hình: testing, staging, production, ab_testing.
active: tồn tại hay không tồn tại format boolean.
created_by: tên người tạo.
created_at: ngày khởi tạo trạng thái.
parent_mlmodel: khóa ngoại của bảng MLModel.
'''
status = models.CharField(max_length=128)
active = models.BooleanField()
created_by = models.CharField(max_length=128)
created_at = models.DateTimeField(auto_now_add=True, blank=True)
parent_mlmodel = models.ForeignKey(MLModel, on_delete=models.CASCADE, related_name = "status")
class MLRequest(models.Model):
'''
Lưu lại toàn bộ request liên quan đến mô hình
Attributes:
input_data: input của mô hình dưới dạng Json.
full_response: kết quả raw của mô hình (optional).
response: kết quả của mô hình dưới dạng Json.
feedback: feedback của người dùng (optional).
created_at: ngày khởi tạo request.
parent_mlalgorithm: khóa ngoại của bảng MLModel.
'''
input_data = models.CharField(max_length=10000)
full_response = models.CharField(max_length=10000)
response = models.CharField(max_length=10000)
feedback = models.CharField(max_length=10000, blank=True, null=True)
created_at = models.DateTimeField(auto_now_add=True, blank=True)
parent_mlmodel = models.ForeignKey(MLModel, on_delete=models.CASCADE)
Vì Django cung cấp ORM Layer (object-relational mapping layer) nên tôi phải có bước map models vào database:
python manage.py makemigrations
python manage.py migrate

 Database mặc định của Django là SQLite, do chỉ test nên tôi không scale up database to hơn như postgres, các bạn có thể check bằng DB Browser (https://sqlitebrowser.org/ ).
Database mặc định của Django là SQLite, do chỉ test nên tôi không scale up database to hơn như postgres, các bạn có thể check bằng DB Browser (https://sqlitebrowser.org/ ).
Tạo REST API cho models
Để đơn giản tôi install package Django REST Framework
pip3 install djangorestframework
Đăng ký drf trong Django project
INSTALLED_APPS = [
'django.contrib.admin',
'django.contrib.auth',
'django.contrib.contenttypes',
'django.contrib.sessions',
'django.contrib.messages',
'django.contrib.staticfiles',
'app',
'rest_framework',
]
1 API hoàn chỉnh cần:
- serializers
- views
- urls
DRF Serializers
Tạo file serializers.py trong thư mục backend/server/app. Serializers hỗ trợ việc chuyển đổi dữ liệu trong database thành JSON objects và ngược lại.
from rest_framework import serializers
from app.models import Endpoint
from app.models import MLModel
from app.models import MLModelStatus
from app.models import MLRequest
# read_only_fields: các trường chỉ cho phép đọc
class EndpointSerializer(serializers.ModelSerializer):
class Meta:
model = Endpoint
read_only_fields = ("id", "name", "owner", "created_at")
fields = read_only_fields
class MLModelSerializer(serializers.ModelSerializer):
current_status = serializers.SerializerMethodField(read_only=True)
def get_current_status(self, mlmodel):
return MLModelStatus.objects.filter(parent_mlmodel=mlmodel).latest('created_at').status
class Meta:
model = MLModel
read_only_fields = ("id", "name", "description", "version",
"owner", "created_at", "parent_endpoint", "current_status")
fields = read_only_fields
class MLModelStatusSerializer(serializers.ModelSerializer):
class Meta:
model = MLModelStatus
read_only_fields = ("id", "active")
fields = ("id", "active", "status", "created_by",
"created_at", "parent_mlmodel")
class MLRequestSerializer(serializers.ModelSerializer):
class Meta:
model = MLRequest
read_only_fields = (
"id",
"input_data",
"full_response",
"response",
"created_at",
"parent_mlmodel",
)
fields = (
"id",
"input_data",
"full_response",
"response",
"feedback",
"created_at",
"parent_mlmodel",
)
Views
Trong file views.py ở thư mục backend/server/app.
