Paper reading | MaxViT: Multi-Axis Vision Transformer
Bài đăng này đã không được cập nhật trong 2 năm
Đóng góp của bài báo
Các mô hình ViT nếu như không pretrained trước đó sẽ có hiệu suất kém hơn so với các mô hình ConvNets. Lý do là các mô hình Transformer có model capacity cao với inductive bias thấp, điều này dẫn tới tình trạng overfitting. Bài toán đặt ra là làm như thế nào để kết hợp hiệu quả tương tác global và local trong mô hình Transformer với mục tiêu cân bằng model capacity và tính tổng quát hóa trong một lượng tài nguyên tính toán hợp lý.
Bài báo đề xuất một loại Transformer module mới có tên là multi-axis self-attention (Max-SA) có khả năng thực hiện đồng thời cả tương tác local và global (local and global spatial interactions) trong một block. Nếu so sánh với self-attention đầy đủ thì Max-SA linh hoạt và hiệu quả hơn (ví dụ như có thể áp dụng cho các input có độ dài khác nhau với độ phức tạp tuyến tính). Trái ngược với window attention hay local attention, Max-SA cho phép model capacity mạnh hơn bằng cách đề xuất một global receptive field. Ngoài ra, với độ phức tạp tuyến tính, Max-SA có thể được sử dụng như một module attention tổng quát tại bất kì layer nào trong mô hình, kể cả những layer ở stage đầu hay input với high resolution.
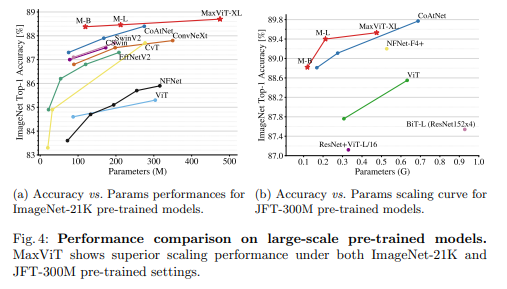
Bên cạnh đó, nhóm tác giả cũng thiết kế một backbone đơn giản mà hiệu quả có tên là Multi-axis Vision Transformer (MaxViT) bằng cách stack các block mà thành phần là Max-SA và các lớp convolution. Mô hình MaxViT cải thiện kết quả SOTA ở nhiều task liên quan tới hình ảnh. Tương quan giữa độ chính xác với FLOPs và lượng tham số giữa các mô hình được thể hiện trong 2 biểu đồ dưới:
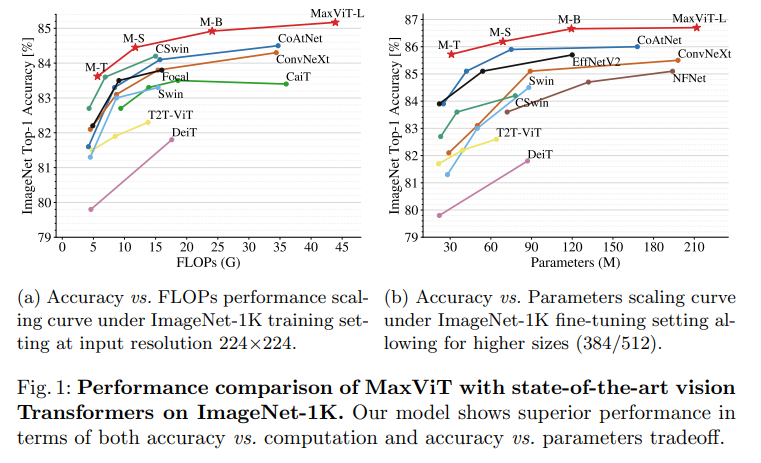
Phương pháp
Attention
Thành phần attention được sử dụng trong mô hình là Relative self-attention mà không phải self-attention tiêu chuẩn (được giới thiệu trong bài báo của mô hình ViT). Lý do là self-attention tiêu chuẩn không có thông tin về vị trí (location), chính vì vậy mà chúng không có tính chất translation equivariant, đây là một inductive bias quan trọng xuất hiện trong các mô hình ConvNet. Relative attention mà mô hình sử dụng có công thức như sau:
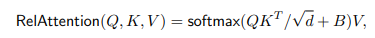
trong đó là ma trận query, key và value. là hidden dimension. Các trọng số attention được quyết định bởi một ma trận learnable location-aware có chứa thông tin về vị trí và input-adaptive attention . Relative attention có các ưu điểm là input-adaptivity, translation equivariance và global interaction.
Multi-axis Attention
Global interaction là một ưu điểm vượt trội của self-attention so với local convolution. Tuy nhiên, nếu áp dụng trực tiếp attention sẽ không khả thi do yêu cầu độ phức tạp bậc 2 với spatial size. Để giải quyết vấn đề này, nhóm tác giả đề xuất một cách tiếp cận multi-axis, mục tiêu là tách full-size attention thành 2 thành phần local và global bằng cách tách thành các chiều spatial khác nhau. Gọi là input feature map, thay vì sử dụng attention cho flattened spatial dimension , nhóm tác giả tạo một tensor có shape là . Tensor này đại diện cho các window không chồng nhau có kích thước là . Việc sử dụng self-attention cho các cửa số kích thước chính là tương đương với việc ta thực hiện local interaction, nhóm tác giả gọi đây là block attention.
