PySpark cho người mới - Cùng học Pyspark sử dụng data US Stock Price
Bài đăng này đã không được cập nhật trong 5 năm
Happy New Year 2021 ^^ !
Ở trong bài viết này mình sẽ viết bài về Pyspark mục đích để nhớ kiến thức và chia sẻ cho mọi người những gì mình đã học được. Để hỗ trợ Python có thể sử dụng Spark dễ dàng hơn Apache Spark đã released ra một tool là PySpark. Với PySpark chúng ra có thể làm việc cới RDDs trong ngôn ngữ python.
Let's Started!
Install
Để sử dụng được Pyspark bước đầu không thể thiếu đó chính là cài đặt môi trường cho nó. Bạn có thể sử dụng Google colab để thử nghiệm hoặc setup môi trường ở local nhé. Chúng ta cần phải cài đặt Pyspark và Py4J . py4J cho phép chương trình python chạy trong chương trình thông dịch python truy nhập động các đối tượng Java trong máy ảo Java. Cài đặt như dưới đây:
!pip install pyspark==3.0.1 py4j==0.10.9
Khởi tạo SparkSession
from pyspark.sql import SparkSession
spark = SparkSession.builder\
.master("local[*]")\
.appName('Us_stock_price')\
.getOrCreate()
- appName(): dùng để tạo tên cho ứng dụng
- getOrCreate() trả về một SparkSession nếu nó tồn tại hoặc tạo SparkSession mới
Data
Ở đây mình sử dụng dữ liệu US Stock Price các bạn có thể download tại đây để thực hành nhé. Bây giờ sử dụng spark để đọc dữ liệu:
data_ = spark.read.csv('../stocks_price_final.csv', sep= ',', header = True)
Cách đọc dữ liệu của pyspark khá là giống với pandas nếu như mọi người đã từng sử dụng qua, thử xem qua dữ liệu khi đọc bằng pyspark sẽ như thế nào nhé? Mình nghĩ cách đọc khá giống pandas nên thử xem mấy lệnh để check dữ liệu từ pandas vào đây xem có được không 
data.head(3)
Hên quá nó vẫn đọc được và không báo lỗi nè:

Hình: Dữ liệu của US Stock Price
Tuy vẫn là không lỗi nhưng cách hiện thị dữ liệu của spark khác hoàn toàn so với cách hiển thị dữ liệu thành table như trong pandas và nhìn trông cũng rối hơn :3. Khi sử dụng pyspark chúng ta sẽ thường sử dụng printSchema để xem được schema của dữ liệu.
data.printSchema()
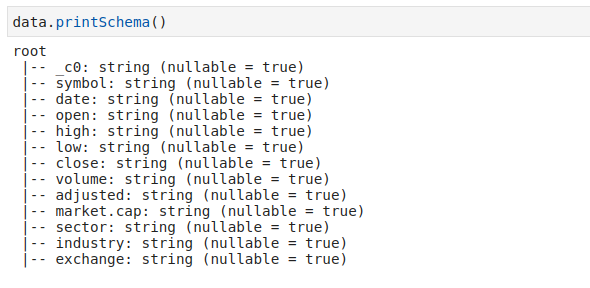
Hình : schema dữ liệu
khi sử dụng printSchema chúng ta có thể biết dữ liệu có những columns nào, kiểu dữ liệu là gì và có dữ liệu null hay không như hình bên trên. Chúng ta cũng có thể sử dụng StructType để define schema.
from pyspark.sql.types import *
data_schema = [
StructField('_c0', IntegerType(), True),
StructField('symbol', StringType(), True),
StructField('open', DoubleType(), True),
StructField('high', DoubleType(), True),
StructField('low', DoubleType(), True),
StructField('close', DoubleType(), True),
StructField('volume', IntegerType(), True),
StructField('adjusted', DoubleType(), True),
StructField('market.cap', StringType(), True),
StructField('sector', StringType(), True),
StructField('industry', StringType(), True),
StructField('exchange', StringType(), True),
]
final_struc = StructType(fields=data_schema)
data = spark.read.csv('../stocks_price_final.csv', sep= ',', header = True, schema = final_struc )
Tiếp theo chúng tử printSchema xem kết quả nhé:
data.printSchema()
 Hình: Schema dữ liệu mới
Hình: Schema dữ liệu mới
Như vậy chúng ta có thể tự define ra schema cho dữ liệu của chính mình nè.
