Những vấn đề trong Hệ thống phân tán (phần 1)
(rely on Designing Data-Intensive Applications)
Trong bài viết sau, chúng ta sẽ tìm hiểu sâu thêm về cách để tạo sự đảm bảo trong hệ thống phân tán. Đối với bài viết này, chúng ta phải hiểu về thách thức/vấn đề mà chúng ta sẽ gặp phải.
Các hệ thống phân tán gặp phải những vấn đề gì phổ biến nhất?
Đó là Mạng không chính xác (Unreliable Networks), Đồng hồ không chính xác (Unreliable Clocks)
1. Faults and Partial Failures
Trên 1 máy tính, không có 1 lý do chính nào nói rằng phần mềm là không đáng tin cậy, nếu được viết 1 cách thích đáng, nó hoặc sẽ hoạt động hết hoặc là không, chứ không đưa ra một kết quả sai. Nếu phần cứng không hoạt động đúng thì sẽ dẫn đến cả hệ thống đi bụi (blue screen of death, kernal panic). Tuy nhiên với một hệ thống phân tán, bài toán khác biệt hoàn toàn. Trích dẫn lời của Coda Hale thì:
In my limited experience I’ve dealt with long-lived network partitions in a single data center (DC), PDU [power distribution unit] failures, switch failures, accidental power cycles of whole racks, whole-DC backbone failures, whole-DC power failures, and a hypoglycemic driver smashing his Ford pickup truck into a DC’s HVAC [heating, ven‐ tilation, and air conditioning] system. And I’m not even an ops guy. —Coda Hale
Trong hệ thống phân tán, có những phần của hệ thống bị fail theo một cách không lường trước được, chúng ta gọi là partial failure. Partial Failure là không tất định, nếu you tính làm gì dựa trên nhiều node và network, nó có thể hoạt động hoặc fail một cách không dự đoán được. Bạn có thể cũng không biết được nó hoạt động hay là không luôn, bởi vì ... thời gian cho 1 message chuyển đi trong network là không tất định.
1.1 Cloud Computing and Supercomputing
Điểm khác biệt chính giữa điện toán đám mây và siêu máy tính là gì?
1 dải triết lý (spectrum of philosophies) trong việc build 1 large-scale computing system có thể kể tới:
- 1 đầu là HPC (High Performance Computing), Siêu máy tính với hàng ngàn CPU
- 1 đầu là Cloud Computing
- Traditional enterprise datacenter thì nằm giữa hai cái kể trên
HPC có triết lý giống 1 máy tính đơn, nếu 1 node hư thì dừng cả cluster, chờ đến khi vấn đề được xử lý, nó sẽ restart từ điểm checkpoint gần nhất. Just let everything crash (Giống với kernal panic trên máy đơn).
Đối với internet services thì không thể theo triết lý này bởi:
- Cần đảm bảo tính sẵn sàng khi user request
- HPC yêu cầu phần cứng đặc biệt, trong khi đó cloud service đem lại hiệu suất tương đương với giá thành rẻ hơn, tuy nhiên khả năng fail cao hơn
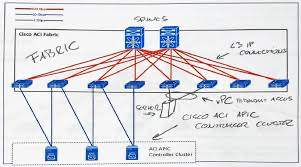
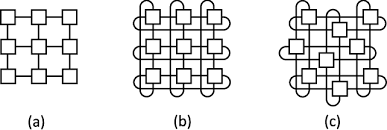
- Network topologies khác nhau, Clos topology (IP & Ethernet) vs multi-dimensional meshes and toruses (HPC)
Clos topology:
Multi-dimensional meshes and toruses:
- Hệ thống càng lớn thì... rủi ro 1 phần hệ thống lỗi càng lớn. Trong 1 hệ thống với hàng ngàn node, hợp lý khi ta cho rằng có 1 cái gì đó luôn lỗi trong hệ thống. Nếu kiên trì với giải pháp dừng hệ thống khi có sự cố, hệ thống sẽ tốn thời gian cho việc recover hơn là thực sự làm gì có ích (1)
- Ở chiều ngược lại với (1), nếu hệ thống có thể tolerate failed node, việc đó sẽ cực kỳ hữu dụng cho operation và maintainance, chẳng hạn như rolling upgrade. Trong cloud env, nếu 1 VM hoạt động không ổn, bạn có thể KILLING nó với hi vọng things go well
- Ở khoảng cách xa, giao tiếp chủ yếu đi qua đường internet, chậm và không đáng tin như local network. Supercomputer thường có tất cả các node gần nhau.