Tuy khắc phục được vấn đề về tài nguyên tính toán của full self-attention nhưng local-attention lại gặp vấn đề là underfit trên các bộ dataset lớn. Đề giải quyết vấn đề này, nhóm tác giả đề xuất một ý tưởng có tên là grid attention. Thay vì chia feature map thành các window size cố định, nhóm tác giả thực hiện chia lưới (grid) tensor thành tensor có shape sử dụng grid, kết quả là ta có các window có kích thước là . Với việc sử dụng window size và grid size giống nhau (), ta có thể cân bằng tài nguyên cho các phép tính local và global (cả 2 đều có độ phức tạp tuyến tính với spatial size hoặc sequence length).
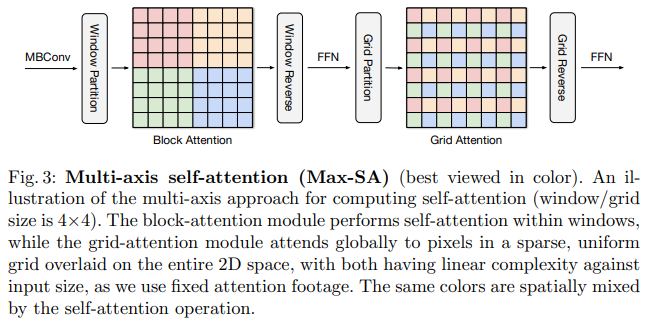
Bằng việc stack 2 loại attention để có cả local và global interaction, ta có MaxViT block (như trong hình trên). Trong MaxViT block vẫn có các thành phần giống Transformer như Feedforward networks (FFNs) và skip-connections. Bên cạnh đó, nhóm tác giả cũng sử dụng MBConv block với squeeze-and-excitation (SE) module để thực hiện multi-axis attention. Lý do là nhóm tác giả nhận thấy rằng việc sử dụng MBConv cùng với attention làm tăng khả năng tổng quát hóa và khả năng huấn luyện của mô hình. Việc sử dụng layer MBConv trước attention mang lại nhiều ưu điểm, depthwise convolution có thể được coi là một conditional position encoding (CPE), do đó ta không cần phải dùng một positional encoding layer rõ ràng nữa (như trong mô hình transformer tiêu chuẩn). Một điểm hay nữa là multi-axis attention có thể sử dụng cùng hoặc đứng riêng cho nhiều mục đích khác nhau: block attention cho local interaction và grid attention cho global mixing. Các thành phần này có thể tích hợp vào trong nhiều kiến trúc khác nhau, đặc biệt là trong các task high resolution để tận dụng ưu điểm là global interaction mà không sử dụng nhiều tài nguyên tính toán.
Các biến thể của kiến trúc
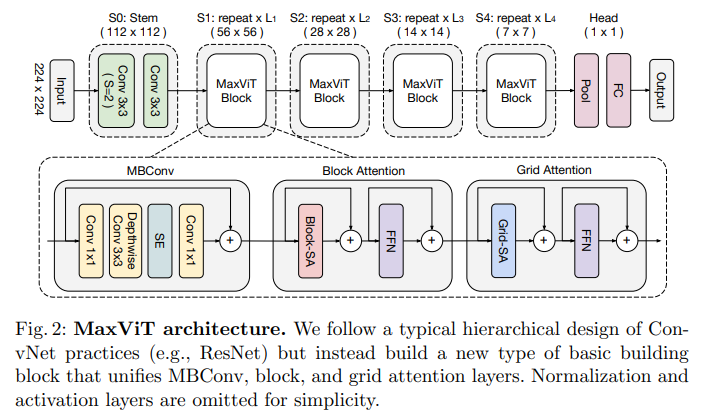
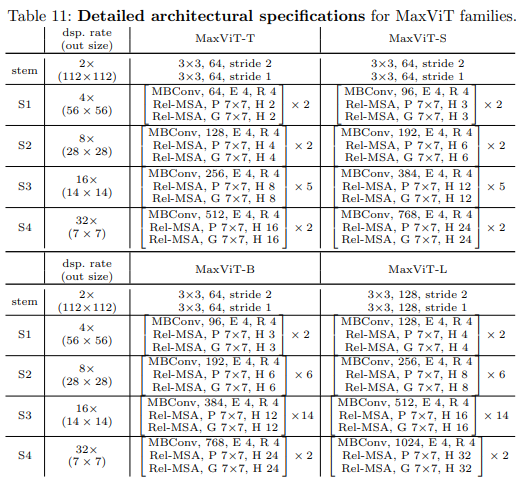
Kiến trúc tổng thể của MaxViT được thể hiện trong hình trên. Nhóm tác giả thiết kế một backbone có kiến trúc hierarchical. Input ban đầu được downsample sử dụng các layer Conv3x3 trong stem stage (S0). Phần thân của mô hình bao gồm 4 stage (S1-S4) với mỗi stage chứa một nửa resolution của stage trước đó và lượng channel (hidden dimension) được tăng gấp đôi. MaxViT block được sử dụng xuyên suốt trong mô hình. Tỉ lệ expansion và shrink cho inverted bottleneck và squeeze-excitation (SE) mặc định lần lượt là 4 và 0.25. Nhóm tác giả đặt attention head size là 32 cho tất cả attention block. Để thực hiện scale model, nhóm tác giả tăng số lượng block trên mỗi stage và channel dimension . Tổng hợp cấu hình của các biến thể MaxViT được thể hiện trong bảng dưới:

Coding
Code mô hình MaxViT tham khảo:
""" MaxViT
A PyTorch implementation of the paper: `MaxViT: Multi-Axis Vision Transformer`
- MaxViT: Multi-Axis Vision Transformer
"""
from typing import Type, Callable, Tuple, Optional, Set, List, Union
import torch
import torch.nn as nn
from timm.models.efficientnet_blocks import SqueezeExcite, DepthwiseSeparableConv
from timm.models.layers import drop_path, trunc_normal_, Mlp, DropPath
def _gelu_ignore_parameters(
*args,
**kwargs
) -> nn.Module:
""" Bad trick to ignore the inplace=True argument in the DepthwiseSeparableConv of Timm.
