Paper reading | CoAtNet: Marrying Convolution and Attention for All Data Sizes
Bài đăng này đã không được cập nhật trong 2 năm
Giới thiệu
Kể từ sự ra đời của AlexNet, mạng ConvNets đã trở thành một kiến trúc mô hình quan trọng trong lĩnh vực thị giác máy tính. Bên cạnh đó, với sự thành công của các mô hình self-attention như Transformers trong lĩnh vực xử lý ngôn ngữ tự nhiên, nhiều nghiên cứu trước đó đã có ý tưởng kết hợp sức mạnh của attention vào lĩnh vực thị giác máy tính. Mô hình ViT (Vision Transformer) đã chứng minh rằng chỉ cần sử dụng các lớp Transformer thông thường là có thể đạt được hiệu suất chấp nhận được trên tập dữ liệu ImageNet-1K. Đặc biệt, khi pretrained trên tập dữ liệu lớn với label yếu như JFT-300M, ViT đã đạt được kết quả tương đương với các mô hình SOTA ConvNets, cho thấy rằng các mô hình Transformer có hiệu suất tốt với các tập dữ liệu lớn so với ConvNets.
Tuy nhiên, đây cũng lại là điểm yếu của các mô hình Transformer so với ConvNets. Nếu như trong bộ dữ liệu nhỏ, cho dù sử dụng các kĩ thuật regularization hay data augmentation mạnh, các biến thể của ViT vẫn không thể vượt qua các mô hình SOTA chỉ sử dụng convolution với cùng lượng dữ liệu và tài nguyên tính toán. Điều này cho thấy rằng, các layer Transformer thiếu inductive bias nhất định so với ConvNets và do đó cần nhiều data hơn để bù đắp phần thiếu sót này.
Đóng góp của bài báo
Trong bài báo nhóm tác giả nghiên cứu về vấn đề kết hợp convolution và attention từ 2 khía cạnh là tính tổng quát và model capacity. Bài báo cho thấy rằng các layer convolutional có xu hướng tổng quát và tốc độ hội tụ nhanh hơn do sức mạnh inductive bias. Trong khi đó, các layer attention có model capacity cao hơn và có thể có lợi khi sử dụng tập dữ liệu lớn. Kết hợp 2 thành phần này cho ta cả 2 lợi ích về tính tổng quát và capacity. Tuy nhiên, vấn đề là kết hợp 2 thành phần như nào để đạt hiệu suất tối ưu nhất. Từ đó, bài báo đề xuất kiến trúc mô hình có tên CoAtNet, là kết hợp sức mạnh của cả ConvNets và Transformer.
Chi tiết mô hình
Để thiết kế mô hình CoAtNet, ta cần trả lời 2 câu hỏi sau:
- Làm như nào để kết hợp convolution và self-attention thành 1 block trong mô hình.
- Cần stack các block trên như nào để thành một mô hình hoàn chỉnh.
Kết hợp convolution và self-attention
Nhóm tác giả sử dụng MBConv block (Mobile convolution block) cho mô hình. Lý do sử dụng MBConv block đó là do module FFN trong Transformer và MBConv sử dụng thiết kế "inverted bottleneck". "Inverted bottleneck" mô tả quá trình tăng kích thước kênh của input lên gấp 4 lần, sau đó chiếu hidden-state đó về kích thước ban đầu để thực hiện residual connection.
Bên cạnh sự tương tự về inverted bottleneck, cả hai depthwise convolution và self-attention có khả năng biểu diễn thông tin dưới dạng tổng trọng số theo từng chiều (per-dimension weighted sum) của giá trị trong một receptive field. Receptive field là một phạm vi không gian của dữ liệu mà mô hình sử dụng để thu thập thông tin. Cụ thể, depthwise convolution sử dụng một kernel cố định để thu thập thông tin từ một local receptive field, trong khi self-attention trong mô hình Transformer cũng thực hiện một phép tổng trọng số theo từng chiều dựa trên các trọng số học được từ dữ liệu. Tổng trọng số trong depthwise convolution được thể hiện trong công thức sau:
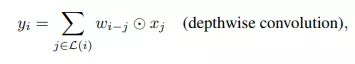
trong đó là input và output tại vị trí tương ứng. là local neighborhood của .
