Paper reading | MOBILEVIT: LIGHT-WEIGHT, GENERAL-PURPOSE, AND MOBILE-FRIENDLY VISION TRANSFORMER
Bài đăng này đã không được cập nhật trong 3 năm
Giới thiệu chung
Các mô hình CNN đạt được kết quả SOTA trong các task về mobile vision. Spatial inductive bias cho phép những mô hình này học với ít tham số hơn với các task Computer Vision khác nhau. Tuy nhiên, những mạng CNN có tính cục bộ về mặt không gian. Để có thể học được global representations, self-attention based vision transformer được sử dụng. Tuy đạt được kết quả chính xác cao, nhưng những mô hình self-attention based vision transformer rất nhiều tham số. Vì vậy bài báo đã để xuất MobileViT, là một mô hình nhẹ, độ trễ thấp có thể sử dụng trên các thiết bị di động. Model này cho hiệu suất đáng kể so với CNN và ViT based network trên các task và dataset khác nhau. Ngoài ra, nhóm tác giả cũng để xuất MobileViT block encode cả 2 local và global representation trong một tensor một cách hiệu quả. Không như ViT và một số biến thể, MobileViT sử dụng một cách tiếp cận khác để học global representation. Một convolution chuẩn liên quan đến 3 phép toán: unfolding, local processing và folding. MobileViT block thay local processing trong convolution bằng global processing sử dụng transformer. Điều này cho phép MobileViT block có các thuộc tính giống CNN và ViT, giúp học representations tốt hơn với ít tham số hơn và các công thức training đơn giản (ví dụ: chỉ cần áp dụng các thao tác data augmentation cơ bản).
Motivation
Self-attention based model, cụ thể là vision transformers là một sự lựa chọn thay thế với CNN cho việc học visual representation. Xu hướng chung là ta sẽ tăng lượng tham số trong ViT để tăng độ chính xác. Việc này, dẫn đến vấn đề về kích thước model và độ trễ -> không phù hợp khi chạy trên các thiết bị di động hay sử dụng trong các task có yêu cầu realtime. Ta có thể giảm size của model ViT nhưng với lượng tham số tương tự, ViT lại cho kết quả tệ hơn rất nhiều so với CNN.
Ngoài ra, ViT cũng có một số hạn chế khác như khó optimize, cần data augmentation nhiều, L2 regularization để hạn chế overfitting và yêu cầu một expensive decoder cho các tác vụ downstream. Nhu cầu có nhiều tham số hơn trong các mô hình dựa trên ViT có thể là do chúng thiếu inductive bias hình ảnh cụ thể, vốn có trong CNN. Để tận dụng thế mạnh của convolutional và transformer, nhiều hybrid model kết hợp 2 thành phần này được hình thành. Tuy nhiên, model vẫn heavy weight và sensitive với data augmentation (ví dụ, việc bỏ CutMix và DEiT style làm cho accuracy giảm 78.1% xuống 72.4%).
Một điều nữa cần chú ý là việc giảm FLOPS là không đủ cho yêu cầu về độ trễ thấp, lý do là FLOP bỏ qua một số yếu tố liên quan đến inferences quan trọng như truy cập bộ nhớ, mức độ tính toán song song và đặc điểm nền tảng. Ví dụ, ViT-based method như PiT có FLOPS ít hơn gấp 3 lần sao với DEiT nhưng lại có tốc độ inference như nhau trên thiết bị di động, DeIT với PiT trên iPhone-12: 10.99 ms và 10.56 ms. Do vậy, việc optimize FLOPS là không cần thiết.
-> Cần có model ViT ngon nhưng phải nhẹ để đáp ứng yêu cầu khi chạy trên các thiết bị di động và task yêu cầu realtime. Model này cũng cần đảm bảo general - purpose để có thể ứng dụng trên nhiều task CV khác nhau.
