Quản Lý Dữ Liệu Qua Hướng Sự Kiện Trong Mô Hình Microservice
Bài đăng này đã không được cập nhật trong 6 năm
Xin chào các đọc giả của Viblo, vẫn là mình - dev gà mờ đây  ) Trong chuỗi bài viết về Microservice mà mình tìm hiểu và đang dần thấu hiểu trên Viblo, mình đã điểm qua được một số vấn đề chính về cái mô hình toẹt vời này. Giới thiệu này, cách xây dựng này, sự giao tiếp của chúng này )
) Trong chuỗi bài viết về Microservice mà mình tìm hiểu và đang dần thấu hiểu trên Viblo, mình đã điểm qua được một số vấn đề chính về cái mô hình toẹt vời này. Giới thiệu này, cách xây dựng này, sự giao tiếp của chúng này )
Và để tiếp nối về chuỗi bài viết, ở lần này mình sẽ trình bày về cách thức quản lý dữ liệu của chúng, hay chúng ta có thể gọi là cách chúng lưu trữ và tương tác với cơ sở dữ liệu ra sao =)) So, let's get staring
1. Mở Đầu
Vẫn là cách lấy cái mô hình cũ Monolithic để củng cố ưu điểm cho mô hình mới Microservice =)) Như chúng ta đã biết, khi sử dụng mô hình Monolithic, chúng ta sẽ chỉ có một hệ cơ sở dữ liệu duy nhất cho một ứng dụng - thường sẽ là hệ quản trị cơ sở dữ liệu quan hệ. Và đây chính là chìa khóa chính để ứng dụng của bạn có thể sử dụng giao dịch ACID - bốn thuộc tính thường thấy của cơ sở dữ liệu bao gồm:
- Atomicity: Đảm bảo tính vẹn toàn - Chạy hoàn tất toàn bộ giao dịch hoặc ko ko giao dịch nào được thực hiện
- Consistency: Tính nhất quán - Đảm bảo rằng các giao dịch không bao giở dang - Tạo ra một trạng thái mới hoặc đưa về trạng thái ban đầu
- Isolation: Tính độc lập - Các giao dịch chạy độc lập với nhau và phải đảm bảo rằng giao dịch sau sẽ chạy khi giao dịch trước đó hoàn tất
- Durability: Tính bền vững - Khi một giao dịch đã được cam kết, nó sẽ không được hoàn tác lại nữa.
Bốn tính chất này đảm bảo cho cơ sở dữ liệu luôn luôn làm việc một cách hiệu quả và chính xác. Do đó ứng dụng có thể sử dụng để thêm, cập nhập hoặc xóa nhiều giao dịch khác nhau mà không sợ sai sót.
Ngoài lợi ích toẹt vời trên ra thì cơ sử dữ liệu quản hệ còn cung cấp cho chúng ta Sql, một ngôn ngữ mạnh mẽ dùng để tương tác, làm đơn giản hóa việc truy vấn vào cơ sở dữ liệu ) Ngon ko :v
Theo mình nghĩ cài này sẽ ngon khi nó dùng với mô hình Monolithic, còn khi áp dùng cái cơ sở dữ liệu quan hệ - Relational Database Management System (RDBMS) này cho mô hình Microservice có vẻ ko được ngon cho lắm. Vì nguyên lý làm việc của mô hình này là phân nhỏ các dịch vụ ra, mỗi dịch vụ lại có một cơ sở dữ liệu riêng, và nó chỉ được sử dụng thông qua API của service đó. Nếu cùng một cơ sử dữ liệu của một service mà nhiều service khác cũng truy cập vào thì việc cập nhập cho các lược đồ (schema) sẽ tốn thời gian, và còn phải cập nhập cho tất cả các service nữa )
2. Đặt Vấn Đề
Theo những gì mình vừa phân tích ở trên thì có vẻ hơi toang nhỉ. Nhưng đó chưa phải là cái thú vị đâu. Cái này mới thú vị nè:
Nếu mỗi một service sử dụng môt hệ quản trị cơ sở dữ liệu thì sao ? =))
Khủng khiếp để xử lý nếu dùng hệ quản trị cơ sở dữ liệu quan hệ nhỉ. Hoặc nếu dùng thì cũng phải lưu trữ và xử lý nó khá là mệt đó. Vậy chúng ta có thể dùng cái nào đó phù hợp hơn không? Có, và NoSql chính là chiếc chìa khóa để giải quyết vấn đề quan hệ ràng buộc lằng nhằng mà hệ RDBMS gặp phải. Nó cho ta mô hình cơ sở dữ liệu phù hợp hơn, ko có ràng buộc lằng nhằng, hiệu suất cao hơn, và mở rộng tốt hơn :v
Tuy nhiên vẫn có lúc chúng ta cần những ràng buộc trong quản hệ của RDBMS nên cách tốt nhất vẫn là kết hợp hai cái hệ này với nhau: NoSQL và RDBMS và cách này được gọi là PolyglotPersistence hay như mình google dịch thì nó nghĩa là phương pháp tiếp cận bền vững polyglot: Nó gần nghĩa như câu đông tây y kết hợp ý =))
Khi bạn sử dụng cái phương pháp trên để áp dụng vào mô hình Microservice thì các service đạt được hiểu quả cao hơn nhờ việc đảm bảo được hiệu suất cũng như tạo ra các liên kết lỏng lẻo giữa các service, nâng cao khả năng mở rộng hơn. Tuy nhiên nó lại đăt ra một thách thức mới: Quản lý dữ liệu phân tán.