Với mỗi model tôi tạo 1 view cho phép truy xuất dữ liệu. Riêng 2 model Endpoint và MLModel thì không tạo API bởi, phần tạo mô hình học máy chỉ ở phía server và không publish ra bên ngoài.
from django.db import transaction
from rest_framework import viewsets
from rest_framework import mixins
from app.models import Endpoint
from app.serializers import EndpointSerializer
from app.models import MLModel
from app.serializers import MLModelSerializer
from app.models import MLModelStatus
from app.serializers import MLModelStatusSerializer
from app.models import MLRequest
from app.serializers import MLRequestSerializer
class EndpointViewSet(
mixins.RetrieveModelMixin, mixins.ListModelMixin, viewsets.GenericViewSet
):
serializer_class = EndpointSerializer
queryset = Endpoint.objects.all()
class MLModelViewSet(
mixins.RetrieveModelMixin, mixins.ListModelMixin, viewsets.GenericViewSet
):
serializer_class = MLModelSerializer
queryset = MLModel.objects.all()
def deactivate_other_statuses(instance):
old_statuses = MLModelStatus.objects.filter(parent_mlmodel=instance.parent_mlmodel,
created_at__lt=instance.created_at,
active=True)
for i in range(len(old_statuses)):
old_statuses[i].active = False
MLModelStatus.objects.bulk_update(old_statuses, ["active"])
class MLModelStatusViewSet(
mixins.RetrieveModelMixin, mixins.ListModelMixin, viewsets.GenericViewSet,
mixins.CreateModelMixin
):
serializer_class = MLModelStatusSerializer
queryset = MLModelStatus.objects.all()
# gọi bởi CreateModelMixin class để lưu một object mới
def perform_create(self, serializer):
try:
# quản lý các tiến trình nhỏ trong Django transaction. Success thì active == True và ngược lại
with transaction.atomic():
instance = serializer.save(active=True)
# set active=False for other statuses
deactivate_other_statuses(instance)
except Exception as e:
raise APIException(str(e))
class MLRequestViewSet(
mixins.RetrieveModelMixin, mixins.ListModelMixin, viewsets.GenericViewSet,
mixins.UpdateModelMixin
):
serializer_class = MLRequestSerializer
queryset = MLRequest.objects.all()
URLS
Thêm url truy xuất model. Trong urls.py ở thư mục backend/server/server.
from django.contrib import admin
from django.urls import path
from django.conf.urls import url, include
from rest_framework.routers import DefaultRouter
from app.views import EndpointViewSet
from app.views import MLModelViewSet
from app.views import MLModelStatusViewSet
from app.views import MLRequestViewSet
router = DefaultRouter(trailing_slash=False)
router.register(r"endpoints", EndpointViewSet, basename="endpoints")
router.register(r"mlmodels", MLModelViewSet, basename="mlmodels")
router.register(r"mlmodelstatuses", MLModelStatusViewSet,
basename="mlmodelstatuses")
router.register(r"mlrequests", MLRequestViewSet, basename="mlrequests")
urlpatterns = [
url(r"^api/v1/", include(router.urls)),
path('admin/', admin.site.urls),
]
Block code bên trên tạo 1 REST API routers tới cơ sở dữ liệu. Các thông số của mô hình có thể truy cập bởi địa chỉ đã có format
http://<server-ip>/api/v1/<object-name>
Ok, tôi run server để xem thành quả phát.
