Paper reading | Masked Motion Encoding for Self-Supervised Video Representation Learning
Đóng góp của bài báo
Bài báo đóng góp một phương pháp để có thể học biểu diễn video (Video representation learning) một cách hiệu quả. Do lượng video data được gán nhãn còn hạn chế nên việc có một phương pháp có thể tận dụng nguồn data không gán nhãn này là một điều cần thiết.Những năm gần đây trong các bài toán computer vision, có rất nhiều nghiên cứu ứng dụng self-supervised learning để học biểu diễn trong các dữ liệu không được gán nhãn. Ví dụ đối với ảnh, ta sẽ mask (che) các patch của ảnh theo một tỉ lệ nào đó và thực hiện train để học cách tái tạo (reconstruct) lại phần bị mask này (ví dụ trong model MAE). Dựa vào ý tưởng này, nhiều nhóm nghiên cứu áp dụng cho video, tuy nhiên vẫn tồn tại 2 điểm hạn chế chính:
- Trong hình ảnh, ta có thể mask các patch của ảnh và tái tạo lại một cách dễ dàng. Điều này tương tự với video do bản chất là sự kết hợp giữa các frame, ta có thể tái tạo các patch của các frame. Tuy nhiên, việc học cách tái tạo này không giúp ta có được những thông tin về thời gian.
- Các nghiên cứu trước đây thường áp dụng cách sample frame là sử dụng stride cố định (sau mỗi stride thì lấy frame 1 lần) sau đó mask một vùng nào đó trên các frame này, điều này làm mất đi những frame chứa thông tin quan trọng. Đặc biệt, với bài toán phân loại hành động thì những chi tiết chuyển động nhỏ ở từng frame là vô cùng cần thiết, là dấu hiệu để phân biệt với các hành động khác.
Từ những hạn chế trên, bài báo đưa ra phương pháp giải quyết như sau:
- Đề xuất mô hình Masked Motion Encoding (MME) giải quyết những hạn chế về vấn đề thông tin thời gian bằng cách yêu cầu mô hình reconstruct lại quỹ đạo chuyển động (motion trajectory).
- Đề xuất cơ chế nội suy chuyển động nhận đầu vào là video đã masking sau đó dự đoán chuỗi chuyển động ở cả chiều không gian và thời gian. Điều này cho phép mô hình nắm bắt các thông tin chuyển động dài hạn và chi tiết từ đầu vào là video "thưa".
Tổng quan mô hình được thể hiện trong hình dưới
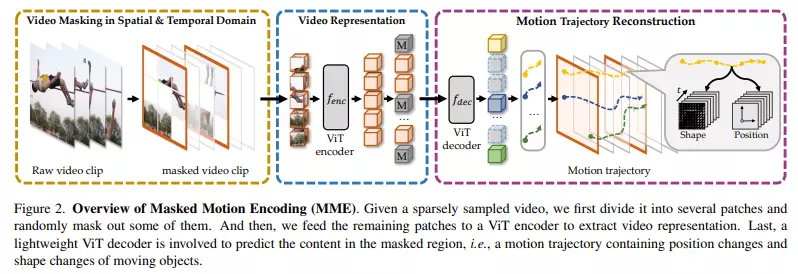
Phương pháp
Nhắc lại Masked Video Modeling
Cho một video clip được cắt từ một video, mục tiêu của self-supervised video representation learning là training một feature encoder ánh xạ video clip thành feature tương ứng. Các model video masking trước đây thường theo một ý tưởng chung như sau:
- Chia clip đầu vào thành các 3D patch không chồng nhau.
- Thực hiện mask ngẫu nhiên các patch sau đó đưa các patch không bị mask vào một feature encoder.
- Sử dụng decoder để reconstruct lại thông tin từ các patch bị mask. Một số model có ý tưởng reconstruct thông tin khác nhau, ví dụ như model VideoMAE thì reconstruct luôn các pixel, MaskFeat thì reconstruct HOG.
Cách trên tuy có thể học tốt các thông tin không gian nhưng lại hạn chế học được các thông tin về thời gian, đây là yếu tố rất quan trọng trong biểu diễn video.
Kiến trúc tổng quát của MME
Để học các thông tin về thời gian tốt hơn trong video, model MME sẽ không học cách reconstruct thông tin không gian như các model trước đó mà học reconstruct thông tin chuyển động của object bao gồm vị trí và sự thay đổi hình dạng của object.
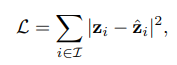
Như hình trên, các bước thực hiện của model như sau:
- Chia video thành các 3D patch không chồng nhau có kích thước tương ứng với chiều time, height, width.
