
[Paper Explain] - Hiểu về Skip Connection - một kĩ thuật "nhỏ mà có võ" trong các kiến trúc Residual Networks
Bài đăng này đã không được cập nhật trong 4 năm
Lời nói đầu
Xin chào các bạn. Cũng đã lâu rồi mình mới bài viết mới và hôm nay mình xin được quay lại với series paper explain cũng đã ngâm hàng khá lâu rồi. Chắc hẳn các bạn nào đã làm việc nhiều với các kiến trúc mạng CNN thì không còn xa lạ gì với kiến trúc ResNet nữa rồi nhỉ. Nó đã quá thành công và vẫn được sử dụng làm backbone cho rất nhiều bài toán Computer Vision hiện nay như Image Classification, Object Detection, GAN .... Về tư tưởng chính của ResNet, xin phép được tóm gọn lại trong một câu ngắn như sau:
Residual learning là một hướng thiết kế mạng nơ ron giúp cho việc huấn luyện các mạng nơ ron sâu trở nên có hiệu quả hơn so với các phương pháp trước đó (2015). Ví dụ Alexnet, VGG, NiN, ...
Trong bài này chúng ta sẽ cùng nhau tìm hiểu về Skip connection một thuật ngữ cũng đã xưa như trái đất nhưng vẫn chưa bao giờ tỏ ra kém hiệu quả khi được áp dụng. Đồng thời chúng ta cũng sẽ có những explain chi tiết trong bài báo gốc mà kĩ thuật này được trình bày lần đầu tiên đó chính là Deep Residual Learning for Image Recognition - một nghiên cứu có thể coi là huyền thoại bởi sự phổ cập của nó đến từ Microsoft Research. OK chúng ta sẽ bắt đầu ngay thôi
Các vấn đề của các mạng nơ ron sâu
Như đã trình bày ở những phần trên, trong bối cảnh những năm 2015 thì các mạng nơ ron đang được thiết kế với xu hướng ngày càng sâu. Việc các mạng nơ ron sâu có một số đặc điểm hữu ích mà tiêu biểu nhất đó là khi thiết kế một mạng nơ ron sâu hơn sẽ giúp cho việc tăng khả năng biểu diễn cho các thoong tin phức tạp hơn và nó phù hợp hơn với các dataset có kích thước lớn và phức tạp
Vậy một câu hỏi đặt ra cho chúng ta là Các mạng nơ ron sâu đã gặp phải các vấn đề gì trước đó khiến cho việc huấn luyện trở nên kém hiệu quả ???. Chúng ta có thể nhận thấy ngay một số nguyên nhân sau:
- Một trở ngại lớn nhất khi training một mạng nơ ron quá sâu đó chính là vấn đề biến mất đạo hàm - vanishing gradient. Các deep network thường xảy ra hiện tượng đạo hàm tiến dần về 0 rất nhanh khiến cho quá trình gradient descent trở nên kém hiệu quả và sự hội tụ trở nên rất chậm chạp
- Cụ thể hơn thì trong quá trình gradient descent chúng ta sẽ tính toán đạo hàm từ layer cuối cùng đến layer đầu tiên thông qua lan truyền ngược (back-propagation) và chúng ta cần phải thực hiện phép nhân với ma trận trọng số tại mỗi step. Nếu như đạm hàm tại mỗi step nhỏ thì với một số lượng phép nhân ngày càng tăng khi số lượng layer càng sâu sẽ dẫn đến đạo hàm sẽ về 0 rất nhanh. Hiện tượng này gọi là vanishing gradient hay biến mất đạo hàm.
- Vấn đề ngược lại được gọi là bùng nổ đạo hàm exploding gradients xảy ra tương tự với trường hợp các đạo hàm có giá trị lớn.