Args:
*args: Ignored.
**kwargs: Ignored.
Returns:
activation (nn.Module): GELU activation function.
"""
activation = nn.GELU()
return activation
class MBConv(nn.Module):
""" MBConv block as described in: https://arxiv.org/pdf/2204.01697.pdf.
Without downsampling:
x ← x + Proj(SE(DWConv(Conv(Norm(x)))))
With downsampling:
x ← Proj(Pool2D(x)) + Proj(SE(DWConv ↓(Conv(Norm(x))))).
Conv is a 1 X 1 convolution followed by a Batch Normalization layer and a GELU activation.
SE is the Squeeze-Excitation layer.
Proj is the shrink 1 X 1 convolution.
Note: This implementation differs slightly from the original MobileNet implementation!
Args:
in_channels (int): Number of input channels.
out_channels (int): Number of output channels.
downscale (bool, optional): If true downscale by a factor of two is performed. Default: False
act_layer (Type[nn.Module], optional): Type of activation layer to be utilized. Default: nn.GELU
norm_layer (Type[nn.Module], optional): Type of normalization layer to be utilized. Default: nn.BatchNorm2d
drop_path (float, optional): Dropout rate to be applied during training. Default 0.
"""
def __init__(
self,
in_channels: int,
out_channels: int,
downscale: bool = False,
act_layer: Type[nn.Module] = nn.GELU,
norm_layer: Type[nn.Module] = nn.BatchNorm2d,
drop_path: float = 0.,
) -> None:
""" Constructor method """
# Call super constructor
super(MBConv, self).__init__()
# Save parameter
self.drop_path_rate: float = drop_path
# Check parameters for downscaling
if not downscale:
assert in_channels == out_channels, "If downscaling is utilized input and output channels must be equal."
# Ignore inplace parameter if GELU is used
if act_layer == nn.GELU:
act_layer = _gelu_ignore_parameters
# Make main path
self.main_path = nn.Sequential(
norm_layer(in_channels),
nn.Conv2d(in_channels=in_channels, out_channels=in_channels, kernel_size=(1, 1)),
DepthwiseSeparableConv(in_chs=in_channels, out_chs=out_channels, stride=2 if downscale else 1,
act_layer=act_layer, norm_layer=norm_layer, drop_path_rate=drop_path),
SqueezeExcite(in_chs=out_channels, rd_ratio=0.25),
nn.Conv2d(in_channels=out_channels, out_channels=out_channels, kernel_size=(1, 1))
)
# Make skip path
self.skip_path = nn.Sequential(
nn.MaxPool2d(kernel_size=(2, 2), stride=(2, 2)),
nn.Conv2d(in_channels=in_channels, out_channels=out_channels, kernel_size=(1, 1))
) if downscale else nn.Identity()
def forward(
self,
input: torch.Tensor
) -> torch.Tensor:
""" Forward pass.
Args:
input (torch.Tensor): Input tensor of the shape [B, C_in, H, W].
Returns:
output (torch.Tensor): Output tensor of the shape [B, C_out, H (// 2), W (// 2)] (downscaling is optional).
"""
output = self.main_path(input)
if self.drop_path_rate > 0.:
output = drop_path(output, self.drop_path_rate, self.training)
output = output + self.skip_path(input)
return output
def window_partition(
input: torch.Tensor,
window_size: Tuple[int, int] = (7, 7)
) -> torch.Tensor:
""" Window partition function.
Args:
input (torch.Tensor): Input tensor of the shape [B, C, H, W].
window_size (Tuple[int, int], optional): Window size to be applied. Default (7, 7)
Returns:
windows (torch.Tensor): Unfolded input tensor of the shape [B * windows, window_size[0], window_size[1], C].
"""
# Get size of input
B, C, H, W = input.shape
# Unfold input
windows = input.view(B, C, H // window_size[0], window_size[0], W // window_size[1], window_size[1])
# Permute and reshape to [B * windows, window_size[0], window_size[1], channels]
windows = windows.permute(0, 2, 4, 3, 5, 1).contiguous().view(-1, window_size[0], window_size[1], C)
return windows
def window_reverse(
windows: torch.Tensor,
original_size: Tuple[int, int],
window_size: Tuple[int, int] = (7, 7)
) -> torch.Tensor:
""" Reverses the window partition.
Args:
windows (torch.Tensor): Window tensor of the shape [B * windows, window_size[0], window_size[1], C].
original_size (Tuple[int, int]): Original shape.
window_size (Tuple[int, int], optional): Window size which have been applied. Default (7, 7)
Returns:
output (torch.Tensor): Folded output tensor of the shape [B, C, original_size[0], original_size[1]].