Đối với self-attention, receptive field ở đây là toàn bộ vị trí trong không gian được tính trọng số dựa vào các cặp tương đương đồng được chuẩn hóa
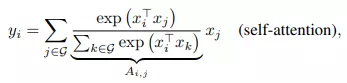
trong đó là spatial space toàn cục.
Trước khi đi vào cách kết hợp 2 thành phần này, ta cần so sánh ưu và nhược điểm của chúng, điều này giúp ta biết được xem là thuộc tính nào tốt cần duy trì 
-
Sự Khác Biệt về Khả Năng Tính Toán:
-
Self-Attention: Trong self-attention, trọng số attention (attention weight) được tính động (dynamically) dựa trên biểu diễn của dữ liệu đầu vào. Điều này cho phép self-attention bắt được các mối tương tác phức tạp giữa các vị trí không gian khác nhau. Điều này đặc biệt hữu ích khi xử lý các khái niệm cấp cao (high-level concept) trong dữ liệu. Tuy nhiên, điều này cũng có nguy cơ dễ gây overfitting, đặc biệt khi dữ liệu huấn luyện hạn chế.
-
Convolution: Trong tích chập, kernel convolution là một tham số độc lập với đầu vào và có giá trị tĩnh (static value). Kernel này chỉ quan tâm đến sự tương quan giữa các vị trí không gian (được biểu thị bằng ). Điều này giúp conv thực hiện việc gọi là "translation equivalence", nghĩa là conv có khả năng tổng quát hóa tốt hơn khi lượng dữ liệu huấn luyện hạn chế.
-
-
Khác Biệt về Receptive Field:
-
Self-Attention: Mạng self-attention thường có khả năng bao gồm toàn bộ receptive field (phạm vi nhận thức) của dữ liệu, tức là nó có khả năng thu thập thông tin từ tất cả các vị trí không gian. Điều này giúp mô hình hiểu bối cảnh rộng hơn và có khả năng biểu diễn thông tin phức tạp. Tuy nhiên, việc tính toán tổng thể sẽ đòi hỏi nhiều tài nguyên tính toán.
-
Convolution: Convolution có khả năng thu thập thông tin trong một receptive field cố định, có thể bao gồm một phạm vi không gian nhỏ hơn. Điều này có thể giới hạn khả năng của mô hình trong việc hiểu bối cảnh rộng hơn, nhưng có thể giảm đáng kể tải tính toán.
-

Bảng trên là những thuộc tính mà ta mong muốn cho kiến trúc mới. Dựa vào các công thức depthwise convolution và self-attention, ta có thể có 2 ý tưởng để kết hợp những thuộc tính mong muốn trên đó là tính tổng của global static convolution kernel với adaptive attention matrix sau đó, việc tính tổng có thể thực hiện trước hoặc sau khi đi qua softmax.
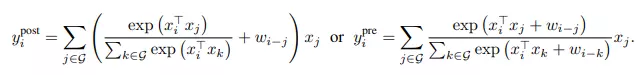
Thiết kế mô hình
Sau khi tìm được cách kết hợp convolution và attention, trong phần này ta sẽ xem xét cách sử dụng nó để tạo thành một mạng hoàn chỉnh.
Vì global context có độ phức tạp bậc 2 của spatial size, nếu ta sử dụng trực tiếp relative attention trong công thức trên với ảnh thô input ban đầu thì thời gian tính toán sẽ rất chậm do có một lượng lớn pixel của ảnh với kích thước phổ biến. Vì vậy, ta cần xây dựng một kiến trúc mạng khả thi hơn, nhóm tác giả đưa ra 3 phương án sau:
- Thực hiện down-sampling để giảm spatial size và sử dụng global relative attention sau khi feature map đạt được mức độ hợp lý.
- Sử dụng local attention thay vì global receptive field trong attention, ý tưởng này giống như trong convolution.