Các kiến trúc mạng trước khi Resnet ra đời như Alexnet, VGG được coi là các mạng nơ ron thuần (plain network). Đối với các mạng nơ ron thuần, tác giả đã thí nghiệm và đưa ra kết luận khi tăng số lượng layer của mạng từ 20 lên 56 thì lỗi trên tập huấn luyện và trên tập kiểm tra của mạng 56 lyaer đều cao hơn so với mạng 20 layer. Chúng ta có thể xem kết quả trong hình dưới đây
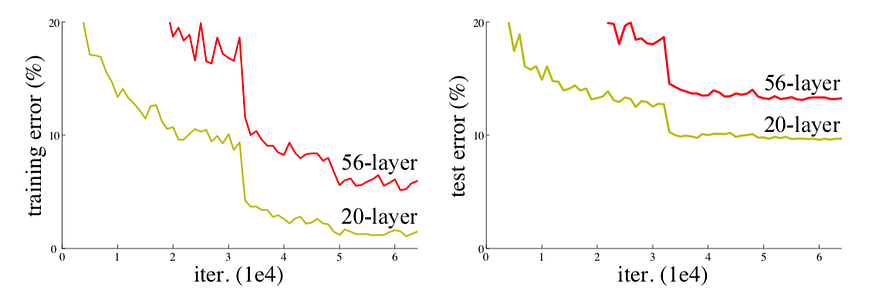
Có vấn đề gì đã xảy ra vậy?
Các lớp hàm số và ánh xạ đồng nhất
Một cách tự nhiên, chúng ta nghĩ rằng việc thêm càng nhiều lớp sẽ khiến cho kiến trúc mạng của chúng ta trở nên lớn hơn và đồng nghĩa với việc có khả năng biểu diễn được các thông tin phức tạp hơn và đương nhiên là phải tăng độ chính xác chứ nhỉ. Tuy nhiên thực tế thì nó lại đang chứng minh điều ngược lại, khi càng tăng số lượng các lớp thì hiện tương higher training error xảy ra. Để tìm câu trả lời cho vấn đề này, các nhà khoa học thời đó đã đưa ra một khái niệm gọi là Function classes hay lớp các hàm số. Gọi là lớp các hàm số mà kiến trúc mạng (với leanring rate và các hyper params khác nhau) có thể đạt được. Nói một cách khác với mọi hàm số luôn tồn tại một bộ tham số cho kiến trúc mạng được huấn luyện trên một bộ dữ liệu phù hợp. Giả sử hàm số là hàm số cần tìm.
Chúng ta sẽ thấy rằng nếu như hàm số là một điều rất tốt. Nhưng thường thì chúng ta sẽ không may mắn như vậy. Chúng ta sẽ phải đi giải bài toán tối ưu để tìm ra hàm phù hợp.
Nếu chúng ta thiết kế một kiến trúc mạng khác có lớp hàm số mạnh mẽ hơn thì một cách tự nhiên chúng ta kì vọng rằng độ chính xác của mô hình sẽ tăng lên hay tham số sẽ tốt hơn tham số . Tuy nhiên điều này sẽ không thể khẳng định được nếu như . Trên thực tế, đôi khi chính hàm thậm chí còn tệ hơn. Việc tăng số lớp của mạng không những không làm tăng độ chính xác mà còn dẫn đến những hệ quả khó lường. Chung ta có thể minh hoạ nó trong hình sau:

Ở hình bên trái minh hoạ các lớp hàm số không lồng nhau. Lúc này việc tăng kích thước của mạng thâm chí còn làm cho các hàm có khoảng cách ngày càng xa hơn khi mở rộng (ví dụ trong hình bên trái). Điều này sẽ không xảy ra đối với các hàm số lồng nhau như hình bên phải.
Chỉ khi các lớp hàm lớn hơn chứa các lớp nhỏ hơn, thì mới đảm bảo rằng việc tăng thêm các tầng sẽ tăng khả năng biểu diễn của mạng. Đây là câu hỏi mà He và các cộng sự đã suy nghĩ khi nghiên cứu các mô hình mạng nơ ron sâu vào năm 2016. Ý tưởng trọng tâm của ResNet là mỗi tầng được thêm vào nên có một thành phần là hàm số đồng nhất. Điều này có nghĩa rằng, nếu ta huấn luyện tầng mới được thêm vào thành một ánh xạ đồng nhất thì mô hình mới sẽ hiệu quả ít nhất bằng mô hình ban đầu. Vì tầng được thêm vào có thể khớp dữ liệu huấn luyện tốt hơn, dẫn đến sai số huấn luyện cũng nhỏ hơn.
