Paper reading | ShuffleNet: An Extremely Efficient Convolutional Neural Network for Mobile Devices
Bài đăng này đã không được cập nhật trong 2 năm
Đóng góp của bài báo
Việc thiết kế những model nhỏ, nhẹ, chính xác để có thể tích hợp trên các thiết bị di động luôn là bài toán hay thách thức những người thiết kế model AI  Bài báo giới thiệu model ShuffleNet là một mô hình CNN nhẹ được thiết kế cho thiết bị di động có sức mạnh tính toán 10-150 MFLOPS. Nếu như bạn chưa biết thi MFLOPS là viết tắt của "Millions of Floating-point Operations Per Second" (Tốc độ thực hiện triệu phép tính số học dấu phẩy động mỗi giây). Đây là một đơn vị đo hiệu năng tính toán của một hệ thống máy tính. Nó đo lường khả năng thực hiện các phép tính số học dấu phẩy động (floating-point arithmetic) mỗi giây, bao gồm các phép tính như cộng, trừ, nhân, chia, căn bậc hai, lũy thừa, và các phép tính hàm số phức tạp khác. MFLOPS thường được sử dụng để đánh giá hiệu năng của các thiết bị tính toán như máy tính cá nhân, máy chủ, các thiết bị điện tử và các hệ thống tương tự. Nó là một chỉ số quan trọng để đo lường khả năng xử lý số học của hệ thống và cung cấp thông tin về tốc độ xử lý của hệ thống.
Bài báo giới thiệu model ShuffleNet là một mô hình CNN nhẹ được thiết kế cho thiết bị di động có sức mạnh tính toán 10-150 MFLOPS. Nếu như bạn chưa biết thi MFLOPS là viết tắt của "Millions of Floating-point Operations Per Second" (Tốc độ thực hiện triệu phép tính số học dấu phẩy động mỗi giây). Đây là một đơn vị đo hiệu năng tính toán của một hệ thống máy tính. Nó đo lường khả năng thực hiện các phép tính số học dấu phẩy động (floating-point arithmetic) mỗi giây, bao gồm các phép tính như cộng, trừ, nhân, chia, căn bậc hai, lũy thừa, và các phép tính hàm số phức tạp khác. MFLOPS thường được sử dụng để đánh giá hiệu năng của các thiết bị tính toán như máy tính cá nhân, máy chủ, các thiết bị điện tử và các hệ thống tương tự. Nó là một chỉ số quan trọng để đo lường khả năng xử lý số học của hệ thống và cung cấp thông tin về tốc độ xử lý của hệ thống.
ShuffleNet sử dụng pointwise group convolution và channel shuffle để giảm chi phí tính toán trong khi vẫn duy trì độ chính xác. Mô hình có hiệu suất vượt MobileNet và đạt được tốc độ thực tế gấp ~13 lần so với AlexNet trong khi vẫn duy trì độ chính xác tương đương.
Phương pháp
Channel Shuffle for Group Convolutions
Các model SOTA như Xception và ResNeXT sử dụng depthwise separable convolution hoặc group convolution vào việc xây dựng các block và đạt được sự cân bằng giữa việc đánh đổi khả năng biểu diễn và chi phí tính toán. Tuy nhiên, cách thiết kế này không hoàn toàn sử dụng convolution (hay còn gọi là pointwise convolutions) để thực hiện tính toán. Ví dụ, trong ResNeXt chỉ có các layer sử dụng group convolution. Trong các mô hình nhỏ, việc sử dụng nhiều các pointwise convolution có thể hạn chế số channel từ đó đạt được độ phức tạp hằng số nhưng cách này có thể làm độ chính xác giảm đáng kể.
Để giải quyết vấn đề trên, một cách tự nhiên là ta sẽ áp dụng các kết nối channel thưa (channel sparse connections).