- Thay Softmax attention với độ phức tạp bậc 2 bằng biến thể linear attention, biến thể này chỉ có độ phức tạp bậc 2 so với spatial size.
Nhóm tác giả đã thực nghiệm cả 3 phương pháp trên để chọn ra phương pháp khả thi nhất. Đầu tiên, với phương pháp thứ 3, nhóm tác giả không thu được kết quả tốt. Với phương pháp thứ 2, nhóm tác giả gặp khó khăn trong việc triển khai local attention. Việc triển khai này đòi hỏi rất nhiều phép biến đổi hình dạng (shape formatting operations) phức tạp và yêu cầu truy cập bộ nhớ một cách tập trung. Mô hình sử dụng TPU (Tensor Processing Unit) cho tính toán, và trên nền TPU, các phép toán này trở nên cực kỳ chậm. Cuối cùng, nhóm tác giả đi tới lựa chọn đầu tiên đó là thực hiện down-sampling. Cụ thể, để thực hiện phương pháp này ta có 2 cách tiếp cận như sau:
- Sử dụng một lớp convolution với stride lớn (stride 16x16) như trong ViT.
- Sử dụng Multi-stage network với gradual pooling giống như ConvNets.
Với 2 cách tiếp cận trên, nhóm tác giả đưa ra 5 biến thể và so sánh hiệu suất của 5 biến thể này bằng thực nghiệm:
-
Với cách tiếp cận đầu tiên, nhóm tác giả thực hiện stack block Transformer, được biểu thị là .
-
Với cách tiếp cận thứ hai, nhóm tác giả bắt chước ConvNets xây dựng một mạng gồm 5 stage (S0, S1, S2, S3 và S4) với spatial resolution giảm dần dần từ S0 tới S4. Tại bắt đầu của mỗi stage, ta thực hiện giảm spatial size đi 2 lần và tăng số lượng channel. Stage S0 sử dụng 2 layer Conv và S1 luôn luôn sử dụng MBConv block với squeeze-excitation (SE), lý do là spatial size quá lớn để sử dụng global attention. Nhóm tác giả xem xét việc sử dụng các block MBConv và block Transformer trong mạng từ stage S2 đến S4 và áp đặt một ràng buộc quan trọng về thứ tự xuất hiện của các tầng Convolution và Transformer. Các biến thể này được xây dựng dựa trên giả định rằng Conv thích hợp hơn trong việc xử lý các mẫu cục bộ mà thường xuất hiện ở các stage đầu của mạng. Điều này dẫn đến sự xuất hiện của 4 biến thể với số lượng tầng Transformer ngày càng tăng như sau:
-
C-C-C-C: Trong biến thể này, tất cả các stage từ S2 đến S4 đều sử dụng block Convolution (C). Không có block Transformer nào xuất hiện.
-
C-C-C-T: Trong biến thể này, hai stage đầu S2 và S3 sử dụng block Convolution (C), sau đó stage cuối S4 sử dụng block Transformer (T).
-
C-C-T-T: Ở biến thể này, stage S2 sử dụng block Convolution (C), stage S3 sử dụng block Convolution (C), và hai stage cuối S4 sử dụng khối Transformer (T).
-
C-T-T-T: Cuối cùng, trong biến thể này, stage S2 sử dụng block Convolution (C), sau đó cả ba stage cuối S3, S4 sử dụng block Transformer (T).
Nhóm tác giả tiến hành một nghiên cứu hệ thống về các lựa chọn thiết kế trong mô hình. Họ tập trung vào hai khía cạnh quan trọng: khả năng tổng quát hóa và model capacity.
-
Khả năng Tổng Quát Hóa (Generalization Capability): Đây là khả năng tổng quát hóa của mô hình từ dữ liệu train sang dữ liệu test (hoặc val). Tức là mô hình có khả năng hoạt động tốt trên dữ liệu mà nó chưa từng thấy trước đó. Để đánh giá khả năng tổng quát, tác giả xem xét sự khác nhau giữa training loss và độ chính xác trong quá trình đánh giá. Nếu hai mô hình có cùng training loss, mô hình có độ chính xác cao hơn trong quá trình đánh giá được xem là có khả năng tổng quát hóa tốt hơn, vì nó có khả năng tổng quát hóa tốt hơn đối với dữ liệu đánh giá mà nó chưa từng thấy. Khả năng tổng quát hóa quan trọng, đặc biệt khi kích thước của tập dữ liệu huấn luyện có hạn.
