[Paper reading] Rethinking Table Recognition using Graph Neural Networks
Abstract
Thành công gần đây của deep learning trong việc giải quyết các vấn đề về thị giác máy tính và học máy khác nhau không được thể hiện tốt trong phân tích cấu trúc tài liệu vì mạng nơ-ron thông thường không phù hợp với cấu trúc đầu vào của bài toán. Trong bài báo, nhóm tác giả đề xuất một cấu trúc dựa trên mạng đồ thị là một thay thế tốt hơn so với các mạng neural tiêu chuẩn cho table recognition. Nhóm tác giả chứng minh rằng graph net là một sự lựa chọn tự nhiên hơn cho bài toán này, và khám phá 2 gradient-base graph neural net. Kiến trúc được đề xuất kết hợp sức mạnh của CNN trong visual feature extraction và graph net cho giải quyết các bài toán liên quan tới cấu trúc. Nhóm tác giả cũng đóng góp bộ dataset lớn tổng hợp cho bài toán này.
Introduction
Các thông tin trong bảng được trình bày rất đa dạng về bố cục và ảnh đầu vào của chúng cũng rất đa dạng do góc chụp, chất lượng camera,...
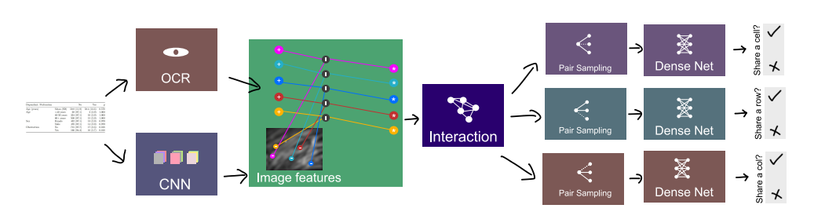
Ảnh bên dưới mô tả kiến trúc được đề xuất trong bài báo. Với ảnh tài liệu, một feature map được extract sử dụng CNN model và vị trí từ (words’ positions) được extract sử dụng OCR engine. Image feature tương ứng với vị trí từ được tổng hợp và concat với positional feature để tạo thành input feature. Một mạng tương tác (interation network) được áp dụng cho input feature để nhận representative feature. Đối với mỗi đỉnh (từ), việc lấy mẫu được thực hiện riêng lẻ để phân loại ô, hàng và cột. Các đặc trưng đại diện cho mọi cặp mẫu tiếp tục được concat lại và được sử dụng làm đầu vào cho dense net. Các dense net này khác nhau đối với việc chia sẻ hàng, cột và ô. Việc lấy mẫu chỉ được thực hiện trong quá trình đào tạo. Trong quá trình suy luận, mọi cặp đỉnh được phân loại.
Dataset
Có một số tập dataset cho bài toán này là UW3, UNLV và ICDAR 2013. Tuy nhiên, kích thước của những dataset này còn hạn chế dẫn đến việc overfiting trong quá trình training, không tổng quát cho mọi trường hợp. Nhóm tác giả cung cấp bộ dữ liệu gồm 0.5 triệu ảnh với nhãn là HTML. Mặc dù bộ dữ liệu tổng hợp này là không mới nhưng ta có thể dùng làm benchmark để nghiên cứu các thuật toán khác nhau.
Mô hình đồ thị
Xét một bài toán table recognition, ground truth được định nghĩa là 3 graph trong đó mỗi từ là một đỉnh. Có 3 ma trận kề đại diện cho mỗi đồ thị được đặt tên cell-, row-, và column-sharing. Vậy nếu 2 đỉnh chia sẻ 1 hàng tức là cả hai từ đều thuộc cùng một hàng, các đỉnh này được coi là liền kề với nhau (tương tự như vậy đối với chia sẻ ô và cột). Dự đoán của một mô hình cũng được thực hiện dưới dạng ba ma trận kề. Sau khi nhận được ma trận kề, các ô, hàng và cột hoàn chỉnh có thể được tạo lại bằng cách giải quyết vấn đề về maximal cliques cho các hàng và cột và các thành phần được kết nối cho các ô. Mô hình này không chỉ ổn cho bài toán table recognition mà còn có thể được sử dụng cho document segmentation. Trong trường hợp đó, nếu hai đỉnh (có thể là các từ) chia sẻ cùng một khu vực thì chúng liền kề nhau. Các vùng kết quả cũng có thể được tái tạo lại bằng cách sử dụng bài toán maximal clique.