Skip connection - cách khắc phục của ResNet
Ý tưởng chính của phương pháp này thực ra rất đơn giản trong quá trình implement (dù nó được xuất phát từ một tư duy khá trừu tượng về lớp các hàm số được trình bày phía trên). Tác giả đã thực hiện residual mapping để copy thông tin từ các layer nông shallow layer trước đó đến các layer sâu hơn. Chúng ta giả sử output của shallow layer là . Trong quá trình forward của mạng nó được đưa qua một phép biến đổi tuyến tính . Chúng ta giả sử output của phép biến đổi tuyền tính này là . Một residual (phần dư) giữa deep layer và shallow layer là
Trong đố là các tham số của mô hình CNN với phép biến đổi và nó được tối ưu trong quá trình huấn luyện.
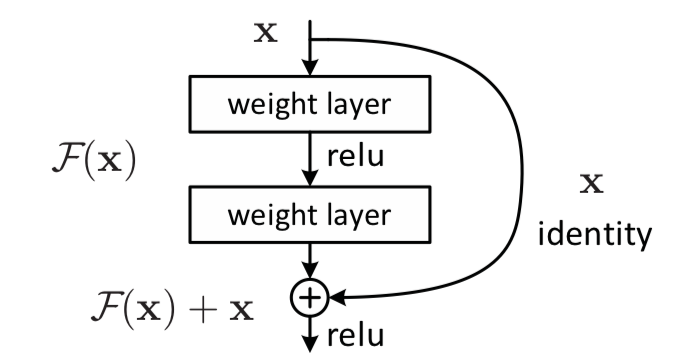
Việc thêm vào các residual block vào trong kiến trúc mạng deep learning có hai cách tuỳ thuộc vào từng trường hợp cụ thể.
- identity mapping trong trường hợp này residual mapping đơn giản là việc cộng trực tiếp vào đầu ra của các stacked block . Đây là một cách sử dụng khá phổ biến trong thiết kế mạng ResNet nếu như input activation có cùng số chiều với output activation. Chúng ta có thể minh hoạ nó trong hình sau:

- Convolutional block một trường hợp khác là thay vì cộng trực tiếp giá trị của input activation chúng ta sẽ đưa qua một convolution transformation. Trường hợp này có thể được thực hiện trong trường hợp input activation và output activation có số chiều khác nhau. Lúc này đầu ra được xác định như sau . Chúng ta có thể xem hình minh hoạ dưới đây
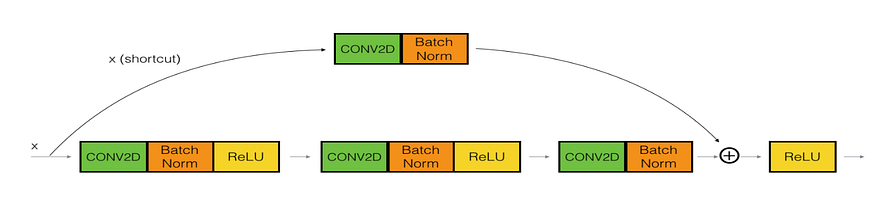
Code thôi
Chúng ta đã tìm heiuer qua về những lý thuyết để xây dựng mạng ResNet, bây giờ chúng ta sẽ tiến hành xây dựng mô hình này bằng các framework quen thuộc. Khác với các bài viết paper explain khác mình sẽ sử dụng song song cả Tensorflow 2 và PyTorch để implement vì nó cũng không quá dài. OK chúng ta bắt đầu thôi
Xây dựng Resnet với TF 2
Residual Block
Trong trường hợp này chúng ta sẽ xây dựng resdiaul blcok với hai trường hợp là identity mapping và sử dụng conv block. Chúng ta sẽ sử dụng biếnis_identity để xác định điều đó
import tensorflow as tf
from tensorflow.keras.layers import Layer, Conv2D, BatchNormalization, ReLU
# Build residual block
class ResidualBlock(Layer):
def __init__(self, num_channels, output_channels, strides=1, is_identity=True, **kwargs):
super(ResidualBlock, self).__init__(**kwargs)
self.is_identity = is_identity
self.conv1 = Conv2D(num_channels, padding='same', kernel_size=3, strides=1)
self.bn = BatchNormalization()
self.conv2 = Conv2D(num_channels, padding='same', kernel_size=3)
if not self.is_identity:
self.conv3 = Conv2D(num_channels, kernel_size=1, strides=1)
else:
self.conv3 = None
self.conv4 = Conv2D(output_channels, padding='same', kernel_size=1, strides=strides)
self.relu = ReLU()
def call(self, X):
# Init residual
Y = X
if self.conv3 is not None:
Y = self.conv3(X)
# Conv block 1
X = self.conv1(X)
X = self.bn(X)
X = self.relu(X)
# Conv block 2
X = self.conv2(X)
X = self.bn(X)
# Add residual to output of stacked
X += Y
# Last conv block
X = self.conv4(X)
return self.relu(X)
Chúng ta thử kiểm tra output của khối ResidualBlock trên nhé.