Từ những điều trên, chúng ta phải chấp nhận khả năng partial failure và build cơ chế fault-tolerance vào trong software. Chúng ta cần build 1 hệ thống đáng tin cậy từ những thành phần không đáng tin cậy. Kể cả hệ thống nhỏ với chỉ vài node cũng cần phải nghĩ tới partial failure, phòng khi có biến.
1.1.1 Xây dựng hệ thống tin cậy từ những thành phần không đáng tin cậy
- Error-detecting code xử lý sai số bits trong quá trình giao tiếp
- IP tầng 3 không đáng tin cậy (drop, delay, dupplicate, reorder) -> TCP tầng 4 (retranmission, loại bỏ trùng lặp, sắp xếp lại gói tin theo thứ tự ban đầu)
Nhưng, luôn có 1 giới hạn về mức độ tin cậy nó có thể đảm bảo.
2. Unreliable Networks
Hệ thống phân tán chúng ta đề cập tới là share-nothing systems, có memory và disk riêng, không thể access lẫn nhau. Dominant approach để xây dựng internet services, vì nhiều lý do:
- Rẻ vì không yêu cầu phần cứng đặc biệt
- Tận dụng cloud thông dụng
- Tính tin cậy cao do redundancy (hệ thống dự phòng)
The internet and most internal networks in datacenters (often Ethernet) are asynchronous packet networks.
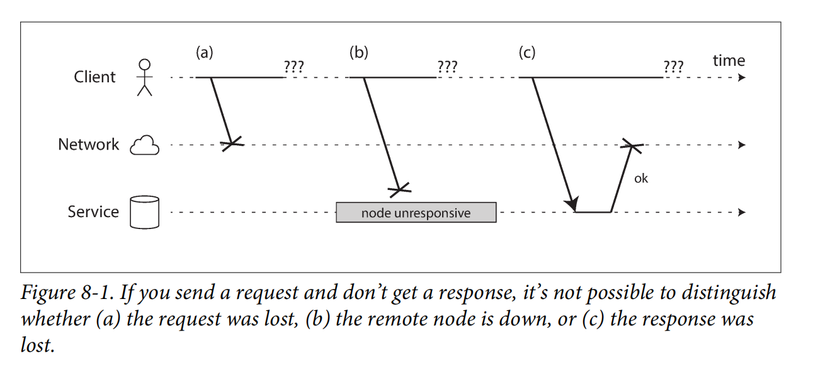
Cách xử lý hữu dụng trong tình huống này là timeout, tuy nhiên kể cả vậy thì vẫn không biết được remote node có nhận được request hay không.
2.1 Network Faults in Practice
Dựa theo một số nghiên cứu có hệ thống, và nhiều chuyện đồn thì...lỗi mạng khá là phổ biến.
1 nghiên cứu chỉ ra datacenter loại trung bình có khả năng ăn 12 lỗi mạng/tháng, 1 nửa trong số đó làm mất kết nối mạng máy đơn, nửa còn lại làm mất mạng nguyên 1 hàng máy.
1 nghiên cứu khác đo lường tỷ lệ lỗi của các thành phần mạng như:
- Switch cấp rack (Top-of-rack switches)
- Switch tổng hợp (Aggregation switches)
- Bộ cân bằng tải (Load balancers)
Kết quả cho thấy việc thêm thiết bị mạng dự phòng không giảm lỗi nhiều như mong đợi. Lý do: Dự phòng chỉ giúp chống lại lỗi phần cứng, nhưng không thể ngăn lỗi do con người (human error), chẳng hạn như cấu hình sai switch, vốn là nguyên nhân chính gây gián đoạn hệ thống.
Dịch vụ đám mây công cộng (như EC2) thường gặp sự cố mạng tạm thời, trong khi trung tâm dữ liệu riêng có thể ổn định hơn. Mặc dù vậy, Không ai tránh được lỗi mạng:
- Nâng cấp phần mềm switch có thể gây tái cấu trúc mạng, làm chậm gói tin hơn 1 phút.
- Cá mập cắn cáp quang dưới biển có thể làm gián đoạn kết nối.
- Lỗi mạng bất thường: Card mạng có thể gửi dữ liệu đi nhưng không nhận được
Khi 1 phần của mạng mất kết nối với phần còn lại, ta gọi đó là network partition, hay là netsplit.
