
[Practical Series] Is Simple Chunking Enough ?
Mở đầu.
Trong lĩnh vực Hồi đáp theo Kiến thức (RAG), việc chia nhỏ văn bản (chunking) là một bước quan trọng để tối ưu hóa truy xuất và sử dụng thông tin. Các kỹ thuật chunking không chỉ cải thiện độ chính xác mà còn giúp tổ chức dữ liệu hiệu quả hơn cho mô hình ngôn ngữ lớn (LLMs). Bài viết này sẽ giới thiệu các loại chunking phổ biến, và chú ý hơn một chút về Semantic Chunking và Proposition-Based Retrieval, cùng vai trò của chúng trong việc nâng cao hiệu suất RAG.
Một chút về 1 hệ thống RAG cơ bản.
Trước khi đọc bài viết của mình thì mọi người có thể đọc 1 bài tổng quan về RAG và các cách tối ưu rất hay từ a Phạm Văn Toàn ở đây.
Oke, Bắt đầu nào. Đầu tiên thì để hiểu Chunking chúng ta sẽ nhìn qua lại một chút về Simple RAG.
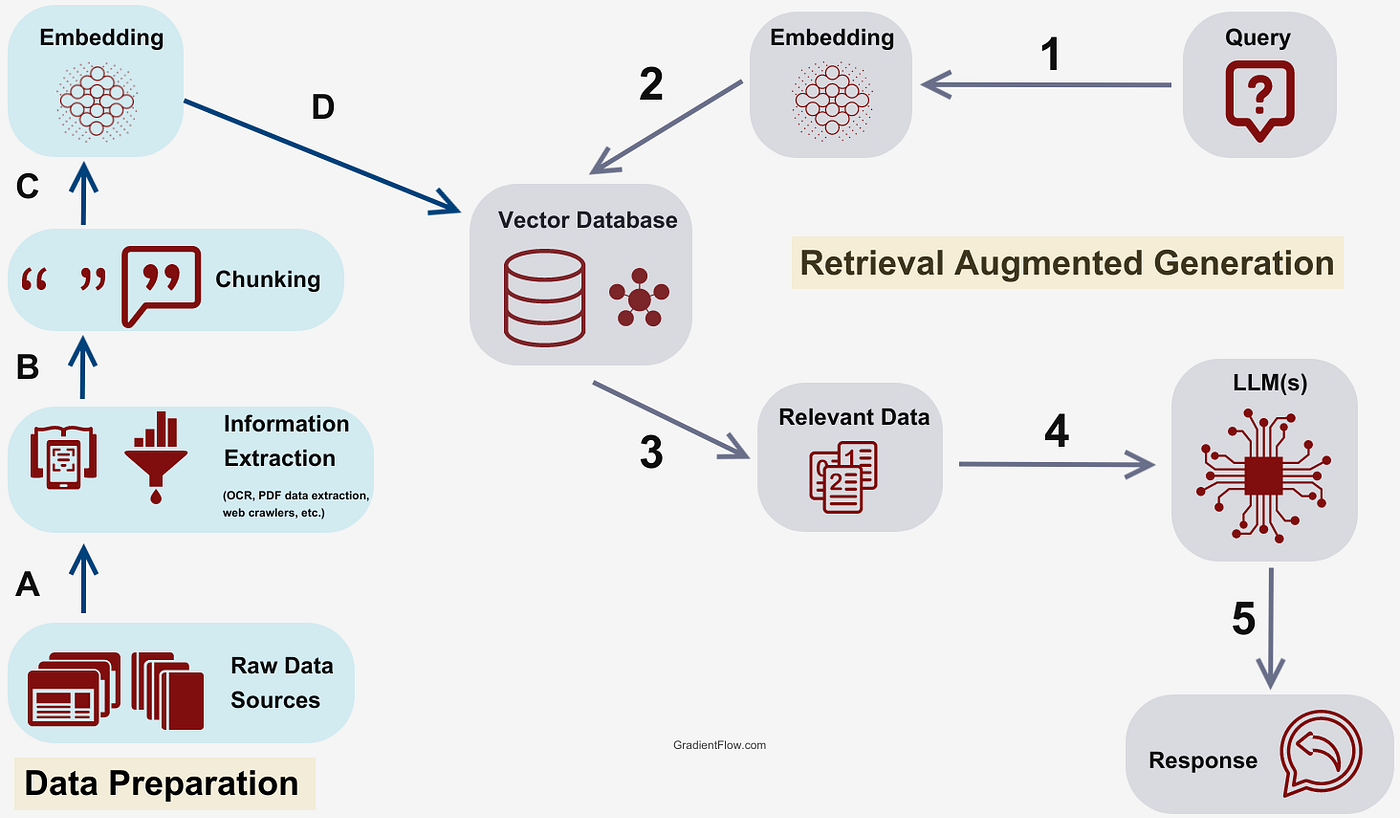
Flow cơ bản của một hệ thống RAG cơ bản sẽ như ảnh trên. Theo mình thì có thể chia thành 5 stages nhỏ:
- Chunking : Nhiệm vụ chính là chia nhỏ tài liệu (text) thành các đoạn text nhỏ hơn (chunks).
