Paper reading | Inception-v4, Inception-ResNet and the Impact of Residual Connections on Learning
Bài đăng này đã không được cập nhật trong 2 năm
Đóng góp bài báo
Trong bài báo, nhóm tác giả nghiên cứu sự kết hợp của 2 ý tưởng có thể coi là kinh điển trong lịch sử các mô hình CNN nổi tiếng là Residual connection và phiên bản mới nhất của kiến trúc Inception  .
.
Residual connection (xem hình dưới) đóng vai trò quan trọng trong việc training các mạng deep learning sâu.
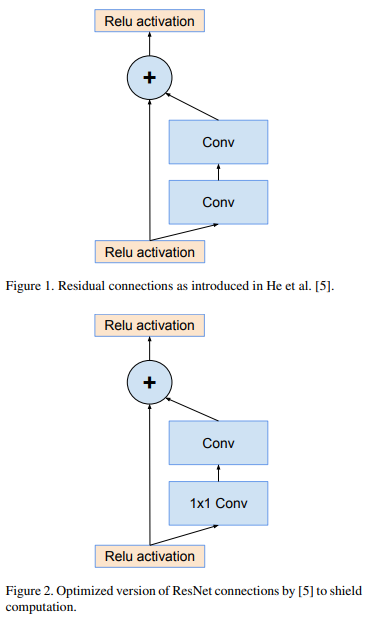
Inception cũng là một kiểu mạng deep learning "rất là deep" nên là một cách rất tự nhiên khi ta kết hợp Residual connection với mô hình Inception. Bằng cách này mô hình mới sẽ có được ưu điểm của Residual connection mà vẫn giữ nguyên độ hiệu quả tính toán.
Bên cạnh đó, nhóm tác giả cũng thực hiện nghiên cứu mô hình Inception và cải thiện mô hình bằng cách làm cho nó rộng và sâu hơn Cụ thể, bài báo giới thiệu mô hình Inception-v4 là một kiến trúc đơn giản đồng nhất hơn và nhiều module Inception hơn so với Inception-v3.
Ngoài ra, các thực nghiệm và so sánh giữa các mô hình cũng được báo cáo để làm rõ sự vượt trội của mô hình Inception-v4.
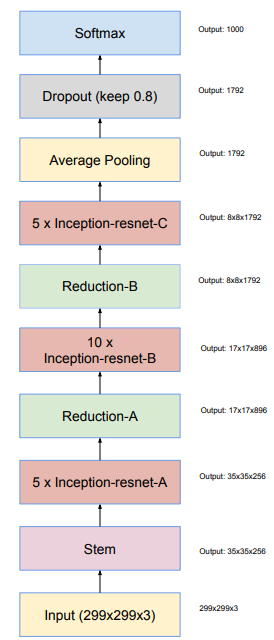
Kiến trúc mô hình
Inception-v4