2.2 Detecting Faults
Nhiều hệ thống tự động phát hiện lỗi:
- Load balancer dừng gửi request tới node chết
- Distributed db với single leader replication. Nếu leader chết, follower được promote
Sự không tin cậy về mạng khiến chúng ta không chắc chắn 1 node có đang hoạt động hay không. Trong 1 số trường hợp cụ thể, ta có thể nhận phản hồi giúp nắm bắt tình hình:
- Nếu có thể tiếp cận máy mà node đáng ra đang chạy trên đó, nhưng không có process nào lắng nghe tại destination port -> OS hỗ trợ đóng hoặc từ chối TCP connection bằng cách gửi packet FIN hoặc RST. Tuy nhiên nếu node crash khi đang thực hiện request, không cách nào biết request của bạn đã được xử lý tới đâu.
- Nếu 1 node crash nhưng OS của node vẫn chạy, 1 script có thể thông báo tình hình tới các node khác nhằm mục đích tiếp quản -> không phải chờ hết timeout. HBase thực hiện điều này.
- Nếu có quyền access tới giao diện quản lý của bộ chuyển mạch trong datacenter, bạn có thể truy vấn để phát hiện lỗi ở tầng hardware. Tuy nhiên điều này không thể nếu: bạn kết nối qua internet (firewall chặn), hoặc không có quyền access vào switches, hoặc không thể tiếp cận giao diện quản lý do vấn đề mạng.
- Nếu IP mà bạn connect tới không thể liên hệ được -> nó có thể phản hồi với ICMP Destination Unreachable. Tuy nhiên router không phải luôn phản hồi đúng(router/firewall có thể bị cấu hình chặn ICMP), và cũng có không có khả năng phát hiện lỗi thần kỳ luôn.
Phản hồi nhanh thì hữu dụng, nhưng không trông chờ hoàn toàn được. Kể cả khi packet deliver, hoàn toàn có khả năng app crash trước/đang xử lý. Nếu muốn đảm bảo request thành công, cần chờ phản hồi từ bản thân app. Trong trường hợp không có response có thể retry thêm vài lần, chờ timeout, hoặc có thể đánh dấu node đã chết nếu không thấy có dấu hiệu phản hồi.
2.3 Timeouts and Unbounded Delays
Định ra thời gian timeout không phải là 1 vấn đề đơn giản.
Too long timeout: user phải chờ hoặc thấy message lỗi
Too short timeout: rủi ro nhầm lẫn, trong khi vấn đề chỉ là tạm thời. Nếu node được định là đã chết (node A) vẫn còn sống, và đang thực hiện tác vụ, việc định ra 1 node B khác đứng ra thay thế sẽ khiến tác vụ được thực hiện 2 lần. Ngoài ra thì, trách nhiệm của node A sẽ được chuyển giao cho các node khác, làm tăng tải lên các node khác và mạng. Nếu hệ thống đang chịu tải lớn, điều này có thể khiến mọi chuyện diễn biến tệ, tạo ra 1 cascading failure. Tệ nhất là khi tất cả các node đều xác định lẫn nhau là đã chết và mọi thứ dừng luôn -_-
Tưởng tượng 1 packet luôn được gửi đi trong time d, với thời gian xử lý tối đa là r -> tổng thời gian < 2d + r -> 2d + r là timeout lý tưởng để chọn. Tuy nhiên thì async network có unbounded delay(không có giới hạn trên), và hầu hết các triển khai đều không thể đảm bảo được xử lý trong 1 khoảng thời gian r.
2.3.1 Tắc nghẽn mạng và hàng đợi
Hàng đợi network switch, OS, VM, TCP flow control.
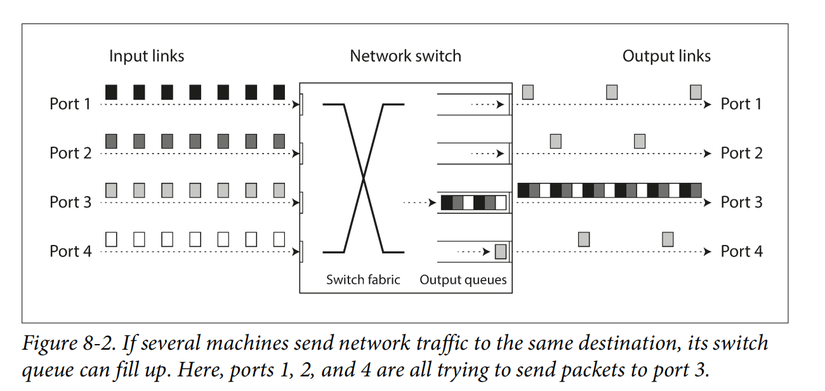
TCP vs. UDP
TCP: Đảm bảo độ tin cậy nhưng có thể gây độ trễ biến đổi do kiểm soát luồng và truyền lại gói tin.