"""
# Get height and width
H, W = original_size
# Compute original batch size
B = int(windows.shape[0] / (H * W / window_size[0] / window_size[1]))
# Fold grid tensor
output = windows.view(B, H // window_size[0], W // window_size[1], window_size[0], window_size[1], -1)
output = output.permute(0, 5, 1, 3, 2, 4).contiguous().view(B, -1, H, W)
return output
def grid_partition(
input: torch.Tensor,
grid_size: Tuple[int, int] = (7, 7)
) -> torch.Tensor:
""" Grid partition function.
Args:
input (torch.Tensor): Input tensor of the shape [B, C, H, W].
grid_size (Tuple[int, int], optional): Grid size to be applied. Default (7, 7)
Returns:
grid (torch.Tensor): Unfolded input tensor of the shape [B * grids, grid_size[0], grid_size[1], C].
"""
# Get size of input
B, C, H, W = input.shape
# Unfold input
grid = input.view(B, C, grid_size[0], H // grid_size[0], grid_size[1], W // grid_size[1])
# Permute and reshape [B * (H // grid_size[0]) * (W // grid_size[1]), grid_size[0], window_size[1], C]
grid = grid.permute(0, 3, 5, 2, 4, 1).contiguous().view(-1, grid_size[0], grid_size[1], C)
return grid
def grid_reverse(
grid: torch.Tensor,
original_size: Tuple[int, int],
grid_size: Tuple[int, int] = (7, 7)
) -> torch.Tensor:
""" Reverses the grid partition.
Args:
Grid (torch.Tensor): Grid tensor of the shape [B * grids, grid_size[0], grid_size[1], C].
original_size (Tuple[int, int]): Original shape.
grid_size (Tuple[int, int], optional): Grid size which have been applied. Default (7, 7)
Returns:
output (torch.Tensor): Folded output tensor of the shape [B, C, original_size[0], original_size[1]].
"""
# Get height, width, and channels
(H, W), C = original_size, grid.shape[-1]
# Compute original batch size
B = int(grid.shape[0] / (H * W / grid_size[0] / grid_size[1]))
# Fold grid tensor
output = grid.view(B, H // grid_size[0], W // grid_size[1], grid_size[0], grid_size[1], C)
output = output.permute(0, 5, 3, 1, 4, 2).contiguous().view(B, C, H, W)
return output
def get_relative_position_index(
win_h: int,
win_w: int
) -> torch.Tensor:
""" Function to generate pair-wise relative position index for each token inside the window.
Taken from Timms Swin V1 implementation.
Args:
win_h (int): Window/Grid height.
win_w (int): Window/Grid width.
Returns:
relative_coords (torch.Tensor): Pair-wise relative position indexes [height * width, height * width].
"""
coords = torch.stack(torch.meshgrid([torch.arange(win_h), torch.arange(win_w)]))
coords_flatten = torch.flatten(coords, 1)
relative_coords = coords_flatten[:, :, None] - coords_flatten[:, None, :]
relative_coords = relative_coords.permute(1, 2, 0).contiguous()
relative_coords[:, :, 0] += win_h - 1
relative_coords[:, :, 1] += win_w - 1
relative_coords[:, :, 0] *= 2 * win_w - 1
return relative_coords.sum(-1)
class RelativeSelfAttention(nn.Module):
""" Relative Self-Attention similar to Swin V1. Implementation inspired by Timms Swin V1 implementation.
Args:
in_channels (int): Number of input channels.
num_heads (int, optional): Number of attention heads. Default 32
grid_window_size (Tuple[int, int], optional): Grid/Window size to be utilized. Default (7, 7)
attn_drop (float, optional): Dropout ratio of attention weight. Default: 0.0
drop (float, optional): Dropout ratio of output. Default: 0.0
"""
def __init__(
self,
in_channels: int,
num_heads: int = 32,
grid_window_size: Tuple[int, int] = (7, 7),
attn_drop: float = 0.,
drop: float = 0.
) -> None:
""" Constructor method """
# Call super constructor
super(RelativeSelfAttention, self).__init__()
# Save parameters
self.in_channels: int = in_channels
self.num_heads: int = num_heads
self.grid_window_size: Tuple[int, int] = grid_window_size
self.scale: float = num_heads ** -0.5
self.attn_area: int = grid_window_size[0] * grid_window_size[1]
# Init layers
self.qkv_mapping = nn.Linear(in_features=in_channels, out_features=3 * in_channels, bias=True)
self.attn_drop = nn.Dropout(p=attn_drop)
self.proj = nn.Linear(in_features=in_channels, out_features=in_channels, bias=True)
self.proj_drop = nn.Dropout(p=drop)
self.softmax = nn.Softmax(dim=-1)
# Define a parameter table of relative position bias, shape: 2*Wh-1 * 2*Ww-1, nH
self.relative_position_bias_table = nn.Parameter(
torch.zeros((2 * grid_window_size[0] - 1) * (2 * grid_window_size[1] - 1), num_heads))
# Get pair-wise relative position index for each token inside the window
self.register_buffer("relative_position_index", get_relative_position_index(grid_window_size[0],
grid_window_size[1]))
# Init relative positional bias
trunc_normal_(self.relative_position_bias_table, std=.02)
def _get_relative_positional_bias(
self
) -> torch.Tensor:
""" Returns the relative positional bias.