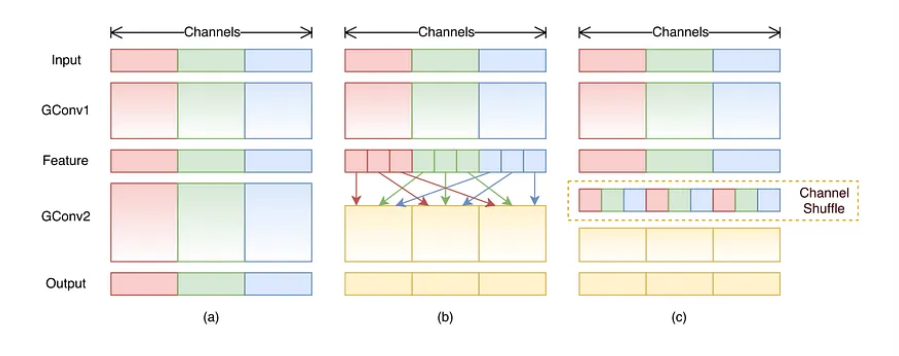
Bằng cách cho mỗi convolution thực hiện tính toán chỉ trên input channel group tương ứng, group convolution có thể giảm đáng kể chi phí tính toán. Tuy nhiên nếu nếu các group convolution stack lên nhau thì sẽ có tác dụng phụ , đó là: output của mỗi channel nhất định chỉ được lấy từ một phần nhỏ của input channel. Ví dụ như trong hình trên phần (a) ta có 2 group convolution layer stack lên nhau. Dễ thấy rằng, output của group nhất định chỉ liên quan tới input trong group và điều này chặn luồng thông tin giữa các channel, từ đó làm cho việc học biểu diễn trở nên kém hiệu quả.
Nếu như ta cho phép group convolution có thể nhận input data từ các group khác nhau như trong hình trên phần (b) thì các input và output channel sẽ hoàn toàn liên quan tới nhau. Cụ thể, với các feature map được tạo từ group layer trước, các channel sẽ được chia thành các group con trong mỗi group lớn sau đó mỗi group con sẽ truyền vào layer tiếp theo. Ý tưởng này có thể cài đặt một cách hiệu quả hơn bằng cách sử dụng channel shuffle (như hình (c)) như sau: Giả sử ta có một convolution layer với group và tổng số output channel của group này là channel. Đầu tiên, ta sẽ reshape chiều output channel thành , thực hiện transpose và flatten và tiếp tục làm input cho layer sau. Cách làm này vẫn okay với 2 convolution có số group khác nhau. Ngoài ra, channel shuffle cũng khả vi, điều này có nghĩa là ta có thể nhúng vào model để thực hiện train từ đầu tới cuối.
ShuffleNet Unit
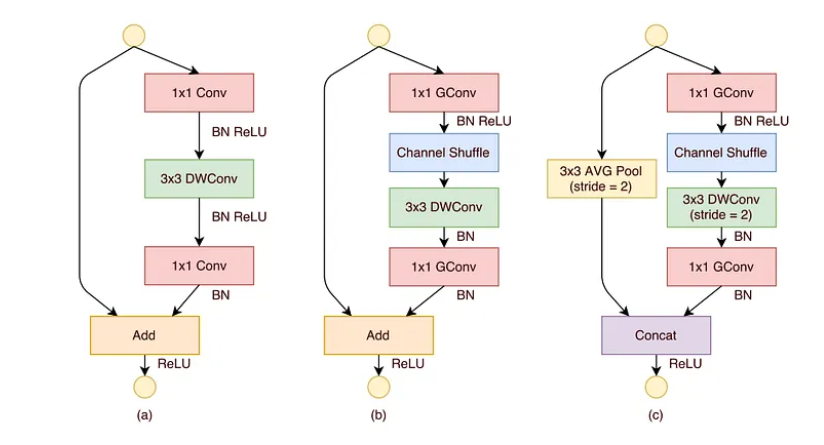
Hình trên thể hiện so sánh giữa 3 cấu hình khác nhau:
- Với hình (a) là một bottleneck unit với depthwise convolution ( DWConv).
