Nhật ký học Hibernate từ số 0
HIBERNATE
MỞ ĐẦU
- Trong mục chương trình Java tương tác với cơ sở dữ liệu, chúng ta xây dựng chương trình Java sao cho mỗi bảng trong cơ sở dữ liệu ứng với một class trong phần Models của chương trình Java. Sau đó chúng ta viết code pure Java để kết nối chương trình với cơ sở dữ liệu, qua đó thực hiện những câu lệnh SQL theo cách viết trực tiếp lệnh đó vào trong chương trình Java và truyền nó cho đối tượng Statement để thực hiện lệnh đó lên CSDL.
- Như vậy tính liên kết giữa đối tượng đã xây dựng trong Models và CSDL chưa được chặt chẽ, mình đang ngộ nhận rằng chúng có liên kết với nhau vì chúng giống nhau, trong khi sự giống nhau đó lại là do mình xây dựng. Nếu chúng thực sự liên kết với nhau, mình chỉ cần tác động lên Models (thêm/sửa/xóa dựa vào Models) là đã có thể thay đổi dữ liệu trong CSDL. Không yêu cầu viết hẳn câu lệnh SQL vào trong chương trình Java, mà chỉ cần thông qua các câu lệnh dựng sẵn để thực hiện. (lúc đó tính “ánh xạ” giữa bảng trong CSDL và Objects trong Models rất rõ).

HIBERNATE
Đây là nhật ký học Hibernate với Java của một đứa chưa biết gì về Java EE, mới chỉ học qua OOP với Java. Bài viết chắc chắn có nhiều điểm sai sót và lệch lạc, xin mọi người thông cảm. Link tham khảo mình có để ở từng phần cụ thể.
Cảm ơn mọi người.
Docs: https://docs.jboss.org/hibernate/orm/current/userguide/html_single/Hibernate_User_Guide.html
KHÁI NIỆM
Định nghĩa
- Hibernate là một framework trong java.
- Cụ thể hơn, Hibernate là một framework ORM (Object-Relational Mapping) trong Java. Dịch ra là “ánh xạ các đối tượng quan hệ”, cụ thể là ánh xạ các bảng trong cơ sở dữ liệu quan hệ tới các lớp đối tượng mô phỏng (models) trong chương trình Java.
- Nếu không dùng Hibernate thì mình phải làm những gì?
Nếu không sử dụng Hibernate, mọi thao tác truy xuất dữ liệu với CSDLQH (load Driver, tạo Statement, viết câu lệnh thủ công, thao tác với ResultSet, …) đều phải viết thủ công. Nếu sử dụng Hibernate, các thao tác đó sẽ được viết code bằng Java, cụ thể hơn là dưới dạng Hibernate Query Language (HQL).
Giới thiệu các thành phần
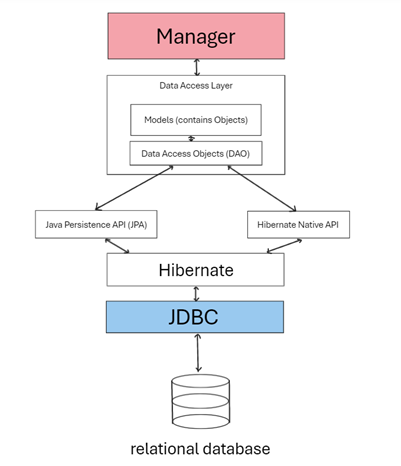
Theo sơ đồ thì phần liên quan đến hiberate sẽ xử lý cho mình phần liên kết chương trình từ Manager (Controller) tới JDBC. Qua đó cũng sẽ phát sinh thêm một vài thay đổi với phần Models và DAO so với dùng pure Java.
Giải thích cho từng phần:
- Data Access Layer: phần này bao gồm những phần có dính líu tới cơ sở dữ liệu (Models và một phần Utils DAO). Phần này sẽ bị thay đổi so với bên docs1, sử dụng pure Java.
- Java Persistence API (JPA): là một API phục vụ việc ánh xạ giữa các đối tượng Java (Models) với cơ sở dữ liệu quan hệ. Nó đóng vai trò như cầu nối từ Java Models tới CSDL, giữ quan hệ một một cho table – objects trong mối liên kết.
https://gpcoder.com/6282-tong-quan-ve-jpa-java-persistence-api/
- Hibernate Native API: là một API nằm trong Hibernate Framework, cho phép thực thi các truy vấn SQL native trực tiếp vào cơ sở dữ liệu thay vì sử dụng Hibernate Query Language (HQL). Dùng trong trường hợp HQL hết cứu. Nhưng phải dùng cẩn thận nếu không sẽ dính SQL Injection. (nói sau đi).
=> Có thể hiểu JPA là cách tiếp cận mới như đang mong đợi trong phần Hibernate này. Nhưng đôi khi nó không thể nào thực thi hết được với những câu lệnh phức tạp (HQL hết cứu) nên phải dùng câu lệnh pure SQL để cứu. Lúc đó là lúc Hibernate Native API hoạt động.
- Hibernate: phần module này cung cấp khả năng chuyển đổi các yêu cầu nhận được từ JPA và HNA để biến đổi thành câu lệnh SQL, sau đó chuyển xuống JDBC yêu cầu thực thi.
- JDBC: như đã viết thì JDBC tạo kết nối tới CSDL, mở một Connection và thực thi câu lệnh (từ module Hibernate), sau đó đóng Connection và trả về kết quả lên các tầng cao hơn.
CHI TIẾT CÁC THÀNH PHẦN
ORM và JPA
ORM
- Như đã nói ở trên, ORM (Object-Relational Mapping - dịch ra là “ánh xạ các đối tượng quan hệ”), là một kỹ thuật để định nghĩa sự ánh xạ giữa các đối tượng (trong Models) và các table (CSDL).
- Nhờ vào kỹ thuật này, mỗi table trong CSDL sẽ được xây dựng cho một đối tượng trong chương trình, và chúng được liên kết bởi các annotation và lệnh trong file cấu hình (config XML).
- Nguyên tắc hoạt động:
(tìm mãi không có cái docs nào nói. Đọc source thì cũng không có gì đặc biệt)