Returns:
relative_position_bias (torch.Tensor): Relative positional bias.
"""
relative_position_bias = self.relative_position_bias_table[
self.relative_position_index.view(-1)].view(self.attn_area, self.attn_area, -1)
relative_position_bias = relative_position_bias.permute(2, 0, 1).contiguous()
return relative_position_bias.unsqueeze(0)
def forward(
self,
input: torch.Tensor
) -> torch.Tensor:
""" Forward pass.
Args:
input (torch.Tensor): Input tensor of the shape [B_, N, C].
Returns:
output (torch.Tensor): Output tensor of the shape [B_, N, C].
"""
# Get shape of input
B_, N, C = input.shape
# Perform query key value mapping
qkv = self.qkv_mapping(input).reshape(B_, N, 3, self.num_heads, -1).permute(2, 0, 3, 1, 4)
q, k, v = qkv.unbind(0)
# Scale query
q = q * self.scale
# Compute attention maps
attn = self.softmax(q @ k.transpose(-2, -1) + self._get_relative_positional_bias())
# Map value with attention maps
output = (attn @ v).transpose(1, 2).reshape(B_, N, -1)
# Perform final projection and dropout
output = self.proj(output)
output = self.proj_drop(output)
return output
class MaxViTTransformerBlock(nn.Module):
""" MaxViT Transformer block.
With block partition:
x ← x + Unblock(RelAttention(Block(LN(x))))
x ← x + MLP(LN(x))
With grid partition:
x ← x + Ungrid(RelAttention(Grid(LN(x))))
x ← x + MLP(LN(x))
Layer Normalization (LN) is applied after the grid/window partition to prevent multiple reshaping operations.
Grid/window reverse (Unblock/Ungrid) is performed on the final output for the same reason.
Args:
in_channels (int): Number of input channels.
partition_function (Callable): Partition function to be utilized (grid or window partition).
reverse_function (Callable): Reverse function to be utilized (grid or window reverse).
num_heads (int, optional): Number of attention heads. Default 32
grid_window_size (Tuple[int, int], optional): Grid/Window size to be utilized. Default (7, 7)
attn_drop (float, optional): Dropout ratio of attention weight. Default: 0.0
drop (float, optional): Dropout ratio of output. Default: 0.0
drop_path (float, optional): Dropout ratio of path. Default: 0.0
mlp_ratio (float, optional): Ratio of mlp hidden dim to embedding dim. Default: 4.0
act_layer (Type[nn.Module], optional): Type of activation layer to be utilized. Default: nn.GELU
norm_layer (Type[nn.Module], optional): Type of normalization layer to be utilized. Default: nn.BatchNorm2d
"""
def __init__(
self,
in_channels: int,
partition_function: Callable,
reverse_function: Callable,
num_heads: int = 32,
grid_window_size: Tuple[int, int] = (7, 7),
attn_drop: float = 0.,
drop: float = 0.,
drop_path: float = 0.,
mlp_ratio: float = 4.,
act_layer: Type[nn.Module] = nn.GELU,
norm_layer: Type[nn.Module] = nn.LayerNorm,
) -> None:
""" Constructor method """
super(MaxViTTransformerBlock, self).__init__()
# Save parameters
self.partition_function: Callable = partition_function
self.reverse_function: Callable = reverse_function
self.grid_window_size: Tuple[int, int] = grid_window_size
# Init layers
self.norm_1 = norm_layer(in_channels)
self.attention = RelativeSelfAttention(
in_channels=in_channels,
num_heads=num_heads,
grid_window_size=grid_window_size,
attn_drop=attn_drop,
drop=drop
)
self.drop_path = DropPath(drop_path) if drop_path > 0. else nn.Identity()
self.norm_2 = norm_layer(in_channels)
self.mlp = Mlp(
in_features=in_channels,
hidden_features=int(mlp_ratio * in_channels),
act_layer=act_layer,
drop=drop
)
def forward(self, input: torch.Tensor) -> torch.Tensor:
""" Forward pass.
Args:
input (torch.Tensor): Input tensor of the shape [B, C_in, H, W].
Returns:
output (torch.Tensor): Output tensor of the shape [B, C_out, H (// 2), W (// 2)].
"""
# Save original shape
B, C, H, W = input.shape
# Perform partition
input_partitioned = self.partition_function(input, self.grid_window_size)
input_partitioned = input_partitioned.view(-1, self.grid_window_size[0] * self.grid_window_size[1], C)
# Perform normalization, attention, and dropout
output = input_partitioned + self.drop_path(self.attention(self.norm_1(input_partitioned)))
# Perform normalization, MLP, and dropout
output = output + self.drop_path(self.mlp(self.norm_2(output)))
# Reverse partition
output = self.reverse_function(output, (H, W), self.grid_window_size)
return output
class MaxViTBlock(nn.Module):
""" MaxViT block composed of MBConv block, Block Attention, and Grid Attention.