python manage.py runserver
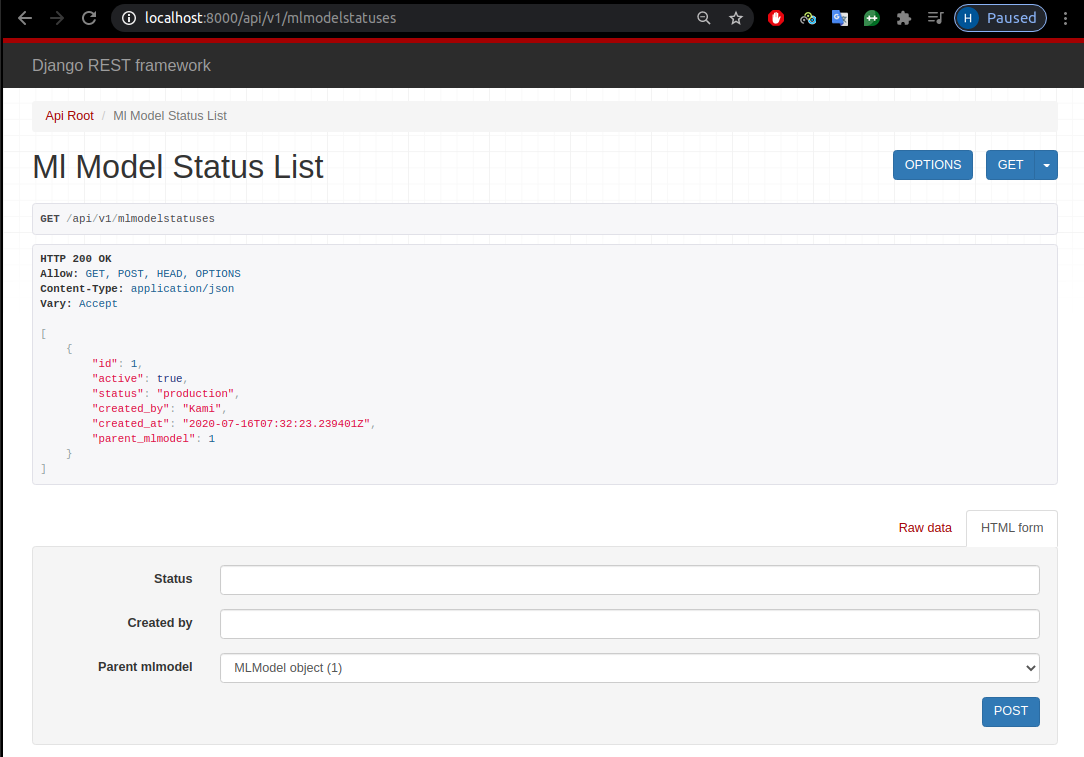
 Như hình trên tôi có 1 đống api endpoint của các django model, nhưng dữ liệu thì chưa có gì => tích hợp code từ mục "Xây dựng mô hình học máy".
Như hình trên tôi có 1 đống api endpoint của các django model, nhưng dữ liệu thì chưa có gì => tích hợp code từ mục "Xây dựng mô hình học máy".
Đẩy lên git tiếp
git add app
git commit -m "endpoints models"
git push origin master
Thêm MLModel vào Django project
ML code trong Django Project
Trong thư mục backend/server, tạo thư mục ml/classifier/, thêm file random_forest.py làm nơi chứa code cho mô hình Random Forest.
import joblib
import pandas as pd
class RandomForestClassifier:
def __init__(self):
path_to_artifacts = "../../research/"
self.values_fill_missing = joblib.load(
path_to_artifacts + "train_mode.joblib")
self.encoders = joblib.load(path_to_artifacts + "encoders.joblib")
self.model = joblib.load(path_to_artifacts + "random_forest.joblib")
def preprocessing(self, input_data):
# JSON to pandas DataFrame
input_data = pd.DataFrame(input_data, index=[0])
# fill missing values
input_data.fillna(self.values_fill_missing)
# convert categoricals
categories = ["workclass", "education", "marital-status",
"occupation", "relationship", "race", "sex", "native-country"]
for column in categories:
enc = self.encoders[column]
input_data[column] = enc.transform(input_data[column])
return input_data
def predict(self, input_data):
return self.model.predict_proba(input_data)
def postprocessing(self, input_data):
label = "<=50K"
if input_data[1] > 0.5:
label = ">50K"
return {"probability": input_data[1], "label": label, "status": "OK"}
def compute_prediction(self, input_data):
try:
input_data = self.preprocessing(input_data)
prediction = self.predict(input_data)[0] # 1 mẫu
prediction = self.postprocessing(prediction)
except Exception as e:
return {"status": "Error", "message": str(e)}
return prediction
Bởi vì đã train từ mục trước và lưu lại weight nên giờ tôi đi luôn vào bước inference. 2 bước train và inference này nên tách biệt nhau ra, bước train model chỉ thực hiện trên server, còn bước inference này do phải đóng gói thành 1 container để chuyển giao cho khách hàng hoặc bên thứ 3 nào đấy, việc tách biệt này nhằm mục đích bảo vệ bản quyền model do ta đã bỏ công sức fine-tune, tiền xử lý dữ liệu các kiểu, tuy việc này dễ bị lách qua nhưng méo mó có hơn không .