- Sử dụng chiến lược tube masking (giống VideoMAE, bạn có thể đọc thêm về model này trên Viblo 😄) để mask cho một số patch.
- Các patch không bị mask sẽ được đưa vào encoder.
- Biểu diễn đầu ra sau khi đi qua encoder cùng với các learnable
[MASK]token được đưa vào encoder để reconstruct motion trajectory trong các patch bị mask. - Training loss cho MME như sau:
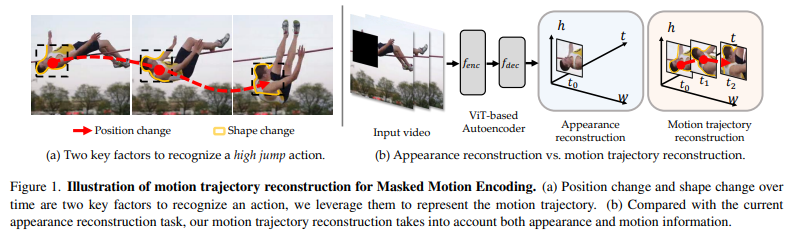 trong đó là giá trị dự đoán motion trajectory và tập các index của các motion trajectories trong tất cả các patch bị mask.
trong đó là giá trị dự đoán motion trajectory và tập các index của các motion trajectories trong tất cả các patch bị mask.
Motion Trajectory trong MME
Được truyền cảm hứng bởi thực tế là con người chúng ta nhận ra các hành động bằng cách cảm nhận sự thay đổi vị trí và thay đổi hình dạng của các vật thể đang chuyển động, nhóm tác giả tận dụng hai loại thông tin này để biểu diễn thông tin motion trajectory.
Sự chuyển động của các object có thể biểu diễn bằng nhiều cách khác nhau như:
- Optical flow (Luồng quang): Optical flow là một khái niệm trong lĩnh vực thị giác máy tính và xử lý hình ảnh, nó liên quan đến sự di chuyển của các đối tượng trong một cảnh quan. Khi một đối tượng di chuyển trong một khung hình, các pixel tương ứng trên các khung hình liên tiếp sẽ thay đổi vị trí của chúng. Optical flow sử dụng các phương pháp tính toán để ước lượng vector chuyển động của mỗi pixel từ khung hình hiện tại sang khung hình tiếp theo. Optical flow là một công cụ quan trọng để phân tích và hiểu sự chuyển động của các đối tượng trong các chuỗi video. Bằng cách tính toán optical flow, ta có thể xác định hướng và tốc độ di chuyển của các đối tượng trong cảnh quan.
- Histograms of optical flow (HOF) là một phương pháp trong xử lý hình ảnh và phân loại đối tượng dựa trên optical flow. HOF sử dụng thông tin về hướng và tốc độ di chuyển của các pixel trong một chuỗi video để tạo ra các biểu đồ histogram mô tả các mẫu chuyển động trong cảnh quan. HOF thường được sử dụng như các đặc trưng (features) trong các hệ thống nhận dạng hoặc phân loại đối tượng. Các biểu đồ histogram của optical flow cung cấp thông tin về mẫu chuyển động trong video và có thể được sử dụng để phân loại các hành động, nhận dạng các hoạt động như đi bộ, đạp xe, chạy,...
- Motion boundary histograms (MBH) là một phần mở rộng của Histograms of Optical Flow (HOF) và tập trung vào việc mô hình hóa biên giới chuyển động trong cảnh quan. MBH sử dụng thông tin về hướng và tốc độ di chuyển của các pixel trong video để tạo ra các biểu đồ histogram mô tả phân bố các biên giới chuyển động. Thay vì chỉ xem xét hướng di chuyển, MBH cũng xem xét biên giới chuyển động, tức là các vùng trên các đối tượng trong video mà có sự thay đổi mạnh về di chuyển. MBH cung cấp thông tin chi tiết về các biên giới chuyển động trong video, giúp nhận biết các cạnh và biên giới quan trọng trong quá trình di chuyển. Điều này có thể được sử dụng trong các ứng dụng như nhận dạng hành động, phân loại đối tượng di động, nhận diện vật thể và xử lý video.
Tuy nhiên các cách trên chỉ biểu diễn các chuyển động ngắn hạn giữa các frame kề nhau. Thứ ta mong muốn bây giờ là motion trajectory có thể biểu diễn được các chuyển động dài hạn hơn. Đầu tiên, ta sẽ track chuyển động của object trong frame để thu được chuyển động dài hạn, kết quả là một quỹ đạo như sau:
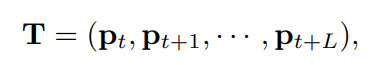
trong đó biểu diễn một điểm tại vị trí của frame và là thao tác concat. Xét trong quỹ đạo này, ta sẽ tìm các position feature và shape feature của object để tạo thành một quỹ đạo chuyển động :
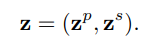
Các position feature được biểu diễn bởi sự dịch chuyển vị trí tương đối với time step trước đó, trong khi đó các shape feature được coi là các HOG descriptor của object được track trong các những time step khác nhau.