Args:
in_channels (int): Number of input channels.
out_channels (int): Number of output channels.
downscale (bool, optional): If true spatial downscaling is performed. Default: False
num_heads (int, optional): Number of attention heads. Default 32
grid_window_size (Tuple[int, int], optional): Grid/Window size to be utilized. Default (7, 7)
attn_drop (float, optional): Dropout ratio of attention weight. Default: 0.0
drop (float, optional): Dropout ratio of output. Default: 0.0
drop_path (float, optional): Dropout ratio of path. Default: 0.0
mlp_ratio (float, optional): Ratio of mlp hidden dim to embedding dim. Default: 4.0
act_layer (Type[nn.Module], optional): Type of activation layer to be utilized. Default: nn.GELU
norm_layer (Type[nn.Module], optional): Type of normalization layer to be utilized. Default: nn.BatchNorm2d
norm_layer_transformer (Type[nn.Module], optional): Normalization layer in Transformer. Default: nn.LayerNorm
"""
def __init__(
self,
in_channels: int,
out_channels: int,
downscale: bool = False,
num_heads: int = 32,
grid_window_size: Tuple[int, int] = (7, 7),
attn_drop: float = 0.,
drop: float = 0.,
drop_path: float = 0.,
mlp_ratio: float = 4.,
act_layer: Type[nn.Module] = nn.GELU,
norm_layer: Type[nn.Module] = nn.BatchNorm2d,
norm_layer_transformer: Type[nn.Module] = nn.LayerNorm
) -> None:
""" Constructor method """
# Call super constructor
super(MaxViTBlock, self).__init__()
# Init MBConv block
self.mb_conv = MBConv(
in_channels=in_channels,
out_channels=out_channels,
downscale=downscale,
act_layer=act_layer,
norm_layer=norm_layer,
drop_path=drop_path
)
# Init Block and Grid Transformer
self.block_transformer = MaxViTTransformerBlock(
in_channels=out_channels,
partition_function=window_partition,
reverse_function=window_reverse,
num_heads=num_heads,
grid_window_size=grid_window_size,
attn_drop=attn_drop,
drop=drop,
drop_path=drop_path,
mlp_ratio=mlp_ratio,
act_layer=act_layer,
norm_layer=norm_layer_transformer
)
self.grid_transformer = MaxViTTransformerBlock(
in_channels=out_channels,
partition_function=grid_partition,
reverse_function=grid_reverse,
num_heads=num_heads,
grid_window_size=grid_window_size,
attn_drop=attn_drop,
drop=drop,
drop_path=drop_path,
mlp_ratio=mlp_ratio,
act_layer=act_layer,
norm_layer=norm_layer_transformer
)
def forward(self, input: torch.Tensor) -> torch.Tensor:
""" Forward pass.
Args:
input (torch.Tensor): Input tensor of the shape [B, C_in, H, W]
Returns:
output (torch.Tensor): Output tensor of the shape [B, C_out, H // 2, W // 2] (downscaling is optional)
"""
output = self.grid_transformer(self.block_transformer(self.mb_conv(input)))
return output
class MaxViTStage(nn.Module):
""" Stage of the MaxViT.
Args:
depth (int): Depth of the stage.
in_channels (int): Number of input channels.
out_channels (int): Number of output channels.
num_heads (int, optional): Number of attention heads. Default 32
grid_window_size (Tuple[int, int], optional): Grid/Window size to be utilized. Default (7, 7)
attn_drop (float, optional): Dropout ratio of attention weight. Default: 0.0
drop (float, optional): Dropout ratio of output. Default: 0.0
drop_path (float, optional): Dropout ratio of path. Default: 0.0
mlp_ratio (float, optional): Ratio of mlp hidden dim to embedding dim. Default: 4.0
act_layer (Type[nn.Module], optional): Type of activation layer to be utilized. Default: nn.GELU
norm_layer (Type[nn.Module], optional): Type of normalization layer to be utilized. Default: nn.BatchNorm2d
norm_layer_transformer (Type[nn.Module], optional): Normalization layer in Transformer. Default: nn.LayerNorm
"""
def __init__(
self,
depth: int,
in_channels: int,
out_channels: int,
num_heads: int = 32,
grid_window_size: Tuple[int, int] = (7, 7),
attn_drop: float = 0.,
drop: float = 0.,
drop_path: Union[List[float], float] = 0.,
mlp_ratio: float = 4.,
act_layer: Type[nn.Module] = nn.GELU,
norm_layer: Type[nn.Module] = nn.BatchNorm2d,
norm_layer_transformer: Type[nn.Module] = nn.LayerNorm
) -> None:
""" Constructor method """
# Call super constructor
super(MaxViTStage, self).__init__()
# Init blocks
self.blocks = nn.Sequential(*[
MaxViTBlock(
in_channels=in_channels if index == 0 else out_channels,
out_channels=out_channels,
downscale=index == 0,
num_heads=num_heads,
grid_window_size=grid_window_size,
attn_drop=attn_drop,
drop=drop,
drop_path=drop_path if isinstance(drop_path, float) else drop_path[index],
mlp_ratio=mlp_ratio,
act_layer=act_layer,
norm_layer=norm_layer,
norm_layer_transformer=norm_layer_transformer
)
for index in range(depth)
])
def forward(self, input=torch.Tensor) -> torch.Tensor:
""" Forward pass.
Args:
input (torch.Tensor): Input tensor of the shape [B, C_in, H, W].
Returns:
output (torch.Tensor): Output tensor of the shape [B, C_out, H // 2, W // 2].
