[NLP] Cải thiện Elasticsearch trong bài toán semantic search sử dụng phương pháp Sentence Embeddings
Bài đăng này đã không được cập nhật trong 5 năm
Elasticsearch
Elasticsearch là gì ?
Elasticsearch là một công cụ tìm kiếm dựa trên phần mềm Lucene. Nó cung cấp một bộ máy tìm kiếm dạng phân tán, có đầy đủ công cụ với một giao diện web HTTP có hỗ trợ dữ liệu JSON. Elasticsearch được phát triển bằng Java và được phát hành dạng nguồn mở theo giấy phép Apache. Elasticsearch là một công cụ tìm kiếm phổ biến nhất, theo sau là Apache Solr, cũng dựa trên Lucene. (Theo wiki)
Hạn chế của Elasticsearch trong bài toán semantic search:
Do cơ chế đánh Inverted Index theo từng từ nên elasticsearch rất kém trong bài toán semantic search, vì với cách đánh index đó elasticsearch không thể hiểu hết được cả câu ( hay cả đoạn văn bản).
 Inverted Index elasticsearch
Inverted Index elasticsearch
Sentence Embeddings:
Từ những hạn chế trên của elasticsearch việc chúng ta cần làm là tìm cách cho elasticsearch hiểu được toàn bộ câu.
Hiện nay với sự phát triển bùng nổ của các mô hình họ nhà transformers như Bert, RoBerta, GPT, .. thì việc hiểu ngôn ngữ tự nhiên trở nên đơn giản hơn. Trong bài này mình sẽ không đi vào phân tích từng mô hình này vì đã có rất nhiều bạn đã phân tích khá chi tiết.
Hiện nay có một số kỹ thuật sentence embedding phổ biến như InferSent, Universal Sentence Encoder, SBERT, SimCSE, ...
Trong bài viết mình sẽ hướng dẫn mọi người sử dụng mô hình SimeCSE_Vietnamese để cải thiện elasticsearch trong bài toán Semantic search.
SimeCSE_Vietnamese là pretrain model được mình training dựa trên kiến trúc SimCSE với encoding input mình sử dụng PhoBert mình đã tối lại một vài chỗ trong quá trình trainning để mô hình có thể hoạt động tốt nhất.
Mọi người có thể tham khảo chi tiết tại : https://github.com/vovanphuc/SimeCSE_Vietnamese
(Nếu mọi người có quan tâm đến bài toán thì mình sẽ tiếp tục viết 1 bài hướng dẫn tạo dữ liệu cũng như training cho mô hình SimCSE)
Áp dụng SimeCSE_Vietnamese vào Elasticsearch
Cài đặt Elasticsearch
Muốn sử dụng elastic search thì đầu tiên tất nhiên mọi người phải cài đặt elasticsearch rồi. :v Mọi người có thể vào trang chủ để cài đặt theo hướng dẫn. https://www.elastic.co/guide/en/elasticsearch/reference/current/install-elasticsearch.html
Dữ liệu sử dụng trong bài:
Trong bài ví dụ này mình sẽ sử dụng dữ liệu là 100k title của 100k bài báo mình đã crawl được.
Mọi người có thể tải tại đây !
Sử dụng SimCSE_Vietnamese:
Mình sẽ hướng dẫn các bạn sử dụng SimCSE_Vietnamese để embeddings các câu trước khi lưu vào elasticsearch.
Thư viện chúng ta sẽ sử dụng để load model SimCSE là sentence-transformers vì nó khá đơn giản và dễ dùng.
Đầu tiên chúng ta cài đặt thư viện sentence-transformers:
pip install -U sentence-transformers
Sau đó cùng load model thôi
from sentence_transformers import SentenceTransformer
model_embedding = SentenceTransformer('VoVanPhuc/sup-SimCSE-VietNamese-phobert-base')
def embed_text(batch_text):
batch_embedding = model_embedding.encode(batch_text)
return [vector.tolist() for vector in batch_embedding]
Quá trình tải model sẽ mất vài phút.
Sử dụng python để đánh index trong elasticsearch:
Mình sẽ đánh index các câu và các vector embedding sau khi chúng qua hàm embed_text đã được viết ở trên, mỗi lần mình sẽ đánh 1 batch cho nhanh.
Trước khi đánh index cho các câu mình sẽ sử dụng thêm thư viện pyvi để tokenize các câu.
from elasticsearch import Elasticsearch
from elasticsearch.helpers import bulk
from pyvi.ViTokenizer import tokenize
import pandas as pd
index_name = "demo_simcse"
path_index = "config/index.json"
path_data = "data/data_title.csv"
batch_size = 128
client = Elasticsearch()
def index_batch(docs):
requests = []
titles = [tokenize(doc["title"]) for doc in docs]
title_vectors = embed_text(titles)
for i, doc in enumerate(docs):
request = doc
request["_op_type"] = "index"
request["_index"] = index_name
request["title_vector"] = title_vectors[i]
requests.append(request)
bulk(client, requests)
print(f"Creating the {index_name} index.")
client.indices.delete(index=index_name, ignore=[404])
with open(path_index) as index_file:
source = index_file.read().strip()
client.indices.create(index=index_name, body=source)
docs = []
count = 0
df = pd.read_csv(path_data).fillna(' ')
for index, row in df.iterrows():
count += 1
item = {
'id': row['id'],
'title': row['title']
}
docs.append(item)
if count % batch_size == 0:
index_batch(docs)
docs = []
print("Indexed {} documents.".format(count))
if docs:
index_batch(docs)
print("Indexed {} documents.".format(count))
client.indices.refresh(index=index_name)
print("Done indexing.")