- Embedding : embed các chunks thành các vector đại diện cho chunks đó.
- VectorDB : Những vector được embed ở trước đó sẽ được lưu vào một vector database để phục vụ cho việc truy vấn dữ liệu sau này.
- Retrieval : Khi hệ thống nhận được query từ user, hệ thống sẽ embed query thành vector và tìm kiếm các chunks có liên quan đến query của user.
- Response Generation: Gửi query và relevant chunks lên LLM để nhận câu trả lời.
Một chút về các loại Chunking.
Theo mình hiểu thì có rất nhiều loại Chunking chủ yếu được chia thành 5 dạng cơ bản:
Fixed Size Chunking.
Đơn giản thì text sẽ được chia theo số lượng ký tự và nó quyết định bởi Chunk_size và Chunk_overlap

Recursive Chunking.
Hạn chế lớn của Fixed Size Chunking là không quan tâm đến cấu trúc của văn bản, nó chỉ quan đến đến số lượng ký tự. Recursive Chunking để giải quyết một phần hạn chế này, về cơ bản có thể hiểu đơn giản là trước khi sử dụng đến Fixed Size thì Recursize sẽ phân chia text thành các đoạn nhỏ trước bằng các bộ tách như \n\n, \n, ; , : bla bla rồi mới dùng Fixed size để chia các đoạn nhỏ thành từng Chunk một.

Document Based Chunking
Đơn giản chỉ là một bản update so với Recursive Chunking. Document Chunking chia document thành các Chunk dựa trên cấu trúc vốn có của tài liệu. Tuy nhiên thì nó sẽ không đủ hiệu quả đối với những tài liệu mà không có cấu trúc rõ ràng. Có thể kể đến một số loại Document Chunking được support như : Document with Markdown, Python/Js, Tables, Images, ...
Semantic Chunking
Về semantic Chunking về phía sau mình sẽ nói kỹ hơn một chút về phần này.
Agentic Chunking.
Hiểu một cách đơn giản là sử dụng LLm để chunking tài liệu.
Một chút về Semantic Chunking.
Một chút về cách hoạt động.
Về cơ bản thì cách hoạt động của semantic Chunking sẽ dựa trên việc tính tương đồng về mặt ngữ nghĩa giữa các câu hoặc đoạn văn. Hãy xem hình mô tả ở dưới để nhìn tổng quát cách hoạt động.
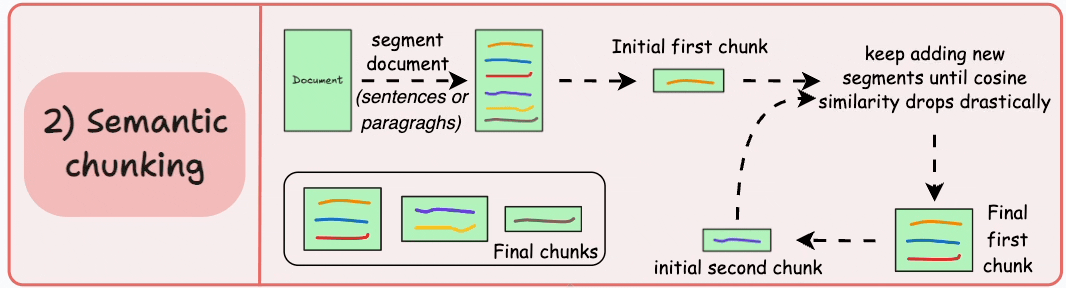 B1: Đầu tiên sẽ chia tài liệu ra thành các chunks nhỏ (ở đây có thể là các câu, hoặc các đoạn).
