Phát hiện ngôn ngữ lập trình cực kỳ đơn giản với Machine learning
Bài đăng này đã không được cập nhật trong 7 năm

Hôm nay trời thanh gió mát, Lập trình không khó sẽ cùng các bạn đi xây dựng một chương trình có thể dự đoán ngôn ngữ lập trình khi cung cấp cho nó code. Ý tưởng có vẻ khá to, nhưng đơn giản lắm. Cùng mình bắt tay vào triển khai nhé.
Dự đoán ngôn ngữ lập trình
Ý tưởng bài toán dự đoán ngôn ngữ lập trình rất đơn giản: hãy đưa cho tôi một đoạn code. Tôi sẽ cho bạn biết code này được viết bởi ngôn ngữ lập trình nào!
Trên thực tế, khi bạn nhìn vào một source code bạn có thể đoán được ngôn ngữ lập trình nào được dùng để tạo ra đoạn code đó không? Câu trả lời là không, nếu bạn chưa biết tới ngôn ngữ đó. Nhưng nếu bạn đã sử dụng qua, bạn có thể dễ dàng biết đó là ngôn ngữ nào. Tại sao bạn lại có thể đoán được: Tất nhiên là nhìn vào cú pháp của đoạn code để tìm ra các đặc trưng của mỗi ngôn ngữ phải không nào? Chẳng hạn như:
- Ngôn ngữ Python: định nghĩa hàm bằng từ khóa def, không có cặp ngoặc {}, sử dụng câu lệnh
import, có dòngif __name__ == __main__,… - Ngôn ngữ C++: khai báo thư viện dùng
#include, cócout,cinhuyền thoại,…
Mỗi ngôn ngữ đều có những đặc điểm riêng. Và việc của chúng ta là tìm cách xây dựng một chương trình có thể làm điều đó.
Ở góc nhìn của machine learning, đây thực chất là bài toán phân loại văn bản(document classification) nhiều lớp. Và mỗi một lớp sẽ là một ngôn ngữ lập trình. Trong bài viết này, mình sẽ cùng các bạn từng bước xây dựng một chương trình dự đoán ngôn ngữ lập trình hoàn chỉnh. Chúng ta sẽ đi qua các phần:
- Chuẩn bị dữ liệu
- Tiền xử lý
- Train mô hình sử dụng Fasttext
- Xây dựng giao diện với Flask
Các bạn đừng quá lo lắng nếu không biết nhiều về machine learning. Bài viết này được viết là dành cho những người không chuyên. Bây giờ chúng ta sẽ đi vào từng phần chi tiết nhé.
1. Chuẩn bị dữ liệu
Dữ liệu là thứ không thể thiếu đối với máy học. Bây giờ chúng ta cần đi kiếm cho mỗi ngôn ngữ một kho code. Mình giả sử mỗi ngôn ngữ lập trình có tầm 1000 đoạn code là ok. Chúng ta sẽ cố gắng phân loại càng nhiều ngôn ngữ lập trình càng tốt. Nhưng điều đó còn phụ thuộc vào dữ liệu ^^.
Tìm kiếm ý tưởng
Nghĩ đến code là mình nghĩ ngay tới StackOverFlow, lên đó lượn 1 hồi cũng nghĩ ra cách để kiếm dữ liệu cực kỳ ez. Ý tưởng như sau:
Đầu tiên, vào trang Tags của họ để lấy các tags về, các ngôn ngữ lập trình có tags nằm trong top đầu luôn, nên chúng ta chỉ cần lấy khoảng 5 trang đầu là lấy được hầu hết ngôn ngữ lập trình rồi.
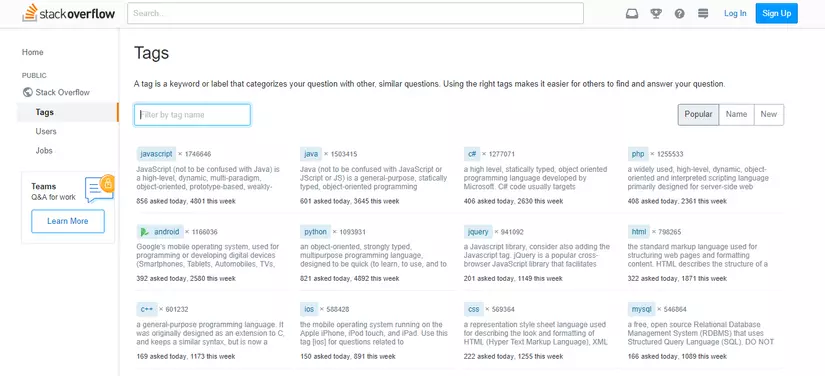
Triển khai ý tưởng
Để làm được điều này thì mình sử dụng thư viện requests trong Python để crawl data. Sau đó extract lấy tags và url tới các tags đó. Mục đích là để lọc các bài viết theo thẻ tags. Tất nhiên, sẽ có lẫn một số tags không phải ngôn ngữ lập trình, lọc tay qua 1 lượt chưa mất tới 5 phút 🙂
Một phát hiện thú vị nữa, mỗi đoạn code trong trang này đều có class đi kèm, chẳng hạn đoạn code php có css-class là lang-php, hay Python thì là lang-py,… Bước này lại phải làm bằng tay, phải mò thôi. Sau cùng cũng thu được một bộ sưu tập gồm khoảng 20 class khác nhau(20 ngôn ngữ lập trình). Việc còn lại phải làm là đi lôi dữ liệu về máy thôi. Với mỗi tags chúng ta đã có url để lọc bài viết rồi, lọc tiếp theo css-class để thu được dữ liệu chuẩn nhất.