- Hình (b) là ShuffleNet unit với pointwise group convolution và channel shuffle. Mục đích của pointwise group convolution là khôi phục kích thước channel để khớp với skip connection.
- Hình (c) là ShuffleNet unit với stride là 2.
Việc sử dụng pointwise group convolution với channel shuffle làm cho tất cả các thành phần trong ShuffleNet unit được tính toán hiệu quả hơn.
Kiến trúc mạng
Kiến trúc tổng quan ShuffleNet được trình bày trong bảng dưới. mô hình bao gồm một stack các ShuffleNet unit được nhóm thành ba giai đoạn. Trong bảng dưới, số group kiểm soát độ thưa thớt của các pointwise convolution. Đồng thời, được gán cho các số khác nhau, do đó các output channel có thể được tính toán và đánh giá để đảm bảo tổng chi phí tính toán xấp xỉ như nhau (~140 MFLOP).
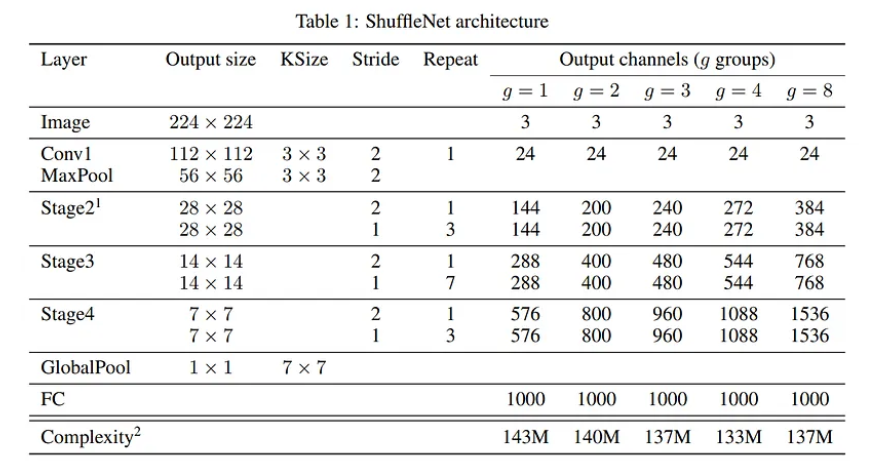
Mô hình có thể được tùy chỉnh tự do theo độ phức tạp mong muốn. Để thực hiện điều này, ta chỉ cần áp dụng hệ số tỷ lệ trên số lượng kênh. Ví dụ: nếu các model được biểu thị trong bảng trên là “ShuffleNet ”, thì “ShuffleNet ” có nghĩa tăng số lượng filter trong ShuffleNet lên lần, do đó độ phức tạp tổng thể sẽ bằng xấp xỉ của ShuffleNet .