Một số hàm tương ứng với Pandas
Như mình có nhắc ở trên thì mình nghĩ với data dạng bảng biểu thì pyspark khá giống với cách xử lý trong pandas.
head
Ở trong pandas Hàm head có thể show bao nhiêu rows tùy ý thì ở trong pyspark cũng có nè tuy nhiên nhìn lại không đẹp mắt bằng khi show ra bằng pandas. Với hàm này trong pandas thì mặc định của nó là 5 rows còn trong pyspark thì mặc định là 1 row thôi.
data.head()
 Hình: head function
Hình: head function
Để show được nhiều hơn thì chúng ta có thể tự thêm những con số truyền vào theo ý muốn, bên cạnh đó pyspark có hàm show cũng tương tự như head nhưng sẽ show ra dạng table như hình dưới đây và mặc định của hàm nãy sẽ là show ra 20 rows luôn.
data.show()
 Hình: Hàm show
Hình: Hàm show
Columns
Để check được những columns của bảng thì:
data.columns
 Hình: columns function
Hình: columns function
Describe
Giống với Pandas Pyspark cũng có hàm describe để xem tóm tắt về thống kê của các cột với dạng số.
data.describe().show()
 Hình: Describe function
Hình: Describe function
Ngoài những hàm ở trên thì còn có rất nhiều hàm để xử lý dữ liệu trong pyspark nữa, mọi người có thể tham khảo thêm ở đây nè.
Xử lý missing data
Các bạn đọc bài về cách xử lý dữ liệu bị missing này của mình đã từng viết ở trước đây nhé.
Data trước khi xử lý missing
 Hình: data trước khi xử lý missing
Hình: data trước khi xử lý missing
với dữ liệu này mình sẽ điền những giá trị null bằng giá trị 0 hết nhé 
data = data.na.fill(0)
Còn hình ảnh dưới đây là data sau khi xử lý missing:
 Hình: data sau khi đã thay thế giá trị null bằng 0
Hình: data sau khi đã thay thế giá trị null bằng 0
Query data
Pyspark và PysparkSQL cung cấp nhiều hàm tương tự như sql để giúp chúng ta có thể truy vấn dữ liệu một cách dễ dàng hơn.
Select
Giống như trong SQL, Select để giúp chúng ta có thể chọn lựa một hoặc nhiều columns sử dụng tên của các columns.
## Selecting Single Column
data.select('sector').show(5)
## Selecting Multiple columns
data.select(['open', 'close', 'adjusted']).show(5)
 Hình: Select
Hình: Select
Filter
Filter dữ liệu dựa trên điều kiện đã được cho, chúng ta có thể sử dụng các toán tử AND, OR, NOT để đưa ra nhiều điều kiện để filter hơn.
from pyspark.sql.functions import col, lit
data.filter((col('high') >= lit('50')) & (col('low') <= lit('60'))).show(5)
 Hình: filter
Hình: filter
When
Trả về 0 hoặc 1 tùy thược vào điều kiện đã cho ví dụ dưới đây mình chọn điều kiện là giá mở cửa và đóng cửa của cổ phiếu được điều chỉnh lớn hơn hoặc bằng 596300.
data.select('open', 'close',
f.when(data.adjusted >= 596300.0, 1).otherwise(0)
).show(5)
 Hình: when
Hình: when
GroupBy
Mục đích của groupby là nhóm dữ liệu dựa theo trên cột đã cho.
data.select([
'industry',
'open',
'close',
'adjusted'
]
).groupBy('industry')\
.mean()\
.show()
Ở đây mình nhóm các cột 'industry', 'open', 'close', 'adjusted' theo 'industry' và tính giá trị mean của các cột còn lại
 Hình: Groupby
Và nhiều hàm khác như Like, Aggregations, ...
Hình: Groupby
Và nhiều hàm khác như Like, Aggregations, ...
Kết Luận
Ở bài viết này mình đã viết những câu lệnh cơ bản về việc sử dụng pyspark với dữ liệu dạng bảng và cách query dữ liệu sử dụng pyspark SQL. Cảm ơn mọi người đã đọc bài viết của mình, mình sẽ tiếp tục tìm hiểu và chia sẻ chi tiết hơn ở các bài viết tiếp theo nhé (bow). Chúc mừng năm mới mọi người ạ.
Inference
https://www.tutorialspoint.com/pyspark/index.htm
https://towardsdatascience.com/beginners-guide-to-pyspark-bbe3b553b79f
https://www.kaggle.com/dinnymathew/usstockprices
https://medium.com/towards-artificial-intelligence/handle-missing-data-in-pyspark-3b5693fb04a4
All rights reserved