3. Bài Toán
Hình dung chúng ta đang xây dựng một ứng dụng kinh doanh B2B trực tuyến áp dụng mô hình Microservice, sẽ có nhiều khối service kinh doanh trong đó có khối dịch vụ khách hàng - chứa thông tin về khách hàng, mức tín dụng của họ và khối đặt hàng - quản lý các đơn hàng của họ. Và bài toán ở đây là làm sao để các khối service kinh doanh này hoạt động một cách nhất quán với nhau đây ? Làm cách nào để đảm bảo rằng đặt hàng mới không vượt quá giới hạn tín dụng của khách hàng ?
Nếu chúng ta đang ở trong mô hình Monolithic thì việc này khá là đơn giản do chỉ có một hệ cơ sở dữ liệu, chỉ cần kiểm tra mức tín dụng và tạo đơn hàng thôi
Nhưng chúng ta đang ở trong mô hình Microservice, và việc này được thiết lập trong hai hệ cơ sở dữ liệu khác nhau cho từng khối dịch vụ:
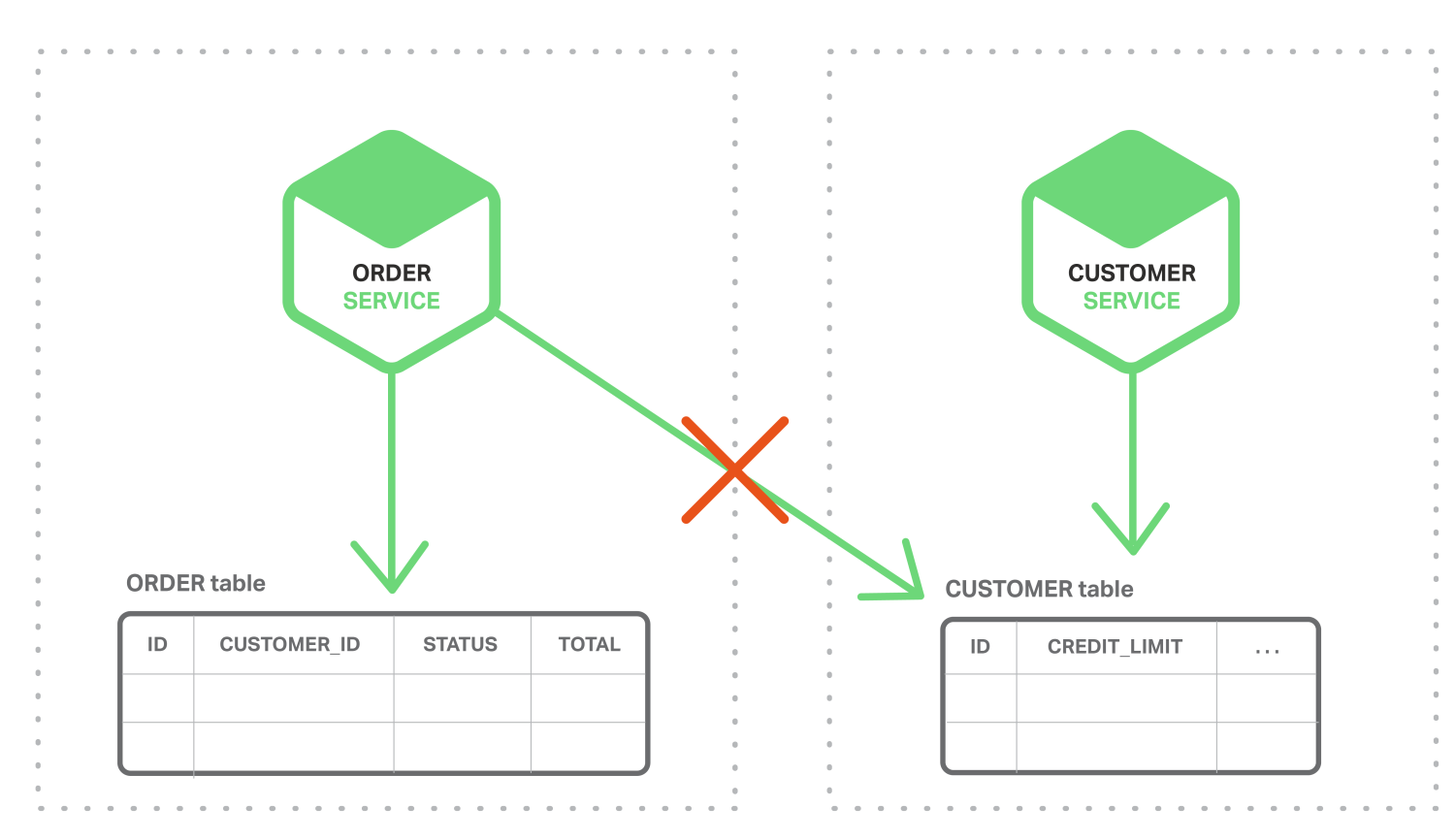
Chúng ta không thể nào check trực tiếp mức tín dụng trong bảng khách hàng được do nó đang ở trong một hệ cơ sở khác. Nó chỉ được sử dụng bới API của khối khách hàng. Nếu khối đặt hàng có thể sử dụng các giao dịch phân tán (2PC). Tuy nhiên đây lại không phải một lựa chọn tốt do nếu chúng ta sử dụng NoSQL thì nó lại ko hỗ trợ 2PC.