B1: Đầu tiên sẽ chia tài liệu ra thành các chunks nhỏ (ở đây có thể là các câu, hoặc các đoạn).
B2: Embedd các chunks thành các vector đại diện.
B3: Sau khi có vector đại diện, chúng ta sẽ tiến hành so sánh các chunks nối tiếp nhau (Chunk 1 với chunk2, tiếp tục đến chunk 3, chunk 4, ... nối tiếp nhau). Thường sẽ dùng cosine để so sánh các vector của các chunks.
B4: Nếu 2 Chunk cạnh nhau có độ tương đồng lớn hơn 1 ngưỡng thì gộp 2 chunk đó lại và tiếp tục so sánh tiếp cho đến chunk cuối cùng
B4: Cuối cùng chúng ta sẽ thu được 1 list các chunk khác nhau về mặt ngữ nghĩa. (Mỗi chunk sẽ mang một ý nghĩa riêng).
Một chút thực hành.
Nói sơ qua một chút lý thuyết rồi, giờ chúng ta sẽ đá qua code một xíu. Trước hết chúng ta cần quan tâm đến 2 thông số khi triển khai Semantic Chunking.
- buffer_size : Số lượng câu sẽ gộp thành 1 group trước khi thực hiện semantic chunking. (default = 1 -> từng câu, lớn hơn 1 -> Chính là từng đoạn)
- breakpoint_percentile_threshold : Giá trị giúp kiểm soát các chunk được chia thành dựa trên độ khác biệt ngữ nghĩa giữa một nhóm câu hiện tại và câu tiếp theo. Giá trị càng lớn thì yêu cầu khác biệt về mặt nghĩa ngữ để tách càng lớn (Chunk sẽ rất lớn và ít chunk được tạo ra). Giá trị càng bé thì càng nhỏ (chunk sẽ nhỏ hơn và tạo thành nhiều chunk hơn). (Hiểu đơn giản thì nó là cosine dissimilarity, = 0 là giống nhau hoàn toàn, =1 thì là khác nhau hoàn toàn)
(Logic của Semantic Chunking khá đơn giản, nên việc triển khai từ đâu thì cũng chỉ là for rồi embedd vài dòng là được nên mọi người dùng chatgpt để xem nhé =))) )
Ở đây mình sẽ sử dụng llama-index để sử dụng luôn hàm mà họ đã triển khai sẵn cho tiện.
from llama_index.core import SimpleDirectoryReader
from llama_index.core.node_parser import SentenceSplitter, SemanticSplitterNodeParser
from llama_index.embeddings.azure_openai import AzureOpenAIEmbedding
import os
OPENAI_ENDPOINT=os.getenv("OPENAI_ENDPOINT")
OPENAI_KEY=os.getenv("OPENAI_KEY")
OPENAI_GPT_DEPLOYMENT_NAME=os.getenv("OPENAI_GPT_DEPLOYMENT_NAME")
OPENAI_API_VERSION=os.getenv("OPENAI_API_VERSION")
AZURE_OPENAI__EMBED_DEPLOYMENT_NAME=os.getenv("AZURE_OPENAI__EMBED_DEPLOYMENT_NAME")
embed_model = AzureOpenAIEmbedding(
api_key=OPENAI_KEY,
azure_endpoint=OPENAI_ENDPOINT,
azure_deployment=AZURE_OPENAI__EMBED_DEPLOYMENT_NAME,
api_version=OPENAI_API_VERSION,
)
splitter = SemanticSplitterNodeParser(
buffer_size=3, breakpoint_percentile_threshold=95, embed_model=embed_model
)
doc_path = "data/test.txt"
# content :
"""
Hôm nay là một ngày tuyệt vời để bắt đầu bằng một tách cà phê nóng hổi.
Sau khi thưởng thức bữa sáng, tôi quyết định đi dạo trong công viên gần
nhà, nơi cây cối xanh tươi và tiếng chim hót rộn ràng. Tuy nhiên, tôi hơi
thất vọng vì công viên khá đông đúc, khiến không khí yên bình thường ngày
bị phá vỡ. Mặc dù vậy, tôi vẫn tìm được một góc nhỏ yên tĩnh để đọc cuốn
sách yêu thích. Sau buổi sáng trong lành, tôi quay về nhà để làm việc.
