[Open Source] #13 - OneUptime: Nền tảng Observability "Full-stack" thay thế hoàn hảo cho Datadog và PagerDuty
Trong vận hành hệ thống hiện đại, việc duy trì sự ổn định (reliability) đòi hỏi sự phối hợp của rất nhiều công cụ. OneUptime nổi lên như một nền tảng mã nguồn mở hiếm hoi cung cấp đầy đủ các tính năng từ giám sát Uptime, quản lý sự cố (Incident Management), lịch trực (On-call), cho đến Status Page công khai và phân tích Telemetry (Logs/Metrics/Spans).
📌 Tổng quan về hệ sinh thái công nghệ
Github: https://github.com/OneUptime/oneuptime
OneUptime là một dự án Enterprise-grade với kiến trúc cực kỳ quy mô, được viết gần như 100% bằng TypeScript:
- Backend: Node.js (Express) với tư duy hướng dịch vụ.
- Frontend: React kết hợp Tailwind CSS, sử dụng Esbuild để tối ưu tốc độ đóng gói.
- Hybrid Database: Đây là điểm sáng kỹ thuật. Hệ thống sử dụng PostgreSQL (via TypeORM) cho các dữ liệu quan hệ và ClickHouse cho dữ liệu quan sát khổng lồ (Logs, Metrics, Spans).
- Infrastructure: Triển khai linh hoạt qua Docker Compose hoặc Kubernetes (Helm Charts).
🏗️ Tư duy kiến trúc: Monorepo & Micro-services Hybrid
Dù nằm trong một kho lưu trữ duy nhất (Monorepo), OneUptime được chia tách thành các dịch vụ độc lập nhưng có tính gắn kết cực cao nhờ module Common/:
- Shared Logic (Common Module): Toàn bộ Model, Type và các Utility được dùng chung cho cả Frontend và Backend. Điều này đảm bảo tính nhất quán dữ liệu (Data Consistency) tuyệt đối và giúp quá trình phát triển nhanh hơn rất nhiều.
- Decoupled Architecture: OneUptime tách biệt hoàn toàn giữa việc Tiếp nhận (Ingest) và Xử lý (Process). Các dịch vụ Ingest chỉ làm nhiệm vụ nhận dữ liệu Telemetry hoặc trạng thái Probe, sau đó đẩy vào Redis Queue để các Worker xử lý nặng ở phía sau.
- Multi-tenancy: Hệ thống được thiết kế ngay từ đầu để hỗ trợ nhiều Project riêng biệt, cho phép các doanh nghiệp lớn quản lý hàng trăm hạ tầng độc lập trên cùng một instance.
🔄 Phân tích chuyên sâu Luồng hoạt động (System Pipeline)
Sơ đồ dưới đây mô tả hành trình từ lúc phát hiện một sự cố nhỏ cho đến khi thông báo tới người dùng và tự động khắc phục:
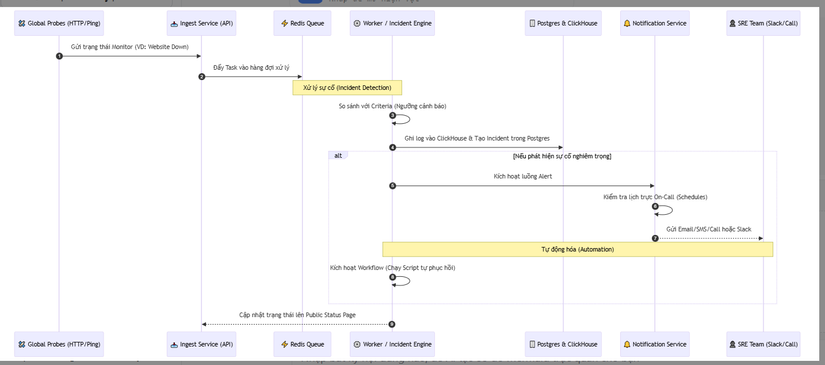
1. Giai đoạn Tiếp nhận & Chống nghẽn (Ingestion & Decoupling) - Bước 1 & 2
- High-Speed Ingest: Dịch vụ
Ingest APIđược viết tối giản để đạt throughput cao nhất. Nhiệm vụ duy nhất của nó là xác thực (Auth) gói tin từ Probes và đẩy ngay vào Redis Queue. - Cơ chế Decoupling: Việc sử dụng Redis ở giữa đóng vai trò như một bộ đệm (Buffer). Nếu hệ thống gặp "spike" (lượng log/metrics tăng đột ngột), các Worker phía sau không bị "chết chùm". Redis giúp điều tiết lưu lượng (Rate Limiting) và bảo vệ cơ sở dữ liệu phía sau khỏi các đợt tấn công hoặc quá tải.
2. Giai đoạn Xử lý Thông minh (Intelligent Incident Engine) - Bước 3 & 4
- Stateful Monitoring: Worker không chỉ so sánh một giá trị đơn thuần. Nó thực hiện các phép tính dựa trên Trạng thái (State). Ví dụ: "Nếu website trả về 500 liên tiếp 3 lần trong 5 phút từ ít nhất 2 khu vực địa lý khác nhau thì mới tạo Incident". Điều này giúp giảm thiểu tối đa Cảnh báo giả (False Positives).
