
[Paper Explain] DAMFormer: Enhancing Polyp Segmentation through Dual Attention Mechanism
Bài đăng này đã không được cập nhật trong 2 năm
I. Mở đầu:
Việc đưa các các hệ thống học máy vào trong y tế nhằm giúp các bác sĩ hay các chuyên gia y tế chuẩn đoán chính xác đang dần trở lên phổ biến hơn. Đặc biệt là phải nhắc đến nội soi trực tràng nhằm phát hiện các khối u bất thường, điều này cực kỳ quan trọng khi giúp phát hiện và loại bỏ các khối u ra khỏi cơ thể tránh chúng phát triển thành ung thư. Việc các khối u có hình dáng, kích thước và màu sắc đa dạng đôi khi khiến cho bác sĩ nhầm lẫn bỏ sót. Vậy nên, việc áp dụng các hệ thống xác định và khoanh vùng khối u một cách tự động là điều cực kỳ quan trọng. Trong bài viết này, mình xin giới thiệu với mọi người một phương pháp có tên DAMFormer một mô hình nhỏ nhẹ, nhưng vẫn giữ được độ chính xác cao do chính mình và Nguyễn Mai làm tác giả chính, bài báo được accept tại hội thảo ICONIP 2023.
II. DAMFormer
 Mô hình gồm 2 thành phần chính Encoder và Decoder. Contribute chính trong paper của chúng mình là cung cấp một Decoder mới tối ưu cho bài toán polyp về cả mặt hiệu suất và độ nhẹ của mô hình. Còn về phía Encoder chúng mình có sử dụng MiT làm backbone.
Mô hình gồm 2 thành phần chính Encoder và Decoder. Contribute chính trong paper của chúng mình là cung cấp một Decoder mới tối ưu cho bài toán polyp về cả mặt hiệu suất và độ nhẹ của mô hình. Còn về phía Encoder chúng mình có sử dụng MiT làm backbone.
Encoder
Như có thể thấy trong bài toán segmentation đặc biệt là Polyp segmentation thì các objects luôn có nhiều kích thước và hình dạng khác nhau. Điều này gây ra khó khăn rất lớn nếu như chúng ta chỉ sử dụng một mô hình single-scale. Vì vậy chúng mình quyết định sử dụng MiT làm backbone, nó sử dụng kiến trúc hierarchical Transformer việc này giúp cho mô hình MiT có thể sinh được cả high-resolution features lẫn low-resolution features điều này giúp Decoder có thể tận dụng được cả local lẫn global features.
Thêm một lý do cực kỳ quan trọng để mình sử dụng MiT đó chính là việc các khối MHSA trong các mô hình transformer thường là nguyên nhân chính dẫn đến việc tiêu tốn nhiều tài nguyên tính toán. Ở MHSA gốc bao gồm 3 ma trận có cùng kích thước là . Trong đó là độ dài của tokens. Chúng ta có công thức self-attention như sau:
Như vậy chúng ta có thể thấy phép tính self-attention trên sẽ khiến cho mô hình có độ phức tạp lên tới , khi độ phân giải của ảnh càng lớn điều này sẽ càng tệ hơn.
Do đó, để giải quyết vấn đề này MiT đã cải tiến MHSA bằng kỹ thuật có tên là Effective Self-Attention (ESA). Kỹ thuật này sử dụng một tỉ lệ để giảm chiều dài của tokens trong xuống lần:
Bằng cách này kích thước mới của thu được sẽ là . Với cách triển khai này, độ phức tạp của phép tính self-attention sẽ giảm từ xuống còn .
Decoder
1. Convblock
Với những multi-scale outputs chúng ta thường sẽ sử dụng một lateral connections để tổng hợp thông tin các features scale lại với nhau. Và lateral connections thường được triển khai bằng các layer conv1x1. Trong quá trình thí nghiệm, chúng mình nhận thấy việc chỉ sử dụng các layer conv1x1 là không tối ưu. Khi mà output của 3 stage đầu tiên của encoder thường có xu hướng capture được các thông tin cục bộ, trong khi tại stage cuối sẽ capture được thông tin toàn cục. Do đó, việc chỉ sử dụng conv1x1 trên toàn bộ đầu ra sẽ không thể tận dụng được toàn bộ thông tin mà encoder mang lại.
Vì vậy, tận dụng khả năng capture thông tin cục bộ mạnh mẽ của convolution, chúng mình đã quyết định sử dụng 3 block conv3x3 cho 3 stage đầu tiên. Convblock được triển khai như sau:
- : Relu activation function
- : Batch-Normalization
- : Convolution 3x3
2. EDAM (Enhanced Dual Attention Module)
Một khó khăn khi xử lý bài toán về polyp đó chính là việc foreground (polyp objects) và background thường không có sự tách biệt rõ rệt. Do đó, việc yêu cầu một mô hình có một effective receptive field lớn là điều cực kỳ cần thiết.