Công việc hôm nay khá bận rộn, nhưng tôi cảm thấy rất hài lòng vì hoàn
thành đượcmột dự án lớn. Buổi tối, tôi tự thưởng cho mình một bữa ăn ngon
và xem một bộ phim hài trước khi đi ngủ.
"""
documents = SimpleDirectoryReader(input_files=[doc_path]).load_data()
nodes = splitter.get_nodes_from_documents(documents)
print(nodes[0].to_dict())
Kết quả khi tôi đặt buffer size = 1 và threshold = 95 như sau :
len nodes 2
==================
Node ID: 334ed00f-f251-4669-ae62-ebb1fb2064c7
Text: Hôm nay là một ngày tuyệt vời để bắt đầu bằng một tách cà phê
nóng hổi. Sau khi thưởng thức bữa sáng, tôi quyết định đi dạo trong
công viên gần nhà, nơi cây cối xanh tươi và tiếng chim hót rộn ràng.
Tuy nhiên, tôi hơi thất vọng vì công viên khá đông đúc, khiến không
khí yên bình thường ngày bị phá vỡ. Mặc dù vậy, tôi vẫn tìm được một
góc nhỏ yên...
==================
Node ID: 2498dc8d-4b36-4524-95c2-748b480c8495
Text: Công việc hôm nay khá bận rộn, nhưng tôi cảm thấy rất hài lòng
vì hoàn thành được một dự án lớn. Buổi tối, tôi tự thưởng cho mình một
bữa ăn ngon và xem một bộ phim hài trước khi đi ngủ.
Nhưng nếu tôi để threshold nhỏ hơn một chút (may be 70) sẽ chia thành nhiều chunk hơn với nội dung bị chia nhỏ ra hơn.
len nodes 3
==================
Node ID: e530c434-076e-47e6-9ac3-9398dfbe5700
Text: Hôm nay là một ngày tuyệt vời để bắt đầu bằng một tách cà phê
nóng hổi. Sau khi thưởng thức bữa sáng, tôi quyết định đi dạo trong
công viên gần nhà, nơi cây cối xanh tươi và tiếng chim hót rộn ràng.
==================
Node ID: caa79c45-0e13-49c7-840f-255a9ac7bd28
Text: Tuy nhiên, tôi hơi thất vọng vì công viên khá đông đúc, khiến
không khí yên bình thường ngày bị phá vỡ. Mặc dù vậy, tôi vẫn tìm được
một góc nhỏ yên tĩnh để đọc cuốn sách yêu thích. Sau buổi sáng trong
lành, tôi quay về nhà để làm việc.
==================
Node ID: 00770320-a9e4-44b8-a845-7f6f4b825571
Text: Công việc hôm nay khá bận rộn, nhưng tôi cảm thấy rất hài lòng
vì hoàn thành được một dự án lớn. Buổi tối, tôi tự thưởng cho mình một
bữa ăn ngon và xem một bộ phim hài trước khi đi ngủ.
node 2 và node 3 đều đang nói về công viên nhưng bị tách ra nhỏ hơn, đó là do threshold đã giảm xuống. Tuy mặt ngữ nghĩa hơi hơi giống nhau nhưng sẽ bị tách thành 2 chunk khác nhau.
Note:
- Chất lượng của các tất node, tất nhiên sẽ còn phụ thuộc vào nhiều yếu tố khác, ví dụ như mô hình embedding chẳng hạn.
- nếu không dùng Azure OpenAI Embedding, mọi người có thể sử dụng các model embedding khác chỉ cần kế thừa lại lớp BaseEmbedding là có thể dùng được (Có thể xem qua mẫu của huggingfaceembedding mà llama-index đã triển khai sẵn.)
Một Chút về Proposition Retrieval.
Một chút về cách hoạt động.
Trước khi đọc tiếp thì mình xin đính chính đây không phải là một paper explain 🫣, cho nên mình chỉ điểm qua một vài ý chính mình thấy nó hay ho và nổi trội và mình diễn giải theo cách mình hiểu nên có thể sẽ bị tối nghĩa, và tất nhiên sẽ thiếu rất nhiều detail, nội dung khác mà mình lược bỏ, thậm chí không nhắc đến. Rất mong mọi người góp ý nếu có sai sót hoặc hiểu sai ý nghĩa phần nào đó.