MOBILEVIT: A LIGHT-WEIGHT TRANSFORMER
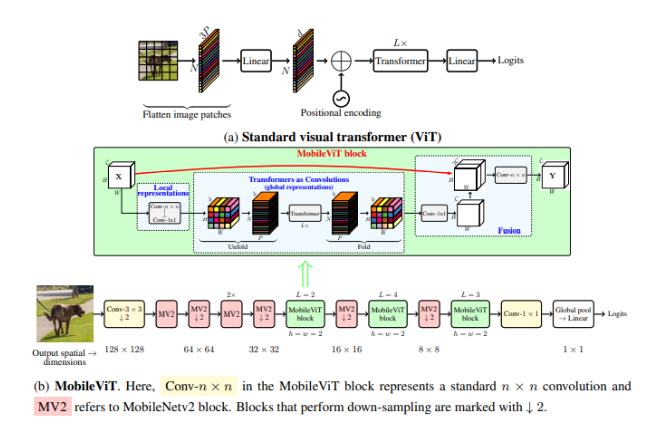
Một mô hình ViT tiêu chuẩn (show trong hình a), reshape input thành một chuỗi các patch , chiếu các patch vào một không gian d chiều cố định và sau đó thực hiện học mối quan hệ giữa các patch sử dụng L transformer block. Chi phí tính toán self-attention trong vision transformers là . Trong đó, là channels, height, width của tensor. là số pixel của patch và là số patch. Bài báo giới thiệu phiên bản lightweight ViT model, MobileVit. Ý tưởng chính là học global representation với transformer dưới dạng convolution.
MOBILEVIT Architecture
MobileViT block. Mục đích của block này là mô hình thông tin local và global trong một input tensor với ít tham số hơn. Cụ thể cho một input tensor , MobileViT ứng dụng lớp convolution theo sau là lớp point-wise convolution để có . Lớp convolution encode local spatial information trong khi point-wise convolution thực hiện thao tác chiếu tensor lên không gian nhiều chiều bằng cách học các kết hợp tuyển tính của các kênh đầu vào.
Với mobileViT, ta muốn mô hình long-range non-local dependencies trong khi vẫn có effective receptive field kích thước H x W. Một trong những phương pháp được nghiên cứu rộng rãi cho model long -range dependencies là dilated convolutions. Tuy nhiên, cách tiếp cận như vậy yêu cầu lựa chọn cẩn thận dilation rate.
Đê cho MobileVIT học được global representation với spatial inductive bias, nhóm tác giả unfold thành flatten patch không overlap . Trong đó, là số patch, và w là chiều rộng và chiều cao tương ứng của 1 patch. Với mỗi mối quan hệ giữa các patch được mã hóa bởi transformer để xác định như sau:
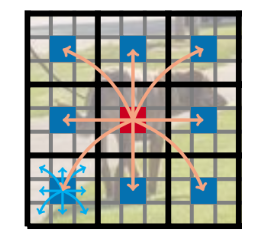
Không như ViTs làm mất thứ tự không gian của các pixel. MobileViT có điểm mạnh là vừa không làm mất thứ tự patch, vừa không làm mất thứ tự không gian của pixel trong mỗi patch. Vì vậy, ta có thể fold để xác định . Sau đó được chiếu đến không gian chiều thấp sử dụng point-wise convolution và được kết hợp với sử dụng feature này. Chú ý rằng, vì mã hóa thông tin local từ vùng sử dụng convolution và . mã hóa thông tin global qua patch cho p vị trí, mỗi pixel trong có thể mã hóa thông tin của toàn bộ pixel trong . Vi vậy, tổng quan ảnh hưởng receptive field của MobileVit là . Minh họa cho điều này ở trong hình dưới.
Mối quan hệ với convolution. Convolution tiêu chuẩn có thể được nhìn như là 1 stack của 3 chuỗi thao tác. (1) Unfolding, (2) nhân ma trận (để học biểu diễn local) và (3) folding. Khối MobileVit tương tự convolution theo nghĩa là nó cũng tận dụng các block tương tự. MobileViT thay thế local processing (matrix multiplication) trong convolution với global processing “”sâu hơn”” đó là một stack các transformer layer. Do đó, MobileViT có các thuộc tính giống như convolution (inductive bias). Do đó, MobileViT block có thể được xem như vừa là transformer vừa là convolution.
Light-weight. Tại sao MobileVit light-weight? Lý do nằm ở việc học biểu diễn global với Transformer. Trong các nghiên cứu trước đó, một patch sẽ được chuyển đổi spatial information sang latent bằng cách học tổ hợp tuyến tính các pixel. Global information sau đó được mã hóa bằng cách học thông tin giữa các patch sử dụng transformer. Kết quả là model như vậy mất đi tính inductive bias của CNN. Vì vậy, model yêu cầu nhiều tài nguyên để học visual representation. Model như vậy thương deep và wide. Với MobileViT có MobileViT block tận dụng 2 thuộc tính của conv và transformer => mô hình nhẹ hơn.