X = tf.random.uniform((32, 256, 256, 3)) # shape=(batch_size, width, height, channels)
X = ResidualBlock(num_channels=1, output_channels=64, strides=2, is_identity=True)(X)
print(X.shape)
>>> (32, 128, 128, 64)
Resnet Model
Dựa trên các khối Residual Block đã được xây dựng trước đó chúng ta có thể xây dựng lên ResNet model một cách rất đơn giản bằng cách stack các khối này lại với nhau. Về mặt lý thuyết chúng ta có thể có những mạng ResNet với một mức độ sâu bất kì. Nhờ sự khác biệt vệ mức độ sâu của các mạng này mà chúng ta có rất nhiều biến thể của ResNet khác nhau như ResNet18, ResNet34, ResNet50, ResNet101, ResNet152. Chúng ta thực hiện xây dwungj Resnet18 model với các cấu hình như sau:
- Hai tầng đầu tiên của ResNet giống hai tầng đầu tiên của GoogLeNet: tầng tích chập 7×7 với 64 kênh đầu ra và stride 2. Sở dĩ chúng ta bắt đầu với một kernel lớn như vậy để có teher capture được các thông tin về ngữ cảnh được rộng hơn.
- Tiếp theo đó là 1 layer MaxPooling với stride 3x3
- Tiêp theo mỗi tầng tích chập là một lớp Batch Normalization
- Mỗi khối residual được biểu diễn bằng 1 ô có viền nét đứt như hình bên dưới. Hai khối đầu tiên sử dụng identity block. Tiếp sau đó là việc lặp lại ba lần các khối residual theo thứ tự
conv - identity. - Có tổng cộng 8 khối residual với 2 layer conv trong mỗi khối (thay vì 3 conv như trong implement của chúng ta). Cộng thêm lớp conv 7x7 đầu tiên và lớp Fully Connected cuối cùng. Tổng cộng có 18 layer và đó là lý do chúng ta đặt tên là ResNet-18

Chúng ta có thể dễ dàng thay đổi kiến trúc này để tăng hoặc giảm số chiều sâu tuỳ thuộc vào yêu cầu của bài toán. Ở đây chúng ta có thể implement một cách tổng quát như sau
# Build our ResNet model
class ResNetModel(tf.keras.Model):
def __init__(self, residual_blocks, nb_classes):
super(ResNetModel, self).__init__()
self.conv1 = Conv2D(kernel_size=7, filters=64, strides=2, padding='same')
self.bn = BatchNormalization()
self.max_pool = MaxPool2D(pool_size=(3, 3), strides=2, padding='same')
self.relu = ReLU()
self.residual_blocks = residual_blocks
self.gap = GlobalAvgPool2D()
self.fc = Dense(units=nb_classes)
def call(self, X):
# First layer before residual blocks
X = self.conv1(X)
X = self.bn(X)
X = self.relu(X)
X = self.max_pool(X)
# Residual blocks
for block in residual_blocks:
X = block(X)
# After residual block
X = self.gap(X)
# Fully connected layer
X = self.fc(X)
return X
Tong đó chúng ta sẽ truyền vào các khối residual_blocks như một tham số của mạng. Chính ở đây chúng ta sẽ định nghĩa các số lượng layer tuỳ chỉnh. Để cho đơn giản các bạn có thể xây dựng một list các khối như sau
# Define residual blocks
residual_blocks = [
# Two residual block with identity mapping
ResidualBlock(num_channels=64, output_channels=64, strides=2, is_identity=True),
ResidualBlock(num_channels=64, output_channels=64, strides=2, is_identity=True),
# Next 3 [conv mapping + identity mapping]
ResidualBlock(num_channels=64, output_channels=128, strides=2, is_identity=False),
ResidualBlock(num_channels=128, output_channels=128, strides=2, is_identity=True),