Các class được xây dựng tương tự thông thường, rồi được thêm vào các annotations,
phần code XML thì có các lệnh cấu hình cho các class trên,
dựa vào đó Hibernate sẽ tìm được vị trí của các class Models rồi dựa vào thông tin đã có trên annotations để biết được class nào ánh xạ tới table nào.
JPA (Java Persistence API)
- Mở đầu:
- Như phần giới thiệu bên trên, JPA là “một API phục vụ việc ánh xạ giữa các đối tượng Java (Models) với cơ sở dữ liệu quan hệ”, là một đặc tả tiêu chuẩn của Java cho phép các ứng dụng Java quản lý dữ liệu quan hệ trong cơ sở dữ liệu theo một cách hướng đối tượng.
- Cụ thể hơn, JPA là một framework bao gồm các interface và abstract class (API), được xây dựng với các thành phần các Annotations, EntityManager, EntityManagerManager,… (đừng hỏi interface gì và abstract class gì)
- Với cấu trúc như vậy JPA có thể sử dụng kỹ thuật ORM như bên trên để cung cấp sự ánh xạ giữa các đối tượng Java (Models) với các table trong CSDLQH.
- Tuy nhiên JPA lại là một API của Java EE (Enterprise Edition – Java bản mở rộng) chứ không có trong Java SE (Standard Edition – Java bản cơ bản). Muốn sử dụng JPA trong Java SE thì phải sử dụng từng thư viện riêng lẻ.
(Một khi code với Java EE thì bắt đầu làm quen với JAVA MAVEN).
- Chi tiết:
- Các thành phần trong JPA:
Chúng ta có thể thấy trong docs cái cảnh này:

Sau khi đơn giản hóa đi thì có được sơ đồ như sau:
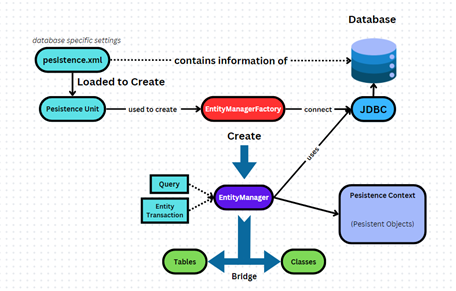
Nhìn vẫn rất rối. Bây giờ sẽ quan sát từ từ. Ở đây nhận thấy nơi phức tạp nhất là EntityManager (vẫn chưa biết chúng nó là gì, nhưng sẽ phân tích từ đó).

