Paper reading | Scaling Language-Image Pre-training via Masking
Bài đăng này đã không được cập nhật trong 2 năm
Động lực và đóng góp
Các model Language-supervised visual pre-training điển hình như CLIP thể hiện được sự mạnh mẽ trong việc học các biểu diễn chung giữa hình ảnh và ngôn ngữ tự nhiên. Mặt khác, CLIP cũng tận dụng được việc sử dụng các pretrained encoder, điều này này cải thiện đáng kể hiệu suất cho các task multimodel và cả unimodel.
Tuy nhiên, do sự phức tạp của việc training multimodel hình ảnh và ngôn ngữ, đặc biệt nếu thực hiện training từ đầu, ta phải cần một lượng lớn dữ liệu được train trong nhiều giờ và tiêu tốn nhiều tài nguyên. Ví dụ như model CLIP gốc được train trên 400 triệu dữ liệu (image,text) trong 32 epoch, cần rất nhiều GPU khỏe. Ngay cả khi sử dụng cơ sở hạ tầng cao cấp, thời gian training vẫn là một nút cổ chai lớn cản trở việc thực hiện training.
Do đó, nhóm tác giả đề xuất một phương pháp có thể training CLIP hiệu quả hơn có tên Fast Language-Image Pre-training (FLIP) giúp tối ưu thời gian training và tài nguyên sử dụng. Ý tưởng cơ bản của phương pháp này là thực hiện xóa ngẫu nhiên một lượng lớn image patch trong quá trình training. Ý tưởng ở đây là sự đánh đổi giữa việc "sự cẩn thận khi xét 1 mẫu (image - text) nào đó" và "số mẫu ta có thể xử lý". Việc sử dụng masking cho ta một số lợi ích. Thứ nhất, vẫn cùng một thời gian training nhưng cho ta train được nhiều mẫu dữ liệu hơn (vì mỗi mẫu dữ liệu giống như việc ta nhìn lướt qua vậy  từ đó có thể nhìn được thêm nhiều mẫu khác). Thứ hai, vẫn cùng lượng memory footprint, ta có thể so sánh đối chiếu nhiều mẫu tại mỗi step hơn (tức là có thể sử dụng batch size lớn hơn).
từ đó có thể nhìn được thêm nhiều mẫu khác). Thứ hai, vẫn cùng lượng memory footprint, ta có thể so sánh đối chiếu nhiều mẫu tại mỗi step hơn (tức là có thể sử dụng batch size lớn hơn).
Quan sát hình dưới ta thấy rằng với thời gian training ít hơn nhưng ta vẫn thu được kết quả training tương tự, thậm chí còn tốt hơn so với phương pháp ban đầu của CLIP.
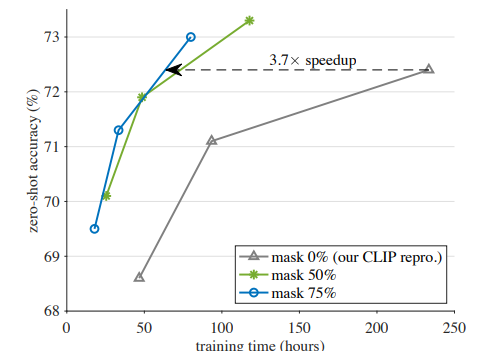
Nhóm tác giả nhận thấy rằng FLIP hiệu suất cạnh tranh so với CLIP tại nhiều downstream task. Đặc biệt, do việc training diễn ra nhanh hơn, ta có thể tính đến việc scale FLIP. Nhóm tác giả thực hiện nghiên cứu theo 3 hướng:
- Scale model size
- Scale dataset size
- Scale thời gian training
Nhóm tác giả quan sát việc scale model size và dataset có thể làm tăng độ chính xác mà không làm tăng training cost. Điều này là động lực cho việc nghiên cứu scale model vision-language trong tương lai.
Phương pháp
Nhóm tác giả đề xuất 4 ý tưởng chính trong FLIP.
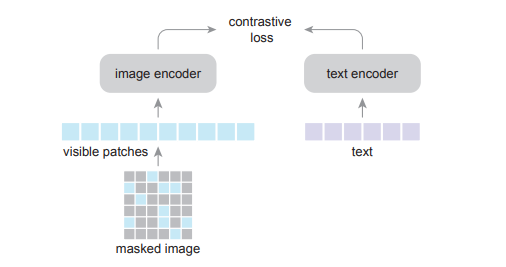
Đầu tiên là image masking. Như model CLIP, nhóm tác giả sử dụng model ViT làm image encoder. Image ban đầu cũng được chia thành các patch không overlap nhau. Sau đó, nhóm tác giả thực hiện mask các patch (với tỉ lệ 50%, 75%). Image encoder ViT chỉ được train trên các patch không bị mask. Việc sử dụng tỉ lệ mask là 50% hoặc 75% giảm độ phức tạp thời gian của image encoding đi 1/2 (hoặc 1/4) và đồng thời giúp tăng batch size lên gấp 2 hoặc 4 lần mà vẫn giữ nguyên cost tài nguyên sử dụng.
Tiếp theo là text masking. Bước này thì có hay không là tùy ý Cách thực hiện giống như image masking, ta cũng thực hiện mask các text token và sử dụng text encoder cho các text token không bị mask. Điều này khác với BERT là ta sẽ cho encoder học cả mask token. Với cách masking và chỉ học trên text token không bị che nên ta có thể giảm cost cho việc training text encoder. Tuy nhiên, việc training text encoder nhanh hơn (do giảm lượng token) có thể làm cho hiệu suất giảm.