Đăng ký folder ml trong Django Project 
INSTALLED_APPS = [
'django.contrib.admin',
'django.contrib.auth',
'django.contrib.contenttypes',
'django.contrib.sessions',
'django.contrib.messages',
'django.contrib.staticfiles',
'app',
'rest_framework',
'ml',
]
ML code tests
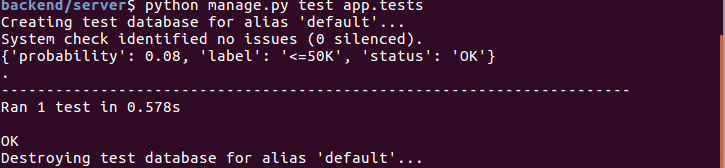
Test thử bằng 1 mẫu xem code chạy đc không, trong file app/tests.py tôi viết 1 testcase đơn giản như sau
from django.test import TestCase
from ml.classifier.random_forest import RandomForestClassifier
class MLTests(TestCase):
def test_rf_algorithm(self):
input_data = {
"age": 37,
"workclass": "Private",
"fnlwgt": 34146,
"education": "HS-grad",
"education-num": 9,
"marital-status": "Married-civ-spouse",
"occupation": "Craft-repair",
"relationship": "Husband",
"race": "White",
"sex": "Male",
"capital-gain": 0,
"capital-loss": 0,
"hours-per-week": 68,
"native-country": "United-States"
}
my_alg = RandomForestClassifier()
response = my_alg.compute_prediction(input_data)
self.assertEqual('OK', response['status'])
self.assertTrue('label' in response)
self.assertEqual('<=50K', response['label'])
Rồi chạy câu lệnh
python manage.py test
Output
ML registry
Tuy đã thêm folder ml vào trong django project cũng như có file inference, mô hình đã sẵn sàng để cho ra kết quả nhưng vẫn chưa liên quan gì cho lắm với API, chúng ta phải thêm 1 bước tạo 1 ML registry object, có nhiệm vụ lưu trữ thông tin về mô hình đúng với format của API Endpoint, nói chung là lưu vào cơ sở dữ liệu.
Thêm file registry.py vào thư mục backend/server/ml.
from app.models import Endpoint
from app.models import MLModel
from app.models import MLModelStatus
class MLRegistry:
def __init__(self):
self.endpoints = {}
def add_algorithm(self, endpoint_name, algorithm_object, algorithm_name,
algorithm_status, algorithm_version, owner,
algorithm_description):
# get endpoint
endpoint, _ = Endpoint.objects.get_or_create(
name=endpoint_name, owner=owner)
# get model algorithm
database_object, algorithm_created = MLModel.objects.get_or_create(
name=algorithm_name,
description=algorithm_description,
version=algorithm_version,
owner=owner,
parent_endpoint=endpoint)
if algorithm_created:
status = MLModelStatus(status=algorithm_status,
created_by=owner,
parent_mlmodel=database_object,
active=True)
status.save()
# add to registry
self.endpoints[database_object.id] = algorithm_object
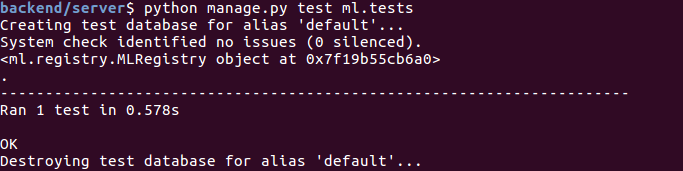
Test xem tạo registry có đúng không, thêm 1 file tests.py vào thư mục backend/server/ml để thực hiện unittest.