ResidualBlock(num_channels=128, output_channels=256, strides=2, is_identity=False),
ResidualBlock(num_channels=256, output_channels=256, strides=2, is_identity=True),
ResidualBlock(num_channels=256, output_channels=512, strides=2, is_identity=False),
ResidualBlock(num_channels=512, output_channels=512, strides=2, is_identity=True)
]
Tiếp theo đó chúng ta thử tạo model với bộ input đầu vào là của tập dữ liệu CIFAR-10
# Create model
model = ResNetModel(residual_blocks=residual_blocks, nb_classes=10)
model.build(input_shape=(None, 32, 32, 3))
Tiếp theo chúng ta sẽ thử summary model xem sao
model.summary()
>>>
Model: "res_net_model"
_________________________________________________________________
Layer (type) Output Shape Param #
=================================================================
conv2d_30 (Conv2D) multiple 9472
_________________________________________________________________
batch_normalization_9 (Batch multiple 256
_________________________________________________________________
max_pooling2d (MaxPooling2D) multiple 0
_________________________________________________________________
re_lu_9 (ReLU) multiple 0
_________________________________________________________________
residual_block_1 (ResidualBl multiple 78272
_________________________________________________________________
residual_block_2 (ResidualBl multiple 78272
_________________________________________________________________
residual_block_3 (ResidualBl multiple 86592
_________________________________________________________________
residual_block_4 (ResidualBl multiple 312192
_________________________________________________________________
residual_block_5 (ResidualBl multiple 345216
_________________________________________________________________
residual_block_6 (ResidualBl multiple 1246976
_________________________________________________________________
residual_block_7 (ResidualBl multiple 1378560
_________________________________________________________________
residual_block_8 (ResidualBl multiple 4984320
_________________________________________________________________
global_average_pooling2d (Gl multiple 0
_________________________________________________________________
dense (Dense) multiple 5130
=================================================================
Total params: 8,525,258
Trainable params: 8,522,186
Non-trainable params: 3,072
_________________________________________________________________
Huấn luyện mô hình với tập dữ liệu CIFAR-10
Sau khi build xong mô hình ResNet chúng ta có thể huấn luyện nó với các tập dữ liệu đơn giản. ở đây mình sử dụng CIFAR-10
from tensorflow.keras.datasets import cifar10
from tensorflow.keras.utils import to_categorical
(X_train, y_train), (X_test, y_test) = cifar10.load_data()
# Normalization
X_train = X_train.astype('float32')/255.0
X_test = X_test.astype('float32')/255.0
# Convert label to one-hot
y_train = to_categorical(y_train)
y_test = to_categorical(y_test)
Tiến hành training mô hình thôi
from tensorflow.keras.optimizers import Adam
from tensorflow.keras.losses import CategoricalCrossentropy