- Hybrid Storage Strategy: Đây là kỹ thuật đỉnh cao trong Observability:
- PostgreSQL (OLTP): Lưu trữ metadata của
Incident, trạng thái hiện tại củaMonitor. Đây là dữ liệu cần tính nhất quán cao. - ClickHouse (OLAP): Lưu trữ toàn bộ lịch sử
LogsvàMetrics. ClickHouse sử dụng cấu trúc Columnar Storage, cho phép nén dữ liệu cực tốt và truy vấn hàng tỷ bản ghi để vẽ biểu đồ xu hướng (Uptime Graph) chỉ trong vài mili giây.
- PostgreSQL (OLTP): Lưu trữ metadata của
3. Giai đoạn Thông báo & Leo thang (On-Call & Escalation) - Bước 5 & 7
- On-Call Logic: Khi phát hiện sự cố,
Notification Servicekhông gửi mail bừa bãi. Nó truy vấn bảng Schedules để biết ai đang trực. - Escalation Policy: Hệ thống hỗ trợ phân cấp. Nếu sau 5 phút người trực chính (Primary) không phản hồi (Acknowledge), hệ thống sẽ tự động gọi điện hoặc nhắn tin cho người trực phụ (Secondary).
- Multi-Channel: Tích hợp sâu với Twilio (SMS/Call), SendGrid (Email) và Slack Webhooks để đảm bảo cảnh báo không bị bỏ sót.
4. Giai đoạn Tự động hóa & Khôi phục (Self-healing Workflow) - Bước 8
- Workflow Execution: Đây là tính năng nâng cao. OneUptime cho phép chạy các script JavaScript trong một môi trường cô lập (Sandbox).
- Remediation: Khi website sập, Workflow có thể tự động gọi Webhook đến hạ tầng của bạn (ví dụ: Kubernetes API) để thực hiện
Rolling Restarthoặc kích hoạt các kịch bản dự phòng (Failover), giúp giảm thiểu thời gian gián đoạn (Downtime) mà không cần con người can thiệp thủ công vào ban đêm.
5. Giai đoạn Công khai & Minh bạch (Public Reporting) - Bước 9
- Status Page Sync: Bước cuối cùng là đồng bộ trạng thái lên trang
Status Pagecông khai. Điều này được thực hiện bất đồng bộ (Asynchronous) để đảm bảo dù hệ thống nội bộ đang xử lý Incident nặng nề, khách hàng bên ngoài vẫn nhìn thấy thông tin cập nhật kịp thời, giúp xây dựng niềm tin với người dùng.
🛠️ Tại sao kiến trúc này lại vượt trội?
- Tính sẵn sàng (Scalability): Nhờ mô hình Worker + Queue, bạn có thể dễ dàng scale-out bằng cách tăng số lượng Worker khi số lượng thiết bị cần giám sát tăng lên.
- Khả năng phục hồi (Resiliency): Nếu Database Postgres gặp sự cố, dữ liệu thô vẫn nằm an toàn trong Redis Queue chờ xử lý lại.
- Tối ưu tài nguyên: Việc tách biệt ClickHouse giúp OneUptime duy trì hiệu suất dashboard cực mượt mà dù đang lưu trữ dữ liệu giám sát của nhiều năm.
⚖️ Tại sao OneUptime nổi bật hơn các đối thủ?
| Tính năng | OneUptime | Datadog / NewRelic | UptimeRobot / PagerDuty |
|---|---|---|---|
| Giá cả | $0 (Mã nguồn mở) | Rất đắt (tính theo host/log) | Trả phí riêng lẻ từng tool |
| Dữ liệu | Tự quản lý (Self-hosted) | Nằm trên cloud của họ | Rời rạc |
| Tích hợp | All-in-one (Native) | Tốt nhưng phức tạp | Cần cấu hình tích hợp chéo |
| Công nghệ | TS, ClickHouse, OTel | Đóng (Proprietary) | Đơn giản |
✅ Kết luận: Có nên triển khai OneUptime?
Nếu bạn đang quản lý một hạ tầng từ trung bình đến lớn và muốn:
- Làm chủ hoàn toàn dữ liệu giám sát: Tránh bị vendor lock-in và bảo mật tuyệt đối.
- Tiết kiệm chi phí cực lớn: Thay vì trả hàng nghìn USD cho Datadog mỗi tháng.
- Hệ thống đồng nhất: Một nơi duy nhất để xem Logs, Metrics, On-call và Status Page.
Thì OneUptime là một dự án "must-try" (phải thử). Đây là một minh chứng tuyệt vời cho sức mạnh của mã nguồn mở khi có thể xây dựng được một hệ thống Observability toàn diện không kém gì các giải pháp SaaS hàng đầu thế giới.
Hy vọng phân tích này mang lại cho bạn một vũ khí mới để tối ưu hóa việc vận hành hệ thống. Đừng quên Upvote và Follow mình để đón xem những "siêu phẩm" tiếp theo nhé!
All rights reserved