from django.test import TestCase
from ml.classifier.random_forest import RandomForestClassifier
from ml.registry import MLRegistry
class MLRegistryTests(TestCase):
def test_registry(self):
registry = MLRegistry()
self.assertEqual(len(registry.endpoints), 0)
endpoint_name = "classifier"
algorithm_object = RandomForestClassifier()
algorithm_name = "random forest"
algorithm_status = "production"
algorithm_version = "0.0.1"
algorithm_owner = "Kami"
algorithm_description = "test deploy Random Forest on Django Project"
registry.add_algorithm(endpoint_name, algorithm_object, algorithm_name,
algorithm_status, algorithm_version, algorithm_owner,
algorithm_description)
self.assertEqual(len(registry.endpoints), 1)
Chạy câu lệnh
python manage.py test ml.tests
Output
Thêm mô hình ML vào registry
Ở đây chúng ta có 2 cách để thêm thông tin về mô hình đã train vào cơ sở dữ liệu.
- Cách 1: thêm trực tiếp từ API Endpoint dùng phương thức post hay update để cập nhật thông số, bạn sẽ phải cập nhật ở cả 3 bảng Endpoint, MLModel, MLModelStatus. Cách này có thể thông qua code hoặc các platform như postman để giao tiếp với API.
# Endpoint
endpoint_name = "classifier"
algorithm_owner = "Kami"
data_endpoint = (endpoint_name, algorithm_owner)
# MLModel
algorithm_name = "random forest"
algorithm_description = "test deploy Random Forest on Django Project"
algorithm_version = "0.0.1"
algorithm_owner = "Kami"
data_model = (algorithm_name, algorithm_description, algorithm_version, algorithm_owner)
# MLModelStatus
algorithm_status = "production"
algorithm_createdby = "Kami"
algorithm_activate = True
data_status = (algorithm_status, algorithm_createdby, algorithm_activate)
- Cách 2: thêm bằng registry như đã tạo ở trên. Cách này thì chỉ có thông qua code mới được. Để mỗi khi bật server sẽ tự động cập nhật thông tin về mô hình, tôi đặt vào trong file
wsgi.pyở thư mụcbackend/server/server.
import os
from django.core.wsgi import get_wsgi_application
os.environ.setdefault('DJANGO_SETTINGS_MODULE', 'server.settings')
application = get_wsgi_application()
# ML registry
from ml.registry import MLRegistry
from ml.classifier.random_forest import RandomForestClassifier
try:
# create ML registry
registry = MLRegistry()
# Random Forest classifier
rf = RandomForestClassifier()
# add to ML registry
registry.add_algorithm(endpoint_name="classifier",
algorithm_object=rf,
algorithm_name="random forest",
algorithm_status="production",
algorithm_version="0.0.1",
owner="Kami",
algorithm_description="Random Forest with simple pre- and post-processing")
except Exception as e:
print("Exception while loading the algorithms to the registry,", str(e))
Rồi đến lúc kiểm tra API xem thông tin đã được thêm vào chưa.
python manager.py runserver


Tiếp tục đẩy lên git
git add .
git commit -m "add ml code"
git push origin master
Kết phần 1
Bài viết khá dài nên tôi chia ra làm 2 phần:
- Phần 1 là thêm model vào Django app, quản lý version của model cũng như các thông số như trạng thái, tên, ...
- Phần 2 là thêm inference vào Django app, giới thiệu các bạn về A/B testing trong ML bằng việc sử dụng model ExtraTree đã train ở mục trên, đóng gói project bằng Docker.
Link Git: https://github.com/hoangpm-2081/ml_system_sample
References
https://www.deploymachinelearning.com/#add-ml-algorithms-to-the-registry (Author: Piotr Płoński)
All rights reserved
