Phân tích chuyên sâu về triển khai LLM cục bộ trên Mac & Hướng dẫn kiến trúc lai (2026)
Sau nhiều năm tiến hóa về mặt kiến trúc, trải nghiệm chạy các Mô hình ngôn ngữ lớn (LLM) cục bộ trên chip Apple Silicon đã đạt đến tiêu chuẩn của môi trường sản xuất. Với việc phát hành Ollama phiên bản 0.19 vào năm 2026 và sự chuyển đổi hoàn toàn của công cụ suy luận cốt lõi sang MLX, tốc độ tạo văn bản và hiệu suất sử dụng tài nguyên trên các thiết bị Mac đã chứng kiến một bước nhảy vọt chưa từng có.
Đối với các nhà phát triển và đội ngũ kỹ thuật, việc chỉ phụ thuộc vào một API đám mây duy nhất và gọi giao diện trong thời gian dài sẽ phát sinh chi phí đáng kể. Triển khai cục bộ không chỉ cắt giảm mạnh các khoản phí này mà còn nâng cao đáng kể khả năng bảo mật dữ liệu và tính khả dụng ngoại tuyến. Dưới đây, chúng ta sẽ đi sâu vào cách lựa chọn phần cứng, thiết lập môi trường và thiết kế kiến trúc để triển khai các mô hình AI trên nền tảng Mac.

Bạn cần bao nhiêu RAM để chạy AI cục bộ trên Mac?
Chỉ số trực tiếp quyết định khả năng suy luận cục bộ của Mac chính là dung lượng Bộ nhớ thống nhất (Unified Memory). Apple Silicon tích hợp VRAM và RAM hệ thống làm một, nghĩa là các mô hình lớn sẽ trực tiếp chiếm dụng không gian vật lý này khi được tải. Ngành công nghiệp thường có một lầm tưởng là đánh giá quá cao yêu cầu phần cứng; các công nghệ lượng tử hóa (quantization) hiện tại đã cho phép các mô hình có lượng tham số khổng lồ chạy mượt mà trong giới hạn bộ nhớ hẹp.
Cấu hình với RAM 8GB đến 16GB phù hợp với các mô hình nền tảng nhỏ cỡ 3B. Apple Foundation Models được tích hợp sẵn đã được tối ưu hóa đặc biệt để xử lý việc phân loại văn bản, trích xuất thông tin và hội thoại cơ bản một cách liền mạch trên các thiết bị này. Nếu bạn cần chạy các mô hình 7B đến 8B, việc sử dụng lượng tử hóa 4-bit (chiếm khoảng 5GB bộ nhớ thường trực) có thể miễn cưỡng tải được, nhưng nó có xu hướng tiêu tốn nhiều tài nguyên hệ thống và làm chậm các ứng dụng khác.
RAM 16GB đến 32GB hiện là mức tiêu chuẩn để chạy các mô hình tạo ảnh cục bộ và các mô hình ngôn ngữ cỡ trung bình. Ở mức dung lượng này, thiết bị có thể chạy dễ dàng phiên bản lượng tử hóa Q4 của mô hình Qwen 3 8B, đồng thời vẫn dành ra không gian hoạt động dư dả cho hệ điều hành.
Các cỗ máy có dung lượng RAM lớn từ 32GB lên đến 128GB sẽ mở khóa hoàn toàn khả năng chạy các LLM cỡ 30B hoặc thậm chí 70B. Các mô hình được lượng tử hóa sâu như DeepSeek V3-Distill-32B hoặc Qwen3.5-35B-A3B có thể được tải toàn bộ vào RAM trong phạm vi này, mang lại chất lượng nội dung tạo ra có thể cạnh tranh trực tiếp với các mô hình đám mây xu hướng hiện nay.
Đề xuất các dòng Mac cho Phát triển AI năm 2026
Đáp ứng nhu cầu thực tế của các giai đoạn phát triển khác nhau, dòng sản phẩm Mac năm 2026 mang đến sự phân cấp hiệu năng rõ ràng.
Dòng M1 và M2 (bao gồm cả phiên bản Pro) rất lý tưởng cho các tác vụ nhẹ nhàng. Vì các thiết bị này đã hỗ trợ framework Foundation Models gốc của macOS 26, các nhà phát triển có thể gọi trực tiếp các mô hình 3B tham số có sẵn để xử lý đầu ra cấu trúc hóa, đồng thời kết hợp chúng với mô hình Whisper-base cho các công việc chuyển giọng nói thành văn bản cơ bản.