optimizer = Adam(lr=0.001)
model.compile(optimizer=optimizer, loss=CategoricalCrossentropy(), metrics=['accuracy'])
model.fit(X_train, y_train, validation_data = (X_test, y_test), batch_size=32, epochs=50)
Xây dựng Resnet với PyTorch
Đối với Pytorch chúng ta cũng tiến hành xây dựng các khối tương tự. Mình xin phép chỉ show code mà không giải thích thêm
Residual Block
# Build residual block
class ResidualBlock(nn.Module):
def __init__(self, num_channels, output_channels, is_identity=True, stride=1):
super(ResidualBlock, self).__init__()
self.is_identity = is_identity
self.conv1 = nn.Conv2d(num_channels, num_channels, kernel_size=3, padding=1, stride=1)
self.conv2 = nn.Conv2d(num_channels, num_channels, kernel_size=3, padding=1)
if not self.is_identity:
self.conv3 = nn.Conv2D(num_channels, kernel_size=1, stride=1)
else:
self.conv3 = None
self.conv4 = nn.Conv2d(num_channels, output_channels, padding=0, kernel_size=1, stride=stride)
self.bn = nn.BatchNorm2d(num_channels)
self.relu = nn.ReLU()
def forward(self, X):
# Init residual
Y = X
if self.conv3 is not None:
Y = self.conv3(X)
# Conv block 1
X = self.conv1(X)
X = self.bn(X)
X = self.relu(X)
# Conv block 2
X = self.conv2(X)
X = self.bn(X)
# Add residual to output of stacked
X += Y
# Last conv block
X = self.conv4(X)
return self.relu(X)
Ta test thử với một batch dữ liệu
X = torch.rand((32, 3, 256, 256)) # shape=(batch_size, channels, width, height)
X = ResidualBlock(num_channels=3, output_channels=64, stride=1, is_identity=True)(X)
print(X.shape)
>>> torch.Size([32, 64, 256, 256])
Resnet Model
# Build resnet model
from torchsummary import summary
class ResNetModel(nn.Module):
def __init__(self, residual_blocks, nb_classes):
super(ResNetModel, self).__init__()
self.conv1 = nn.Conv2d(3, 64, kernel_size=7, stride=2, padding=1)
self.batch_norm = nn.BatchNorm2d(64)
self.max_pool = nn.MaxPool2d(kernel_size=3, stride=2, padding=1)
self.relu = nn.ReLU()
self.residual_blocks = nn.Sequential(*residual_blocks)
self.gap = nn.Flatten()
self.fc = nn.Linear(in_features=512, out_features=nb_classes)
def forward(self, X):
X = self.conv1(X)
X = self.batch_norm(X)
X = self.relu(X)
X = self.max_pool(X)
X = self.residual_blocks(X)
X = self.gap(X)
X = self.fc(X)
return X
Chúng ta định nghĩa các khối residual_blocks tương tự như đối với mô hình TF 2
# Define residual blocks
residual_blocks = [
# Two residual block with identity mapping
ResidualBlock(num_channels=64, output_channels=64, stride=2, is_identity=True),
ResidualBlock(num_channels=64, output_channels=64, stride=2, is_identity=True),
# Next 3 [conv mapping + identity mapping]
ResidualBlock(num_channels=64, output_channels=128, stride=2, is_identity=False),
ResidualBlock(num_channels=128, output_channels=128, stride=2, is_identity=True),
ResidualBlock(num_channels=128, output_channels=256, stride=2, is_identity=False),
ResidualBlock(num_channels=256, output_channels=256, stride=2, is_identity=True),
ResidualBlock(num_channels=256, output_channels=512, stride=2, is_identity=False),