-
Model Capacity: Đây là khả năng của một mô hình để phù hợp với tập dữ liệu huấn luyện lớn. Khi tập dữ liệu huấn luyện là một tập dữ liệu lớn và không gặp vấn đề về overfitting, mô hình có capacity lớn hơn sẽ đạt được hiệu suất cuối cùng tốt hơn sau một số bước huấn luyện hợp lý. Tuy nhiên, để có thể so sánh mô hình về khả năng tổng quát hóa và model capacity một cách có ý nghĩa, tác giả đảm bảo rằng kích thước mô hình của 5 biến thể là tương đương.
Để so sánh khả năng tổng quát hóa và model capacity, nhóm tác giả đã huấn luyện các biến thể khác nhau của mô hình trên tập dữ liệu ImageNet-1K và JFT. Sau đó, họ tiến hành đánh giá thông qua training loss và evaluation accuracy. Kết quả của quá trình huấn luyện và đánh giá trên cả hai tập dữ liệu được trình bày trong hình dưới.
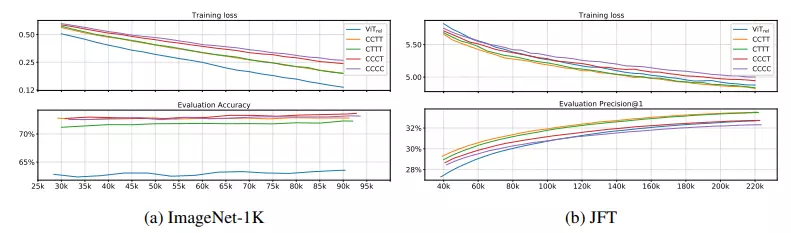
Bảng xếp hạng theo khả năng tổng quát và model capacity lần lượt như sau:
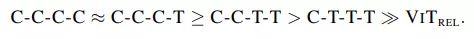
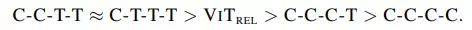
Từ 2 kết quả trên, để quyết định xem nên chọn C-C-T-T hay C-T-T-T, nhóm tác giả tiến hành bài kiểm tra transferability tức là so sánh hiệu suất 2 biến thể khi thực hiện transfer learning. Kết quả như sau:

Cuối cùng, nhóm tác giả chọn C-C-T-T làm kiến trúc mô hình cuối cùng, ta có sơ đồ kiến trúc của mô hình CoAtNet như sau:

Coding
import torch
import torch.nn as nn
from einops import rearrange
from einops.layers.torch import Rearrange
def conv_3x3_bn(inp, oup, image_size, downsample=False):
stride = 1 if downsample == False else 2
return nn.Sequential(
nn.Conv2d(inp, oup, 3, stride, 1, bias=False),
nn.BatchNorm2d(oup),
nn.GELU()
)
class PreNorm(nn.Module):
def __init__(self, dim, fn, norm):
super().__init__()
self.norm = norm(dim)
self.fn = fn
def forward(self, x, **kwargs):
return self.fn(self.norm(x), **kwargs)
class SE(nn.Module):
def __init__(self, inp, oup, expansion=0.25):
super().__init__()
self.avg_pool = nn.AdaptiveAvgPool2d(1)
self.fc = nn.Sequential(
nn.Linear(oup, int(inp * expansion), bias=False),
nn.GELU(),
nn.Linear(int(inp * expansion), oup, bias=False),
nn.Sigmoid()
)
def forward(self, x):
b, c, _, _ = x.size()
y = self.avg_pool(x).view(b, c)
y = self.fc(y).view(b, c, 1, 1)
return x * y
class FeedForward(nn.Module):
def __init__(self, dim, hidden_dim, dropout=0.):
super().__init__()
self.net = nn.Sequential(
nn.Linear(dim, hidden_dim),
nn.GELU(),
nn.Dropout(dropout),