Phân biệt giữa entities, class, objects, table trong bối cảnh sử dụng JPA:
-
-
- Entity: Lớp Java (Java class) được ánh xạ tới một bảng (table) trong cơ sở dữ liệu, đánh dấu bằng @Entity.
- Class: Kiểu dữ liệu trong lập trình hướng đối tượng, trở thành entity nếu đánh dấu bằng @Entity.
- Object: Thực thể cụ thể của một class, tương ứng với một hàng (row) trong bảng cơ sở dữ liệu.
- Table: Bảng trong cơ sở dữ liệu, chứa dữ liệu dưới dạng hàng và cột, được ánh xạ từ entity class, tùy chỉnh bằng @Table.
- Entity: Lớp Java (Java class) được ánh xạ tới một bảng (table) trong cơ sở dữ liệu, đánh dấu bằng @Entity.
-
- EntityManager:
-
- Là phần quản lý đối tượng thực thể (Pesistent Objects) trong một “bối cảnh” nhất định – có thể hiểu là trong một thời điểm/ khu lưu trữ của Pesistent Objects nhất định với mỗi lần sử dụng đến nó. (Pesistence Context – dưới nói sau)
- EntityManager cung cấp các phương thức CRUD với các Entity từ CSDL.
- Là phần quản lý đối tượng thực thể (Pesistent Objects) trong một “bối cảnh” nhất định – có thể hiểu là trong một thời điểm/ khu lưu trữ của Pesistent Objects nhất định với mỗi lần sử dụng đến nó. (Pesistence Context – dưới nói sau)
-
Đối với pure Java, chức năng này phải tự viết dựa vào JDBC. Thực tế thì để thực hiện được chức năng này EntityManager cũng dựa vào JDBC để có thể thực hiện CRUD.
-
-
- Được sử dụng để thực thi các truy vấn nói trên bằng cách sử dụng các lệnh query.
- Điểm đặc biệt của EntityManager là thực hiện truy vấn bằng các transaction để tăng tính toàn vẹn dữ liệu.
- Được sử dụng để thực thi các truy vấn nói trên bằng cách sử dụng các lệnh query.
-
- Pesistence Context:
-
- Dịch ra nghĩa đen thì nó là “Bối cảnh lưu trữ”.
- Cụ thể hơn thì nó là một bộ nhớ đệm tạm thời chứa các đối tượng thực thể trước khi chúng được lưu hoặc sau khi chúng được tải từ cơ sở dữ liệu. (tác dụng như Buffer)
- Pesistence Context luôn đảm bảo tính đồng nhất: đảm bảo mỗi thực thể được quản lý chỉ có một bản sao duy nhất trong một Persistence Context. (có nghĩa là nếu truy vấn một đối tượng nhiều lần trong cùng một Persistence Context, bạn sẽ luôn nhận được cùng một đối tượng, không phải các bản sao khác nhau)
- Pesistence Context có tính đồng bộ hóa: sau mỗi lần transaction commit (của EntityManager) thì Pesistence Context sẽ được đồng bộ lại với database: gần như cách buffer hoạt động: đem lên một phần dữ liệu tạm lên trên chương trình, mỗi lần chương trình thực hiện xong sẽ có một hành động là “flush” xuống database.
- Persistence Context quản lý vòng đời của các đối tượng thực thể (entities), từ khi chúng được tạo, cập nhật cho đến khi bị xóa.
- Dịch ra nghĩa đen thì nó là “Bối cảnh lưu trữ”.
-
Thực tế là một khi chạy một request của user, chỉ một EntityManager tồn tại trong thời điểm đó, nên chỉ một Persistence Context được có mặt để thực hiện request đó. Hay đơn giản hơn là 1 yêu cầu của khách hàng sẽ gọi đến 1 phần database, và lệnh gọi đó (EntityManager) đem lên một phần database cần thiết bỏ vào không gian thực thi – tạm (Persistence Context) để làm việc. Làm việc xong thì đóng luôn EntityManager đó, nên Persistence Context cũng biến mất. Và các đối tượng thực thể (entities) sẽ tồn tại và được quản lý trong phần đời của Persistence Context hiện tại.
-
-
- Các trạng thái của một thực thể trong một vòng đời Persistence Context:
-
new (Transient – tạm thời): thực thể được tạo ra nhưng chưa được quản lý bởi Persistence Context, cũng chưa được lưu vào database. => Không có ID được gán từ cơ sở dữ liệu.
Managed (Persistent – bền vững): thực thể đang được Persistence Context quản lý và đồng bộ với database. => Thực thể có ID duy nhất, được gán từ database.
Detached: thực thể từng được quản lý nhưng hiện không còn nằm trong Persistence Context. => Thực thể có ID từ cơ sở dữ liệu nhưng thay đổi trên nó sẽ không được đồng bộ với database.
Removed: thực thể được đánh dấu để xóa khỏi database khi transaction kết thúc. => Thực thể vẫn được quản lý bởi Persistence Context cho đến khi transaction kết thúc.
-
-
- Quan hệ và sự chuyển hóa giữa các trạng thái:
-
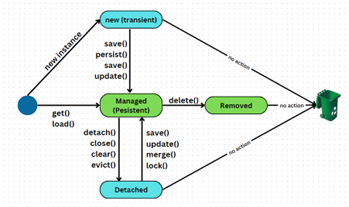
Trong chỗ này có 2 trạng thái được quản lý bởi Persistence Context là Managed và Removed thôi. Các quan hệ còn lại cũng được mô tả trong hình khá rõ rồi nên sẽ không nói thêm.
- EntityManagerFactory
-
- Là một interface trong JPA đại diện cho một kết nối tới cơ sở dữ liệu theo cấu hình của ứng dụng (pesistence.xml – nói sau).
- EntityManagerFactory có chức năng tạo và quản lý EntityManager.
- Ngoài ra EntityManagerFactory nhận cấu hình từ pesistence.xml và cung cấp nó cho những bên cần thiết như JDBC. EntityManagerFactory sử dụng JDBC để thiết lập các kết nối cơ sở dữ liệu ban đầu và tạo ra các EntityManager. Tuy nhiên, nó không trực tiếp thực hiện các truy vấn hoặc thao tác cơ sở dữ liệu.
- Vòng đời của một EntityManagerFactory và quan hệ của chúng với vòng đời của app và EntityManager như sau:
- Là một interface trong JPA đại diện cho một kết nối tới cơ sở dữ liệu theo cấu hình của ứng dụng (pesistence.xml – nói sau).
-
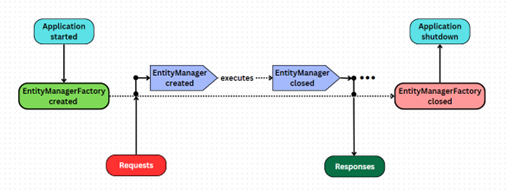
Hình miêu tả khá rõ rồi nên không cần thêm mô tả thêm nữa. (quá lười để viết thêm nên nhờ GPT viết):
Hình minh họa trên mô tả chu trình sống của `EntityManagerFactory` và `EntityManager` trong Java Persistence API (JPA). Khi ứng dụng bắt đầu, `EntityManagerFactory` được tạo ra, đây là một đối tượng singleton và chỉ được khởi tạo một lần trong suốt thời gian chạy của ứng dụng. Từ `EntityManagerFactory`, các `EntityManager` được tạo ra để quản lý các thực thể và thực hiện các hoạt động như truy vấn, cập nhật, và xóa trên cơ sở dữ liệu. Ứng dụng gửi các yêu cầu đến `EntityManager`, và `EntityManager` sẽ xử lý các yêu cầu này và trả về phản hồi tương ứng. Sau khi hoàn thành công việc, `EntityManager` được đóng lại để giải phóng tài nguyên. Cuối cùng, khi ứng dụng dừng, `EntityManagerFactory` cũng được đóng lại để giải phóng các tài nguyên còn lại. Chu trình này phản ánh đúng cách hoạt động cơ bản của JPA.
- Khác nhau giữa EntityManagerFactory và EntityManager trong khi sử dụng JDBC: EntityManagerFactory chịu trách nhiệm thiết lập và quản lý các kết nối cơ sở dữ liệu cần thiết cho toàn bộ ứng dụng. Nó được tạo ra khi ứng dụng khởi động và tồn tại trong suốt vòng đời của ứng dụng. Còn EntityManager sử dụng thông tin cấu hình từ tệp persistence.xml để thiết lập các kết nối JDBC tới cơ sở dữ liệu. EntityManagerFactory không trực tiếp thực hiện các truy vấn hay cập nhật dữ liệu; thay vào đó, nó tạo ra các EntityManager để thực hiện các thao tác này.
- pesistence.xml và pesistence unit
+) pesistence.xml chứa các thông tin cần thiết để JPA có thể kết nối và làm việc với cơ sở dữ liệu. Cấu hình trong persistence.xml sẽ bao gồm các thông tin như:
. Tên đơn vị lưu trữ (Persistence Unit)
. Các thuộc tính kết nối cơ sở dữ liệu (URL, username, password, driver class)
. Các lớp entity mà JPA sẽ quản lý
. Các thuộc tính JPA (như chế độ gỡ lỗi, chiến lược tạo bảng...)
…
+) Persistence Unit là đại diện cho một tập hợp các lớp thực thể (entity classes) và các cài đặt liên quan (như các thuộc tính kết nối cơ sở dữ liệu).
Mỗi persistence unit được quản lý như một đơn vị riêng biệt.
Mỗi persistence unit phải có một tên định danh duy nhất (được xác định bằng thuộc tính name). Tên này được sử dụng trong mã nguồn Java để tham chiếu đến đơn vị lưu trữ này khi tạo EntityManagerFactory.
Khi tạo EntityManagerFactory bằng cách sử dụng tên của persistence unit, JPA sẽ đọc persistence.xml, tìm persistence unit tương ứng và khởi tạo EntityManagerFactory dựa trên các cấu hình này. EntityManagerFactory sau đó quản lý các đối tượng EntityManager, cho phép tương tác với cơ sở dữ liệu theo các cài đặt đã định nghĩa trong persistence.xml.
- Một quy trình hoàn thiện cho sơ đồ trên:
Nhắc lại sơ đồ:
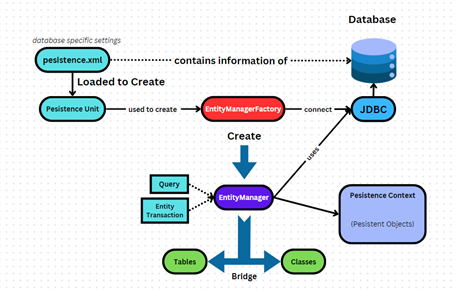
pesistence.xml chứa thông tin cấu hình của database và chứa pesistence unit đại diện cho một tập hợp các lớp thực thể trong database.
Với mỗi chương trình ứng dụng, EntityManagerFactory lấy thông tin cấu hình trên để kết nối với JDBC, còn lấy pesistence unit để tạo ra EntityManager, đi kèm nó là không gian bộ nhớ tạm – Bối cảnh lưu trữ (Pesistent Context).
EntityManager thường được tạo ra khi bắt đầu một request và được sử dụng lại cho toàn bộ quá trình xử lý request đó.
EntityManager sử dụng JDBC để thực thi các câu lệnh truy vấn và cập nhật các thực thể trong bối cảnh lưu trữ (Persistent Context).
Sau khi request hoàn thành, EntityManager sẽ được đóng (closed) và không sử dụng lại.
https://www.java4coding.com/contents/jpa/jpa-architecture
Hibernate Native API
Theo hình mô tả từ ban đầu thì Hibernate Native API nằm ngang hàng với JPA. Vậy chức năng chính của Hibernate Native API cũng tương tự như JPA: dựa vào JDBC để thao tác với cơ sở dữ liệu. Cụ thể hơn thì như sau:
TỔNG QUÁT
- Định nghĩa: Hibernate Native API là một tập hợp các giao diện và lớp mà Hibernate cung cấp để thao tác trực tiếp với cơ sở dữ liệu mà không cần phải qua các lớp trung gian như HQL (Hibernate Query Language). Rõ ràng hơn là nó thực thi câu lệnh pure SQL lên trên CSDL từ chương trình Java.
- Như vậy thì có khác gì JDBC? Mà tại sao nó lại được ngang hàng với JPA? Thực tế HNA không chỉ thực thi một cách thụ động như JDBC làm cho người dùng phải tự khởi tạo kết nối, tự quản lý Statement,.v.v... mà những thao tác đó hoàn toàn tự động. Thêm nữa, HNA không một mình thực thi pure SQL mà dựa vào JDBC để làm việc này. Vì vậy có thể coi HNA như một cấp cao hơn của JDBC.
THÀNH PHẦN