Giả sử chúng ta giải quyết được vấn đề trên thì lại sinh ra một vấn đề khác liên quan đến việc truy vấn cơ sở dữ liệu.
Ví dụ: Hãy tưởng tượng rằng ứng dụng cần hiển thị một khách hàng và các đơn đặt hàng gần đây của anh ta. Nếu khối đặt hàng cung cấp API để truy xuất đơn đặt hàng của khách hàng thì bạn có thể truy xuất dữ liệu này bằng cách tham gia bên ứng dụng. Ứng dụng lấy khách hàng từ khối khách hàng và đơn đặt hàng của khách hàng từ khối đặt hàng. Tuy nhiên, giả sử rằng khối đặt hàng sử dụng NoQuery chỉ hỗ trợ truy xuất dựa trên khóa chính thì sẽ gây khó khăn trong việc truy vấn.
Trong tình huống này, không có cách rõ ràng để lấy dữ liệu cần thiết. Toang nhỉ =))
4. Giải Pháp
Và để giải quyểt cho vấn đề trên thì mô hình Microservice đã sử dụng giải pháp hướng sự kiện. Trong đó, khi các khối service thực thi một giao dịch nào đó, nó cho phép các service khác đăng kí thông báo cho giao dịch đó. Khi một dịch vụ Microservice nhận được sự kiện, nó có thể cập nhập cho các service của chính nó, điều này giúp nhiều sự kiện có thể được thông báo.
