Phân Tích Dữ Liệu Chuỗi Thời Gian - Time Series Forecasting
Giới Thiệu Về Dữ Liệu Chuỗi Thời Gian
Trong kỷ nguyên dữ liệu lớn, một trong những dạng dữ liệu phổ biến và quan trọng nhất mà mọi nhà phân tích đều phải đối mặt là Dữ liệu Chuỗi thời gian (Time Series Data). Khác với dữ liệu chéo (Cross-sectional) thường thu thập ở một thời điểm tĩnh, Time Series là một tập hợp các quan sát được ghi nhận liên tục qua các khoảng thời gian đều đặn (như theo giờ, theo ngày, tháng, quý). Ví dụ điển hình là biến động giá cổ phiếu, doanh số bán lẻ hàng ngày, nhiệt độ môi trường, hay lưu lượng truy cập website. Mục tiêu tối thượng của Phân tích chuỗi thời gian không chỉ là hiểu quá khứ, mà còn là dự báo tương lai. Để làm được điều này, các kỹ sư học máy và nhà khoa học dữ liệu phải đi qua một tiến trình lịch sử các thuật toán, từ những mô hình phân tích thống kê cổ điển cho đến những mạng lưới học sâu tiên tiến.
Bản Chất Và Các Đặc Trưng Cốt Lõi Của Chuỗi Thời Gian
Trước khi xây dựng bất kỳ mô hình nào, ta cần dùng phương pháp Phân rã chuỗi thời gian (Time Series Decomposition) để bóc tách dữ liệu thành 4 thành phần cơ bản:
Trend (Xu hướng): Sự tăng hoặc giảm của dữ liệu trong dài hạn (ví dụ: doanh số bán ô tô điện tăng liên tục trong 10 năm qua).
Seasonality (Mùa vụ): Sự dao động lặp đi lặp lại mang tính chu kỳ ngắn hạn liên quan đến các yếu tố lịch (ví dụ: lượng bán áo ấm luôn tăng vọt vào mùa đông hàng năm).
Cyclical (Chu kỳ): Những biến động dài hạn không theo lịch trình cố định, thường gắn với các chu kỳ kinh tế (khủng hoảng, phục hồi).
Noise/Residual (Nhiễu/Phần dư): Những biến động hoàn toàn ngẫu nhiên không thể dự đoán được.
Một khái niệm sống còn trong lĩnh vực này là Tính dừng (Stationarity). Các mô hình thống kê yêu cầu chuỗi thời gian phải "dừng", tức là các đặc tính thống kê như trung bình và phương sai không đổi theo thời gian. Nếu dữ liệu có xu hướng hoặc mùa vụ, ta phải dùng các công cụ kiểm định (như ADF test) và áp dụng phép lấy sai phân (Differencing) để loại bỏ chúng.
Time-Series-Forecasting-Definition--Methods--and-Applications-taxicab-pickup-count.webp
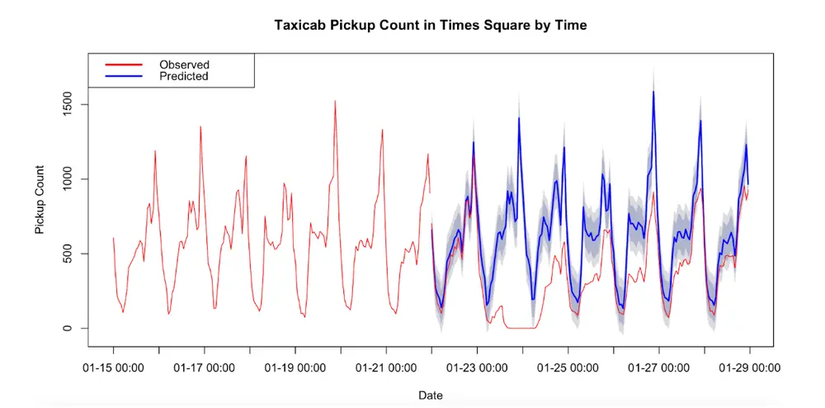
Các Kỹ Thuật Làm Mượt Và Mô Hình Thống Kê Cổ Điển
Những bước đi đầu tiên trong dự báo là các phương pháp làm mượt dữ liệu (Smoothing Techniques) nhằm giảm bớt nhiễu và làm rõ xu hướng. Các phương pháp phổ biến có thể kể đến như Trung bình động (Simple Moving Average - SMA), San bằng mũ (Exponential Smoothing), và đặc biệt là kỹ thuật Holt-Winters.
........ một bậc phức tạp hơn là họ mô hình ARIMA (AutoRegressive Integrated Moving Average). Đây là một trong những thuật toán kinh điển và mạnh mẽ nhất. Nó kết hợp ba yếu tố:
AR (AutoRegressive - p): Dự báo giá trị tương lai dựa trên sự kết hợp tuyến tính của các giá trị trong quá khứ.
I (Integrated - d): Số lần lấy sai phân để biến chuỗi thời gian trở nên "dừng".
MA (Moving Average - q): Dự báo dựa trên phần dư của các khoảng thời gian trước đó.