Nếu như các bạn có đọc bài How do ViT work? thì sẽ biết được self-attention hoạt động như một low-pass filter, nó thiên về khả năng capture hình dạng tổng quát của đối tượng (shape bias). Thêm nữa là đầu ra tại stage cuối mang nhiều thông tin toàn cục hơn, nên việc chỉ sử dụng CNN tại stage này sẽ không tận dụng hết thông tin encoder mang lại, do là CNN thiên về khả năng capture các chi tiết, cấu tạo (texture bias) hơn là hình dạng tổng quát. Do đó, chúng mình quyết định sử dụng một Dual Attention Module bao gồm Position Attention Module (PAM) và Channel Attention Module (CAM). Hai module này sẽ có khả năng capture được long-range contextual information theo cả chiều spatial và channel, tận dụng được tối đa thông tin từ stage cuối này.
Thêm nữa, để cải tiến PAM và CAM cho bài toán Polyp segmentation, chúng mình đã sử dụng Depth-wise Separable Convolution (DwConv) thay vì CNN thông thường bên trong cả PAM và CAM giúp mô hình hoạt động hiệu quả hơn đáng kể. Tại sao, lý do ở đây là gì?
Trong CNN có một tính chất cực kỳ hay mà trong bài báo PosNet đã phát hiện. Đó chính là việc CNN có thể encode được thông tin về postion thông qua padding. Position encoding là cực kỳ cần thiết trong các mô hình sử dụng attention module (Nếu bạn để ý thì cũng có thể thấy mô hình ViT-based mới như Segformer không cần phải add thêm position embedding như ViT gốc bởi nó đã sử dụng thêm các layer CNN trong mạng)
Nhưng nếu sử dụng CNN bên trong PAM và DAM sẽ không hiệu quả trong trường hợp này, như đã giải thích lý do ở phía trên về tính chất của CNN. Do đó, chúng mình quyết định sử dụng DwConv, bởi vì Dwconv vừa có khả năng encode được thông tin vị trí như CNN và nó vừa hoạt động như một low-pass filter nên có khả năng capture được những thông tin tổng quát về dình dạng của đối tượng. Một lần nữa, nếu bạn muốn hiểu rõ hơn thì có thể đọc bài How do ViT work?
Đầu tiên, Position Attetion Module nhận đầu (PAM) vào là và được biểu diễn như sau:
Channel Attention Module (CAM) cũng nhận đầu vào là và được biểu diễn như sau:
Trong đó hai hệ số và là hai learnable parameter và hai giá trị này được khởi tạo ban đầu là 0.
Sau cùng đầu ra của 2 module này sẽ được tổng hợp lại dưới dạng biểu diễn sau:
- có kích thước và
- có kích thước
3. CWS (Channel-Wise Scaling)
Như mọi người đã biết thì tầm quan trong của mỗi channel trong đầu ra thường không giống nhau. Vậy nên, có thể khuếch đại những channel được coi là quan trọng và giảm thiểu những channel không quan trọng là điều cần thiết. Nó giúp giảm đáng để những thông tin gây nhiễu. Một phương pháp cực kỳ hay đó chính là SE(Squeeze and Excite) module, nó là một cơ chế attention được sinh ra để giải quyết vấn đề này. Thế nhưng mà, mục tiêu ban đầu của chúng mình là tạo ra một decoder nhỏ nhẹ và hiệu quả. Vậy nên chúng mình quyết định đơn giản hóa phương pháp trên bằng cách tạo ra một phương pháp có tên là Channel-Wise Scaling, phương pháp này không những hiệu quả mà số lượng tham số cực kỳ ít.
Phương pháp này không những hiệu quả mà nó còn đơn giản và dễ hiểu. Đầu tiên, chúng mình khởi tạo một hệ số scale learnable có kích thước là . Sau đó sẽ được nhân với đầu ra có kích thước . Cuối cùng sẽ thu được một Ma trận đầu ra có kích thước .
4. EFF (Effective Feature Fusion)
Trong bài LAPFormer đã chỉ ra rằng việc sử dụng Feature pyramid network truyền thống là chưa hợp lý, bởi vì có sự khác biệt lớn về ngữ nghĩa giữa các feature scales. Cụ thể, feature scale và sẽ có sự khác biệt rất lớn về mối tương quan ngữ nghĩa. Trong khi feature scale ở và sẽ có tương quan ngữ nghĩa cao hơn. Do đó, trong bài LAPFormer đã giới thiệu phương pháp có tên là Progressive Feature Fusion (PFF) thay thế cho phương pháp Feature pyramid network.