Trong Inception-v4, các block Inception thuần được sử dụng và các block này không có residual connection. Trong khi các mô hình Inception trước đó, mô hình được chia thành các mạng con (sub-network) để fit với bộ nhớ của phần cứng thì mô hình Inception-v4 với khả năng tối ưu hóa bộ nhớ sử dụng cho backpropagation, ta có thể train mà không cần phân chia thành các bản sao.
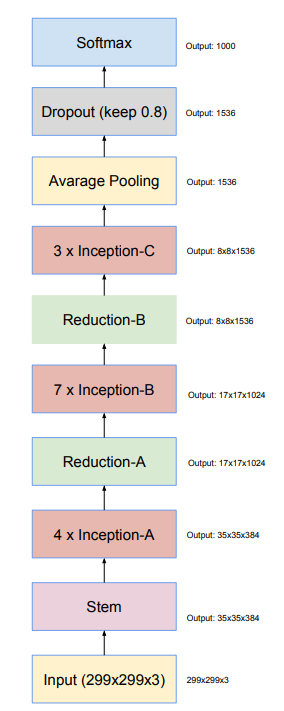
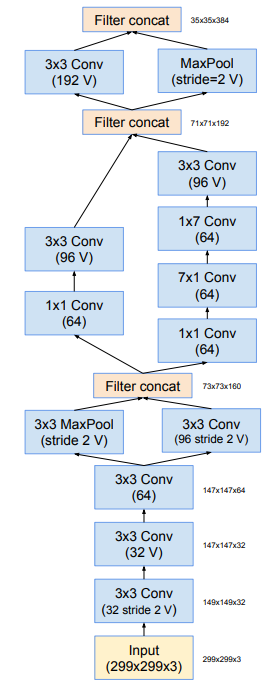
Kiến trúc tổng quan của Inception-v4 như sau:
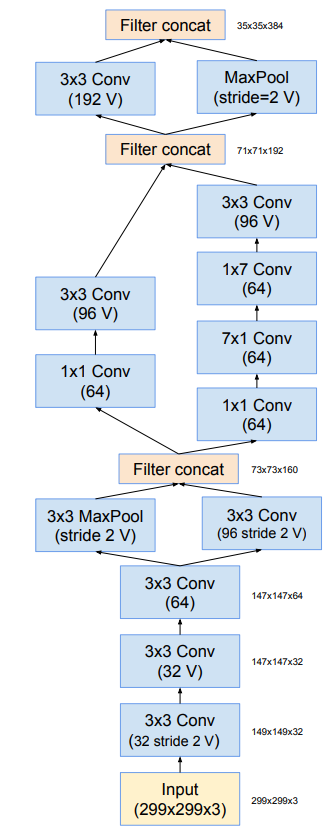
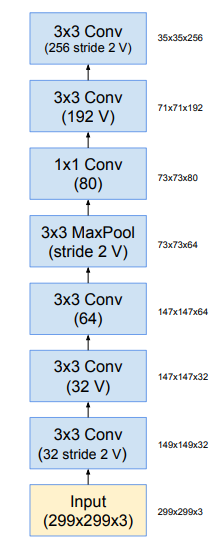
Khối stem trong Inception-v4 được mô tả trong hình dưới:
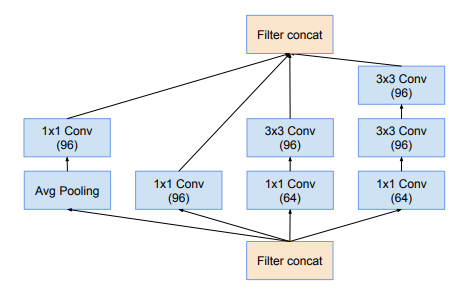
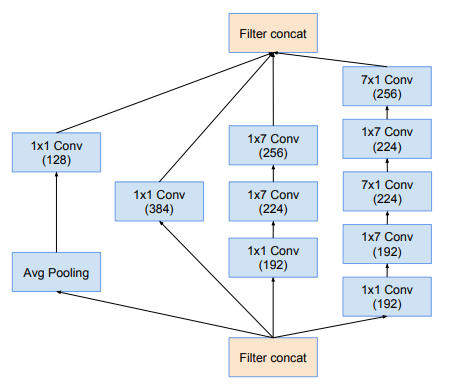
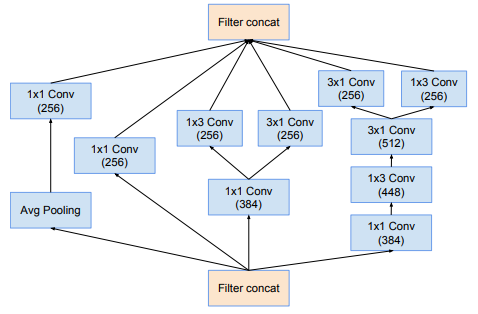
Tiếp theo là khối Inception-A, Inception-B và Inception-C được thể hiện trong hình dưới:
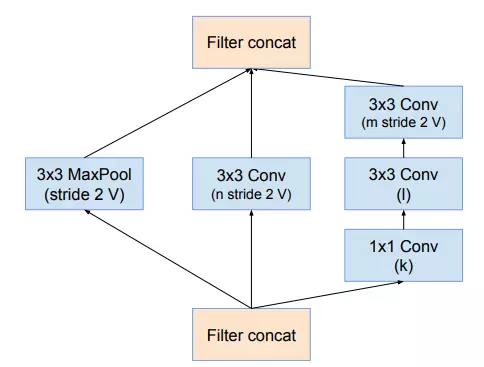
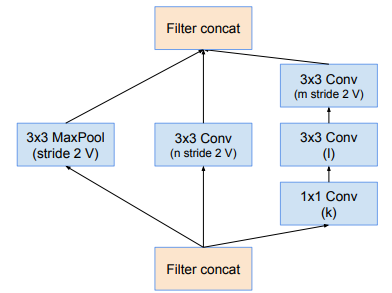
Khối reduction-A được biểu diễn như sau:
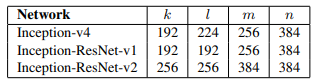
Lưu ý rằng, khối reduction-A cũng được sử dụng trong Inception-ResNet-v1 và Inception-ResNet-v2. Về mặt kiến trúc thì giống nhưng có sự thay đổi về kích thước filter bank tại mỗi model (tại các tham số ).