M3 Pro và M3 Max hiện là những lựa chọn xuất sắc cho các lập trình viên làm việc độc lập. Cấu hình này có thể duy trì nhiều mô hình chạy thường trực trên nền tảng cùng lúc. Các nhà phát triển có thể vừa chạy Qwen 3 8B để xử lý tạo văn bản thông thường, vừa gọi mô hình Phi-4 14B khi cần suy luận logic phức tạp, cho phép thực hiện đa nhiệm vô cùng mượt mà.
Dòng M4 và M5 (đặc biệt là phiên bản Max) đã trải qua một quá trình tái cấu trúc nền tảng chuyên biệt cho các tác vụ suy luận nặng. Bộ tăng tốc thần kinh GPU (GPU Neural Accelerator) trên chip M5 được tối ưu hóa sâu hướng đích cho suy luận LLM. Trong các bài kiểm tra chạy Ollama 0.19 kết hợp với công cụ MLX, M5 Max đạt tốc độ giải mã 112 tokens/s cho Qwen3.5-35B-A3B. Đối với các nhóm phát triển yêu cầu băng thông cực cao và khả năng phân tích mã nguồn, một chiếc M5 Max với RAM khủng có thể thay thế trực tiếp một số máy trạm GPU chuyên dụng.
Hướng dẫn Cài đặt Ollama MLX trên Mac
Bằng cách chuyển sang công cụ MLX, Ollama đã bù đắp được sự thiếu hụt về hiệu suất từng tồn tại trên Apple Silicon khi còn phụ thuộc vào llama.cpp. Với việc hỗ trợ đầy đủ REST API, mọi ứng dụng tương thích với đặc tả API của OpenAI đều có thể sử dụng nó như một dịch vụ suy luận nền tảng.
Trước đây, các nhà phát triển thường quen với việc sử dụng các trình quản lý gói dòng lệnh để cấu hình môi trường. Giờ đây, quá trình triển khai này có thể được đơn giản hóa đi rất nhiều bằng nền tảng ServBay. ServBay cung cấp cài đặt Ollama chỉ bằng một cú nhấp chuột, đồng thời cấu hình sẵn môi trường chạy cho các ngôn ngữ phổ biến như Python, Node.js và PHP, giúp người dùng tiết kiệm được công sức thiết lập biến môi trường và khắc phục lỗi.
Sau khi tải xuống và chạy ServBay trên Mac, bạn chỉ cần chọn hộp kiểm để kích hoạt Ollama trong bảng quản lý dịch vụ của nó. Hệ thống sẽ tự động cấu hình các phần phụ thuộc và khởi chạy dịch vụ nền.