EFF kết nối lần lượt các feature scale như sau: [ [ [ , ], ], ]
Tuy nhiên, trong quá trình thử nghiệm của chúng mình cho thấy rằng đầu ra của mô hình phụ thuộc rất nhiều vào output ở stage cuối của encoder (đây là stage chứa rất nhiều thông tin high-level features). Vì thế, việc kết nối các feature scale lại với nhau như phương pháp PFF của LAPFormer sẽ làm mất đi nhiều thông tin về high-level features. Do đó, chúng mình đề xuất một phương pháp hiệu quả hơn cải tiến từ PFF cũ đó là Effective Feature Fusion (EFF). Ở EFF các low-level feature tại ba output stage đầu tiên của encoder sẽ được kết hợp lại với nhau giống như PFF, tiếp đến sau đó nói mới được kết nối với feature scale tại output stage cuối là nhằm giữ lại nhiều thông tin về high-level features.
EFF được biểu diễn như sau:
III. Kết quả:
Với từng tập dataset chúng mình sử dụng metric Dice score để so sánh như bình thường, trong khi đó sẽ sử dụng metric đánh giá là Weighted Dice score (wDice) cho việc so sánh tổng hợp 5 tập datasets. Vì số lượng sample trong các tập dataset là không giống nhau, vậy nên cần phải đánh thêm trọng số cho từng tập dữ liệu để giúp so sánh có sự công bằng hơn.
Kvasir, ClinicDB, ColonDB, CVC-300, và ETIS lần lượt có trọng số tương ứng là 0.1253, 0.0777, 0.4762, 0.0752, và 0.2456.
Cách tính toán sẽ như sau:

Kết quá thí nghiệm ở Bảng 1 cho thấy rằng phương pháp của chúng mình đã đạt kết quả khá cạnh tranh và có phần vượt trội hơn so với nhiều mô hình khác với wDice score cho bản DAMFormer-S sử dụng backbone là MiT-B1 là 81.7 và DAMFormer-M sử dụng backbone là MiT-B2 là 83.7
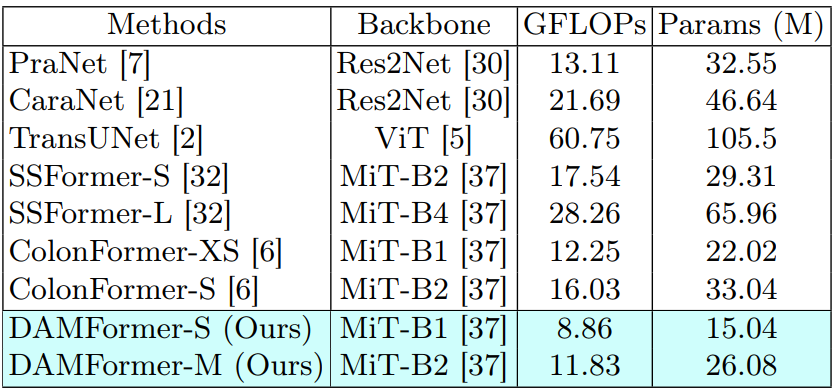
Như có thể thấy ở trên Bảng 2, mô hình của chúng mình có số lượng tham số và GFLOPs ít hơn hẳn các mô hình còn lại. Đặc biệt khi so sánh với những mô hình sử dụng cùng backbone như ColonFormer-XS và ColonFormer-S.
IV. Kết luận:
Tóm lại trong nghiên cứu lần này chúng mình đã đề xuất một mô hình nhẹ nhưng vẫn giữ được độ chính xác cao. Mô hình kết hợp được ưu điểm của cả Transformers và CNN, từ đó cho phép nắm bắt hiệu quả các đặc trưng high-resolution lẫn low-resolution. Sự kết hợp này đã nâng cao hiệu suất của nó trong bài toán polyp segmentation. Thông qua nhiều lần thử nghiệm khác nhau, đã cho thấy rằng mô hình của chúng mình tạo ra kết quả cạnh tranh so với các mô hình SOTA hiện tại. Ưu điểm đáng chú ý của mô hình này là giảm nhu cầu về tài nguyên tính toán mặc dù mang lại kết quả tương đương.
Cám ơn mọi người đã đọc bài viết của mình, nếu thấy hay thì cho mình xin một upvote nhé ^^
Reference:
- DAMFormer: Enhancing Polyp Segmentation through Dual Attention Mechanism
- How do ViT work?
- LAPFormer: A Light and Accurate Polyp Segmentation Transformer
- How much position information do convolutional neural networks encode?
All rights reserved