nn.Linear(hidden_dim, dim),
nn.Dropout(dropout)
)
def forward(self, x):
return self.net(x)
class MBConv(nn.Module):
def __init__(self, inp, oup, image_size, downsample=False, expansion=4):
super().__init__()
self.downsample = downsample
stride = 1 if self.downsample == False else 2
hidden_dim = int(inp * expansion)
if self.downsample:
self.pool = nn.MaxPool2d(3, 2, 1)
self.proj = nn.Conv2d(inp, oup, 1, 1, 0, bias=False)
if expansion == 1:
self.conv = nn.Sequential(
# dw
nn.Conv2d(hidden_dim, hidden_dim, 3, stride,
1, groups=hidden_dim, bias=False),
nn.BatchNorm2d(hidden_dim),
nn.GELU(),
# pw-linear
nn.Conv2d(hidden_dim, oup, 1, 1, 0, bias=False),
nn.BatchNorm2d(oup),
)
else:
self.conv = nn.Sequential(
# pw
# down-sample in the first conv
nn.Conv2d(inp, hidden_dim, 1, stride, 0, bias=False),
nn.BatchNorm2d(hidden_dim),
nn.GELU(),
# dw
nn.Conv2d(hidden_dim, hidden_dim, 3, 1, 1,
groups=hidden_dim, bias=False),
nn.BatchNorm2d(hidden_dim),
nn.GELU(),
SE(inp, hidden_dim),
# pw-linear
nn.Conv2d(hidden_dim, oup, 1, 1, 0, bias=False),
nn.BatchNorm2d(oup),
)
self.conv = PreNorm(inp, self.conv, nn.BatchNorm2d)
def forward(self, x):
if self.downsample:
return self.proj(self.pool(x)) + self.conv(x)
else:
return x + self.conv(x)
class Attention(nn.Module):
def __init__(self, inp, oup, image_size, heads=8, dim_head=32, dropout=0.):
super().__init__()
inner_dim = dim_head * heads
project_out = not (heads == 1 and dim_head == inp)
self.ih, self.iw = image_size
self.heads = heads
self.scale = dim_head ** -0.5
# parameter table of relative position bias
self.relative_bias_table = nn.Parameter(
torch.zeros((2 * self.ih - 1) * (2 * self.iw - 1), heads))
coords = torch.meshgrid((torch.arange(self.ih), torch.arange(self.iw)))
coords = torch.flatten(torch.stack(coords), 1)
relative_coords = coords[:, :, None] - coords[:, None, :]
relative_coords[0] += self.ih - 1
relative_coords[1] += self.iw - 1
relative_coords[0] *= 2 * self.iw - 1
relative_coords = rearrange(relative_coords, 'c h w -> h w c')
relative_index = relative_coords.sum(-1).flatten().unsqueeze(1)
self.register_buffer("relative_index", relative_index)
self.attend = nn.Softmax(dim=-1)
self.to_qkv = nn.Linear(inp, inner_dim * 3, bias=False)
self.to_out = nn.Sequential(
nn.Linear(inner_dim, oup),
nn.Dropout(dropout)
) if project_out else nn.Identity()
def forward(self, x):
qkv = self.to_qkv(x).chunk(3, dim=-1)