Oke, Paper của Proposition Retrieval ở đây, mọi người có thể đọc kỹ hơn nếu muốn biết một cách chuẩn xác 😃
Let's goo.
Trong paper, author đang nói đến việc khi chúng ta thực hiện retrieval (dễ hình dung nhất là hệ thống RAG), chúng ta hay bỏ qua việc thiết kế retrieval unit sao cho hiệu quả. Và trong paper họ giới thiệu một khái niệm mới proposition giúp tối ưu cho quá trình retrieval thông tin khi inference (trong RAG thì nó là bước query data trong vector store)
Hừm, thế thì retrieval unit là gì ? proposition là gì ? tại sao lại tối ưu hơn ? Hãy đào sâu hơn một chút về khái niệm.
Một chút khái niệm.
Retrieval Unit
Paper : retrieval unit in which the corpus is indexed, e.g. document, passage, or sentence . Retieval Unit là đơn vị cơ bản được sử dụng trong việc lập chỉ mục (index) và truy vấn thông tin (query) từ một tập dữ liệu. Nó có thể là document, passage, sentence.
Vẫn hơi phức tạp nhỉ ? 🤔 Không hoàn toàn giống nhưng chúng ta có thể liên tưởng đến một khái niệm tương tự Chunk (Chunk - là các đoạn văn bản được chia nhỏ ra từ quá trình chunking).
Việc thiết kế retrieval unit có mức độ đặc biệt quan trọng trong các hệ thống RAG vì nó ảnh hưởng đến chất lượng của cả hệ thống.
- retrieval unit as document : giữ được trọn ngữ cảnh, nhưng mà nhược điểm là quá dài, chứa nhiều thông tin không liên quan, dễ nhiễu.
- retrieval unit as passage : nhỏ hơn document, ưu điểm là giảm nhiễu, cung cấp ngữ cảnh cô đọng hơn nhưng vẫn có thể chứa các thông tin không liên quan.
- retrieval unit as sentence: nhỏ gọn, ít nhiễu, nhưng mà tồn tại nhược điểm là thiếu ngữ cảnh để hiểu ngữ nghĩa câu văn.
Proposition as a Retrieval Unit
Paper : Propositions are defined as atomic expressions within text, each encapsulating a distinct factoid and presented in a concise, self-contained natural language format. Các mệnh đề (proposition) được định nghĩa là các biểu thức nguyên tử trong văn bản, mỗi mệnh đề bao gồm một thông tin riêng biệt và được trình bày theo một định dạng ngôn ngữ tự nhiên ngắn gọn, tự chứa.
Nghe căng thẳng quá nhỉ ? Biểu thức nguyên tử trong văn bản, thông tin riêng biệt, trình bày ngắn gọn tự chứa 😂.
Oke đơn giản dễ hiểu như tên tiếng việt của nó : Proposition là mệnh đề. Nó cần đảm bảo 3 điều kiện sau thì mới được coi là một mệnh đề:
- Mỗi mệnh đề phải mang một ý nghĩa riêng biệt, khi kết hợp tất cả các mệnh đề thì sẽ đại diện nghĩa của toàn bộ văn bản
- Mỗi mệnh đề phải là tối thiểu, tức là sẽ không thể chia nhỏ ý nghĩa của mệnh đề thành một câu riêng biệt nào nữa.
- Một mệnh đề cần bao gồm tất cả bối cảnh cần thiết từ văn bản để diễn giải ý nghĩa của nó.
Oke, lấy một chút ví dụ cho dễ hiểu nào.
Document : Python là một ngôn ngữ lập trình phổ biến. Nó được sử dụng rộng rãi trong khoa học dữ liệu, trí tuệ nhân tạo, và phát triển web. Guido van Rossum là người tạo ra Python vào năm 1991.
Proposition : từng ý dưới đây là một "mệnh đề"
- Python là một ngôn ngữ lập trình.
- Python phổ biến.
- Python được sử dụng trong khoa học dữ liệu.
- Python được sử dụng trong trí tuệ nhân tạo.
- Python được sử dụng trong phát triển web.
- Guido van Rossum tạo ra Python.
- Python ra đời vào năm 1991.
Note : Ngoài ra còn rất nhiều khái niệm nữa nhưng mình skip do mình nghĩ chỉ cần tập trung vào Proposition là đủ.