Để sử dụng ARIMA, các chuyên gia phải kiểm tra các đồ thị Tự tương quan (ACF) và Tự tương quan riêng phần (PACF) để tìm ra hệ số p và q phù hợp. Nếu dữ liệu có tính mùa vụ, mô hình mở rộng SARIMA sẽ được sử dụng. Dù rất chính xác với dữ liệu tuyến tính, ARIMA gặp khó khăn khi mô hình hóa các quy luật phi tuyến tính phức tạp hoặc xử lý các sự kiện bất thường (ngày lễ tết).
[IMG]
Sự Trỗi Dậy Của Machine Learning Và Prophet
Để khắc phục điểm yếu của ARIMA, các nhà phân tích bắt đầu chuyển hướng sang các mô hình Machine Learning truyền thống (như Random Forest, XGBoost) bằng cách sử dụng kỹ thuật "Cửa sổ trượt" (Sliding Window), biến đổi dữ liệu tuần tự thành bài toán Supervised Learning với các đặc trưng độ trễ (lag).
Nổi bật nhất trong giai đoạn này là sự ra đời của thư viện Facebook Prophet. Prophet được thiết kế cực kỳ dễ sử dụng, cho phép xử lý rất tốt các điểm dữ liệu dị biệt (outliers), tự động điền các khoảng trống dữ liệu, và đặc biệt là khả năng kết hợp tác động của các ngày Lễ/Tết (holidays) vào trong mô hình dự báo.
[IMG]
Đỉnh Cao Deep Learning: Đưa RNN Và LSTM Vào Chuỗi Thời Gian
Khi lượng dữ liệu ngày càng lớn và phức tạp, các nhà khoa học dữ liệu áp dụng Học Sâu (Deep Learning) vào Time Series. Mạng nơ-ron truyền thống gặp khó vì chúng không có "bộ nhớ", xử lý từng điểm dữ liệu độc lập. Do đó, Mạng Nơ-ron Hồi quy (RNN - Recurrent Neural Networks) ra đời với kiến trúc mang lại khả năng ghi nhớ thông tin tuần tự.
Tuy nhiên, RNN lại vướng phải một trở ngại vật lý trong toán học gọi là "Trí nhớ ngắn hạn" hay Vanishing Gradient (tiêu biến đạo hàm). Khi học một chuỗi thời gian quá dài, RNN sẽ quên mất thông tin ở giai đoạn đầu, khiến khả năng dự báo dài hạn bị triệt tiêu.
Cứu cánh thực sự xuất hiện với kiến trúc LSTM (Long Short-Term Memory) và GRU. Bằng việc sáng tạo ra cơ chế "Cổng" (Gate Mechanism - bao gồm cổng quên, cổng cập nhật, cổng xuất), LSTM có thể chủ động quyết định giữ lại những thông tin dài hạn quan trọng (quy luật chu kỳ) và "quên đi" những thông tin nhiễu ngẫu nhiên. Nhờ vậy, quá trình dự báo trở nên cực kỳ mạnh mẽ, đặc biệt trên các tập dữ liệu nhiễu cao như thị trường chứng khoán hay cảm biến IoT IoT. Tuy nhiên, để huấn luyện LSTM, dữ liệu bắt buộc phải được co giãn chuẩn hóa (Data Scaling về khoảng), điều mà ARIMA đôi khi không yêu cầu khắt khe.
[IMG]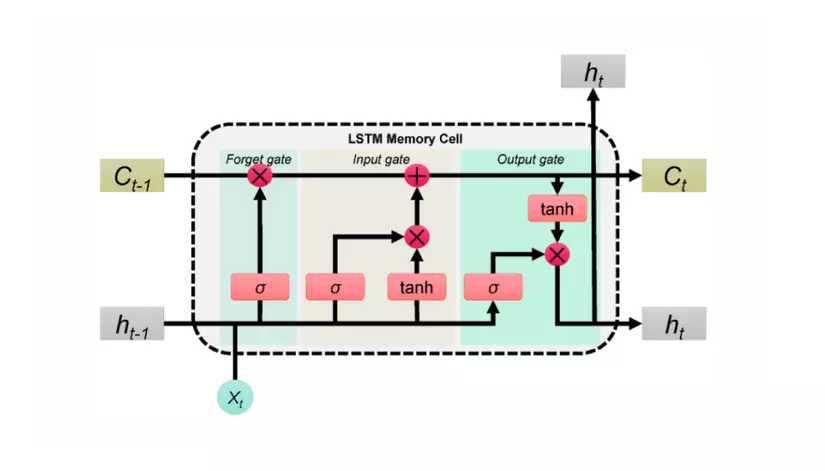
Kết Luận
Phân tích chuỗi thời gian là một nhánh đầy nghệ thuật và tính logic. Tùy thuộc vào đặc thù cấu trúc dữ liệu, độ lớn của tập dữ liệu và yêu cầu hệ thống, các nhà khoa học dữ liệu sẽ linh hoạt lựa chọn từ Holt-Winters, ARIMA, Prophet cho đến những mạng lưới Deep Learning phức tạp như LSTM để mang lại kết quả dự báo ưu việt nhất. Kiến thức nền tảng vững chắc trong toàn bộ tiến trình này chính là hành trang bắt buộc để phân tích và ra quyết định chính xác trong tương lai.
All rights reserved
