[Paper Explained]-Retrieval Augmented Generation for Large Language Models: A Survey
1. Giới Thiệu
Nếu bạn đang muốn học về Retrieval-Augmented Generation (RAG) và bị choáng ngợp không biết bắt đầu từ đâu, đọc từ paper nào, có các kĩ thuật gì trong RAG, RAG đã phát triển như nào qua từng giai đoạn,.. thì paper "Retrieval Augmented Generation for Large Language Models: A Survey" sẽ là sự lựa chọn hoàn hảo cho một newbie muốn tìm hiểu về RAG. Nếu bạn muốn tiết kiệm thời gian và chỉ muốn đọc những ý chính thì blog hôm nay mình viết sẽ tóm lược những ý chính mà paper muốn truyền tải.
Trong thời đại AI phát triển mạnh mẽ, các mô hình ngôn ngữ lớn (Large Language Models - LLMs) đã thể hiện những khả năng ấn tượng. Tuy nhiên, chúng vẫn phải đối mặt với nhiều thách thức quan trọng như:
- Hallucination (tạo ra nội dung sai)
- Kiến thức lỗi thời
- Thiếu tính minh bạch trong quá trình suy luận Retrieval-Augmented Generation (RAG) đã xuất hiện như một giải pháp đầy hứa hẹn bằng cách tích hợp kiến thức từ cơ sở dữ liệu bên ngoài. Điều này giúp chúng ta giải quyết được các vấn đề:
- Tăng độ chính xác và độ tin cậy của nội dung được tạo ra
- Cập nhật kiến thức liên tục
- Tích hợp thông tin chuyên biệt
2. Hành Trình Phát Triển Của RAG
RAG đã trải qua một hành trình phát triển thú vị với hai giai đoạn quan trọng như hình bên dưới:
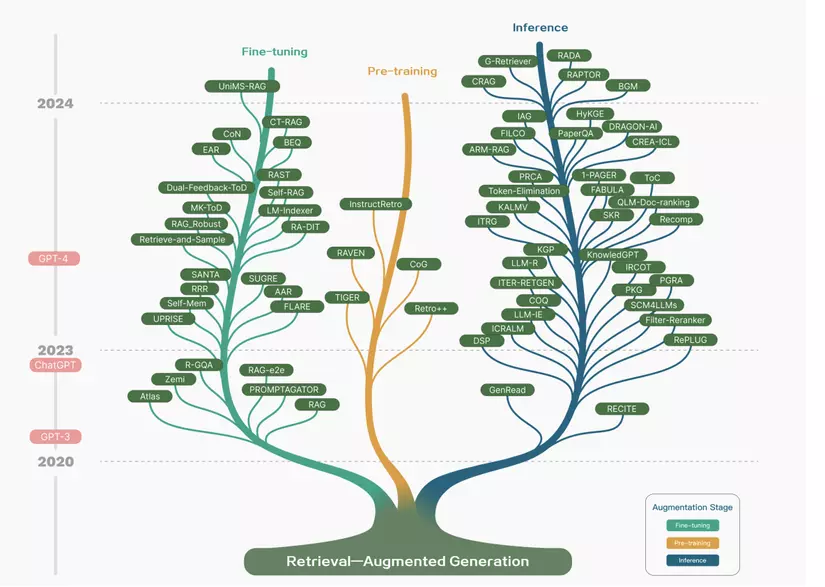
Giai đoạn 1: Thời kỳ đầu với Transformer
Khi RAG mới ra đời, nó gắn liền với sự phát triển của kiến trúc Transformer - một bước đột phá trong lĩnh vực AI. Lúc này, các nhà nghiên cứu tập trung vào việc cải thiện khả năng của mô hình ngôn ngữ thông qua quá trình tiền huấn luyện (pre-training). Đơn giản hóa, họ cố gắng "dạy" cho mô hình nhiều kiến thức hơn trước khi nó bắt đầu thực hiện các nhiệm vụ cụ thể.
