Những câu hỏi trong phỏng vấn Deep Learning - P2
Bài đăng này đã không được cập nhật trong 6 năm
Overfitting là gì?
Khi mô hình của bạn rất khớp với tập huấn luyện, cho ra giá trị loss function thấp trên tập train nhưng khi đưa vào các dữ liệu mới thì lại không phù hợp, cho kết quả rất tồi. Overfitting xảy ra khi mô hình quá phức tạp để mô phỏng training data. Điều này đặc biệt xảy ra khi lượng dữ liệu training quá nhỏ trong khi độ phức tạp của mô hình quá cao.
Underfitting là gì?
Là mô hình của bạn không phù hợp cả với tập huấn luyện và cả tập các dữ liệu mới (hay gọi là tập test). Nguyên nhân có thể là do mô hình của bạn chưa đủ độ phức tạp cần thiết để bao quát được tập dữ liệu.
Good Fitting là gì?
Là mô hình phù hợp với cả tập dữ liệu huấn luyện và tập dữ liệu test. Tuy nhiên để đạt được mô hình như vậy thì cần có sự nghiên cứu tỉ mỉ.
Làm thế nào để có thể nhận biết là có bị overfitting hay không ?
Chúng ta có thể dựa vào một số độ đo để đánh giá xem mô hình có bị overfitting hay không. Chúng ta dựa vào độ đo trung bình lỗi của mô hình đối với từng tập dữ liệu để đánh giá. Ta có công thức tính trung bình độ lỗi với tập dữ liệu có m phần tử:
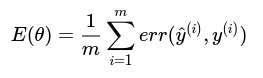
Như vậy, khi dữ liệu của ta sẽ được phân chia làm 3 phần là tập huấn luyện (training set), tập kiểm chứng (cross validation set) và tập kiểm tra (test set). Ứng với mỗi phần ta sẽ đưa ra thông số lỗi tương ứng:
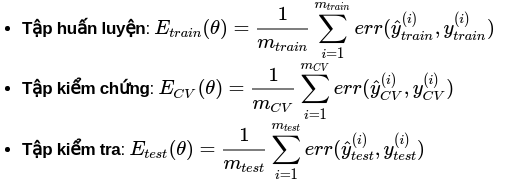
Dựa vào những độ lớn của hàm lỗi trên ta có thể nhận ra được:
- Underfitting thì lớn
- Overfitting thì nhỏ, còn lớn.
- Good fitting thì đều nhỏ.
Hãy nêu một số kỹ thuật để tránh overfitting?
Chúng ta có thể sử dụng kỹ thuật validation(validation, Cross-validation) hoặc Regularization (Early Stopping, l2 regularization,..., và bây giờ thì người ta thường sử dụng một kỹ thuật khác gọi là Dropout.
Ảnh RGB là gì. Trong xử lý dữ liệu thì ảnh RGB thường được biểu diễn như thế nào?
Ảnh RGB là ảnh gồm 3 màu, Red, Green và Blue. Giá trị mỗi màu nằm trong từ [0-255]. Do có 256 cách chọn r, 256 cách chọn màu g, 256 cách chọn b => tổng số màu có thể tạo ra bằng hệ màu RGB là: 256 * 256 * 256 = 16777216 màu !!!
Trong xử lý dữ liệu thì ảnh RGB được biểu diễn bằng tensor có shape (Height, Width, channel), với channel ở đây là 3.
Ảnh xám là gì? Biểu diễn ảnh xám như thế nào ?
Ảnh xám là ảnh chỉ được biểu diễn bởi một ma trận với một điểm ảnh có giá trị trong khoảng [0-255]. Biểu diễn ảnh xám bằng ma trận.
Phép tính convolution được thực hiện như thế nào. Ý nghĩa của phép tính convolution.
Bạn có thể tìm hiểu về phép tính convolution tại đây.
Ý nghĩa của phép tính convolution: Mục đích của phép tính convolution trên ảnh là làm mờ, làm nét ảnh; xác định các đường;... Mỗi kernel khác nhau sẽ có ý nghĩa khác nhau. Bạn có thể tham khảo một số kener sau tại đây
Padding là gì? Stride là gì ?
Padding=k nghĩa là thêm k vector 0 vào mỗi phía của ma trận.

Stride :
Ta thực hiện tuần tự các phần tử trong ma trận X, thu được ma trận Y cùng kích thước ma trận X, ta gọi là stride=1.
Stride thường dùng để giảm kích thước của ma trận sau phép tính convolution.
Pooling layer là gì ?
Pooling layer thường được dùng giữa các convolutional layer, để giảm kích thước dữ liệu nhưng vẫn giữ được các thuộc tính quan trọng. Kích thước dữ liệu giảm giúp giảm việc tính toán trong model.