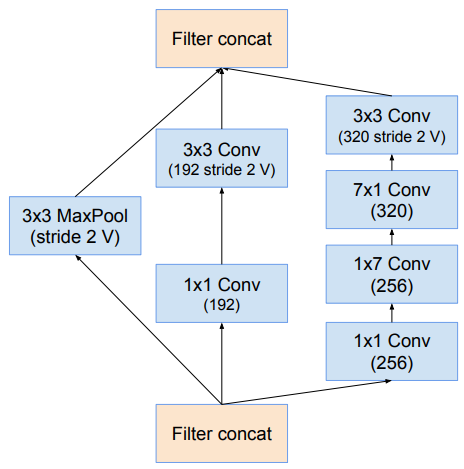
Cuối cùng ta có khối reduction-B
Inception-ResNet
Inception-Resnet-v1 và Inception-ResNet-v2 đều chúng một kiến trúc như hình dưới. Tuy nhiên bên trong các thành phần của 2 mô hình có một chút sự khác biệt.
Inception-ResNet-V1
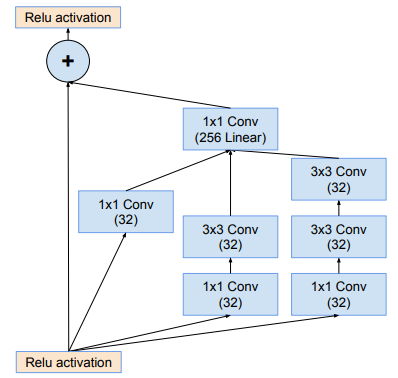
Đối với Inception-ResNet-v1, ta sử dụng các module sau như hình dưới.
Module stem
Module Inception-ResNet-A
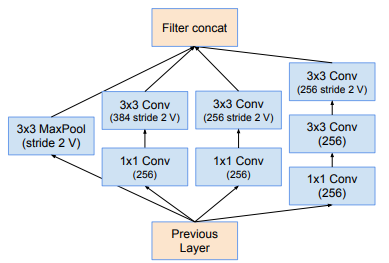
Module Reduction-A
Module Inception-ResNet-B
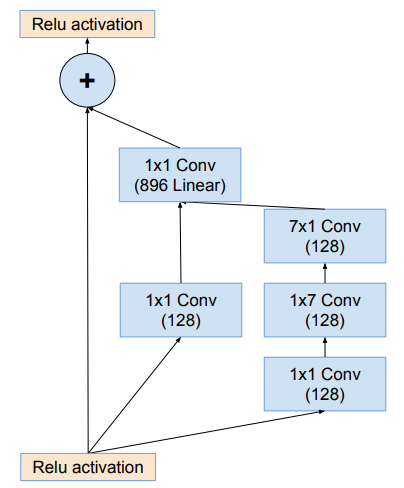
Module Reduction-B
Inception-ResNet-V2
Tương tự, đối với Inception-ResNet-v2, ta sử dụng các module sau.
Module Stem
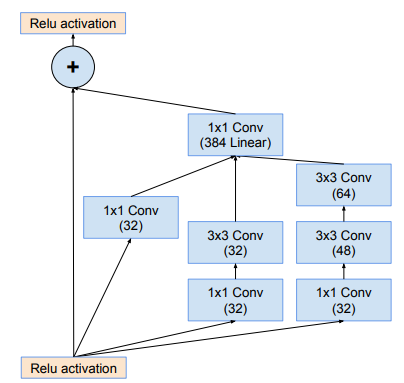
Module Inception-ResNet-A
Module Reduction-A
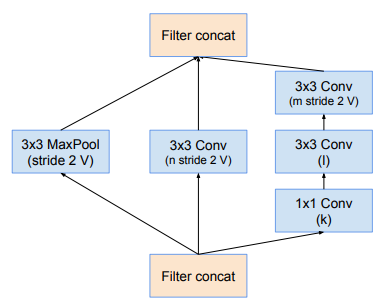
Module Inception-ResNet-B
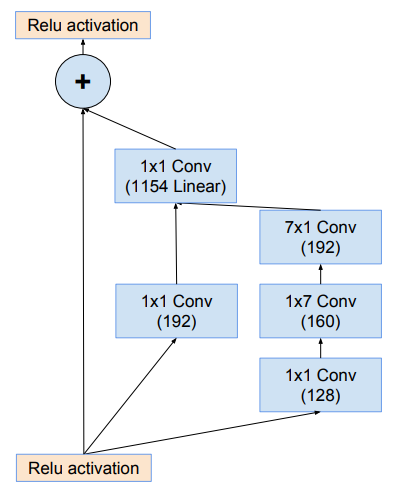
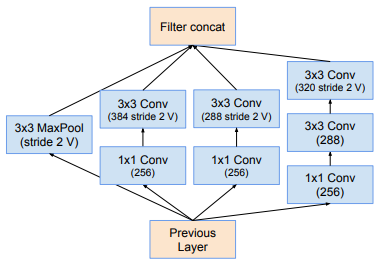
Module Reduction-B
Các tham số trong module Reduction-A của cả 3 mô hình có giá trị thể hiện trong bảng dưới
Coding
Vì 3 mô hình đều có một số điểm chung trong các module và kiến trúc tổng nên khi code ta có thể gộp chung chúng vào một file model và viết các class module riêng để có thể tái sử dụng. Các module trong code được follow chính xác như các hình trong paper
import torch
import torch.nn as nn
class BasicConv2d(nn.Module):
def __init__(self, input_channels, output_channels, **kwargs):
super().__init__()
self.conv = nn.Conv2d(input_channels, output_channels, bias=False, **kwargs)
self.bn = nn.BatchNorm2d(output_channels)
self.relu = nn.ReLU(inplace=True)
def forward(self, x):
x = self.conv(x)
x = self.bn(x)
x = self.relu(x)
return x
class Inception_Stem(nn.Module):
#"""Figure 3. The schema for stem of the pure Inception-v4 and
#Inception-ResNet-v2 networks. This is the input part of those
#networks."""
def __init__(self, input_channels):
super().__init__()
self.conv1 = nn.Sequential(
BasicConv2d(input_channels, 32, kernel_size=3),