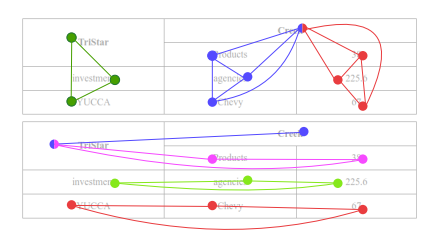
Trong hình trên mô tả việc reconstruct kết quả của việc phân đoạn hàng và côt sử dụng maximal clique. Bảng trên thể hiện column clique trong khi bảng dưới là row cliques.
Phương pháp

Thuật toán được mô tả trong mã giả ở hình trên. Đầu vào là ảnh trong đó , c là chiều cao, rộng và số kênh của ành, positional feature trong đó biểu diễn số đỉnh và feature khác Ngoài ra, input cũng cần thêm một số thông tin về số lượng mẫu trên một đỉnh và 3 ma trận kề . Tất cả parametric function được ký hiệu là và non-parametric function được ký hiệu là . Nểu tất cả parametric function khà vi thì toàn bộ architecture khà vi và do đó có thể thực hiện backpropagation.
Convolutional neural net: nhận ành là đầu vào và output là convolutional feature tương ứng và tương ứng là chiều rộng, cao và số kênh của conv feature map. Để lượng tham số thấp, nhóm tác giả thiết kế shallow , tuy nhiên, một số architecture tiêu chuẩn có thể được sử dụng. Tại output của CNN, một thao tác tồng hợp (gather operation ) được thực hiện đề collect conv feature cho mỗi từ tương ứng với vị trí không gian của chúng trong ành và tạo thành gathered feature .
Interaction: Sau khi tổng hợp tất cả feature đỉnh, chúng được đưa làm input cho interaction model. Nhóm tác già đã thử đề sử dụng làm interaction là và GravNet. Ngoài ra, nhóm tác giả cũng thử nghiệm dense net với xấp xỉ lượng tham số đề cho thấy rằng graph-based model thực hiện tốt hơn. Trong 3 model trên, nhóm tác giả giới hạn lượng tham số là để thực hiện so sánh được công bằng hơn.
Runtime pair sampling: Phân loại mọi cặp từ là một thao tác tốn nhiều bộ nhớ với độ phức tạp không gian là . Sau đó nó sẽ tăng tuyến tính theo batch size, bộ nhớ yêu cầu sẽ còn tăng nữa. Đề giài quyết vấn đề này, nhóm tác giả sử dụng phương pháp lấy mẫu Monte Carlo. Hàm lấy mẫu chỉ mục được ký hiệu là hàm này sẽ tạo ra một số lượng mẫu cố định cho mỗi đỉnh cho mỗi bài toán trong số ba bài toán (chia sè ô, chia sẻ hàng và chia sẻ cột). Uniform sampling có xu hướng bias đối với class 0 . Vì nhóm tác giả không thể sử dụng batch size lớn do hạn chế về bộ nhớ, nên số liệu thống kê không đủ đề phân biệt giữa hai lớp. Đề giải quyết vấn đề này, nhóm tác giả đã thay đồi phân phối lấy mẫu ( ) thành lấy mẫu trung bình, số lượng phần tử bằng nhau của lớp 0 và lớp 1 cho mỗi đỉnh. Các tập mẫu khác nhau được thu thập cho mỗi class (3 class) cho mỗi đỉnh . Giá trị của những ma trận này biều diện chỉ số của cặp mẫu cho mỗi đỉnh. Tuy nhiên, để infer, ta không cần lấy mẫu vì không cần sử dụng cách tiếp cận mini-batch. Do đó, ta chỉ cần đơn giản áp dụng cho mọi cặp đỉnh. Vì vậy trong quá trình training và trong suy luận .
Classification: Sau khi sampling, các phần tử từ output feature vector ( ) của interaction model và các phần từ từ samling matrices được concat với nhau trong và . Các hàm này là parametric neural net. Với output ta thu được bộ ba logits . Chúng có thể được sử dụng để tính loss và backpropagate qua các function hoặc đề dự đoán class và tạo ra ma trận kề kết quả.
Tài liệu tham khảo
[1] Rethinking Table Recognition using Graph Neural Networks
All rights reserved