Một điểm mới trong bài báo đó là track object bằng cách sử dụng một quỹ đạo dày đặc (dense) theo cả không gian và thời gian. Cụ thể, nhóm tác giả thực hiện chọn điểm trong một patch (có kích thước ) bị mask, trong đó mỗi điểm là một phần của một object. Với mỗi điểm, ta thực hiện track qua frame liên tiếp, kết quả là ta thu được quỹ đạo. Bạn có thể xem hình dưới để hiểu rõ hơn.

Bằng cách này, model có thể nắm bắt được thông tin chuyển động về mặt không gian và thời gian tốt hơn (vẫn theo cơ chế là mask và predict như các model masking).
Các nghiên cứu trước đây thường sample video "thưa" làm đầu vào, tức là có stride giữa các frame. Tuy model được đề xuất cũng nhận video "thưa" làm đầu vào nhưng điểm khác là model thực hiện nội suy quỹ đạo chuyển động. Việc thực hiện nội suy này không làm tăng chi phí tính toán của encoder mà còn giúp cho model học được nhiều thông tin chuyển động chi tiết cho dù đầu vào là video thưa.
Cho một quỹ đạo chứa vị trí của object được track tại mỗi frame, ta sẽ quan tâm đến chuyển động của các object thay vì vị trí chính xác của chúng. Do đó, ta sẽ biểu diễn các position feature là chuyển động giữa 2 điểm kề nhau như sau:
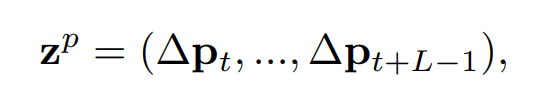
trong đó là một feature chiều. Vì mỗi patch có position feature nên ta sẽ concat và chuẩn hóa chúng và chuyển thành các position feature.
Bên cạnh việc thực hiện embed chuyển động của object, model cũng cần học được sự thay đổi hình dạng của object để nhận biết được các hành động. Trong model, nhóm tác giả sử dụng HOG (histograms of oriented gradients) với 9 bin để mô tả hình dạng của object. Do hình dạng của object thường thay đổi qua các frame nên ta cần tính toán trajectory-aligned HOG để track được những sự thay đổi hình dạng của object, cụ thể:
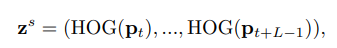
trong đó là HOG descriptor và là feature chiều. Vì mỗi patch gồm quỹ đạo, ta cần concat trajectory-aligned HOG feature và chuẩn hóa chúng về phân phối chuẩn.
Thực nghiệm
Bảng dưới là so sánh của các model SOTA trên tập dữ liệu Something-Something V2. Model MME có hiệu suất tốt hơn so với các model trước đó.
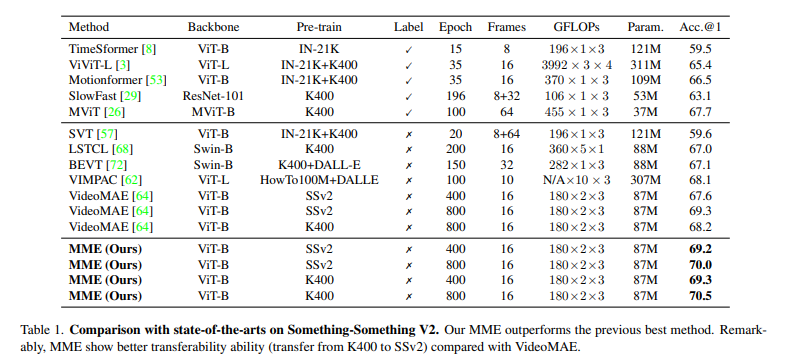
Tương tự, trên tập dữ liệu Kinetics-400. MME cũng cho kết quả ấn tượng.
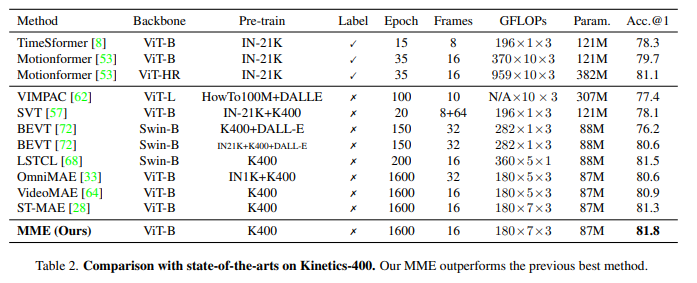
Với 2 bộ dữ liệu UCF101 và HMDB51, MME cũng cho kết quả tốt hơn với các model trước đó.