BasicConv2d(32, 32, kernel_size=3, padding=1),
BasicConv2d(32, 64, kernel_size=3, padding=1)
)
self.branch3x3_conv = BasicConv2d(64, 96, kernel_size=3, padding=1)
self.branch3x3_pool = nn.MaxPool2d(3, stride=1, padding=1)
self.branch7x7a = nn.Sequential(
BasicConv2d(160, 64, kernel_size=1),
BasicConv2d(64, 64, kernel_size=(7, 1), padding=(3, 0)),
BasicConv2d(64, 64, kernel_size=(1, 7), padding=(0, 3)),
BasicConv2d(64, 96, kernel_size=3, padding=1)
)
self.branch7x7b = nn.Sequential(
BasicConv2d(160, 64, kernel_size=1),
BasicConv2d(64, 96, kernel_size=3, padding=1)
)
self.branchpoola = nn.MaxPool2d(kernel_size=3, stride=1, padding=1)
self.branchpoolb = BasicConv2d(192, 192, kernel_size=3, stride=1, padding=1)
def forward(self, x):
x = self.conv1(x)
x = [
self.branch3x3_conv(x),
self.branch3x3_pool(x)
]
x = torch.cat(x, 1)
x = [
self.branch7x7a(x),
self.branch7x7b(x)
]
x = torch.cat(x, 1)
x = [
self.branchpoola(x),
self.branchpoolb(x)
]
x = torch.cat(x, 1)
return x
class InceptionA(nn.Module):
#"""Figure 4. The schema for 35 × 35 grid modules of the pure
#Inception-v4 network. This is the Inception-A block of Figure 9."""
def __init__(self, input_channels):
super().__init__()
self.branch3x3stack = nn.Sequential(
BasicConv2d(input_channels, 64, kernel_size=1),
BasicConv2d(64, 96, kernel_size=3, padding=1),
BasicConv2d(96, 96, kernel_size=3, padding=1)
)
self.branch3x3 = nn.Sequential(
BasicConv2d(input_channels, 64, kernel_size=1),
BasicConv2d(64, 96, kernel_size=3, padding=1)
)
self.branch1x1 = BasicConv2d(input_channels, 96, kernel_size=1)
self.branchpool = nn.Sequential(
nn.AvgPool2d(kernel_size=3, stride=1, padding=1),
BasicConv2d(input_channels, 96, kernel_size=1)
)
def forward(self, x):
x = [
self.branch3x3stack(x),
self.branch3x3(x),
self.branch1x1(x),
self.branchpool(x)
]
return torch.cat(x, 1)
class ReductionA(nn.Module):
#"""Figure 7. The schema for 35 × 35 to 17 × 17 reduction module.