Với mỗi ngôn ngữ lập trình, thực hiện requests theo từng link tới tags đó để kiếm các bài viết của tags đó. Nhưng vấn đề phát sinh nữa là: Các cục code này load bằng Javascript. Lúc này requests chịu thua rồi. Mình phải tìm giải pháp mới đó là Selenium. Ưu điểm của thằng này là chơi luôn được với Javascript. Thế là ngon rồi, kéo dữ liệu về thôi. Nói dễ chứ quá trình lôi data về cũng rất tốn thời gian(mất mấy ngày lận), lại còn bị StackOverFlow chặn do “Spam Request”. Ai biết cách tránh lỗi này mách mình với nha.
Sau bước này, chúng ta thu được kha khá dữ liệu, mỗi ngôn ngữ lưu vào 1 file riêng biệt. Lượng code này cũng đủ để dùng cho huấn luyện rồi.
2. Tiền xử lý dữ liệu
Việc tiền xử lý dữ liệu sẽ giúp chương trình dự đoán ngôn ngữ lập trình chính xác hơn. Tuy nhiên, Dữ liệu đặc thù, cũng là lần đầu mình làm nên chẳng biết giữ gì, bỏ gì. Suy nghĩ một hồi thì cũng nhận ra 2 cái cần làm:
- Xóa bỏ các dòng comment trong Code, cái này có đọc cũng chẳng biết là ngôn ngữ gì này
- Loại khoảng trắng thừa, đưa về 1 dòng thôi. Có vẻ nó cũng vô dụng ý nhể
- Còn cái gì có thể làm thì các bạn gợi ý thêm mình với, chả biết làm gì nữa…
Thế là từ một đoạn code như này:
def check():
# Comment
return render_template('index.html')
/*
Comemnt
*/
Sau khi xử lý thì chúng ta thu được:
def check(): return render_template(
Ở đây, việc xóa comment trong code sử dụng các regex sau đây:
// Remove comment
(\/\/.+)|(#.+)|('.+)|(\/\*[^(\*\/)]+?\*\/)|(\"{3}[^(\"{3})]+?\"{3}) -> ' '
// Remove extra space
\s+ -> ' '
Nó xóa mất cả cái ‘index.html’ rồi, nhưng kệ nó, vì dấu ‘ cũng là bắt đầu comment của một ngôn ngữ nào đó mà mình cũng chẳng nhớ nữa. Bạn có thể xem cách cái regex này nó hoạt động ra sao tại đây.
Theo quan sát thì có vẻ phần tiền xử lý này chưa được tối ưu cho lắm. Phần này mình nhờ các bạn tiếp tục tối ưu thêm giúp mình. Xong khâu tiền xử lý, bây giờ đi vào huấn luyện thôi nào.
3. Huấn luyện mô hình với Fasttext
Nếu bạn nào chưa biết Fasttext là gì thì xem nó ở đây nhé. Ở đó cũng có hướng dẫn cài đặt, mình thì cài đặt trên Python.
Trước khi huấn luyện, chúng ta cần chuẩn bị dữ liệu huấn luyện(training) và kiểm thử(testing). Ở đây mình sẽ chia theo tỉ lệ train/test = 80/20. 80% dữ liệu sẽ dùng để học và 20% còn lại sẽ test xem thuật toán nó học “giỏi” hay “dốt”. Với Fasttext, mỗi mẫu dữ liệu(ở đây là mỗi đoạn code đó ạ) sẽ có format như sau: __lb__label data. Ví dụ vài mẫu nhé:
__lb__lang-java public class Customer implements Parcelable { private String firstName, lastName, address; int age; public Customer(Parcel in ) { readFromParcel( in ); } public static final Parcelable.Creator CREATOR = new Parcelable.Creator() { public LeadData createFromParcel(Parcel in ) { return new Customer( in ); } public Customer[] newArray(int size) { return new Customer[size]; } }; @Override public void writeToParcel(Parcel dest, int flags) { dest.writeString(firstName); dest.writeString(lastName); dest.writeString(address); dest.writeInt(age); } private void readFromParcel(Parcel in ) { firstName = in .readString(); lastName = in .readString(); address = in .readString(); age = in .readInt(); }
__lb__lang-cs string title = "ASTRINGTOTEST"; title.Contains("string");
__lb__lang-sh find ./fs*/* -type d -print0 | xargs -0 -n 1 cp test
Sau khi chuẩn bị xong thì huấn luyện thôi. Quá trình train chỉ mất vài dòng code là xong.