Computational cost. Computational cost của multi-headed self-attention trong MobileVit và ViTs tương ứng là và . Theo lý thuyết, MobileViT không hiệu quả khi so sánh với VíT. Tuy nhiên, trên thực tế, MobileViT hiệu quả hơn nhiều khi so sánh với VíT. MobileViT ít hơn 2 lần FLOPS và cho độ chính xác hơn 1.8% so với DeIT trên tập ImageNet - 1K.

Thực nghiệm
IMAGE CLASSIFICATION ON THE IMAGENET-1K DATASET
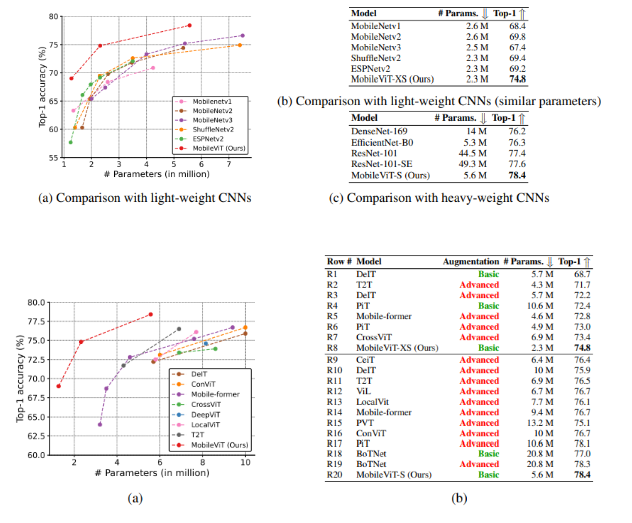
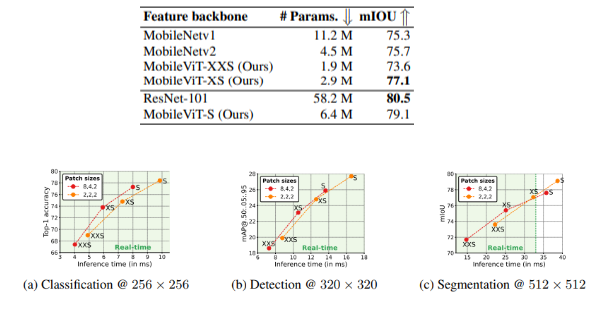
MOBILEVIT AS A GENERAL-PURPOSE BACKBONE
MOBILE OBJECT DETECTION
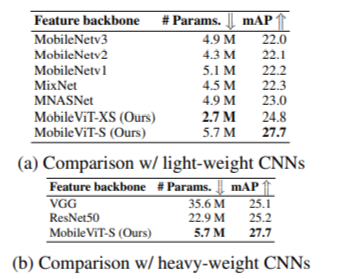
MOBILE SEMANTIC SEGMENTATION
Phụ lục
Impact of weight decay
Một model tốt nên insensitive hoặc ít sensitive với L2 regularization (hay weight decay) bởi vì tuning nó cho mỗi task và dataset là rất mất thời gian. Không như CNNs, ViT model sensitive với weight decay. Để nghiên cứu xem MobileViT có sensitive với weight decay hay không, nhóm tác giả đã train MobileViT-S với các giá trị weight decay khác nhau từ 0.1 đến 0.0001. Kết quả trong hình dưới.
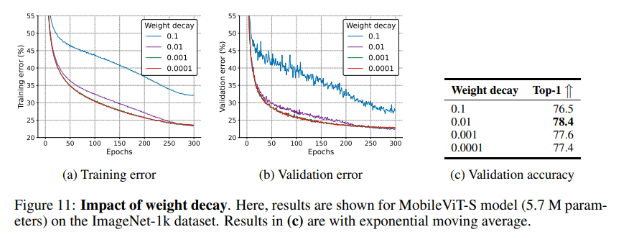
Ngoại trừ giá trị weight decay là 0.1 thì các giá trị khác đều hội tụ cho một kết quả giống nhau. Chú ý rằng 0.0001 là giá trị thường dùng trong các mạng CNN và ngay cả ở giá trị này, MobileViT vẫn tốt hơn CNNs trên tập ImageNet-1K.