Bạn có thể áp dụng điều này cho nhiều giao dịch trên nhiều dịch vụ khác nhau. Để hiểu rõ chúng ta sẽ lấy lại bài toán trên để thấy được ví dụ về hướng sự kiện:
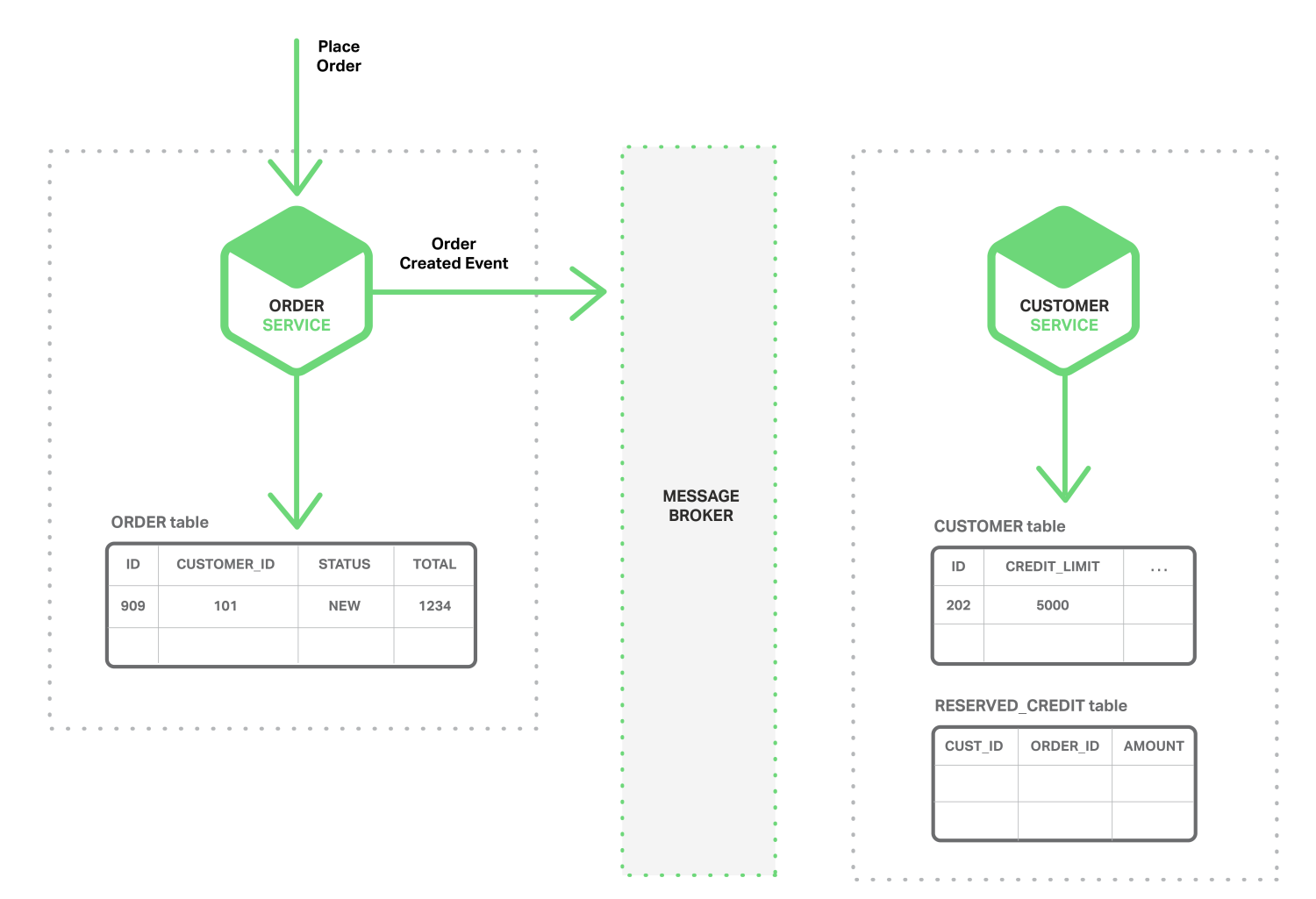
Khi một khối service Đặt Hàng tung ra một thông báo cho một sự kiên Tạo Đơn Hàng, khối servrice Khách Hàng sẽ check sự kiện đó, xử lý sự kiện bên mình và tạo ra một sự kiện mới liên quan đến phần tín dụng và tương tác trở lại cho khối service Đặt Hàng. Hai khối này được tương tác với nhau thông qua một trung tâm kiểm soát thông tin (tin nhắn)
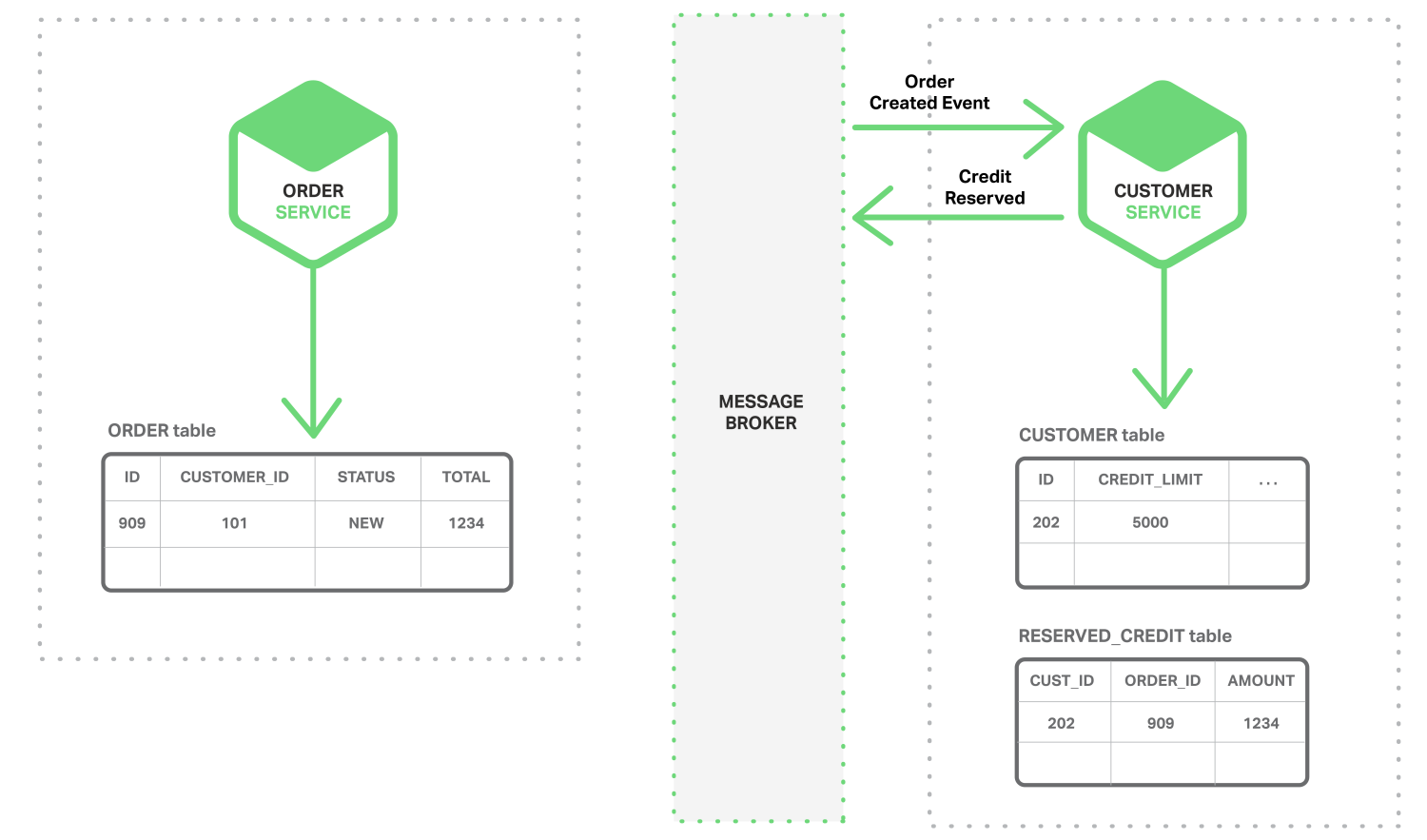
Sự trao đổi thông tin giữ hai sự kiện cửa hai khối service khác nhau này được gọi là mô hình BASE (khác biệt với ACID)
Việc các khối service này tương tác qua lại với nhau thông qua các thông báo sự kiện được nổ ra này ở đây mình chỉ xét đến các giao thực được thực hiện một cách công khai, còn việc xử lý các sự kiện này xảy ra trong từng service một thì nó lại là một chuyện khác. Nó thường là tập hợp một quy trình gồm nhiều bước liên quan đến việc xử lý của cơ sở dữ liệu, cơ chế transaction và việc tận dụng được các nhật ký giao dịch.
5. Kết Luận
Trong mô hình Microservice, mỗi một service lại có một kho lưu trữ riêng với từng xử lý riêng, chúng có thể sử dụng cơ sở dữ liệu SQL hoặc NoSQL khác nhau. Chúng vừa tạo cho ra một sự đa dạng trong việc quản lý dữ liệu nhưng cũng mang lại thách thức liên quan đến việc thống nhất dữ liệu và cách truy vấn dữ liệu từ nhiều dịch vụ
Sự ra đời của kiến trúc hướng kiến trúc đã khắc phục được nhược điểm về sự tương tác giữa các service với nhau. Tuy nhiên vẫn còn phần nào đó các khó khăn khi áp dụng kiến trúc này, đó là việc quản lý các trạng thái và cách các sự kiện này được thông báo ra.
Bài viết là tuy còn sơ sài, hi vọng có thể góp chút kiến thức giúp bạn hình dung rõ hơn về mô hình Microservice.
Cảm ơn các bạn đã đọc bài viết 
All rights reserved