Tiếp theo, bạn có thể tải xuống và cài đặt các mô hình AI cục bộ ngay bên trong ServBay.
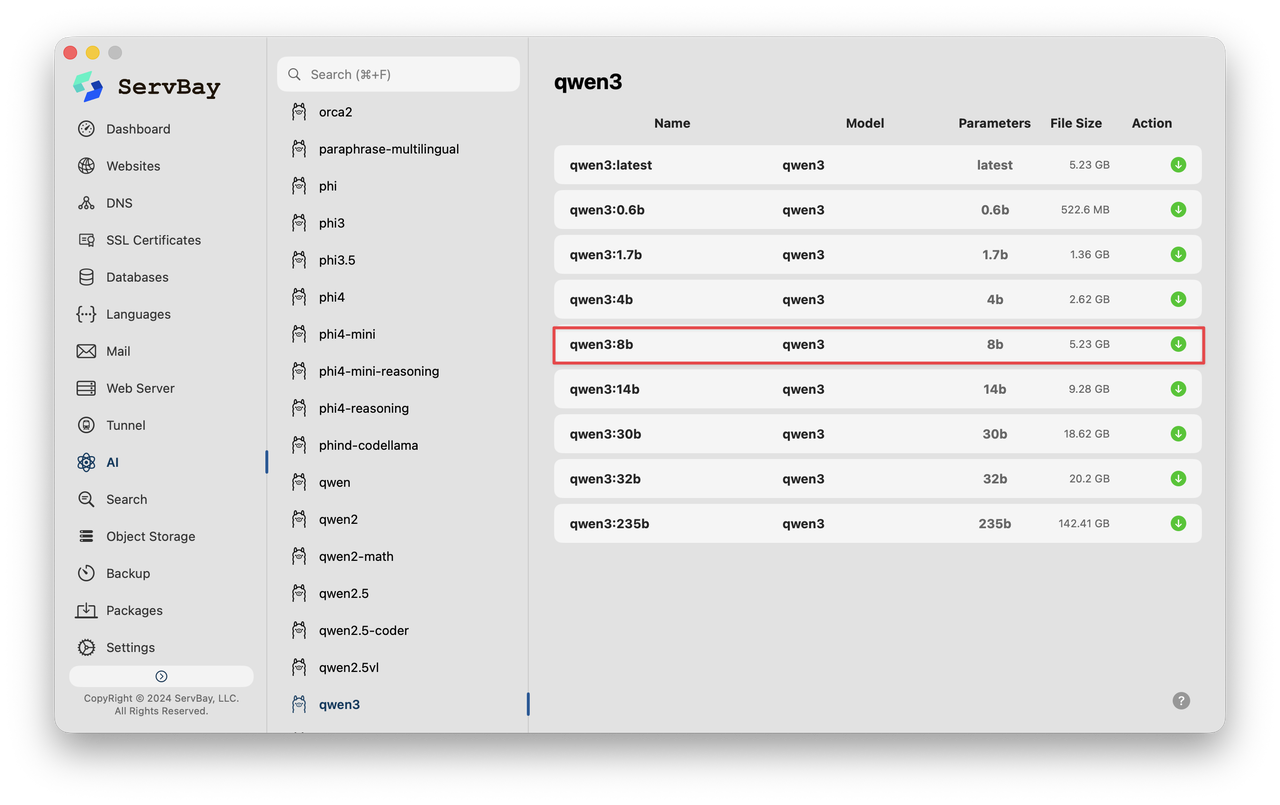
Hoặc, bạn có thể mở terminal của hệ thống và chạy lệnh sau để kéo (pull) tệp mô hình tương ứng và bắt đầu sử dụng.
# Tải xuống và chạy phiên bản 8B của mô hình Qwen 3
ollama pull qwen3:8b
Khi đã khởi chạy, hệ thống sẽ mở một dịch vụ HTTP trên cổng cục bộ 11434, tương thích với định dạng OpenAI. Tập lệnh Python dưới đây sẽ minh họa cách sử dụng SDK chính thức để kết nối với môi trường cục bộ nhằm mục đích thử nghiệm.
from openai import OpenAI
# Khởi tạo máy khách và trỏ nó tới giao diện Ollama cục bộ được lưu trữ bởi ServBay
local_client = OpenAI(
api_key="sk-servbay-local-test",
base_url="http://127.0.0.1:11434/v1"
)
# Xây dựng yêu cầu hội thoại
response = local_client.chat.completions.create(
model="qwen3:8b",
messages=[
{"role": "developer", "content": "Chỉ xuất code, không cần giải thích"},
{"role": "user", "content": "Vui lòng triển khai một mẫu Singleton đơn giản bằng Swift"}
],
temperature=0.1
)
print(response.choices[0].message.content)
Bằng cách sửa đổi địa chỉ API cơ sở trong các framework ứng dụng, các trợ lý lập trình AI hiện có (chẳng hạn như Cursor, Aider, v.v.) có thể kết nối liền mạch với thiết bị đầu cuối suy luận MLX cục bộ, qua đó hiện thực hóa tính năng hỗ trợ lập trình ngoại tuyến.
Thiết kế Kiến trúc: Khám phá các Giải pháp Lai giữa Cục bộ và Đám mây
Việc chỉ phụ thuộc hoàn toàn vào xử lý cục bộ hay chuyển dời tất cả lên đám mây đều không phải là những phương pháp kỹ thuật hiệu quả nhất. Vào năm 2026, các ứng dụng AI cấp độ thương mại phổ biến thường áp dụng kiến trúc phân bổ lai ba tầng (three-tier hybrid scheduling architecture), phân phối năng lực tính toán dựa trên độ phức tạp của tác vụ.