q, k, v = map(lambda t: rearrange(
t, 'b n (h d) -> b h n d', h=self.heads), qkv)
dots = torch.matmul(q, k.transpose(-1, -2)) * self.scale
# Use "gather" for more efficiency on GPUs
relative_bias = self.relative_bias_table.gather(
0, self.relative_index.repeat(1, self.heads))
relative_bias = rearrange(
relative_bias, '(h w) c -> 1 c h w', h=self.ih*self.iw, w=self.ih*self.iw)
dots = dots + relative_bias
attn = self.attend(dots)
out = torch.matmul(attn, v)
out = rearrange(out, 'b h n d -> b n (h d)')
out = self.to_out(out)
return out
class Transformer(nn.Module):
def __init__(self, inp, oup, image_size, heads=8, dim_head=32, downsample=False, dropout=0.):
super().__init__()
hidden_dim = int(inp * 4)
self.ih, self.iw = image_size
self.downsample = downsample
if self.downsample:
self.pool1 = nn.MaxPool2d(3, 2, 1)
self.pool2 = nn.MaxPool2d(3, 2, 1)
self.proj = nn.Conv2d(inp, oup, 1, 1, 0, bias=False)
self.attn = Attention(inp, oup, image_size, heads, dim_head, dropout)
self.ff = FeedForward(oup, hidden_dim, dropout)
self.attn = nn.Sequential(
Rearrange('b c ih iw -> b (ih iw) c'),
PreNorm(inp, self.attn, nn.LayerNorm),
Rearrange('b (ih iw) c -> b c ih iw', ih=self.ih, iw=self.iw)
)
self.ff = nn.Sequential(
Rearrange('b c ih iw -> b (ih iw) c'),
PreNorm(oup, self.ff, nn.LayerNorm),
Rearrange('b (ih iw) c -> b c ih iw', ih=self.ih, iw=self.iw)
)
def forward(self, x):
if self.downsample:
x = self.proj(self.pool1(x)) + self.attn(self.pool2(x))
else:
x = x + self.attn(x)
x = x + self.ff(x)
return x
class CoAtNet(nn.Module):
def __init__(self, image_size, in_channels, num_blocks, channels, num_classes=1000, block_types=['C', 'C', 'T', 'T']):
super().__init__()
ih, iw = image_size
block = {'C': MBConv, 'T': Transformer}
self.s0 = self._make_layer(
conv_3x3_bn, in_channels, channels[0], num_blocks[0], (ih // 2, iw // 2))
self.s1 = self._make_layer(
block[block_types[0]], channels[0], channels[1], num_blocks[1], (ih // 4, iw // 4))
self.s2 = self._make_layer(
block[block_types[1]], channels[1], channels[2], num_blocks[2], (ih // 8, iw // 8))
self.s3 = self._make_layer(
block[block_types[2]], channels[2], channels[3], num_blocks[3], (ih // 16, iw // 16))
self.s4 = self._make_layer(
block[block_types[3]], channels[3], channels[4], num_blocks[4], (ih // 32, iw // 32))
self.pool = nn.AvgPool2d(ih // 32, 1)
self.fc = nn.Linear(channels[-1], num_classes, bias=False)
def forward(self, x):