#Different variants of this blocks (with various number of filters)
#are used in Figure 9, and 15 in each of the new Inception(-v4, - ResNet-v1,
#-ResNet-v2) variants presented in this paper. The k, l, m, n numbers
#represent filter bank sizes which can be looked up in Table 1.
def __init__(self, input_channels, k, l, m, n):
super().__init__()
self.branch3x3stack = nn.Sequential(
BasicConv2d(input_channels, k, kernel_size=1),
BasicConv2d(k, l, kernel_size=3, padding=1),
BasicConv2d(l, m, kernel_size=3, stride=2)
)
self.branch3x3 = BasicConv2d(input_channels, n, kernel_size=3, stride=2)
self.branchpool = nn.MaxPool2d(kernel_size=3, stride=2)
self.output_channels = input_channels + n + m
def forward(self, x):
x = [
self.branch3x3stack(x),
self.branch3x3(x),
self.branchpool(x)
]
return torch.cat(x, 1)
class InceptionB(nn.Module):
#"""Figure 5. The schema for 17 × 17 grid modules of the pure Inception-v4 network.
#This is the Inception-B block of Figure 9."""
def __init__(self, input_channels):
super().__init__()
self.branch7x7stack = nn.Sequential(
BasicConv2d(input_channels, 192, kernel_size=1),
BasicConv2d(192, 192, kernel_size=(1, 7), padding=(0, 3)),
BasicConv2d(192, 224, kernel_size=(7, 1), padding=(3, 0)),
BasicConv2d(224, 224, kernel_size=(1, 7), padding=(0, 3)),
BasicConv2d(224, 256, kernel_size=(7, 1), padding=(3, 0))
)
self.branch7x7 = nn.Sequential(
BasicConv2d(input_channels, 192, kernel_size=1),
BasicConv2d(192, 224, kernel_size=(1, 7), padding=(0, 3)),
BasicConv2d(224, 256, kernel_size=(7, 1), padding=(3, 0))
)
self.branch1x1 = BasicConv2d(input_channels, 384, kernel_size=1)
self.branchpool = nn.Sequential(
nn.AvgPool2d(3, stride=1, padding=1),
BasicConv2d(input_channels, 128, kernel_size=1)
)
def forward(self, x):
x = [
self.branch1x1(x),
self.branch7x7(x),
self.branch7x7stack(x),
self.branchpool(x)
]
return torch.cat(x, 1)
class ReductionB(nn.Module):
#"""Figure 8. The schema for 17 × 17 to 8 × 8 grid-reduction mod- ule.
#This is the reduction module used by the pure Inception-v4 network in
#Figure 9."""
def __init__(self, input_channels):
super().__init__()
self.branch7x7 = nn.Sequential(
BasicConv2d(input_channels, 256, kernel_size=1),
BasicConv2d(256, 256, kernel_size=(1, 7), padding=(0, 3)),
BasicConv2d(256, 320, kernel_size=(7, 1), padding=(3, 0)),
BasicConv2d(320, 320, kernel_size=3, stride=2, padding=1)
)
self.branch3x3 = nn.Sequential(
BasicConv2d(input_channels, 192, kernel_size=1),
BasicConv2d(192, 192, kernel_size=3, stride=2, padding=1)
)
self.branchpool = nn.MaxPool2d(kernel_size=3, stride=2, padding=1)
def forward(self, x):
x = [
self.branch3x3(x),
self.branch7x7(x),
self.branchpool(x)
]
return torch.cat(x, 1)
class InceptionC(nn.Module):
def __init__(self, input_channels):
#"""Figure 6. The schema for 8×8 grid modules of the pure
#Inceptionv4 network. This is the Inception-C block of Figure 9."""