- Phần này thực sự khó để tìm hiểu vì không có docs, mã nguồn cũng không. Tài liệu tìm thấy chỉ nói về cách sử dụng chứ không phân tích cấu trúc của Hibernate Native API.

- Có thể gồm các thành phần như sau (cứ viết nếu sai sẽ sửa sau)
Phần cấu trúc (có thể) cũng tương tự như bên JPA một chút: cũng có phần cấu hình, từ cấu hình tạo được Factory, từ Factory tạo ra các tượng trưng cho các kết nối, rồi từ đó thực hiện các kết nối tới database.
JDBC
- Cái này quen rồi chắc nhắc lại chút cho nhớ:
JDBC (Java Database Connectivity) là một API trong Java giúp kết nối và tương tác với các cơ sở dữ liệu quan hệ. Nó cung cấp một cách để thực thi các câu lệnh SQL, truy vấn cơ sở dữ liệu và xử lý kết quả trả về từ cơ sở dữ liệu.
CÁCH THỨC HOẠT ĐỘNG
Sau khi nói về các thành phần thì sẽ tới phần hoạt động của Hibernate. Thực ra trong lúc nói về các thành phần thì cũng có đề cập qua về cách hoạt động rồi. Bây giờ sẽ nói tổng quan về cách một chương trình tổng quan sẽ hoạt động như thế nào nếu sử dụng framework Hibernate. Mà cũng không hẳn là cách Hibernate hoạt động như thế nào, nói cái đó ở bên trên hết rồi, cụ thể hơn hiện tại cần là mình cài đặt và sử dụng Hibernate như thế nào, và trong từng bước đó thì Hibernate làm gì.
1, Trước hết, nhắc lại tại sao lại là Hibernate chứ không phải pure Java với JDBC.
Đầu tiên sẽ nêu ra những vấn đề với một chương trình JDBC pure Java. Từ đó tìm ra được cách giải quyết/code tốt hơn với Hibernate.
https://www.geeksforgeeks.org/introduction-to-hibernate-framework/
- Vài vấn đề của JDBC có thể nhìn thấy rõ:
- Chuỗi kết nối khác nhau đối với mỗi database và loại database khác nhau:
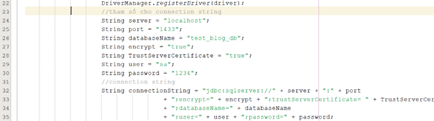
Với mỗi database thì các giá trị của biến databaseName và hầu hết các giá trị kia đều phải thay đổi. Thậm chí nếu đổi loại database (từ SQL server sang MySQL chẳng hạn) thì phải đổi hoàn toàn cách kết nối.
-
- Bắt buộc try/catch:
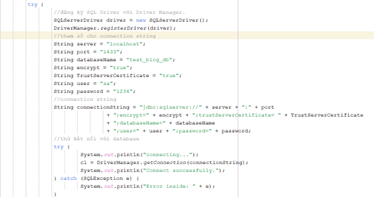
Trong JDBC yêu cầu bắt buộc try/catch cho các kết nối. Tuy nó rõ ràng nhưng khá bất tiện.
-
- Đóng mở kết nối bằng tay:

JDBC yêu cầu đóng mở kết nối mỗi lần thực hiện Statement, làm code dài thêm.
(Boilerplate problem)
Trong khi đó, với Hibernate (theo như quảng cáo) chúng ta có thể:
- Hibernate framework hỗ trợ các hoạt động DDL tự động. Trong JDBC, chúng ta phải tạo bảng theo cách thủ công và khai báo kiểu dữ liệu cho từng cột. Nhưng Hibernate có thể thực hiện các hoạt động DDL cho bạn nội bộ như tạo bảng, xóa bảng, thay đổi bảng, v.v.
(vì nó là ORM mà)
- Hibernate hỗ trợ tạo khóa chính tự động . Điều đó có nghĩa là trong JDBC, chúng ta phải thiết lập khóa chính cho một bảng theo cách thủ công. Nhưng Hibernate có thể thực hiện nhiệm vụ này. (ờ chưa kiểm chứng, lát làm được thì nói sau)
- Khung Hibernate độc lập với Cơ sở dữ liệu vì nó hỗ trợ HQL (Ngôn ngữ truy vấn Hibernate) không dành riêng cho bất kỳ cơ sở dữ liệu nào, trong khi JDBC phụ thuộc vào cơ sở dữ liệu. (ờ chưa kiểm chứng, lát làm được thì nói sau)
- Trong Hibernate, Xử lý ngoại lệ không phải là bắt buộc, trong khi xử lý ngoại lệ trong JDBC là bắt buộc. (ờ chưa kiểm chứng, lát làm được thì nói sau)
- Hibernate hỗ trợ bộ nhớ đệm trong khi JDBC không hỗ trợ bộ nhớ đệm.
- Hibernate hỗ trợ ánh xạ quan hệ đối tượng. Nghĩa là với JDBC, chúng ta đang xử lý những giá trị riêng biệt mà cứ ngộ nhận là chúng có liên kết. Trong khi Hibernate là thực sự kết nối chúng thành một đối tượng.
2, Rất đáng mong chờ. Vậy cấu tạo tổng của một chương trình sử dụng Hibernate như nào để mình còn sử dụng?
(Lưu ý đây là cấu tạo của Hibernate, không phải của HNA hay JPA)
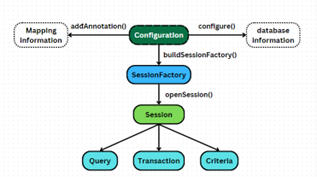
Nhìn cảnh này thật quen thuộc. Hãy thử nhìn lại cấu trúc của JPA:
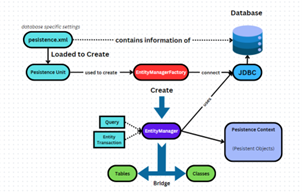
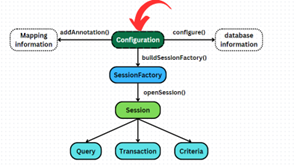
- Có thể thấy sự tương đồng trong cấu tạo của Hibernate và JPA: cũng lấy thông tin từ file cấu hình, tạo ra một Factory, rồi từ Factory tạo ra các đại diện để thực hiện câu lệnh SQL; bằng cách này hay cách khác nhưng cấu tạo chung là như vậy.
Sau đây thì giải thích lại một chút về cấu trúc:
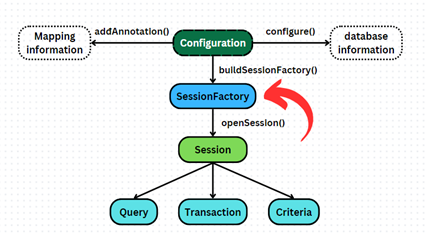
- Configuration: Lớp chính để cấu hình Hibernate. Cung cấp các phương thức để thiết lập cấu hình và cấu hình các thuộc tính của Hibernate.
- SessionFactory: Được tạo ra từ Configuration, SessionFactory là đối tượng chính để mở các Session. Nó chịu trách nhiệm quản lý các kết nối với cơ sở dữ liệu và cung cấp các Session để thực hiện các thao tác với cơ sở dữ liệu.
- Session: Lớp dùng để tương tác với cơ sở dữ liệu. Session cung cấp các phương thức để lưu, cập nhật, xóa và truy vấn các thực thể.
- Transaction: Đối tượng này quản lý các giao dịch cơ sở dữ liệu. Transaction được sử dụng để bắt đầu, commit hoặc rollback các giao dịch.
- Query: Lớp hoặc giao diện để thực hiện các truy vấn HQL (Hibernate Query Language) hoặc SQL thuần.
- Criteria: Cung cấp một API để tạo các truy vấn mà không cần phải viết HQL hoặc SQL, giúp tạo các truy vấn động và tùy chỉnh. Đơn giản hơn thì nó cung cấp các phương thức để thực thi câu lệnh ấy.
- Entity: Các lớp đại diện cho các bảng trong cơ sở dữ liệu. Các lớp này được chú thích với các annotation của Hibernate để ánh xạ tới các bảng và cột.
- Mapping: Cung cấp các phương thức và cấu hình để ánh xạ các lớp thực thể tới các bảng cơ sở dữ liệu, thường thông qua các file cấu hình XML hoặc annotation trong Java.
Vẽ lại workflow thì nó như thế này:
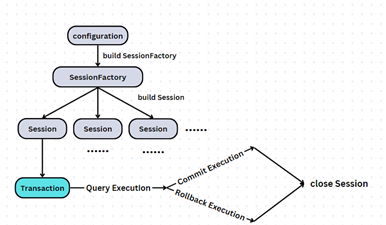
Có lẽ nhìn vào hình minh họa như thế này là đủ hiểu rồi, không cần giải thích thêm (vì nội dung cũng tương tự như nhau cả).
3, Thế code như nào để đi theo cái logic kia giờ? Bây giờ là cách code:
(sang phần mới)

INTRODUCING JAVA MAVEN
Trước hết, hãy làm quen với một dự án Java Maven.
1, Java Maven là gì?
- Tương tự như Java Ant, Java Maven là một công cụ quản lý dự án Java.
- Java Maven là một công cụ quản lý dự án và tự động hóa build được sử dụng trong phát triển phần mềm Java. Maven giúp quản lý các thư viện phụ thuộc (dependencies), build các project một cách tự động và thống nhất, cũng như giúp dễ dàng triển khai và quản lý phiên bản của phần mềm.
- Có thể hiểu đơn giản hơn là với dự án lớn và dùng nhiều framework thì nên dùng Maven, còn nếu tự build và muốn tinh chỉnh source code/cấu hình thì dùng Ant.
2, Tạo một chương trình Java Maven
- Ở mục New Project, chọn Java With Maven.
- VD như tôi đã tạo một Project tên là testHibernate và nó sẽ cho ra một folder như sau:
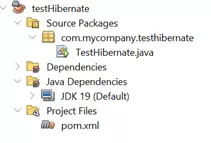
Giải thích các phần như sau:
- testHibernate: Đây là tên của dự án Java mà mình đang làm việc.
- Source Packages: Thư mục này chứa mã nguồn Java của dự án. Trong đó có:
- com.mycompany.testhibernate: Đây là gói (package) của dự án. Các lớp Java nằm trong gói này. Mình có thể chỉnh tên của dự án khác đi, không cần mặc định là mycompany.
- TestHibernate.java: Đây là một file Java chứa mã nguồn của lớp TestHibernate. Đây có thể là lớp chính của dự án hoặc một trong các lớp thành phần.
- Dependencies: Thư mục này chứa các thư viện và các phụ thuộc (dependencies) mà dự án sử dụng. Maven sẽ tự động tải và quản lý các thư viện này dựa trên cấu hình trong file pom.xml.
- Java Dependencies: JDK 19 (Default): Đây là phiên bản của Java Development Kit (JDK) mà dự án đang sử dụng. Trong trường hợp này là JDK 19.
- pom.xml: (Project Object Model) Đây là file cấu hình chính của dự án Maven. File này chứa thông tin về dự án, các phụ thuộc, các plugin và các chi tiết cấu hình khác. Maven sử dụng file này để quản lý và xây dựng dự án.
Thế XML là gì?
XML (eXtensible Markup Language) là một ngôn ngữ đánh dấu mở rộng được sử dụng để mô tả dữ liệu.
Trong phạm vi bài này, hãy coi nó có form giống như HTML: có các thẻ đóng/mở, và dùng để viết tệp cấu
hình trong các phần mềm.
TẠO CHƯƠNG TRÌNH VỚI HIBERNATE!
https://docs.jboss.org/hibernate/orm/6.6/introduction/html_single/Hibernate_Introduction.html
1, Đầu tiên là thêm các thư viện của Hibernate và Database vào trong file cấu hình.
- Đây là bước cung cấp thông tin Configuration.
Hãy nhớ Maven cho phép tự động tải và quản lý các thư viện/dependencies dựa vào cấu hình trong file pom.xml. Nên việc cần làm bây giờ là tìm các dependencies phù hợp để thêm vào file cấu hình pom.xml. Mà như đã giới thiệu thì chúng ta cần JDBC và Hibernate.
- Bây giờ đi vào trang web https://mvnrepository.com/
- Đây là trang web chứa các thư viện/dependencies trong Java Maven để mình lấy mã XML Configuration của các dự án từ đó. Nhắc lại là không phải tải, Maven tự tải.
Sau khi vào trang thì tìm kiếm Hibernate Core và MySQL Connector. Ai dùng SQL Server thì tìm SQL Server JDBC.
Sau đó nhấn chọn phiên bản. Tôi thích cái mới nhất (nhưng không phải bản thử nghiệm Alpha).
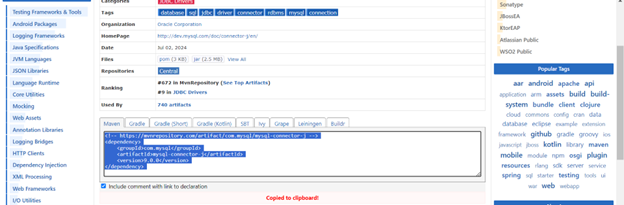
Hãy nhìn đoạn XML được làm riêng cho bản Maven kia. Copy nó lại, sau đó đi vào file pom.xml:
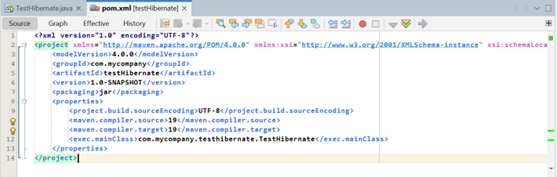
Lúc đầu chúng ta có một file như này. Hãy thêm vào đó một thẻ <dependencies> trong thẻ <project> để khai báo những thư viện của chúng ta trong đó nào.
Sau khi khai báo thì được như sau:
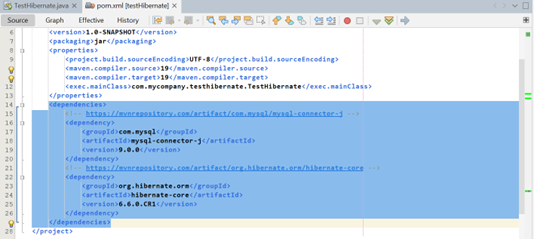
Sau đó lưu lại, và lần đầu ta thấy sự “tự động quản lý” của Maven:
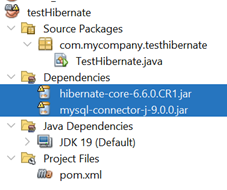
Một vài thư viện mới đã được tự thêm vào phần Dependencies! Nhìn kỹ thì nó là 2 cái mình vừa thêm vào phần Dependencies.
Nhưng sao còn dấu chấm than vậy? Hãy build để hết.
Nhấn chuột phải vào tên Project và chọn build.
Sau khi build xong chúng ta thấy một loạt thư viện được tự động tải về:
Không cần quan tâm nhiều chúng là gì, chúng đơn giản là những thứ được giới thiệu ở phần CHI TIẾT CÁC THÀNH PHẦN thôi.
2, Bước tiếp theo là chuẩn bị một database
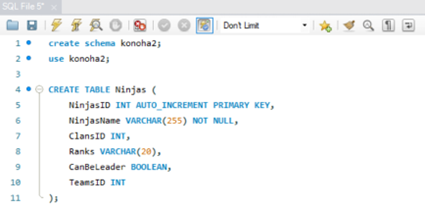
- Tạo một database đơn giản như sau:

- Giải thích một chút về database: quản lý nhóm, clan, nhiệm vụ của một nhóm ninja.
- Về các mqh: một Teams có nhiều Ninjas,
một Clans có nhiều Ninjas,
một Teams có thể làm nhiều Missions và nhiều Teams có thể làm chung Missions.
- Chúng ta cần kiểm tra xem mỗi lần đổi trưởng Clans hay trưởng Teams, trưởng Clans có trong Clans đó hay không; và trưởng Teams có trong bảng Ninjas hay không => viết 2 Trigger, mỗi lần đổi trưởng Clans mà người đó không có trong Clans đó thì báo lỗi, Teams tương tự.
- Ý tưởng là như thế, nhưng vì tôi chưa thạo MySQL nên nhờ GPT viết hộ. (nó đéo viết được và báo hại t mất 1 ngày)

3, Bước tiếp là xây dựng Factory dựa trên những cấu hình vừa tạo
- Sau đây là một loạt các câu lệnh với cú pháp lạ. Cần một sự ngậm ngùi chấp nhận không hề nhẹ ở đây.
- Chúng ta đều rõ bước cần làm để tạo một Factory là phải có được Configuration. Lúc nãy chúng ta mới chỉ tải thư viện JDBC và Hibernate-core về chứ chưa config cái gì cả. Tiếp theo sẽ có hai cách để config (tiếp tục viết trong file XML hoặc viết code Java) nhưng docs tôi đang đọc hướng dẫn dạy tôi làm theo Java nên cứ theo cách đó đi đã.
)
(đưa meme này vào vì có quá nhiều thứ mới)_
- Hãy tạo một class là HibernateUtils trong cùng gói đặt class Main (cho nhanh):
- Đầu tiên muốn một Factory thì hãy khởi tạo và trả về nó. Logic tính sau.
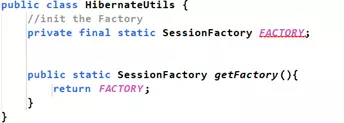
- FACTORY là một phần nặng và cả chương trình chỉ khởi tạo một lần. Vì vậy, xin được giới thiệu cách viết mới, làm cho khối lệnh luôn luôn chỉ được thực thi một lần trong suốt chương trình kể cả có khởi tạo đối tượng nhiều lần:
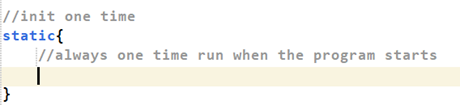
- Trong đó chúng ta sẽ config và khởi tạo (build) Factory:

- Nhìn xem nó yêu cầu gì thế kia: serviceRegistry. Sau khi hỏi GPT thì tôi biết nó là: class chịu trách nhiệm quản lý và cung cấp các dịch vụ cốt lõi như kết nối cơ sở dữ liệu, quản lý các phiên làm việc, các dịch vụ bộ đệm, và nhiều dịch vụ khác. Nó là một điểm trung tâm nơi tất cả các dịch vụ cần thiết cho Hibernate được đăng ký và truy cập. OK tạm chấp nhận thế chứ biết sao nữa, bản chất thì cũng có giới hạn thôi. Bây giờ tạo một serviceRegistry như nó yêu cầu thôi.
- Để tạo một serviceRegistry thì chúng ta tạo từ “serviceRegistry Buider” – nơi xây dựng serviceRegistry. Cụ thể hơn là class StandardServiceRegistryBuilder.
- Trong StandardServiceRegistryBuilder có một phương thức để ép thêm những cấu hình do mình tạo vào trong nơi xây dựng Factory để thành hình Factory như mình mong muốn, đó là method applySettings(Map<String,Object> settings). Có nghĩa là, sau khi dùng method này thứ chúng ta nhận được vẫn là một “bản thiết kế” nhà máy – StandardServiceRegistryBuilder - nhưng nó đã theo ý muốn chúng ta. Sau đó chỉ cần build() nữa là ra cái nhà máy.