Query với embedding vector trong elasticsearch:
Elasticsearch có hỗ trợ sẵn một vài công thức để tính similarity giữa các vector như l1norm, l2norm, cosineSimilarity, dotProduct, .. Trong bài này chúng ta sẽ sử dụng cosineSimilarity.
Chúng ta chỉ cần cho câu muốn tìm kiếm qua hàm embed_text và sử dụng câu query sau:
{
"script_score": {
"query": {
"match_all": {}
},
"script": {
"source": "cosineSimilarity(params.query_vector, 'title_vector') + 1.0",
"params": {"query_vector": query_vector}
}
}
}
Vậy là xong. !!!!!!!
Mình sử dụng thêm streamlit để demo cũng như so sánh kết quả khi search bằng elasticsearch bình thường (BM25) và cách search theo độ tương đồng giữa các vector embedding (SimCSE). Các bạn cùng xem kết quả nhé.!!!!
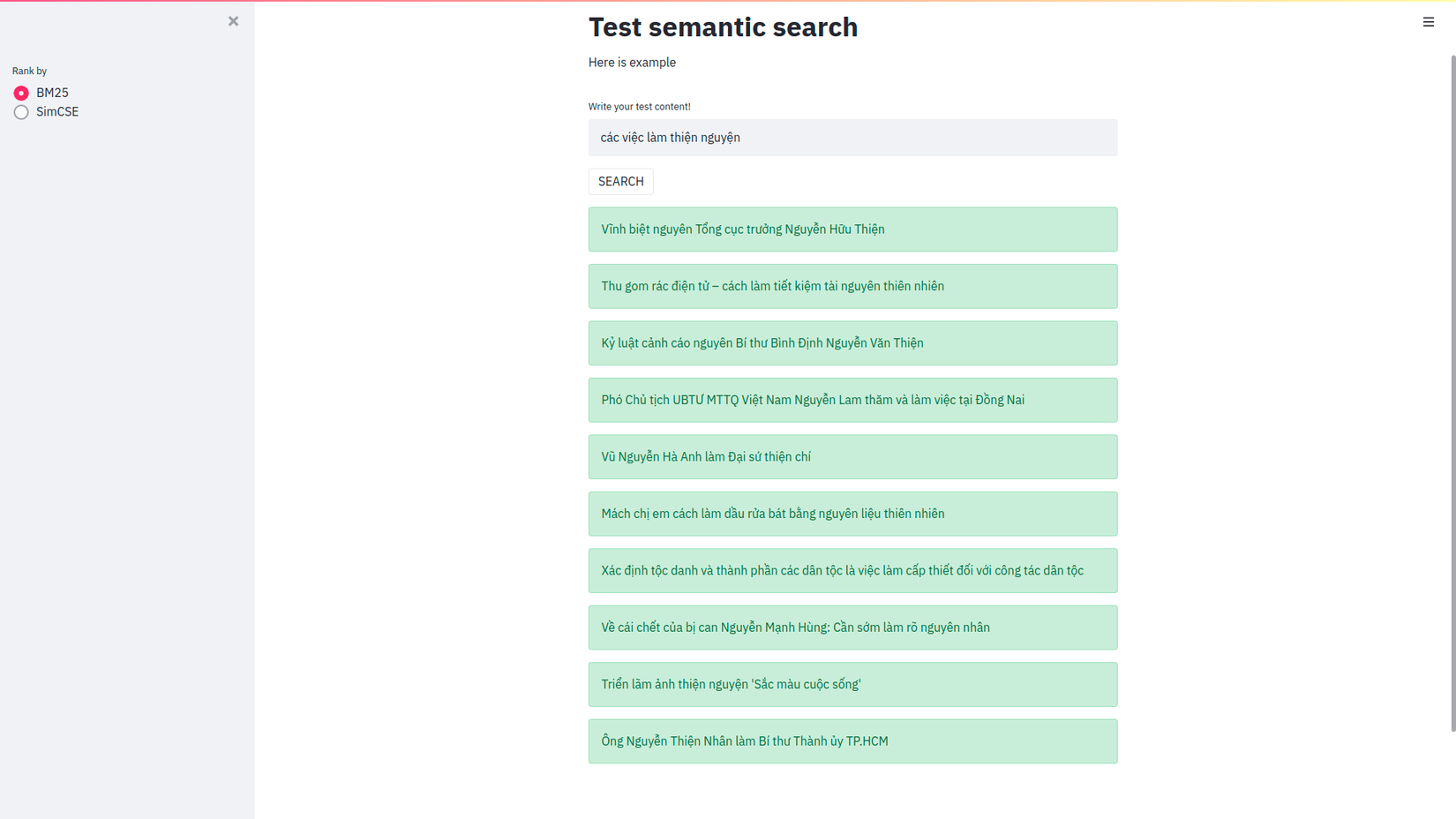
Đây là kết quả khi mình sử dụng elasticsearch bình thường.
 Còn đây là kết quả khi mình sử dụng SimCSE_Vietnamese.
Còn đây là kết quả khi mình sử dụng SimCSE_Vietnamese.
Như mọi người có thể thấy thì kết quả được cải thiện rất nhiều !!!!
Kết luận
Toàn bộ source mình để tại đây: https://github.com/vovanphuc/elastic_simCSE
Nếu mọi người có gặp vấn đề trong khi triển khai thì có thể để lại comment bên dưới. ! ( Đây là bài viết đầu tiên của mình nên còn hơi vụng về mong mọi người góp ý !! )
Tham khảo:
All rights reserved