Giai đoạn 2: Kỷ nguyên ChatGPT
Sự xuất hiện của ChatGPT đã tạo ra một bước ngoặt lớn. ChatGPT cho thấy khả năng tuyệt vời trong việc học và hiểu ngữ cảnh (in-context learning). Điều này đã thúc đẩy nghiên cứu RAG theo một hướng mới:
- Tập trung vào việc cung cấp thông tin chất lượng cao hơn cho các mô hình ngôn ngữ lớn
- Giúp các mô hình trả lời được những câu hỏi phức tạp hơn
- Xử lý được các tác vụ đòi hỏi nhiều kiến thức chuyên môn
Sự thay đổi này giống như việc nâng cấp từ một "thư viện sách cố định" sang một "hệ thống tra cứu thông minh", nơi mô hình có thể chủ động tìm kiếm và sử dụng thông tin mới để đưa ra câu trả lời chính xác hơn. Kết quả là, lĩnh vực nghiên cứu RAG đã phát triển nhanh chóng, mang lại nhiều tiến bộ đáng kể trong việc cải thiện khả năng của các mô hình ngôn ngữ lớn.
3. Ba Thế Hệ phát Triển Của RAG
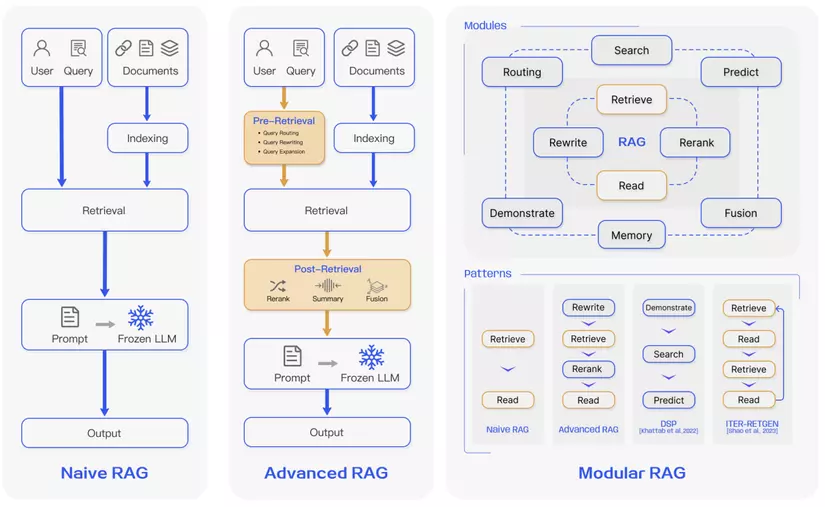
3.1. Naive RAG: Thế hệ đầu tiên
Đây là phiên bản RAG cơ bản nhất, xuất hiện ngay sau thời kỳ ChatGPT bùng nổ. Quy trình hoạt động gồm 3 bước chính:
-
Indexing (Lập chỉ mục):
- Chuyển đổi dữ liệu từ nhiều định dạng (PDF, HTML, Word) thành văn bản thuần túy
- Chia nhỏ văn bản thành các đoạn dễ xử lý
- Chuyển các đoạn văn thành vector và lưu trong cơ sở dữ liệu
-
Retrieval (Thu thập):
- Chuyển câu hỏi người dùng thành vector
- Tìm kiếm các đoạn văn tương tự nhất
- Chọn ra top K đoạn văn liên quan nhất
-
Generation (Sinh nội dung):
- Kết hợp câu hỏi với các đoạn văn đã chọn
- Tạo câu trả lời dựa trên ngữ cảnh mở rộng này
Tuy nhiên, Naive RAG còn một số hạn chế như:
- Thu thập thông tin không chính xác hoặc thiếu sót
- Đôi khi tạo ra nội dung sai lệch (hallucination)
- Khó tích hợp thông tin một cách mạch lạc
3.2. Advanced RAG: Cải tiến toàn diện
Advanced RAG được phát triển để khắc phục những điểm yếu của thế hệ đầu thông qua hai cải tiến chính:
-Pre-retrieval (Tiền xử lý):
Tối ưu cấu trúc indexing
- Nâng Cao Độ Chi Tiết Dữ Liệu: Advanced RAG sử dụng các kỹ thuật phân đoạn nâng cao như cửa sổ trượt và phân đoạn chi tiết để tạo ra các đoạn văn bản đại diện tốt hơn cho nội dung ngữ nghĩa:
- Cửa sổ trượt (Sliding Window) Kỹ thuật này chia văn bản thành các đoạn văn bản có độ dài cố định, được gọi là "cửa sổ". Cửa sổ này trượt dọc theo văn bản, với mỗi bước di chuyển tạo ra một đoạn văn bản mới. Kích thước của cửa sổ (số lượng token) và bước trượt (số lượng token di chuyển mỗi lần) là các tham số cần được điều chỉnh tùy theo loại văn bản và mục tiêu của ứng dụng.