Coding
Block Shufflenet:
import torch
import torch.nn as nn
import torch.nn.functional as F
class ShuffleV1Block(nn.Module):
def __init__(self, inp, oup, *, group, first_group, mid_channels, ksize, stride):
super(ShuffleV1Block, self).__init__()
self.stride = stride
assert stride in [1, 2]
self.mid_channels = mid_channels
self.ksize = ksize
pad = ksize // 2
self.pad = pad
self.inp = inp
self.group = group
if stride == 2:
outputs = oup - inp
else:
outputs = oup
branch_main_1 = [
# pw
nn.Conv2d(inp, mid_channels, 1, 1, 0, groups=1 if first_group else group, bias=False),
nn.BatchNorm2d(mid_channels),
nn.ReLU(inplace=True),
# dw
nn.Conv2d(mid_channels, mid_channels, ksize, stride, pad, groups=mid_channels, bias=False),
nn.BatchNorm2d(mid_channels),
]
branch_main_2 = [
# pw-linear
nn.Conv2d(mid_channels, outputs, 1, 1, 0, groups=group, bias=False),
nn.BatchNorm2d(outputs),
]
self.branch_main_1 = nn.Sequential(*branch_main_1)
self.branch_main_2 = nn.Sequential(*branch_main_2)
if stride == 2:
self.branch_proj = nn.AvgPool2d(kernel_size=3, stride=2, padding=1)
def forward(self, old_x):
x = old_x
x_proj = old_x
x = self.branch_main_1(x)
if self.group > 1:
x = self.channel_shuffle(x)
x = self.branch_main_2(x)
if self.stride == 1:
return F.relu(x + x_proj)
elif self.stride == 2:
return torch.cat((self.branch_proj(x_proj), F.relu(x)), 1)
def channel_shuffle(self, x):
batchsize, num_channels, height, width = x.data.size()
assert num_channels % self.group == 0
group_channels = num_channels // self.group
x = x.reshape(batchsize, group_channels, self.group, height, width)
x = x.permute(0, 2, 1, 3, 4)
x = x.reshape(batchsize, num_channels, height, width)
return x
Kiến trúc mạng:
import torch
import torch.nn as nn
from blocks import ShuffleV1Block
class ShuffleNetV1(nn.Module):
def __init__(self, input_size=224, n_class=1000, model_size='2.0x', group=None):
super(ShuffleNetV1, self).__init__()
print('model size is ', model_size)
assert group is not None
self.stage_repeats = [4, 8, 4]
self.model_size = model_size
if group == 3:
if model_size == '0.5x':
self.stage_out_channels = [-1, 12, 120, 240, 480]
elif model_size == '1.0x':
self.stage_out_channels = [-1, 24, 240, 480, 960]
elif model_size == '1.5x':
self.stage_out_channels = [-1, 24, 360, 720, 1440]
elif model_size == '2.0x':
self.stage_out_channels = [-1, 48, 480, 960, 1920]
else:
raise NotImplementedError
elif group == 8:
if model_size == '0.5x':
self.stage_out_channels = [-1, 16, 192, 384, 768]
elif model_size == '1.0x':
self.stage_out_channels = [-1, 24, 384, 768, 1536]
elif model_size == '1.5x':
self.stage_out_channels = [-1, 24, 576, 1152, 2304]
elif model_size == '2.0x':
self.stage_out_channels = [-1, 48, 768, 1536, 3072]
else:
raise NotImplementedError
# building first layer
input_channel = self.stage_out_channels[1]
self.first_conv = nn.Sequential(
nn.Conv2d(3, input_channel, 3, 2, 1, bias=False),
nn.BatchNorm2d(input_channel),
nn.ReLU(inplace=True),
)
self.maxpool = nn.MaxPool2d(kernel_size=3, stride=2, padding=1)
self.features = []
for idxstage in range(len(self.stage_repeats)):
numrepeat = self.stage_repeats[idxstage]
output_channel = self.stage_out_channels[idxstage+2]
for i in range(numrepeat):
stride = 2 if i == 0 else 1
first_group = idxstage == 0 and i == 0
self.features.append(ShuffleV1Block(input_channel, output_channel,
group=group, first_group=first_group,
mid_channels=output_channel // 4, ksize=3, stride=stride))
input_channel = output_channel
self.features = nn.Sequential(*self.features)
self.globalpool = nn.AvgPool2d(7)
self.classifier = nn.Sequential(nn.Linear(self.stage_out_channels[-1], n_class, bias=False))
self._initialize_weights()
def forward(self, x):
x = self.first_conv(x)
x = self.maxpool(x)
x = self.features(x)
x = self.globalpool(x)
x = x.contiguous().view(-1, self.stage_out_channels[-1])
x = self.classifier(x)
return x
def _initialize_weights(self):
for name, m in self.named_modules():
if isinstance(m, nn.Conv2d):
if 'first' in name:
nn.init.normal_(m.weight, 0, 0.01)
else:
nn.init.normal_(m.weight, 0, 1.0 / m.weight.shape[1])
if m.bias is not None:
nn.init.constant_(m.bias, 0)
elif isinstance(m, nn.BatchNorm2d):
nn.init.constant_(m.weight, 1)
if m.bias is not None:
nn.init.constant_(m.bias, 0.0001)
nn.init.constant_(m.running_mean, 0)
elif isinstance(m, nn.BatchNorm1d):
nn.init.constant_(m.weight, 1)
if m.bias is not None:
nn.init.constant_(m.bias, 0.0001)
nn.init.constant_(m.running_mean, 0)
elif isinstance(m, nn.Linear):
nn.init.normal_(m.weight, 0, 0.01)
if m.bias is not None:
nn.init.constant_(m.bias, 0)
if __name__ == "__main__":
model = ShuffleNetV1(group=3)
# print(model)
test_data = torch.rand(5, 3, 224, 224)
test_outputs = model(test_data)
print(test_outputs.size())
Thực nghiệm
Phụ lục
Bản chất của ShuffleNet là sử dụng pointwise group convolution và channel shuffle. Trong các phần dưới đây sẽ nghiên cứu mức độ ảnh hưởng của 2 thành phần này lên hiệu suất mô hình.