ResidualBlock(num_channels=512, output_channels=512, stride=2, is_identity=True)
]
Tiếp đố chúng ta định nghĩa và truyền model vào device
device = torch.device("cuda" if torch.cuda.is_available() else "cpu")
model = ResNetModel(residual_blocks, nb_classes=10)
model.to(device)
dummy_input = torch.rand((2, 3, 256, 256))
# model(dummy_input.to(device))
summary(model, (3, 32, 32))
>>>
torch.Size([2, 512, 1, 1])
----------------------------------------------------------------
Layer (type) Output Shape Param #
================================================================
Conv2d-1 [-1, 64, 14, 14] 9,472
BatchNorm2d-2 [-1, 64, 14, 14] 128
ReLU-3 [-1, 64, 14, 14] 0
MaxPool2d-4 [-1, 64, 7, 7] 0
Conv2d-5 [-1, 64, 7, 7] 36,928
BatchNorm2d-6 [-1, 64, 7, 7] 128
ReLU-7 [-1, 64, 7, 7] 0
Conv2d-8 [-1, 64, 7, 7] 36,928
BatchNorm2d-9 [-1, 64, 7, 7] 128
Conv2d-10 [-1, 64, 4, 4] 4,160
ReLU-11 [-1, 64, 4, 4] 0
ResidualBlock-12 [-1, 64, 4, 4] 0
Conv2d-13 [-1, 64, 4, 4] 36,928
BatchNorm2d-14 [-1, 64, 4, 4] 128
ReLU-15 [-1, 64, 4, 4] 0
Conv2d-16 [-1, 64, 4, 4] 36,928
BatchNorm2d-17 [-1, 64, 4, 4] 128
Conv2d-18 [-1, 64, 2, 2] 4,160
ReLU-19 [-1, 64, 2, 2] 0
ResidualBlock-20 [-1, 64, 2, 2] 0
Conv2d-21 [-1, 64, 2, 2] 4,160
Conv2d-22 [-1, 64, 2, 2] 36,928
BatchNorm2d-23 [-1, 64, 2, 2] 128
ReLU-24 [-1, 64, 2, 2] 0
Conv2d-25 [-1, 64, 2, 2] 36,928
BatchNorm2d-26 [-1, 64, 2, 2] 128
Conv2d-27 [-1, 128, 1, 1] 8,320
ReLU-28 [-1, 128, 1, 1] 0
ResidualBlock-29 [-1, 128, 1, 1] 0
Conv2d-30 [-1, 128, 1, 1] 147,584
BatchNorm2d-31 [-1, 128, 1, 1] 256
ReLU-32 [-1, 128, 1, 1] 0
Conv2d-33 [-1, 128, 1, 1] 147,584
BatchNorm2d-34 [-1, 128, 1, 1] 256
Conv2d-35 [-1, 128, 1, 1] 16,512
ReLU-36 [-1, 128, 1, 1] 0
ResidualBlock-37 [-1, 128, 1, 1] 0
Conv2d-38 [-1, 128, 1, 1] 16,512
Conv2d-39 [-1, 128, 1, 1] 147,584
BatchNorm2d-40 [-1, 128, 1, 1] 256
ReLU-41 [-1, 128, 1, 1] 0
Conv2d-42 [-1, 128, 1, 1] 147,584
BatchNorm2d-43 [-1, 128, 1, 1] 256
Conv2d-44 [-1, 256, 1, 1] 33,024
ReLU-45 [-1, 256, 1, 1] 0
ResidualBlock-46 [-1, 256, 1, 1] 0
Conv2d-47 [-1, 256, 1, 1] 590,080
BatchNorm2d-48 [-1, 256, 1, 1] 512
ReLU-49 [-1, 256, 1, 1] 0
Conv2d-50 [-1, 256, 1, 1] 590,080
BatchNorm2d-51 [-1, 256, 1, 1] 512
Conv2d-52 [-1, 256, 1, 1] 65,792
ReLU-53 [-1, 256, 1, 1] 0
ResidualBlock-54 [-1, 256, 1, 1] 0
Conv2d-55 [-1, 256, 1, 1] 65,792
Conv2d-56 [-1, 256, 1, 1] 590,080
BatchNorm2d-57 [-1, 256, 1, 1] 512
ReLU-58 [-1, 256, 1, 1] 0
Conv2d-59 [-1, 256, 1, 1] 590,080
BatchNorm2d-60 [-1, 256, 1, 1] 512
Conv2d-61 [-1, 512, 1, 1] 131,584
ReLU-62 [-1, 512, 1, 1] 0
ResidualBlock-63 [-1, 512, 1, 1] 0
Conv2d-64 [-1, 512, 1, 1] 2,359,808
BatchNorm2d-65 [-1, 512, 1, 1] 1,024
ReLU-66 [-1, 512, 1, 1] 0
Conv2d-67 [-1, 512, 1, 1] 2,359,808
BatchNorm2d-68 [-1, 512, 1, 1] 1,024
Conv2d-69 [-1, 512, 1, 1] 262,656
ReLU-70 [-1, 512, 1, 1] 0
ResidualBlock-71 [-1, 512, 1, 1] 0
Flatten-72 [-1, 512] 0
Linear-73 [-1, 10] 5,130
================================================================
Total params: 8,525,130
Trainable params: 8,525,130
Non-trainable params: 0
----------------------------------------------------------------