- Phân đoạn chi tiết (Fine-grained Segmentation):Không giống như cửa sổ trượt, phân đoạn chi tiết không chia văn bản theo độ dài cố định. Thay vào đó, kỹ thuật này sử dụng các tiêu chí ngữ nghĩa để xác định ranh giới của các đoạn. Ví dụ, phân đoạn chi tiết có thể dựa vào cấu trúc câu, cụm từ, hoặc các dấu hiệu ngữ nghĩa khác để tạo ra các đoạn văn bản có ý nghĩa hoàn chỉnh.
- Tối Ưu Hóa Cấu Trúc Chỉ Mục: Các phương pháp như chỉ mục phân cấp và chỉ mục dựa trên đồ thị tri thức được sử dụng để tổ chức tài liệu hiệu quả hơn, cho phép truy xuất nhanh hơn và giảm thiểu khả năng tạo ra thông tin sai lệch.
- Thêm Siêu Dữ Liệu: Advanced RAG làm giàu các đoạn văn bản với siêu dữ liệu (ví dụ: số trang, tên tệp, tác giả, danh mục, dấu thời gian) để hỗ trợ lọc trong quá trình truy xuất và đảm bảo thông tin được cập nhật.
- Tối Ưu Hóa Căn Chỉnh: Sử dụng kỹ thuật Reverse HyDE, trong đó LLM tạo ra các câu hỏi giả định có thể được trả lời bởi tài liệu, giúp giảm khoảng cách ngữ nghĩa giữa câu hỏi và câu trả lời trong quá trình truy xuất. HyDE (Hypothetical Document Embeddings) là một kỹ thuật chuyển đổi truy vấn thay vì tìm kiếm sự tương đồng trực tiếp giữa truy vấn và tài liệu, HyDE tập trung vào sự tương đồng giữa các câu trả lời.
- Truy Xuất Kết Hợp: Kết hợp các phương pháp truy xuất thưa thớt (sparse encoder) (ví dụ: BM25) và dày đặc (dense encoder) (ví dụ: BERT) để tận dụng các điểm mạnh của cả hai phương pháp và cải thiện khả năng truy xuất tổng thể.
Tối ưu câu query
- Viết lại câu hỏi cho rõ ràng hơn : Sử dụng LLM hoặc các mô hình ngôn ngữ nhỏ hơn để viết lại truy vấn, làm cho nó rõ ràng và phù hợp hơn cho việc query.
- Chuyển đổi truy vấn: Áp dụng kỹ thuật prompt engineering để LLM tạo ra một query mới dựa trên truy vấn ban đầu, hoặc sử dụng phương pháp HyDE để tập trung vào sự tương đồng nhúng giữa các câu trả lời giả định.
- Mở rộng câu truy vấn: Mở rộng truy vấn ban đầu thành nhiều truy vấn để cung cấp thêm ngữ cảnh và đảm bảo mức độ liên quan tối ưu.
- Truy Vấn Con: Chia nhỏ câu hỏi phức tạp thành các câu hỏi con đơn giản hơn để LLM xử lý dễ dàng hơn.
- Chuỗi Xác Minh: Các truy vấn mở rộng được LLM xác thực để giảm thiểu khả năng tạo ra thông tin sai lệch.
- Định tuyến truy vấn: Hướng các truy vấn đến các pipeline RAG khác nhau dựa trên nội dung của truy vấn, phù hợp với hệ thống RAG linh hoạt xử lý nhiều tình huống.