UDP: Không kiểm soát luồng, không gửi lại gói tin mất, giúp giảm độ trễ nhưng không đảm bảo dữ liệu đến nơi.
Ứng dụng UDP tiêu biểu: VoIP, video call: Nếu một gói tin bị mất, không có thời gian để gửi lại, ứng dụng phải chấp nhận mất dữ liệu (ví dụ: mất âm thanh tạm thời).
Biến động độ trễ trong môi trường đám mây:
- Tài nguyên mạng trong cloud & datacenter đa khách hàng (multi-tenant) bị chia sẻ → độ trễ thay đổi lớn nếu có "hàng xóm ồn ào" (noisy neighbor) sử dụng nhiều băng thông.
- Batch workloads như MapReduce (mô hình lập trình của Google) có thể làm nghẽn mạng đột ngột.
Cách xử lý timeout hiệu quả:
Timeout nên được xác định dựa trên ** thực nghiệm**:
- Đo thời gian truyền khứ hồi trên nhiều máy, trong thời gian dài.
- Điều chỉnh để cân bằng giữa phát hiện lỗi nhanh và tránh timeout sai.
Để tối ưu hơn thì:
- Sử dụng Phi Accrual failure detector (như trong Akka, Cassandra) để tự động điều chỉnh timeout dựa trên biến động độ trễ.
- TCP cũng có cơ chế timeout động tương tự.
2.4 Synchronous Versus Asynchronous Networks
Mạng điện thoại cực kỳ đáng tin cậy, nhưng lượng data fixed. Bởi vì không có queuing -> bounded delay. Circuit Switching.
TCP connection khác hoàn toàn: dùng băng thông khả dụng, lượng data không rõ kích thước, cố gắng gửi trong thời gian nhanh nhất có thể. Nó không chiếm băng thông khi nó idle. Packet Switching.
Tại sao Ethernet và IP lại chọn packet switching. Bởi vì nó optimize cho busty traffic. Request thông thường sẽ không rõ dung lượng, chúng ta chỉ cần gửi nó nhanh nhất có thể.
Nếu muốn gửi 1 file qua circuit switching, nếu đoán băng thông quá thấp -> chuyển chậm do network capacity không được sử dụng hết. Nếu đoán băng thông cao, circuit không thể setup được, bởi băng thông cấp phát phải được đảm bảo. Ở chiều ngược lại thì TCP đáp ứng được lượng dữ liệu chuyển phát qua mạng khả dụng.
Một số nỗ lực đã được thực hiện để xây dựng hybrid networks kết hợp cả circuit switching và packet switching, chẳng hạn như ATM (Asynchronous Transfer Mode). Tuy nhiên, ATM không được chấp nhận rộng rãi ngoài các switch mạng cốt lõi của hệ thống điện thoại. Một công nghệ tương tự là InfiniBand, hỗ trợ kiểm soát luồng từ đầu đến cuối ở tầng liên kết, giúp giảm nhu cầu xếp hàng. Mặc dù mạng vẫn có thể bị tắc nghẽn, việc sử dụng chất lượng dịch vụ (QoS) và kiểm soát truy cập (admission control) có thể giúp mô phỏng chuyển mạch kênh trên mạng gói hoặc cung cấp độ trễ có giới hạn có thể thống kê được.
Độ trễ biến đổi là hệ quả của việc phân chia tài nguyên động (dynamic resource partitioning). Ví dụ, trong mạng điện thoại cố định, băng thông được cấp phát tĩnh, ngay cả khi không sử dụng hết, trong khi Internet chia sẻ băng thông động, giúp tối ưu tài nguyên nhưng gây ra xếp hàng (queueing). Tương tự, CPU cũng được chia sẻ động giữa nhiều luồng (threads), dẫn đến việc một luồng có thể bị trì hoãn khi chờ CPU, nhưng cách này tận dụng phần cứng tốt hơn so với việc cấp phát tài nguyên cố định. Đảm bảo độ trễ thấp có thể đạt được bằng cách cấp phát tài nguyên tĩnh, nhưng điều này làm giảm hiệu suất và tốn kém hơn. Ngược lại, chia sẻ động giúp tối ưu hóa sử dụng tài nguyên và giảm chi phí, nhưng đánh đổi bằng độ trễ biến đổi.
Phần hay vẫn còn, nhưng mình sẽ để dành bài sau nhé. Vì.. dài quá thì ai xem?
All rights reserved