super().__init__()
self.branch3x3stack = nn.Sequential(
BasicConv2d(input_channels, 384, kernel_size=1),
BasicConv2d(384, 448, kernel_size=(1, 3), padding=(0, 1)),
BasicConv2d(448, 512, kernel_size=(3, 1), padding=(1, 0)),
)
self.branch3x3stacka = BasicConv2d(512, 256, kernel_size=(1, 3), padding=(0, 1))
self.branch3x3stackb = BasicConv2d(512, 256, kernel_size=(3, 1), padding=(1, 0))
self.branch3x3 = BasicConv2d(input_channels, 384, kernel_size=1)
self.branch3x3a = BasicConv2d(384, 256, kernel_size=(3, 1), padding=(1, 0))
self.branch3x3b = BasicConv2d(384, 256, kernel_size=(1, 3), padding=(0, 1))
self.branch1x1 = BasicConv2d(input_channels, 256, kernel_size=1)
self.branchpool = nn.Sequential(
nn.AvgPool2d(kernel_size=3, stride=1, padding=1),
BasicConv2d(input_channels, 256, kernel_size=1)
)
def forward(self, x):
branch3x3stack_output = self.branch3x3stack(x)
branch3x3stack_output = [
self.branch3x3stacka(branch3x3stack_output),
self.branch3x3stackb(branch3x3stack_output)
]
branch3x3stack_output = torch.cat(branch3x3stack_output, 1)
branch3x3_output = self.branch3x3(x)
branch3x3_output = [
self.branch3x3a(branch3x3_output),
self.branch3x3b(branch3x3_output)
]
branch3x3_output = torch.cat(branch3x3_output, 1)
branch1x1_output = self.branch1x1(x)
branchpool = self.branchpool(x)
output = [
branch1x1_output,
branch3x3_output,
branch3x3stack_output,
branchpool
]
return torch.cat(output, 1)
class InceptionV4(nn.Module):
def __init__(self, A, B, C, k=192, l=224, m=256, n=384, class_nums=100):
super().__init__()
self.stem = Inception_Stem(3)
self.inception_a = self._generate_inception_module(384, 384, A, InceptionA)
self.reduction_a = ReductionA(384, k, l, m, n)
output_channels = self.reduction_a.output_channels
self.inception_b = self._generate_inception_module(output_channels, 1024, B, InceptionB)
self.reduction_b = ReductionB(1024)
self.inception_c = self._generate_inception_module(1536, 1536, C, InceptionC)
self.avgpool = nn.AvgPool2d(7)
#"""Dropout (keep 0.8)"""
self.dropout = nn.Dropout2d(1 - 0.8)
self.linear = nn.Linear(1536, class_nums)
def forward(self, x):
x = self.stem(x)
x = self.inception_a(x)
x = self.reduction_a(x)
x = self.inception_b(x)
x = self.reduction_b(x)
x = self.inception_c(x)
x = self.avgpool(x)
x = self.dropout(x)
x = x.view(-1, 1536)
x = self.linear(x)
return x
@staticmethod
def _generate_inception_module(input_channels, output_channels, block_num, block):
layers = nn.Sequential()
for l in range(block_num):
layers.add_module("{}_{}".format(block.__name__, l), block(input_channels))
input_channels = output_channels
return layers
class InceptionResNetA(nn.Module):
#"""Figure 16. The schema for 35 × 35 grid (Inception-ResNet-A)
#module of the Inception-ResNet-v2 network."""
def __init__(self, input_channels):
super().__init__()
self.branch3x3stack = nn.Sequential(
BasicConv2d(input_channels, 32, kernel_size=1),
BasicConv2d(32, 48, kernel_size=3, padding=1),
BasicConv2d(48, 64, kernel_size=3, padding=1)
)
self.branch3x3 = nn.Sequential(
BasicConv2d(input_channels, 32, kernel_size=1),
BasicConv2d(32, 32, kernel_size=3, padding=1)
)
self.branch1x1 = BasicConv2d(input_channels, 32, kernel_size=1)
self.reduction1x1 = nn.Conv2d(128, 384, kernel_size=1)
self.shortcut = nn.Conv2d(input_channels, 384, kernel_size=1)
self.bn = nn.BatchNorm2d(384)
self.relu = nn.ReLU(inplace=True)
def forward(self, x):
residual = [
self.branch1x1(x),
self.branch3x3(x),
self.branch3x3stack(x)
]
residual = torch.cat(residual, 1)
residual = self.reduction1x1(residual)
shortcut = self.shortcut(x)
output = self.bn(shortcut + residual)
output = self.relu(output)
return output
class InceptionResNetB(nn.Module):
#"""Figure 17. The schema for 17 × 17 grid (Inception-ResNet-B) module of
#the Inception-ResNet-v2 network."""
def __init__(self, input_channels):
super().__init__()
self.branch7x7 = nn.Sequential(
BasicConv2d(input_channels, 128, kernel_size=1),
BasicConv2d(128, 160, kernel_size=(1, 7), padding=(0, 3)),
BasicConv2d(160, 192, kernel_size=(7, 1), padding=(3, 0))
)
self.branch1x1 = BasicConv2d(input_channels, 192, kernel_size=1)
self.reduction1x1 = nn.Conv2d(384, 1154, kernel_size=1)
self.shortcut = nn.Conv2d(input_channels, 1154, kernel_size=1)
self.bn = nn.BatchNorm2d(1154)
self.relu = nn.ReLU(inplace=True)
def forward(self, x):
residual = [
self.branch1x1(x),
self.branch7x7(x)
]
residual = torch.cat(residual, 1)
#"""In general we picked some scaling factors between 0.1 and 0.3 to scale the residuals
#before their being added to the accumulated layer activations (cf. Figure 20)."""
residual = self.reduction1x1(residual) * 0.1
shortcut = self.shortcut(x)
output = self.bn(residual + shortcut)
output = self.relu(output)
return output
class InceptionResNetC(nn.Module):
def __init__(self, input_channels):
#Figure 19. The schema for 8×8 grid (Inception-ResNet-C)
#module of the Inception-ResNet-v2 network."""