- Bộ Định Tuyến Siêu Dữ Liệu/ Bộ Lọc: Trích xuất từ khóa từ truy vấn và lọc dựa trên siêu dữ liệu của các đoạn văn bản để thu hẹp phạm vi tìm kiếm.
- Bộ Định Tuyến Ngữ Nghĩa: Sử dụng thông tin ngữ nghĩa của truy vấn để định tuyến đến pipeline RAG phù hợp.
-Post-retrieval (Hậu xử lý):
Sắp xếp lại thứ tự các đoạn văn theo độ liên quan (reranking)
Sử dụng các kỹ thuật sắp xếp lại để ưu tiên các đoạn văn bản có liên quan nhất, giúp LLM tập trung vào thông tin quan trọng và giảm bớt nhiễu.
- Dựa trên Quy Tắc: Sử dụng các chỉ số được xác định trước như Độ Đa Dạng, Mức Độ Liên Quan, và MRR để sắp xếp lại.
- Dựa trên Mô Hình: Sử dụng các mô hình như SpanBERT, Cohere Rerank, bge-raranker-large, hoặc GPT để sắp xếp lại.
Nén ngữ cảnh để tránh quá tải thông tin
- Advanced RAG áp dụng các kỹ thuật nén để giảm kích thước của ngữ cảnh được cung cấp cho LLM, loại bỏ thông tin dư thừa và tránh các vấn đề với ngữ cảnh quá dài.
- Sử dụng các mô hình ngôn ngữ nhỏ (ví dụ: GPT-2 Small hoặc LLaMA-7B) để loại bỏ các token không quan trọng, nén ngữ cảnh thành dạng LLM có thể hiểu.
- Huấn luyện một mô hình riêng biệt để trích xuất thông tin quan trọng từ ngữ cảnh được truy xuất
Tập trung vào những thông tin quan trọng nhất
Cho phép LLM đánh giá nội dung được truy xuất trước khi tạo câu trả lời cuối cùng, giúp LLM tự lọc bỏ các tài liệu không liên quan và tập trung vào những thông tin quan trọng nhất.
3.3. Modular RAG: Kiến trúc linh hoạt
Modular RAG là một bước tiến vượt bậc so với hai mô hình RAG trước đó (Naive RAG và Advanced RAG), mang đến khả năng thích ứng và linh hoạt cao hơn. Mô hình này tích hợp nhiều chiến lược khác nhau để cải thiện các thành phần của nó, ví dụ như thêm mô-đun tìm kiếm để tìm kiếm sự tương đồng và tinh chỉnh bộ truy xuất thông tin. Các cải tiến như tái cấu trúc mô-đun RAG và sắp xếp lại quy trình RAG đã được giới thiệu để giải quyết những thách thức cụ thể. Xu hướng chuyển sang phương pháp Modular RAG đang trở nên phổ biến, hỗ trợ cả xử lý tuần tự và huấn luyện tích hợp đầu cuối trên các thành phần của nó. Mặc dù có sự khác biệt, Modular RAG vẫn dựa trên các nguyên tắc cơ bản của Advanced RAG và Naive RAG, minh họa cho sự tiến bộ và tinh chỉnh trong dòng RAG.
Đặc điểm chính của Modular RAG:
1.Tính linh hoạt: Modular RAG cho phép thay thế hoặc cấu hình lại mô-đun để giải quyết các thách thức cụ thể, vượt ra khỏi cấu trúc cố định của Naive và Advanced RAG.
2.Tích hợp module mới: Modular RAG giới thiệu các thành phần chuyên biệt bổ sung để nâng cao khả năng truy xuất và xử lý, bao gồm:
- Module Search: Thích ứng với các tình huống cụ thể, cho phép tìm kiếm trực tiếp trên nhiều nguồn dữ liệu.
- Module Memory: Sử dụng bộ nhớ của LLM để hướng dẫn truy xuất thông tin.
- Module Router: Điều hướng qua các nguồn dữ liệu khác nhau, chọn đường dẫn tối ưu cho một truy vấn.
- Module Predict: Giảm dư thừa và nhiễu bằng cách tạo ngữ cảnh trực tiếp thông qua LLM.
- Module Task Adapter: Điều chỉnh RAG cho các tác vụ downstream khác nhau:
- Tự động truy xuất prompt phù hợp từ một kho prompt được xây dựng trước cho đầu vào tác vụ zero-shot.