Một chút về flow.
Về cơ bản có thể chia thành 6 bước nhỏ:
- Prepare Your Data : chính là document mà muốn retrieval đến, clean text, cấu trúc định dạng file, bla bla
- Generate Propositions : Đây chính là yếu tố then chốt, sử dụng một mô hình LLm mạnh để sinh proposition từ text.
- Check Quality : kiểm tra lại xem proposition này có đúng đủ như 3 điều kiện mô tả ở trên khái niệm hay không
- Index the proposition: Sau khi kiểm tra xong thì index lại các proposition (embedding) vào store.
- Retrieval: Khi mà query đến thì sử dụng dense retrievak (query) lấy ra các proposition liên quan.
- Use in your system: Sử dụng cơ chế này vào trong các hệ thống RAG.
Oke, ngó qua thì key nằm ở bước 2.
Như trong paper thì author đang train một model LLm để làm nhiệm vụ trích xuất document ra proposition. Về data để train thì tác giả có nói là sử dụng một con LLM mạnh (như chatgpt 4) để sinh ra các proposition từ document.
Một chút thực hành.
Tuy nhiên theo mình thì hiện tại các mô hình LLM rất mạnh và đủ thông minh để làm nhiệm vụ này, đồng thời nó cũng khá rẻ nên thay vì train một mô hình mới thì chúng ta có thể dùng luôn LLM mạnh để gen ra proposition luôn (ở đây hiện tại mình đang dùng gpt4omini).
Ngó nghĩa qua một chút prompt mà tác giả cung cấp :
Decompose the "Content" into clear and simple propositions, ensuring they are interpretable out of
context.
1. Split compound sentence into simple sentences. Maintain the original phrasing from the input
whenever possible.
2. For any named entity that is accompanied by additional descriptive information, separate this
information into its own distinct proposition.
3. Decontextualize the proposition by adding necessary modifier to nouns or entire sentences
and replacing pronouns (e.g., "it", "he", "she", "they", "this", "that") with the full name of the
entities they refer to.
4. Present the results as a list of strings
Input: Title: Eostre. Section: Theories and interpretations, Connection to Easter Hares. Content: ¯
The earliest evidence for the Easter Hare (Osterhase) was recorded in south-west Germany in
1678 by the professor of medicine Georg Franck von Franckenau, but it remained unknown in
other parts of Germany until the 18th century. Scholar Richard Sermon writes that "hares were
frequently seen in gardens in spring, and thus may have served as a convenient explanation for the
origin of the colored eggs hidden there for children. Alternatively, there is a European tradition
that hares laid eggs, since a hare’s scratch or form and a lapwing’s nest look very similar, and
both occur on grassland and are first seen in the spring. In the nineteenth century the influence
of Easter cards, toys, and books was to make the Easter Hare/Rabbit popular throughout Europe.
German immigrants then exported the custom to Britain and America where it evolved into the
Easter Bunny."
Output: [ "The earliest evidence for the Easter Hare was recorded in south-west Germany in
1678 by Georg Franck von Franckenau.", "Georg Franck von Franckenau was a professor of
medicine.", "The evidence for the Easter Hare remained unknown in other parts of Germany until
the 18th century.", "Richard Sermon was a scholar.", "Richard Sermon writes a hypothesis about
the possible explanation for the connection between hares and the tradition during Easter", "Hares
were frequently seen in gardens in spring.", "Hares may have served as a convenient explanation
for the origin of the colored eggs hidden in gardens for children.", "There is a European tradition
that hares laid eggs.", "A hare’s scratch or form and a lapwing’s nest look very similar.", "Both
hares and lapwing’s nests occur on grassland and are first seen in the spring.", "In the nineteenth
century the influence of Easter cards, toys, and books was to make the Easter Hare/Rabbit popular
throughout Europe.", "German immigrants exported the custom of the Easter Hare/Rabbit to
Britain and America.", "The custom of the Easter Hare/Rabbit evolved into the Easter Bunny in
Britain and America." ]
Input: <a new passage>
Output:
Hừm đơn giản họ chỉ define lại một 4 ý để khi gen proposition theo đúng 3 tiêu chuẩn của proposition.