super().__init__()
self.branch3x3 = nn.Sequential(
BasicConv2d(input_channels, 192, kernel_size=1),
BasicConv2d(192, 224, kernel_size=(1, 3), padding=(0, 1)),
BasicConv2d(224, 256, kernel_size=(3, 1), padding=(1, 0))
)
self.branch1x1 = BasicConv2d(input_channels, 192, kernel_size=1)
self.reduction1x1 = nn.Conv2d(448, 2048, kernel_size=1)
self.shorcut = nn.Conv2d(input_channels, 2048, kernel_size=1)
self.bn = nn.BatchNorm2d(2048)
self.relu = nn.ReLU(inplace=True)
def forward(self, x):
residual = [
self.branch1x1(x),
self.branch3x3(x)
]
residual = torch.cat(residual, 1)
residual = self.reduction1x1(residual) * 0.1
shorcut = self.shorcut(x)
output = self.bn(shorcut + residual)
output = self.relu(output)
return output
class InceptionResNetReductionA(nn.Module):
#"""Figure 7. The schema for 35 × 35 to 17 × 17 reduction module.
#Different variants of this blocks (with various number of filters)
#are used in Figure 9, and 15 in each of the new Inception(-v4, - ResNet-v1,
#-ResNet-v2) variants presented in this paper. The k, l, m, n numbers
#represent filter bank sizes which can be looked up in Table 1.
def __init__(self, input_channels, k, l, m, n):
super().__init__()
self.branch3x3stack = nn.Sequential(
BasicConv2d(input_channels, k, kernel_size=1),
BasicConv2d(k, l, kernel_size=3, padding=1),
BasicConv2d(l, m, kernel_size=3, stride=2)
)
self.branch3x3 = BasicConv2d(input_channels, n, kernel_size=3, stride=2)
self.branchpool = nn.MaxPool2d(kernel_size=3, stride=2)
self.output_channels = input_channels + n + m
def forward(self, x):
x = [
self.branch3x3stack(x),
self.branch3x3(x),
self.branchpool(x)
]
return torch.cat(x, 1)
class InceptionResNetReductionB(nn.Module):
#"""Figure 18. The schema for 17 × 17 to 8 × 8 grid-reduction module.
#Reduction-B module used by the wider Inception-ResNet-v1 network in
#Figure 15."""
#I believe it was a typo(Inception-ResNet-v1 should be Inception-ResNet-v2)
def __init__(self, input_channels):
super().__init__()
self.branchpool = nn.MaxPool2d(3, stride=2)
self.branch3x3a = nn.Sequential(
BasicConv2d(input_channels, 256, kernel_size=1),
BasicConv2d(256, 384, kernel_size=3, stride=2)
)
self.branch3x3b = nn.Sequential(
BasicConv2d(input_channels, 256, kernel_size=1),
BasicConv2d(256, 288, kernel_size=3, stride=2)
)
self.branch3x3stack = nn.Sequential(
BasicConv2d(input_channels, 256, kernel_size=1),
BasicConv2d(256, 288, kernel_size=3, padding=1),
BasicConv2d(288, 320, kernel_size=3, stride=2)
)
def forward(self, x):
x = [
self.branch3x3a(x),
self.branch3x3b(x),
self.branch3x3stack(x),
self.branchpool(x)
]
x = torch.cat(x, 1)
return x
class InceptionResNetV2(nn.Module):
def __init__(self, A, B, C, k=256, l=256, m=384, n=384, class_nums=100):
super().__init__()
self.stem = Inception_Stem(3)
self.inception_resnet_a = self._generate_inception_module(384, 384, A, InceptionResNetA)
self.reduction_a = InceptionResNetReductionA(384, k, l, m, n)
output_channels = self.reduction_a.output_channels
self.inception_resnet_b = self._generate_inception_module(output_channels, 1154, B, InceptionResNetB)
self.reduction_b = InceptionResNetReductionB(1154)
self.inception_resnet_c = self._generate_inception_module(2146, 2048, C, InceptionResNetC)
#6x6 featuresize
self.avgpool = nn.AdaptiveAvgPool2d((1, 1))
#"""Dropout (keep 0.8)"""
self.dropout = nn.Dropout2d(1 - 0.8)
self.linear = nn.Linear(2048, class_nums)
def forward(self, x):
x = self.stem(x)
x = self.inception_resnet_a(x)
x = self.reduction_a(x)
x = self.inception_resnet_b(x)
x = self.reduction_b(x)
x = self.inception_resnet_c(x)
x = self.avgpool(x)
x = self.dropout(x)
x = x.view(-1, 2048)
x = self.linear(x)
return x
@staticmethod
def _generate_inception_module(input_channels, output_channels, block_num, block):
layers = nn.Sequential()
for l in range(block_num):
layers.add_module("{}_{}".format(block.__name__, l), block(input_channels))
input_channels = output_channels
return layers
def inceptionv4():
return InceptionV4(4, 7, 3)
def inception_resnet_v2():
return InceptionResNetV2(5, 10, 5)
Thực nghiệm
Hình dưới mô tả Top-5 error của cả 4 model. Nhận thấy rằng các model có sử dụng residual hội tụ nhanh hơn nhưng độ chính xác có vẻ vẫn phụ thuộc chính vào kích thước model.