- Tạo bộ truy xuất dành riêng cho tác vụ thông qua việc tạo truy vấn few-shot
- Hỗ Trợ Tương Tác Đa Dạng: Modular RAG không bị giới hạn trong mô hình “Truy Xuất - Đọc” đơn giản như Naive RAG và Advanced RAG. Mô hình này hỗ trợ nhiều dạng tương tác phức tạp hơn giữa các module, giúp tối ưu hóa hiệu suất cho từng tác vụ cụ thể.
- Tích Hợp Công Nghệ Mới: Modular RAG có thể dễ dàng kết hợp với các công nghệ AI tiên tiến khác như tinh chỉnh (fine-tuning) hoặc học tăng cường (reinforcement learning), mở ra tiềm năng phát triển vượt bậc cho mô hình.
- Các Mô Hình Tương Tác: Modular RAG mở rộng tính linh hoạt bằng cách tích hợp các mô-đun mới hoặc điều chỉnh luồng tương tác giữa các mô-đun hiện có, nâng cao khả năng ứng dụng trên các tác vụ khác nhau.
- Mô hình Rewrite-Retrieve-Read: LLM được sử dụng để tinh chỉnh truy vấn, nâng cao độ chính xác của kết quả truy xuất thông tin.
- Phương Pháp Generate-Read: LLM đóng vai trò là bộ tạo ngữ cảnh, thay thế cho phương pháp truy xuất thông tin truyền thống.
- Phương pháp Recite-Read: Tập trung vào việc truy xuất thông tin từ trọng số của mô hình, tăng cường khả năng xử lý các tác vụ phức tạp đòi hỏi kiến thức chuyên sâu.
So sánh với Naive RAG và Advanced RAG:
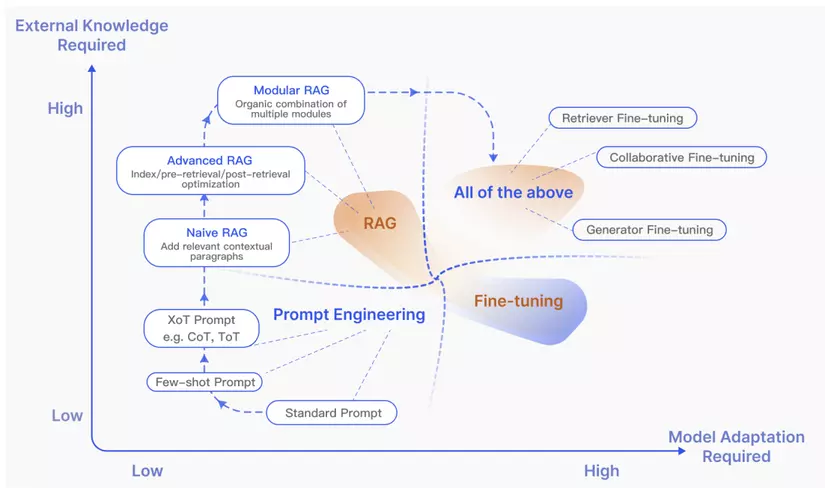
-
Naive RAG tuân theo quy trình truyền thống bao gồm lập chỉ mục, truy xuất và tạo.
-
Advanced RAG tập trung vào việc nâng cao chất lượng truy xuất bằng cách sử dụng các chiến lược trước và sau truy xuất.
-
Modular RAG kế thừa và phát triển từ hai mô hình trước đó, mang đến tính linh hoạt và khả năng thích ứng cao hơn.
-
Lợi ích của Modular RAG:
-Khả năng thích ứng: Modular RAG có thể được điều chỉnh để phù hợp với các tác vụ và yêu cầu cụ thể.
-Hiệu suất được cải thiện: Các mô-đun chuyên biệt và mẫu tương tác mới có thể giúp nâng cao chất lượng truy xuất và tạo.
-Dễ dàng tích hợp: Modular RAG có thể được tích hợp với các công nghệ AI khác để nâng cao hiệu suất.
4. Tài Liệu Tham Khảo
All rights reserved