Input size (MB): 0.01
Forward/backward pass size (MB): 0.61
Params size (MB): 32.52
Estimated Total Size (MB): 33.14
----------------------------------------------------------------
Huấn luyện mô hình với tập dữ liệu CIFAR-10
# Training with CIFAR 10
import torchvision
import torchvision.transforms as transforms
transform = transforms.Compose([
transforms.ToTensor(),
transforms.Normalize((0.5, 0.5, 0.5), (0.5, 0.5, 0.5))
])
Sau đó chúng ta tiến hành load tập dữ liệu
batch_size = 32
trainset = torchvision.datasets.CIFAR10(root='./data', train=True,
download=True, transform=transform)
trainloader = torch.utils.data.DataLoader(trainset, batch_size=batch_size,
shuffle=True, num_workers=4)
testset = torchvision.datasets.CIFAR10(root='./data', train=False,
download=True, transform=transform)
testloader = torch.utils.data.DataLoader(testset, batch_size=batch_size,
shuffle=False, num_workers=4)
classes = ('plane', 'car', 'bird', 'cat',
'deer', 'dog', 'frog', 'horse', 'ship', 'truck')
Định nghĩa các optimizer
import torch.optim as optim
criterion = nn.CrossEntropyLoss()
optimizer = optim.Adam(model.parameters(), lr=0.001)
Định nghĩa hàm đánh giá accuracy tập test
def val_accuracy(model, testloader, device):
correct = 0
total = 0
# since we're not training, we don't need to calculate the gradients for our outputs
with torch.no_grad():
for data in testloader:
inputs, labels = data
inputs, labels = inputs.to(device), labels.to(device)
# calculate outputs by running images through the network
outputs = model(inputs)
# the class with the highest energy is what we choose as prediction
_, predicted = torch.max(outputs.data, 1)
total += labels.size(0)
correct += (predicted == labels).sum().item()
return correct / total
Và cuối cùng là training mô hình
for epoch in range(50): # loop over the dataset multiple times
running_loss = 0.0
train_acc = 0.0
valid_acc = 0.0
for i, data in enumerate(trainloader, 0):
# get the inputs; data is a list of [inputs, labels]
inputs, labels = data
inputs, labels = inputs.to(device), labels.to(device)
# zero the parameter gradients
optimizer.zero_grad()
# forward + backward + optimize
outputs = model(inputs)
train_acc += (torch.argmax(outputs, axis=1)==labels).float().mean()
loss = criterion(outputs, labels)
loss.backward()
optimizer.step()
# print statistics
running_loss += loss.item()
if i % 200 == 199: # print every 200 mini-batches
val_acc = val_accuracy(model, testloader, device)
print('[Epoch %d, Step %5d] loss: %.3f train_acc: %.3f train_acc: %.3f' %
(epoch + 1, i + 1, running_loss / 2000, train_acc / i, val_acc))
running_loss = 0.0
print('Finished Training')
Kết luận
Trong bài này chúng ta đã cùng tìm hiểu về tư tưởng chính của ResNet với sự bổ sung tưởng chừng rất đơn giản nhưng lại hiệu quả của Skip Connection. Đây là một đống góp rất quan trọng và có ảnh hưởng rất lớn đến các cách thiết kế của các mạng nơ ron sau này. Chúng ta sẽ cùng tìm hiểu các kiến trúc mạng khác trong các bài viết tiếp theo nhé. Xin chào tạm biệt các bạn và hẹn gặp lại trong những bài viết sau
All rights reserved