Vậy thì đi thử một chút.
from llama_index.llms.azure_openai import AzureOpenAI
import os
OPENAI_ENDPOINT=os.getenv("OPENAI_ENDPOINT")
OPENAI_KEY=os.getenv("OPENAI_KEY")
OPENAI_GPT_DEPLOYMENT_NAME=os.getenv("OPENAI_GPT_DEPLOYMENT_NAME")
OPENAI_API_VERSION=os.getenv("OPENAI_API_VERSION")
AZURE_OPENAI__EMBED_DEPLOYMENT_NAME=os.getenv("AZURE_OPENAI__EMBED_DEPLOYMENT_NAME")
client = AzureOpenAI(
azure_endpoint=OPENAI_ENDPOINT,
azure_deployment=OPENAI_GPT_DEPLOYMENT_NAME,
api_key=OPENAI_KEY,
api_version=OPENAI_API_VERSION,
)
with open("test/prompt_proposition.txt") as f:
prompt = f.read()
content = "Python is a popular programming language. It is widely used in data science, artificial intelligence, and web development. Guido van Rossum created Python in 1991."
prompt = prompt.format(content=content)
response = client.complete(prompt=prompt, formatted=True)
print(response)
Và output nó sẽ có dạng như thế này :
[
"Python is a popular programming language.",
"Python is widely used in data science.",
"Python is widely used in artificial intelligence.",
"Python is widely used in web development.",
"Guido van Rossum created Python in 1991."
]
Cũng khá giống với kết quả mẫu ví dụ ở trên nhỉ ☺️
Phần này cũng khá dài rồi nên mình xin kết luận một vài ý ở đây :
- Trong paper Proposition Retrieval, tác giả còn mô tả nhiều công đoạn khác nhau nữa, liên quan đến việc đánh giá, phân tích kết quả proposition, kết quả huấn luyện mô hình, đánh giá trên các benchmark QA.
- Về phần thực hành trên mình chỉ run lại prompt mà tác giả cung cấp trên paper. Khi thiết kế trong hệ thống sẽ còn nhiều thứ cần setup, đây là agentic chunking gồm nhiều công đoạn và setup code khác nữa chứ không chỉ việc gửi prompt lên là được.
- Có nhiều ưu điểm khác nữa, cũng như nhược điểm của proposition như ngôn ngữ, data, chất lượng phụ thuộc vào LLm, cần phải đánh giá bởi con người, ... Tuy nhiên cũng không phủ nhận việc sử dụng proposition sẽ làm các chunk mang đặc điểm riêng biệt cụ thể và đầy đủ ngữ cảnh hơn so với các loại chunking khác.
Một chút kết luận.
Oke, nó đã khá dài rồi nhưng vẫn cần tổng kết một chút.
Ở bài viết này, mình xin phép được tổng hợp lại một số loại chunking thông dụng, mô tả kỹ hơn một chút về Semantic Chunking và Proposition Chunking.
Đặc biệt, tuỳ vào bài toán, dữ liệu, cũng như scope của dự án mà sẽ có các chiến thuật chunking được áp dụng khác nhau, không phải cứ dùng agentic chuning là tốt, đặc biệt dùng nhiều sẽ khá tốn xiền, mặc dù api khá rẻ, ngoài ra chất lượng proposition cũng là một điều đáng quan tâm (do mình còn phải đánh giá bằng con người lại trước khi index - nhưng mà nếu tự tin nó gen ra ổn thì cứ index vào vector store thôi kk =))) ).
Đồng thời bài viết vẫn còn nhiều kỹ thuật chưa nhắc đến như late chunking hay meta chunking mới ra gần đây. Sẽ update tiếp các kỹ thuật khác nữa ở các phần tiếp theo.
Cuối cùng, nếu thấy hay thì mình xin một upvote, và bookmark :v , đây là một động lực không nhỏ để mình tiếp tục viết các bài viết ngắn ngọn xúc tác như này :v
References.
https://docs.llamaindex.ai/en/stable/examples/node_parsers/semantic_chunking/ https://medium.com/the-ai-forum/semantic-chunking-for-rag-f4733025d5f5 https://arxiv.org/pdf/2312.06648 https://medium.com/@nirdiamant21/the-propositions-method-enhancing-information-retrieval-for-ai-systems-c5ed6e5a4d2e https://freedium.cfd/https://medium.com/@anuragmishra_27746/five-levels-of-chunking-strategies-in-rag-notes-from-gregs-video-7b735895694d
All rights reserved