Gọi pooling size kích thước K * K. Input của pooling layer có kích thước H * W* D, ta tách ra làm D ma trận kích thước H * W. Với mỗi ma trận, trên vùng kích thước K* K trên ma trận ta tìm maximum hoặc average của dữ liệu rồi viết vào ma trận kết quả. Quy tắc về stride và padding áp dụng như phép tính convolution trên ảnh.
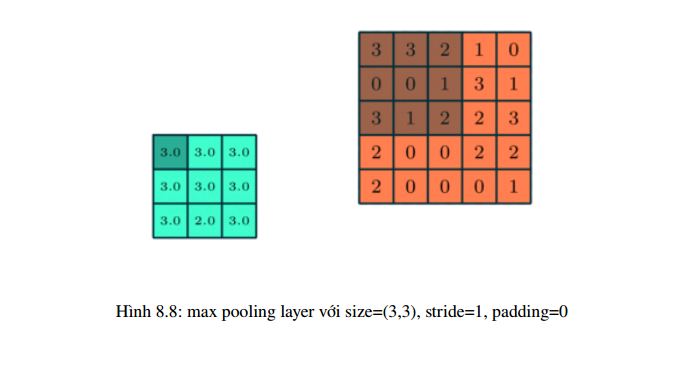
Nhưng hầu hết khi dùng pooling layer thì sẽ dùng size=(2,2), stride=2, padding=0. Khi đó output
width và height của dữ liệu giảm đi một nửa, depth thì được giữ nguyên .
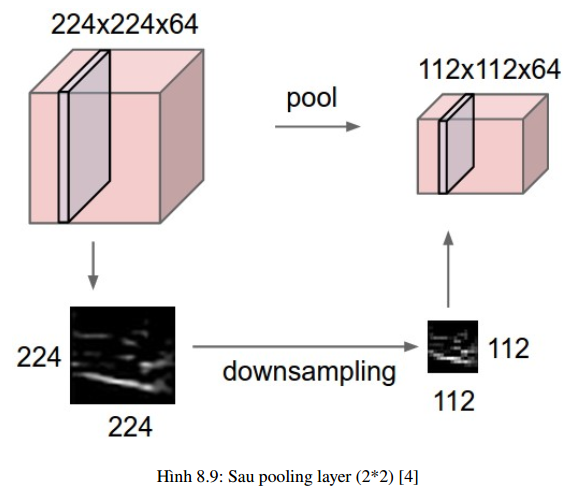
Có 2 loại pooling layer phổ biến là: max pooling và average pooling.

Trong một số model người ta dùng convolutional layer với stride > 1 để giảm kích thước dữ liệu thay cho pooling layer.
Tại sao sử dùng nhiều kernel khác nhau trong convolution layer?
Với mỗi kernel khác nhau ta sẽ học được những đặc trưng khác nhau của ảnh, nên trong mỗi convolutional layer ta sẽ dùng nhiều kernel để học được nhiều thuộc tính của ảnh. Vì mỗi kernel cho ra output là 1 matrix nên k kernel sẽ cho ra k output matrix. Ta kết hợp k output matrix này lại thành 1 tensor 3 chiều có chiều sâu k.
 Output của convolutional layer này sẽ thành input của convolutional layer tiếp theo.
Output của convolutional layer này sẽ thành input của convolutional layer tiếp theo.
Lưu ý: Output của convolutional layer sẽ qua hàm activation function trước khi trở thành input của convolutional layer tiếp theo.
Một số câu hỏi khác:
So sánh regularization và regularization?
BatchNorm là gì?
Tại sao BatchNorm giúp thuật toán tối ưu deep learning hội tụ nhanh hơn?
Nêu sự khác nhau của pha training và pha test khi thực hiện BatchNorm.
Khi thực hiện mini-batch gradient desecent, việc mini-batch nhỏ hay lớn có ảnh hưởng như thế nào tới kết quả? Nêu ưu nhược điểm của mini-batch với kích thước nhỏ hoặc lớn.
Trong một bài toán, giả sử rằng thuật toán mini-batch gradient descent làm việc tốt với mini-batch lớn. Tuy nhiên, vì bộ nhớ có giới hạn, ta không thể tính được bachprogagation với mini-batch lớn. Có cách nào sử dụng backpropagation với mini-batch nhỏ để có hiệu quả tương tự như khi sử dụng mini-batch lớn?
Imbalanced data problem là gì?
Có những cách nào để solve imbalanced data không? (Trình bày về Under-sampling và Over-sampling)
Khi imbalanced thì nên dùng bộ đo nào để đo độ chỉnh xác của model? (Hỏi về Confusion matrix, ROC Curve)
All rights reserved