- Nhưng cái gì là mySettings? Mà nó lại là kiểu Map<> ? => trong Java có một thứ như vậy, đó là class Properties: một tập hợp các cặp khóa-giá trị, thường được sử dụng để lưu trữ các cấu hình của ứng dụng. Nó kế thừa từ lớp Hashtable. Vừa đẹp. Thế là bây giờ phải tạo thêm một Properties, rồi gán giá trị cấu hình theo cặp key-value vào đó, sau đó đem chúng đi làm “bản thiết kế”.
- Theo như docs tôi xem thì có 5 tham số cần cung cấp cho “thiết kế” (nhớ vào): DIALECT, DRIVER, URL, USER, PASS. 4 cái cuối thì ok nhưng cái đầu là gì? GPT cho tôi biết: DIALECT là một lớp định nghĩa cách Hibernate sẽ chuyển đổi các câu lệnh SQL sang cú pháp SQL cụ thể của từng hệ quản trị cơ sở dữ liệu (DBMS) khác nhau. Nói cách khác, Dialect giúp Hibernate hiểu cách tương tác với từng loại DBMS cụ thể. OK chấp nhận thôi chứ biết sao giờ, chương trình người ta đã xây thế, giờ mình đi dùng lại cấm hỏi bản chất.
- Các chuỗi liên kết mà chúng ta cần cung cấp cho Configuration là:
DIALECT: "org.hibernate.dialect.MySQLDialect”
DRIVER: "com.mysql.cj.jdbc.Driver"
URL: "jdbc:mysql://localhost:3306/tên_database[?tham_số=giá_trị…]"
USER: "tên_tài_khoản_database"
PASS: "password_database"
Hãy nhớ các tham số này, và đừng hỏi vì sao nó là như thế. Nếu để ý thì 2 chuỗi DIALECT và DRIVER là địa chỉ của class Driver và Dialect bên trong gói Hibernate và JDBC. Chuỗi kết nối được mở ở cổng 3306, cổng mặc định của MySQL.
- Code thôi:
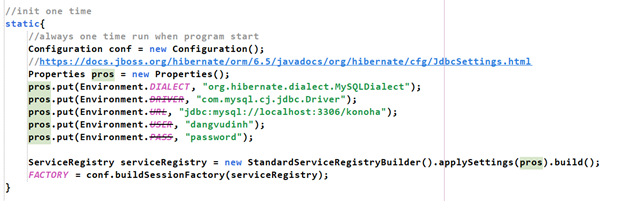
Có thể thấy logic lúc nãy đang được áp dụng một cách ổn thỏa. Nhưng cái đéo gì thế kia? Code bị gạch: hết dát, đã được cập nhật. Giờ làm sao để tìm cái mới?
- Tôi tra thử thì đây là nơi chứa cái đó:
org.hibernate.cfg.JdbcSettings. Lên gg tra xem nào:
https://docs.jboss.org/hibernate/orm/6.5/javadocs/org/hibernate/cfg/JdbcSettings.html

Đây rồi. Bản cũ thì thuộc tính là DRIVER còn bản mới là JAKARTA_JDBC_DRIVER. Quá tốt rồi giờ thay vào xem có chạy không nhé:
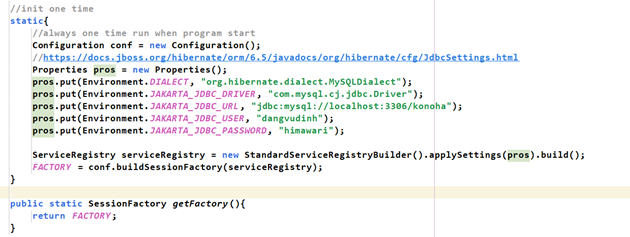
Quá tuyệt vời, không báo lỗi, quá tuyệt vời.
Bây giờ nhanh chóng test xem cái đó thực sự chạy hay chưa. Lên GPT và làm ngay một order: (cứ test đi lát nói phần này sau)
F6 hoặc build:
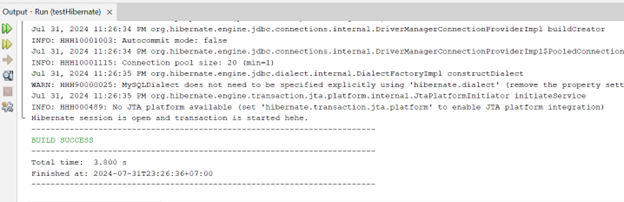
Trên đây tôi nêu ra tất cả những vấn đề tôi gặp phải khi cố gắng làm theo một video đã 4 năm tuổi so với lúc tôi viết cái này (31/7/2024) và cách tôi đối mặt với từng câu hỏi xuất hiện trong đầu tôi.
Lưu ý là chọn gói import đều phải từ org.hibernate mà ra. Import cái khác sai liền. (trừ Properties).
Thêm: khuyến khích dùng getProperties/setProperties của Configuration thay vì truyền thẳng nó vào applySettings().