Phụ lục
Bài báo cũng trình bày ảnh hưởng của các loại reconstruct khác nhau lên hiệu suất của mô hình. Đầu tiên, để kiểm tra xem việc tái tạo hình ảnh có được thực hiện độc lập trong từng frame hay không. Nhóm tác giả thực hiện trộn ngẫu nhiên các frame trong video để hạn chế thông tin về thời gian, điều này có nghĩa là model sẽ khó tận dụng được thông tin từ những frame khác để reconstruct frame hiện tại thông qua sự tương quan về mặt thời gian. Nhóm tác giả cũng thực hiện mask 90% các frame trong video như model VideoMAE.
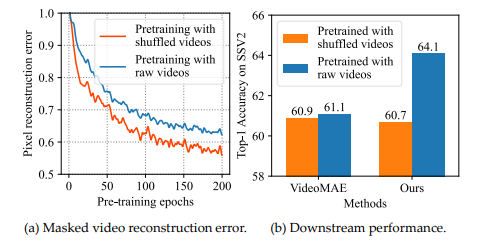
Từ hình trên ta nhận thấy rằng reconstruction loss (là L2 error giữa pixel dự đoán và pixel ground truth) hội tụ về giá trị thấp. Nhóm tác giả cũng tiến hành thực nghiệm sử dụng video thô ban đầu mà không trộn (shuffling) các frame. Model trải qua một quá trình hội tụ tương tự. Điều này chứng tỏ rằng các pixel bị mask được reconstruct tốt mà không cần thông tin thời gian.
Để tìm hiểu xem model được pretrain trên task reconstruct hình ảnh có thể nắm bắt được những thông tin thời gian quan trọng hay không? Nhóm tác giả thực hiện transfer 2 model VideoMAE (1 model được pretrain trên shuffled video và 1 model được pretrained trên video thô) thành downstream task là actio recognition. Như hình trên ta có thể nhận thấy rằng, 2 model có hiệu suất na ná nhau 😄 Điều này chứng tỏ rằng việc xóa thông tin về thời gian không làm ảnh hưởng nhiều đến việc học biểu diễn video trong model VideoMAE. Điều này là hợp lý và dễ hiểu vì model VideoMAE ít tập trung và thông tin thời gian hơn là thông tin về không gian. Ngược lại, model MME lại tốt hơn nhiều VideoMAE khoản này 😄 khi mà thông tin thời gian được cung cấp cho việc pretraining (64.1% và 61.1%). Khi mà thực hiện shuffle video ta thấy hiệu suất của 2 model không khác nhau nhiều (60.7% và 60.9%). Điều này chứng tỏ model MME có khả năng nắm bắt và tận dụng được thông tin thời gian trong quá trình pretraining.
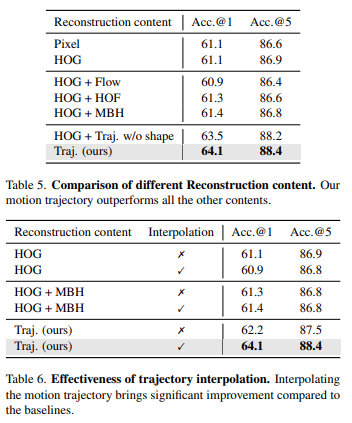
Trong 2 bảng trên, nhóm tác giả thực hiện so sánh ảnh hưởng của các phương pháp reconstruct khác nhau lên hiệu suất model.
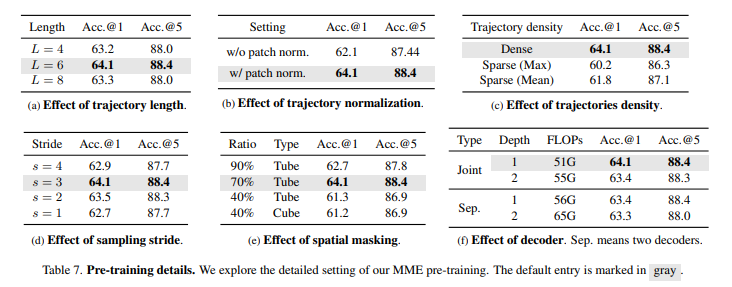
6 bảng trên là ảnh hưởng của các yếu tố khác lên hiệu suất model.
Tham khảo
[1] Masked Motion Encoding for Self-Supervised Video Representation Learning
All rights reserved