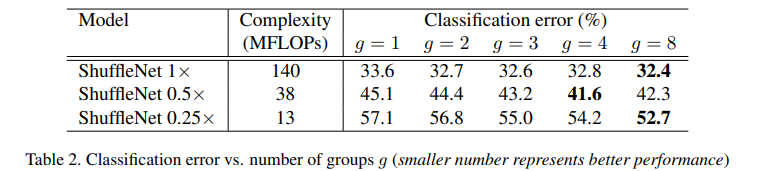
Sự quan trọng của Pointwise Group Convolutions
Bảng dưới so sánh các kết quả của các model ShuffleNet với cùng độ phức tạp, trong đó số group từ 1 tới 8.
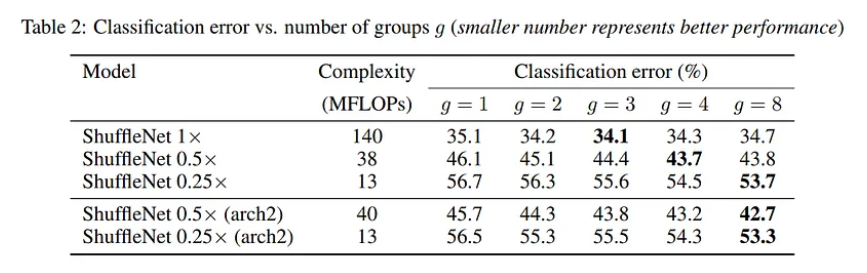
Channel Shuffle với No Shuffle
Bảng dưới so sánh kết quả giữa việc sử dụng và không sử dụng Channel Shuffle.
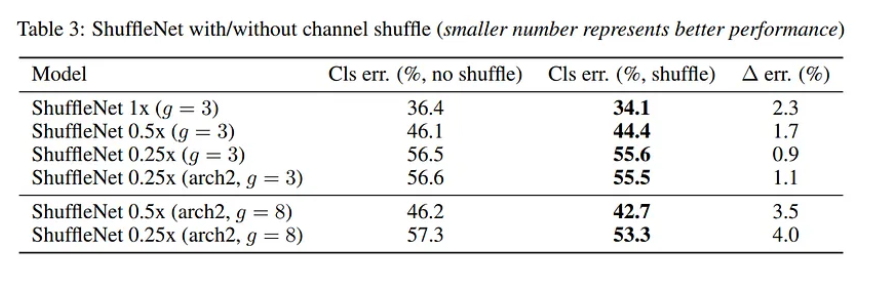
So sánh với các Structure Unit khác
Bảng dưới tổng kết các kết quả với cùng training setting trên các model khác nhau.