train_data = "data/train.txt"
valid_data = "data/test.txt"
# train_supervised uses the same arguments and defaults as the fastText cli
model = train_supervised(
# input=train_data, epoch=25, lr=0.1, wordNgrams=2
input=train_data, epoch=5, lr=0.1, wordNgrams=1, verbose=2, loss="softmax", label='__lb__'
)
model.save_model("model/ft.li.1701.bin")
Kết quả train demo với 1 vài nhãn cũng khá ấn tượng. Ở đây, mình sử dụng độ chính xác(Accuracy) = (số mẫu dự đoán đúng)/ (Tổng số mẫu đem ra dự đoán) cho từng nhãn.
{
"__lb__lang-css": 0.99,
"__lb__lang-perl": 0.66,
"__lb__lang-cs": 0.86,
"__lb__lang-php": 0.84,
"__lb__lang-java": 0.9,
"__lb__lang-hs": 0.9,
"__lb__lang-cpp": 0.69,
"__lb__lang-sh": 0.9,
"__lb__lang-html": 0.86,
"__lb__lang-golang": 0.79,
"__lb__lang-c": 0.59
}
Nếu bạn để ý thì độ chính xác của C với C++ đều khá thấp. Tại sao vậy nhỉ? 😀
4. Xây dựng chương trình Demo
Ở đây mình vẫn sẽ dùng Python để làm một cái api demo. Flask framework có thể giúp ta làm việc đó một cách đơn giản. Viết một cái API nhỏ load sẵn model và dùng chức năng render_template để show lên 1 file html lên trình duyệt. Như vậy là đủ dùng rồi nhỉ.
app = Flask(__name__)
class CodeIdentify:
def __init__(self, model_file='../classifier/model/ft.li.1701.bin',
code2namefile='../data_crawler/data/lang_code.json'):
self.model = ft.load_model(model_file)
self.code2name = rev_dict(json.load(open(code2namefile, encoding='utf8')))
self.tp = CodePreprocess()
def pred(self, txt):
txt = self.tp.preprocess(txt)
res = self.model.predict(txt)
label = res[0][0]
score = round(res[1][0], 2)
language_name = self.code2name[label[6:]].upper()
return language_name, score
ci = CodeIdentify()
@app.route('/')
def ping():
return 'ok'
@app.route('/check', methods=['GET', 'POST'])
def check():
if request.method == 'GET':
return render_template('index.html')
else:
try:
code = request.form['code']
if not code or len(code) <= 20:
return render_template('index.html', error='Please type more than 20 characters!')
language, score = ci.pred(code)
return render_template('index.html', language=language, score=score, code=code)
except:
traceback.print_exc()
return render_template('index.html', error='Unknown error has occurred, please try again!')
if __name__ == '__main__':
app.run(debug=True)
Và đây là giao diện chương trình sau khi chạy:
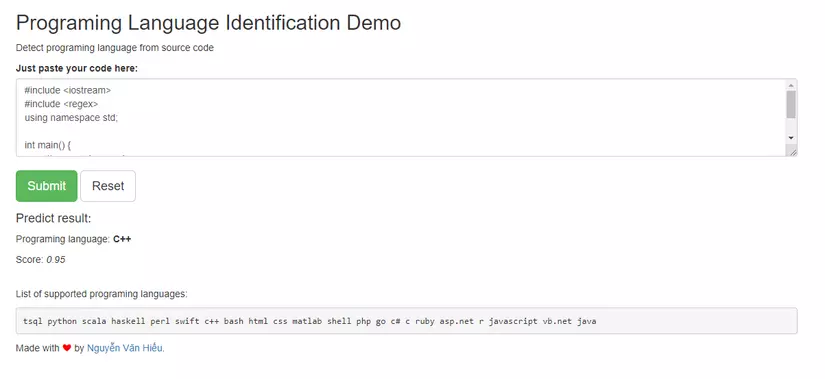
5. Kết luận
Vậy là xong một chương trình dự đoán ngôn ngữ lập trình phức tạp mà lại cực kỳ đơn giản. Source code của bài này mình để tại link github này. Nếu thấy hay đừng quên cho mình 1 star nhé.
Bugs nè: Nếu bây giờ thằng người dùng nó vứt một bài báo vào thì sao nhỉ? Bạn có thể thêm một nhãn “Unknown” với data không phải code vào để train cùng. Hoặc là xây thêm 1 mô hình sàng lọc với 2 nhãn: Code và NotCode, nếu nó là Code thì mới cho vào mô hình này.
Xin chào và hẹn gặp lại các bạn ở các bài tiếp theo. Mọi thắc mắc hãy để lại tại box comment của bài viết, mình sẽ giải đáp cho các bạn!
Bài viết gốc được đăng tại Blog cá nhân của mình: https://nguyenvanhieu.vn/du-doan-ngon-ngu-lap-trinh-voi-machine-learning/
All rights reserved