"""
output = self.blocks(input)
return output
class MaxViT(nn.Module):
""" Implementation of the MaxViT proposed in:
https://arxiv.org/pdf/2204.01697.pdf
Args:
in_channels (int, optional): Number of input channels to the convolutional stem. Default 3
depths (Tuple[int, ...], optional): Depth of each network stage. Default (2, 2, 5, 2)
channels (Tuple[int, ...], optional): Number of channels in each network stage. Default (64, 128, 256, 512)
num_classes (int, optional): Number of classes to be predicted. Default 1000
embed_dim (int, optional): Embedding dimension of the convolutional stem. Default 64
num_heads (int, optional): Number of attention heads. Default 32
grid_window_size (Tuple[int, int], optional): Grid/Window size to be utilized. Default (7, 7)
attn_drop (float, optional): Dropout ratio of attention weight. Default: 0.0
drop (float, optional): Dropout ratio of output. Default: 0.0
drop_path (float, optional): Dropout ratio of path. Default: 0.0
mlp_ratio (float, optional): Ratio of mlp hidden dim to embedding dim. Default: 4.0
act_layer (Type[nn.Module], optional): Type of activation layer to be utilized. Default: nn.GELU
norm_layer (Type[nn.Module], optional): Type of normalization layer to be utilized. Default: nn.BatchNorm2d
norm_layer_transformer (Type[nn.Module], optional): Normalization layer in Transformer. Default: nn.LayerNorm
global_pool (str, optional): Global polling type to be utilized. Default "avg"
"""
def __init__(
self,
in_channels: int = 3,
depths: Tuple[int, ...] = (2, 2, 5, 2),
channels: Tuple[int, ...] = (64, 128, 256, 512),
num_classes: int = 1000,
embed_dim: int = 64,
num_heads: int = 32,
grid_window_size: Tuple[int, int] = (7, 7),
attn_drop: float = 0.,
drop=0.,
drop_path=0.,
mlp_ratio=4.,
act_layer=nn.GELU,
norm_layer=nn.BatchNorm2d,
norm_layer_transformer=nn.LayerNorm,
global_pool: str = "avg"
) -> None:
""" Constructor method """
# Call super constructor
super(MaxViT, self).__init__()
# Check parameters
assert len(depths) == len(channels), "For each stage a channel dimension must be given."
assert global_pool in ["avg", "max"], f"Only avg and max is supported but {global_pool} is given"
# Save parameters
self.num_classes: int = num_classes
# Init convolutional stem
self.stem = nn.Sequential(
nn.Conv2d(in_channels=in_channels, out_channels=embed_dim, kernel_size=(3, 3), stride=(2, 2),
padding=(1, 1)),
act_layer(),
nn.Conv2d(in_channels=embed_dim, out_channels=embed_dim, kernel_size=(3, 3), stride=(1, 1),
padding=(1, 1)),
act_layer(),
)
# Init blocks
drop_path = torch.linspace(0.0, drop_path, sum(depths)).tolist()
stages = []
for index, (depth, channel) in enumerate(zip(depths, channels)):
stages.append(
MaxViTStage(
depth=depth,
in_channels=embed_dim if index == 0 else channels[index - 1],
out_channels=channel,
num_heads=num_heads,
grid_window_size=grid_window_size,
attn_drop=attn_drop,
drop=drop,
drop_path=drop_path[sum(depths[:index]):sum(depths[:index + 1])],
mlp_ratio=mlp_ratio,
act_layer=act_layer,
norm_layer=norm_layer,
norm_layer_transformer=norm_layer_transformer
)
)
self.stages = nn.ModuleList(stages)
self.global_pool: str = global_pool
self.head = nn.Linear(channels[-1], num_classes)
@torch.jit.ignore
def no_weight_decay(self) -> Set[str]:
""" Gets the names of parameters to not apply weight decay to.
Returns:
nwd (Set[str]): Set of parameter names to not apply weight decay to.
"""
nwd = set()
for n, _ in self.named_parameters():
if "relative_position_bias_table" in n:
nwd.add(n)
return nwd
def reset_classifier(self, num_classes: int, global_pool: Optional[str] = None) -> None:
"""Method results the classification head
Args:
num_classes (int): Number of classes to be predicted
global_pool (str, optional): If not global pooling is updated
"""
self.num_classes: int = num_classes
if global_pool is not None:
self.global_pool = global_pool
self.head = nn.Linear(self.num_features, num_classes) if num_classes > 0 else nn.Identity()
def forward_features(self, input: torch.Tensor) -> torch.Tensor:
""" Forward pass of feature extraction.
Args:
input (torch.Tensor): Input images of the shape [B, C, H, W].
Returns:
output (torch.Tensor): Image features of the backbone.
"""
output = input
for stage in self.stages:
output = stage(output)
return output
def forward_head(self, input: torch.Tensor, pre_logits: bool = False):
""" Forward pass of classification head.
Args:
input (torch.Tensor): Input features
pre_logits (bool, optional): If true pre-logits are returned
Returns:
output (torch.Tensor): Classification output of the shape [B, num_classes].
"""
if self.global_pool == "avg":
input = input.mean(dim=(2, 3))
elif self.global_pool == "max":
input = torch.amax(input, dim=(2, 3))
return input if pre_logits else self.head(input)
def forward(self, input: torch.Tensor) -> torch.Tensor:
""" Forward pass
Args:
input (torch.Tensor): Input images of the shape [B, C, H, W].