Objective của bài toán này là tối thiểu hóa contrastive loss. Negative sample ở đây là các sample còn lại ở cùng batch. Số lượng negative sample lớn là rất cần thiết cho self-supervised contrastive learning trên ảnh.
Mặc dù encoder được pretrain trên các ảnh bị mask, nhưng nó có thể được train trực tiếp trên các ảnh nguyên vẹn mà không cần thay đổi. Để thu hẹp khoảng cách phân phối do masking, ta có thể đặt tỷ lệ masking là 0% và tiếp tục pretraining cho các step nhỏ đầu tiên. Chiến lược unmasking này làm tăng hiệu quả cho việc đánh đổi độ chính xác và thời gian training.
Thực nghiệm
Trong bảng dưới, nhóm tác giả thực hiện đánh giá tác động của các tham số lên hiệu suất mô hình.
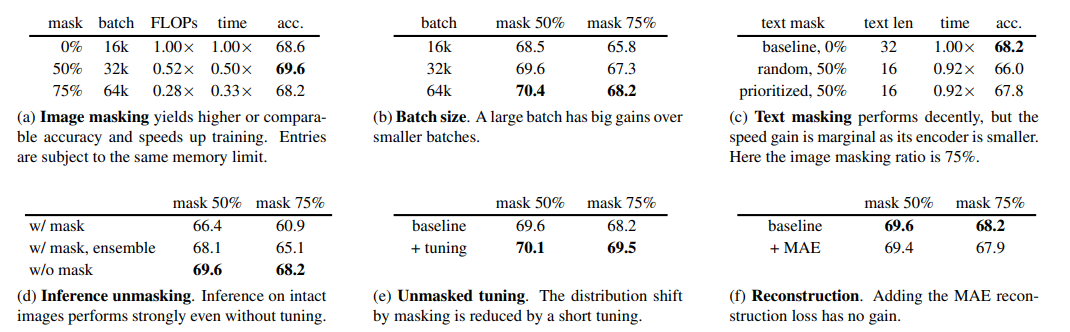
Zero-shot accuracy trên dataset ImageNet-1K, so với các baseline CLIP khác nhau. Kích thước ảnh là 224. Các mục được đánh dấu bằng màu xám được pretrain trên một tập dữ liệu khác. Các mô hình FLIP sử dụng batchsize 64.000, tỷ lệ masking 50% và sử dụng chiến lược unmasked tuning.
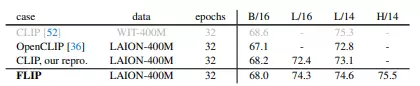
4 bảng dưới là so sánh kết quả mô hình với nhiều task và các bộ dữ liệu khác nhau




Cài đặt
Hàm random mask được nhóm tác giả implement sử framework JAX như sau:
def gather_by_einsum(x, ids):
"""
x: [N, L, ...]
ids: [N, K]
N: Số lượng mẫu trong batch
K: Số lượng các chỉ mục được lấy từ ids
L: Chiều dài của mỗi mẫu trong batch (trong trường hợp này, đây là chiều thứ hai của x).
"""
# Tạo một vector one hot có chiều [N, K, L]
mat = jax.nn.one_hot(ids, x.shape[1]) # [N, K, L]
# Khởi tạo giá trị x là tensor chứa giá trị của các phần tử được giữ lại sau khi masked
x = jnp.einsum("nl...,nkl->nk...", x, mat)
return x
def random_mask(rng, x, mask_ratio, bias=None):
"""
x: [N, L, C] input
bias: [N, L], an additional map to the noise map (small is keep, large is remove)
"""
# Khởi tạo giá trị N, L. Trong đó N là số lượng các mẫu trong batch và L là độ dài mỗi mẫu hay số lượng các vector trong mỗi mẫu
N, L, _ = x.shape # batch, length, dim
# Khởi tạo len_keep là số phần tử được giữ lại sau khi mask
len_keep = int(L * (1 - mask_ratio))
# Khởi tạo noise theo phân phối uniform có shape bằng N và L
noise = random.uniform(rng, shape=x.shape[:2])
# Thêm bias vào noise
if bias is not None:
noise += bias
# Khởi tạo biến ids_shuffle là tensor có giá trị là cần phần tử của noise được sắp xếp theo thứ tự tăng dần
ids_shuffle = jnp.argsort(noise, axis=1) # ascend: small is keep, large is remove
# Lưu lại chỉ số của các phần tử sau khi sắp xếp
ids_restore = jnp.argsort(ids_shuffle, axis=1)
# Giữ lại một số chỉ số bằng len_keep
ids_keep = ids_shuffle[:, :len_keep]
x_masked = gather_by_einsum(x, ids_keep)
x_masked = t5x.layers.with_sharding_constraint(
x_masked, ("batch", "length", "embed")
)
# generate the binary mask: 0 is keep, 1 is remove
# Khởi tạo numpy array có shape là N, L
mask = jnp.ones([N, L])
mask = t5x.layers.with_sharding_constraint(mask, ("batch", "length"))
# Set các giá trị tại axis = 1 có chỉ số nhỏ hơn len_keep bằng 0
mask = mask.at[:, :len_keep].set(0)
# Tạo binary mask
mask = gather_by_einsum(mask, ids_restore)
mask = t5x.layers.with_sharding_constraint(mask, ("batch", "length"))
return x_masked, mask, ids_restore
Tham khảo
[1] Learning Transferable Visual Models From Natural Language Supervision
All rights reserved