x = self.s0(x)
x = self.s1(x)
x = self.s2(x)
x = self.s3(x)
x = self.s4(x)
x = self.pool(x).view(-1, x.shape[1])
x = self.fc(x)
return x
def _make_layer(self, block, inp, oup, depth, image_size):
layers = nn.ModuleList([])
for i in range(depth):
if i == 0:
layers.append(block(inp, oup, image_size, downsample=True))
else:
layers.append(block(oup, oup, image_size))
return nn.Sequential(*layers)
def coatnet_0():
num_blocks = [2, 2, 3, 5, 2] # L
channels = [64, 96, 192, 384, 768] # D
return CoAtNet((224, 224), 3, num_blocks, channels, num_classes=1000)
def coatnet_1():
num_blocks = [2, 2, 6, 14, 2] # L
channels = [64, 96, 192, 384, 768] # D
return CoAtNet((224, 224), 3, num_blocks, channels, num_classes=1000)
def coatnet_2():
num_blocks = [2, 2, 6, 14, 2] # L
channels = [128, 128, 256, 512, 1026] # D
return CoAtNet((224, 224), 3, num_blocks, channels, num_classes=1000)
def coatnet_3():
num_blocks = [2, 2, 6, 14, 2] # L
channels = [192, 192, 384, 768, 1536] # D
return CoAtNet((224, 224), 3, num_blocks, channels, num_classes=1000)
def coatnet_4():
num_blocks = [2, 2, 12, 28, 2] # L
channels = [192, 192, 384, 768, 1536] # D
return CoAtNet((224, 224), 3, num_blocks, channels, num_classes=1000)
def count_parameters(model):
return sum(p.numel() for p in model.parameters() if p.requires_grad)
if __name__ == '__main__':
img = torch.randn(1, 3, 224, 224)
net = coatnet_0()
out = net(img)
print(out.shape, count_parameters(net))
net = coatnet_1()
out = net(img)
print(out.shape, count_parameters(net))
net = coatnet_2()
out = net(img)
print(out.shape, count_parameters(net))
net = coatnet_3()
out = net(img)
print(out.shape, count_parameters(net))
net = coatnet_4()
out = net(img)
print(out.shape, count_parameters(net))
Thực nghiệm
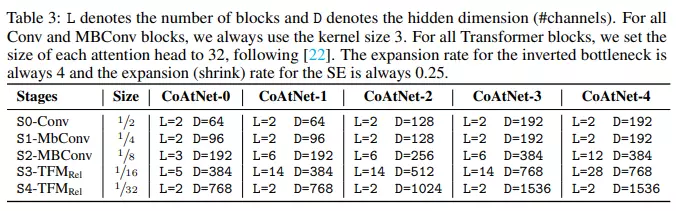
Bảng dưới là thông tin các phiên bản của CoAtNet.
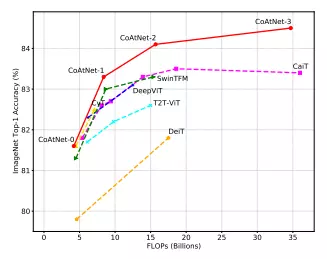
Hình dưới là so sánh độ chính xác tương ứng với FLOPs của mô hình CoAtNet so với các mô hình SOTA khác.
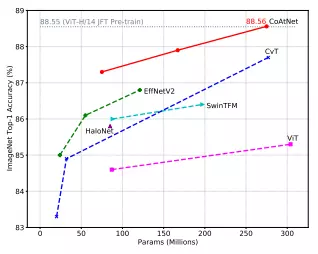
Hình dưới là so sánh độ chính xác tương ứng với lượng tham số của mô hình CoAtNet so với các mô hình SOTA khác.
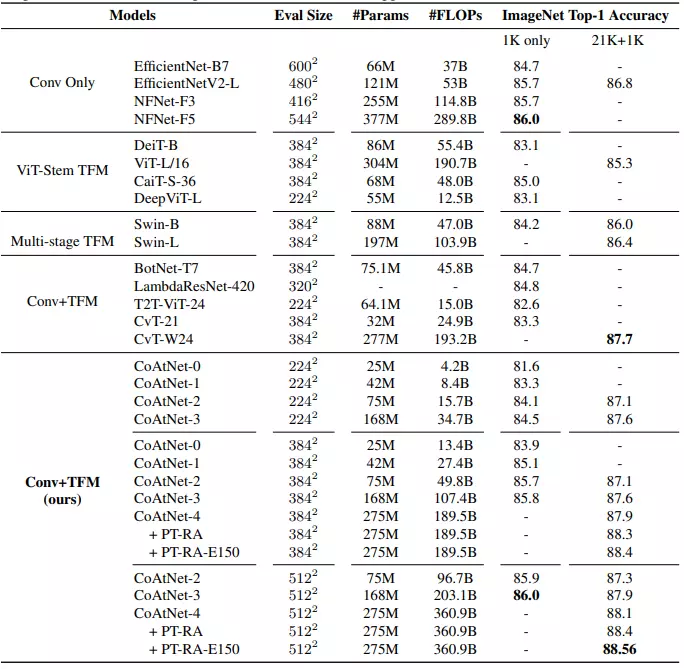
Bảng dưới là kết quả giữa các model trên tập dữ liệu ImageNet-1K và pretrained trên ImageNet-21K + finetuning trên ImageNet-1K.
Tham khảo
[1] CoAtNet: Marrying Convolution and Attention for All Data Sizes
All rights reserved