- Tầng 1: Lớp gốc thường trực với độ trễ cực thấp. Lớp này sử dụng Foundation Models tích hợp sẵn của Apple để xử lý mọi yêu cầu cơ bản. Vì mô hình 3B này được tích hợp sâu vào hệ thống, các nhà phát triển có thể sử dụng macro
@Generabletrong Swift để trực tiếp lấy dữ liệu cấu trúc hóa an toàn về kiểu (type-safe). Lớp này hoàn toàn miễn phí, không tiêu tốn thêm dung lượng cài đặt và cực kỳ hoàn hảo cho việc phân luồng định tuyến thường xuyên, kiểm tra trạng thái và tóm tắt văn bản ngắn. - Tầng 2: Lớp tải nặng cục bộ theo yêu cầu. Khi một ứng dụng gặp phải suy luận nhiều bước, sáng tạo nội dung dài hoặc phân tích logic phức tạp, hệ thống sẽ đánh thức một mô hình mã nguồn mở (như mô hình cấp Qwen 3 8B) đang thường trực trong bộ nhớ. Phần này đảm nhận phần lớn các phép tính logic kinh doanh cốt lõi và hoàn toàn không phụ thuộc vào bất kỳ mạng bên ngoài nào.
- Tầng 3: Cơ chế dự phòng LLM trên Đám mây. Chỉ khi gặp phải các tác vụ có độ khó cực cao mà phần cứng cục bộ không thể vượt qua, ứng dụng — sau khi được người dùng cấp quyền rõ ràng — mới khởi tạo các lệnh gọi API tới Claude Opus 4.7 hoặc GPT-5.5. Thiết kế lai giữa đám mây và cục bộ này đảm bảo quá trình hoạt động không tốn phí cho nhu cầu sử dụng hàng ngày, đồng thời phân bổ tài nguyên đám mây đắt đỏ cho những kịch bản mang lại tỷ suất hoàn vốn (ROI) cao nhất.
Về mặt xử lý giọng nói, WhisperKit (chạy trên Neural Engine) và FluidAudio mã nguồn mở của NVIDIA đã thay thế hoàn toàn các phương pháp phiên âm bằng tập lệnh Python truyền thống. FluidAudio đã giảm thời gian suy luận đơn lẻ cho khối lượng lớn âm thanh tiếng Anh xuống chỉ còn 0.19 giây, cho phép chuyển đổi hàng loạt văn bản với tính đồng thời cực cao ngay trên thiết bị cục bộ.
Triển khai AI Cục bộ Ưu tiên Quyền riêng tư
Trên tất cả các ngành công nghiệp, các yêu cầu tuân thủ đối với việc truyền dữ liệu xuyên biên giới và lưu trữ đám mây đã trở nên nghiêm ngặt chưa từng thấy. Các tổ chức y tế, công ty luật và công ty công nghệ tài chính gần như đã loại trừ hoàn toàn khả năng gửi dữ liệu nhạy cảm dạng thô của người dùng cho các nhà cung cấp LLM bên thứ ba.
Thúc đẩy triển khai AI cục bộ ưu tiên quyền riêng tư là giải pháp hữu hiệu để giải quyết những trở ngại về tuân thủ trong hoạt động kinh doanh. Kiến trúc lai ba tầng đề cập ở trên mặc định chặn phần lớn luồng dữ liệu ngay bên trong thiết bị vật lý của người dùng. Ngay cả khi không có Wi-Fi hoặc ở trong môi trường mạng khắc nghiệt, logic cốt lõi của ứng dụng vẫn có thể duy trì hoạt động.
Sau khoản đầu tư phần cứng ban đầu, chi phí biên cho một lần gọi API sẽ giảm xuống mức 0, mang lại kỳ vọng tài chính có khả năng kiểm soát cao và sức mạnh chống chịu rủi ro vững chắc cho các sản phẩm phần mềm. Do không có độ trễ truyền dữ liệu mạng qua lại, Thời gian xuất hiện Token đầu tiên (Time to First Token - TTFT) của các dịch vụ cục bộ thường vượt trội so với hầu hết các nút đám mây thương mại.
Sau nhiều năm lặp lại các công nghệ trong hệ sinh thái phần mềm AI cục bộ, cả khả năng tích hợp framework lẫn chất lượng mô hình đều đã đạt tiêu chuẩn sản xuất. Hiểu rõ cấu hình phần cứng cơ sở của đối tượng mục tiêu, từ bỏ việc lượng tử hóa quá mức và sự theo đuổi mù quáng đối với các mô hình đám mây, đồng thời chọn đúng môi trường thực thi phù hợp, chính là những hướng đi hợp lý và bền vững nhất để xây dựng các sản phẩm AI gốc (native AI) vào lúc này.
All rights reserved