Returns:
output (torch.Tensor): Classification output of the shape [B, num_classes].
"""
output = self.forward_features(self.stem(input))
output = self.forward_head(output)
return output
def max_vit_tiny_224(**kwargs) -> MaxViT:
""" MaxViT tiny for a resolution of 224 X 224"""
return MaxViT(
depths=(2, 2, 5, 2),
channels=(64, 128, 256, 512),
embed_dim=64,
**kwargs
)
def max_vit_small_224(**kwargs) -> MaxViT:
""" MaxViT small for a resolution of 224 X 224"""
return MaxViT(
depths=(2, 2, 5, 2),
channels=(96, 128, 256, 512),
embed_dim=64,
**kwargs
)
def max_vit_base_224(**kwargs) -> MaxViT:
""" MaxViT base for a resolution of 224 X 224"""
return MaxViT(
depths=(2, 6, 14, 2),
channels=(96, 192, 384, 768),
embed_dim=64,
**kwargs
)
def max_vit_large_224(**kwargs) -> MaxViT:
""" MaxViT large for a resolution of 224 X 224"""
return MaxViT(
depths=(2, 6, 14, 2),
channels=(128, 256, 512, 1024),
embed_dim=128,
**kwargs
)
if __name__ == '__main__':
def test_partition_and_revers() -> None:
input = torch.rand(7, 3, 14, 14)
windows = window_partition(input=input)
windows = window_reverse(windows=windows, window_size=(7, 7), original_size=input.shape[2:])
print(torch.all(input == windows))
grid = grid_partition(input=input)
grid = grid_reverse(grid=grid, grid_size=(7, 7), original_size=input.shape[2:])
print(torch.all(input == grid))
def test_relative_self_attention() -> None:
relative_self_attention = RelativeSelfAttention(in_channels=128)
input = torch.rand(4, 128, 14 * 14)
output = relative_self_attention(input)
print(output.shape)
def test_transformer_block() -> None:
transformer = MaxViTTransformerBlock(in_channels=128, partition_function=grid_partition,
reverse_function=grid_reverse)
input = torch.rand(4, 128, 7, 7)
output = transformer(input)
print(output.shape)
transformer = MaxViTTransformerBlock(in_channels=128, partition_function=window_partition,
reverse_function=window_reverse)
input = torch.rand(4, 128, 7, 7)
output = transformer(input)
print(output.shape)
def test_block() -> None:
block = MaxViTBlock(in_channels=128, out_channels=256, downscale=True)
input = torch.rand(1, 128, 28, 28)
output = block(input)
print(output.shape)
def test_networks() -> None:
for get_network in [max_vit_tiny_224, max_vit_small_224, max_vit_base_224, max_vit_large_224]:
network = get_network(num_classes=365)
input = torch.rand(1, 3, 224, 224)
output = network(input)
print(output.shape)
test_networks()
Thực nghiệm
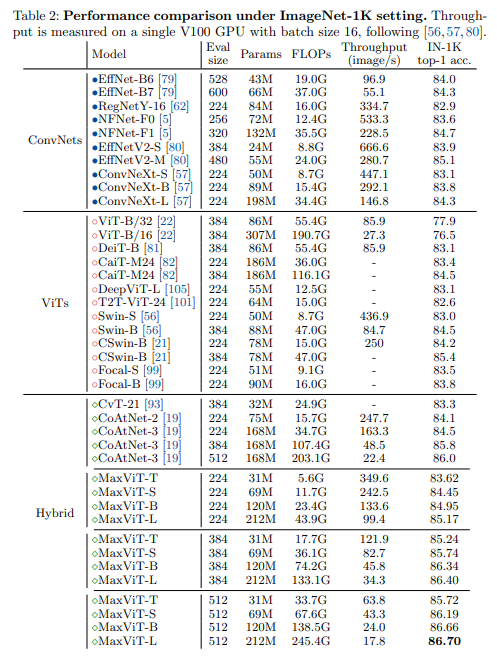
Bảng dưới so sánh kết quả các mô hình SOTA trên tập dữ liệu ImageNet-1K.
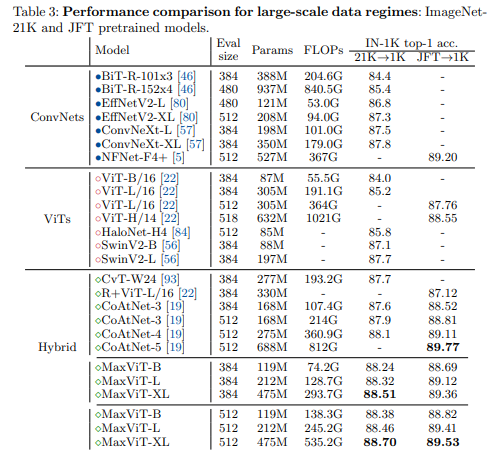
Bảng dưới so sánh kết quả các mô hình SOTA trên tập dữ liệu lớn, các mô hình được pretrained trên bộ ImageNet-21K và JFT.
Hai biểu đồ dưới so sánh tương quan giữa lượng tham số và độ chính xác của các mô hình SOTA.
Tham khảo
[1] MaxViT: Multi-Axis Vision Transformer
[2] https://github.com/google-research/maxvit
[3] https://github.com/ChristophReich1996/MaxViT/tree/master
All rights reserved