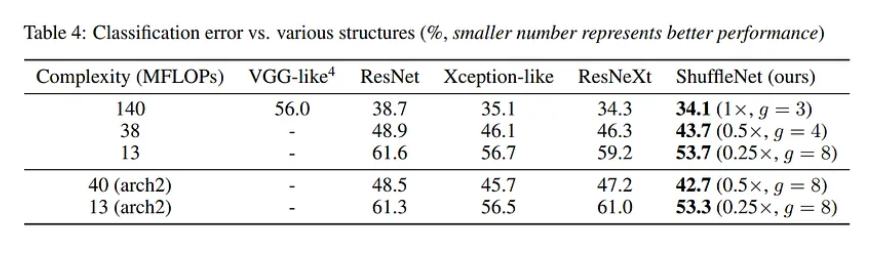
So sánh với MobileNet và các framework khác
Bảng dưới thống kê classification scores của model với các độ phức tạp khác nhau
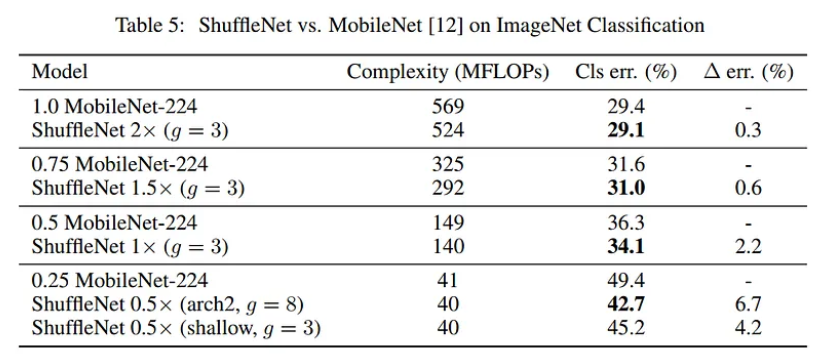
Với cùng accuracy nhưng độ phức tạp của ShuffleNet thấp hơn
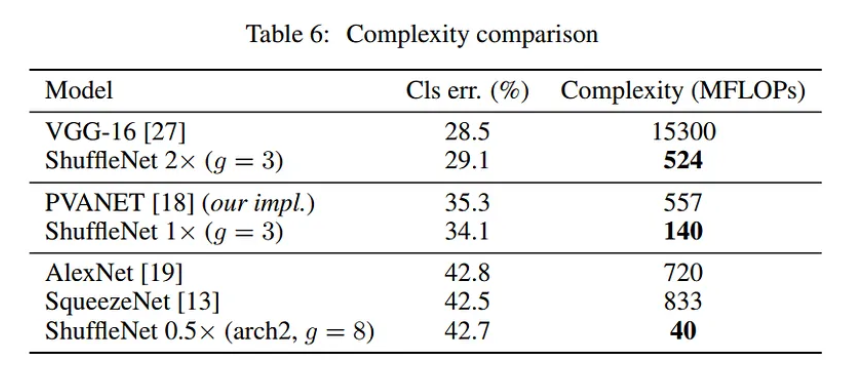
Khả năng tổng quát hóa
Bảng dưới cho thấy rằng ShuffleNet tốt hơn MobileNet trên cả 2 resolution.

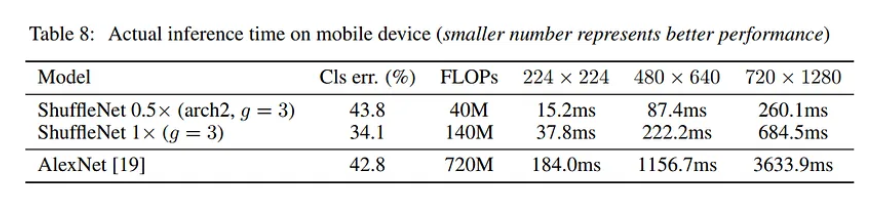
Đánh giá khả năng tăng tốc thực tế
Tốc độ inference của ShuffleNet trên thiết bị di động nhanh hơn rất nhiều so với AlexNet.
Tham khảo
[1] ShuffleNet: An Extremely Efficient Convolutional Neural Network for Mobile Devices
All rights reserved