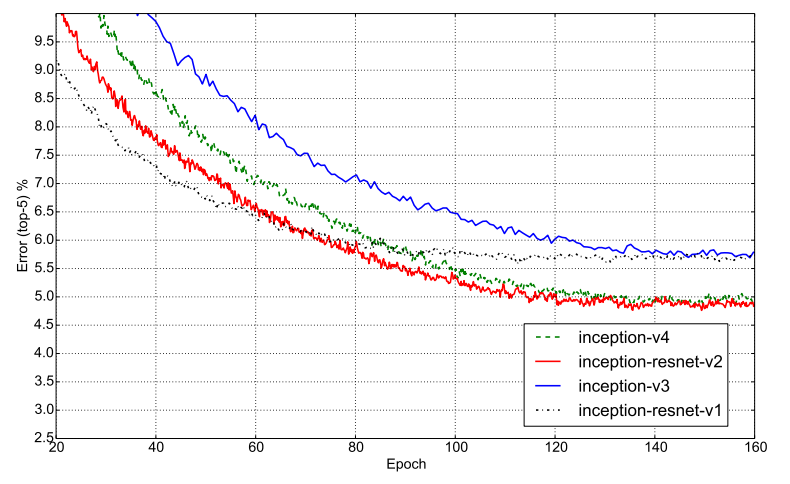
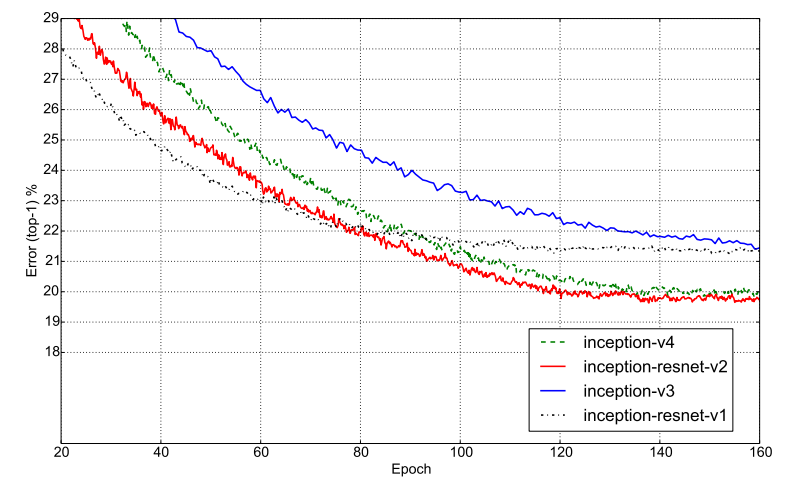
Tương tự, hình dưới là Top-1 error của 4 model.
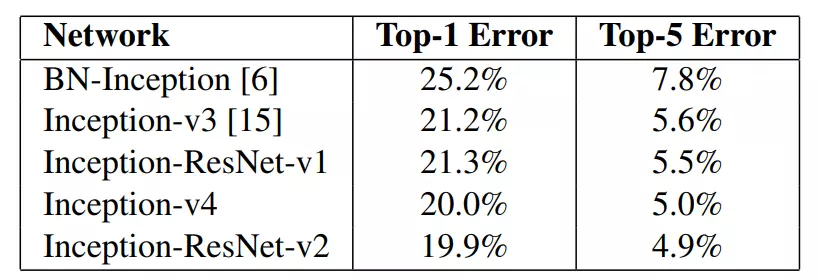
Cụ thể hơn, bảng dưới là kết quả chi tiết của thực nghiệm trên 4 model.
Tài liệu tham khảo
[1] Inception-v4, Inception-ResNet and the Impact of Residual Connections on Learning
[2] Review: Inception-v4 — Evolved From GoogLeNet, Merged with ResNet Idea (Image Classification)
All rights reserved