Impact of skip-connection
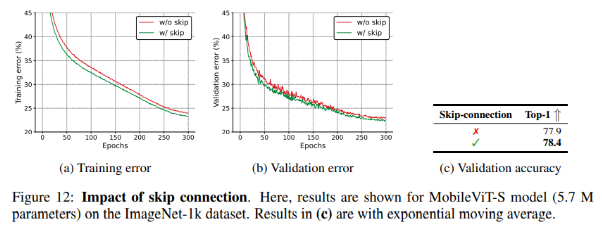
Với skip-connection, MobileViT-S cải thiện kết quả lên 0.5% trên ImageNet dataset. Kể cả khi không có skip-connection, MobileViT-S vẫn cho kết quả gần hay tốt hơn SOTA CNN và ViT-based model (cần nhiều data augmentation).
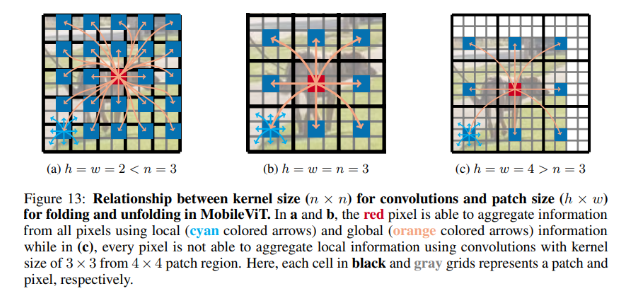
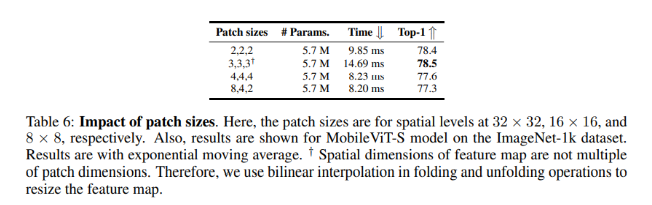
Impact of patch sizes
Vì conv được sử dụng trên vùng n x n và self-attention được tính qua các patch với chiều h và w, điều này là cần thiết để thiết lập mối quan hệ tốt giữa n, h và w.
Impact of exponential moving average and label smoothing
EMA và LS là hai phương pháp tiêu chuẩn được sử dụng để cải thiện hiệu suất CNN và Transformer-based model.
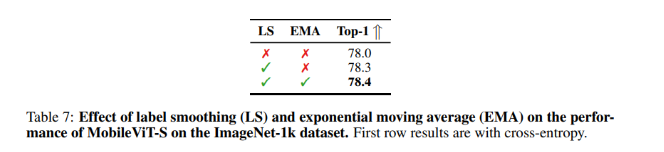
Bảng 7 cho thấy rằng LS cải thiện một chút hiệu suất của MobileViT-S trong khi EMA có ít hoặc không ảnh hưởng đến hiệu suất của mô hình trên tập dữ liệu ImageNet-1k. Bởi vì các nghiên cứu trước đây đã chỉ ra rằng các phương pháp này có hiệu quả trong việc giảm nhiễu ngẫu nhiên (stochastic noise) và ngăn mạng trở nên quá tự tin (over-confident).
Tài liệu tham khảo
- Why this one (literally) small model spells big things for Vision Transformers. | by Chris Ha | Medium
- Patch is all you need
- BEIT: BERT Pre-Training of Image Transformers
- DeepViT: Towards Deeper Vision Transformer
- AN IMAGE IS WORTH 16X16 WORDS: TRANSFORMERS FOR IMAGE RECOGNITION AT SCALE
- Going deeper with Image Transformers
- Visual Transformers: Token-based Image Representation and Processing for Computer Vision
- Zero-Shot Text-to-Image Generation
- ResT: An Efficient Transformer for Visual Recognition
- CvT: Introducing Convolutions to Vision Transformers
- ConViT: Improving Vision Transformers with Soft Convolutional Inductive Biases
- Escaping the Big Data Paradigm with Compact Transformers
- Towards Robust Vision Transformer
- PVTv2: Improved Baselines with Pyramid Vision Transformer
All rights reserved