Link video: https://www.youtube.com/watch?v=4HB6KqAdMGw

(Ai dùng SQL Server thì bỏ qua vấn đề này)
Vấn đề không chỉ dừng lại ở một số cái đơn giản như thế. Sau khi cài lại win và chạy lại thử chương trình thì tôi thấy một số vấn đề phát sinh với database (biết ngay vì sao lại đơn giản như thế được). Cụ thể:
đây là lỗi plugins bên mysql, khi mà mysql bản hiện tại không chấp nhận liên kết sử dụng mật khẩu mysql_native_password mà chỉ hỗ trợ caching_sha2_password. Cũng chưa rõ tại sao nhưng tôi đã cài lại mysql và workbench thì thấy mọi chuyện lại bình thường nên chưa đưa ra được giải pháp gì.
4, Bây giờ tạo ra class ở phần Models và thêm annotations đánh dấu.
- Cùng đọc lại cách hoạt động trong phần này: 2, Rất đáng mong chờ. Vậy cấu tạo tổng của một chương trình sử dụng Hibernate như nào để mình còn sử dụng?
- Tóm tắt lại những thông tin cần dùng: tạo class rồi gán @annotation vào, sau đó cài đặt liên kết, cài xong thì test một cái rồi sang bước tiếp.
Cụ thể các bước như này:
-
- Tạo những class POJO - Plain old Java object – class Java bình thường – như cách vẫn hay tạo.
- Chú ý: những class này phải có: một constructor rỗng, các thuộc tính phải đặt ở dạng private (vẫn tiêu chuẩn cũ)
- Sau đó bắt đầu đánh dấu @annotation theo quy chuẩn sau:
- Tạo những class POJO - Plain old Java object – class Java bình thường – như cách vẫn hay tạo.
QUY CHUẨN ĐÁNH ANNOTATION
| Annotation | Mô tả |
|---|---|
| @Entity | Đánh dấu một lớp là một thực thể (entity). |
| @Table | Định nghĩa tên bảng tương ứng trong cơ sở dữ liệu. |
| @Id | Đánh dấu thuộc tính là khóa chính (primary key). |
| @GeneratedValue | Định nghĩa chiến lược tạo giá trị tự động cho khóa chính. |
| @Column | Định nghĩa cột tương ứng trong cơ sở dữ liệu. |
| @Temporal | Định nghĩa kiểu dữ liệu thời gian (date, time, timestamp). |
| @Transient | Đánh dấu thuộc tính không được lưu trữ trong cơ sở dữ liệu. |
| @ManyToOne | Định nghĩa mối quan hệ nhiều-một (many-to-one). |
| @OneToMany | Định nghĩa mối quan hệ một-nhiều (one-to-many). |
| @ManyToMany | Định nghĩa mối quan hệ nhiều-nhiều (many-to-many). |
| @OneToOne | Định nghĩa mối quan hệ một-một (one-to-one). |
| @JoinColumn | Định nghĩa cột dùng để tạo liên kết giữa các bảng. |
| @JoinTable | Định nghĩa bảng trung gian cho mối quan hệ nhiều-nhiều. |
| @MappedSuperclass | Đánh dấu một lớp là superclass nhưng không ánh xạ trực tiếp vào bảng cơ sở dữ liệu. |
| @Inheritance | Định nghĩa chiến lược kế thừa giữa các thực thể. |
| @DiscriminatorColumn | Định nghĩa cột phân biệt cho các lớp kế thừa. |
| @SequenceGenerator | Định nghĩa bộ tạo số tự động dựa trên sequence trong cơ sở dữ liệu. |
| @NamedQuery | Định nghĩa các truy vấn đặt tên sẵn (named query) để tái sử dụng. |
| @Lob | Đánh dấu thuộc tính là một đối tượng lớn (large object), như văn bản hoặc nhị phân lớn. |
Những annotation nào không phải màu đen thì đó là những cái cơ bản cần đọc ngay.
Thêm nữa là những annotation này không tự nhiên mà có, tất cả phải import (không như @Override của Object sẵn). Mà cũng không phải lo vì nó sẽ tự động import thôi.
- Bây giờ đi code thử:
CODE AND CONFIG POJO CLASS
-
- Vì database Konoha “hơi” phức tạp cho việc demo kết nối (thực ra do tôi lười viết quá) nên tôi sẽ tạo ra một database mới có một bảng duy nhất (để tránh khởi tạo mối quan hệ - cái này sẽ nói sau).
- Vì thế Konoha2 ra mắt với chỉ một bảng Ninjas:
- Vì database Konoha “hơi” phức tạp cho việc demo kết nối (thực ra do tôi lười viết quá) nên tôi sẽ tạo ra một database mới có một bảng duy nhất (để tránh khởi tạo mối quan hệ - cái này sẽ nói sau).
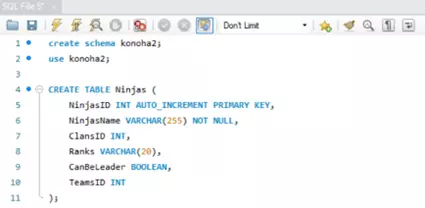
Có một câu hỏi là tại sao trong JDBC lại không có phần liên kết này trong những class trong Models? Lời giải thích tôi có thể đưa ra bây giờ là JDBC không thực thi theo đối tượng – thực thể, mà đơn giản chỉ là thực thi câu lệnh SQL thuần – không hề tạo mô hình hướng đối tượng.
-
- Sau khi tạo lại database mới, chỉnh lại đường dẫn trong file HibernateUtils (tự làm thôi)
- Tạo một nơi để chứa các class POJO này, thay vì tạo Models như JavaSE thì hãy tạo một gói mới là pojo trong gói com.mycompany:
- Sau khi tạo lại database mới, chỉnh lại đường dẫn trong file HibernateUtils (tự làm thôi)
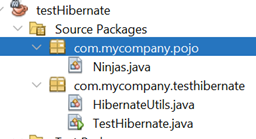
-
- Trong class Ninjas.java chúng ta tạo những thuộc tính và kiểu dữ liệu tương tự như Table Ninjas bên database.
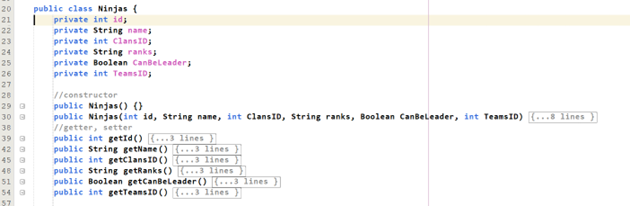
Sau đó bắt đầu đánh dấu bằng annotation. Hiện tại chỉ có một bảng nên chúng ta sẽ đánh dấu những nơi sau: class, id, chiến lược tự tăng (nếu có), match từng thuộc tính (nếu tên thuộc tính trong class khác tên cột trong bảng trong Database), đánh dấu mối quan hệ (nói sau). - Code sẽ như sau:
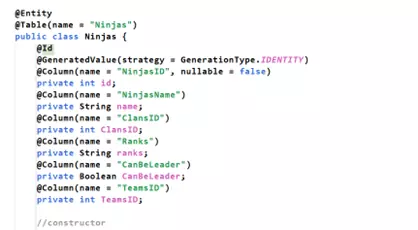
-
- Đã gán xong annotation. Bây giờ hãy đăng ký với Hibernate là “tôi vừa cấu hình lớp Ninjas xong, hãy chấp nhận nó và map nó với Table Ninjas trong database đi” (vào HibernateUtils và thêm vào đó dòng sau: “conf.addAnnotatedClass(Ninjas.class);”):
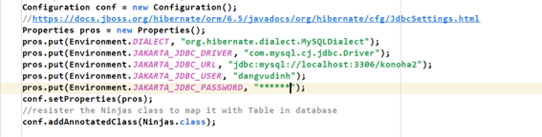
-
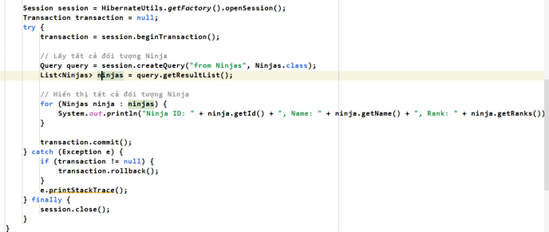
- Viết xong rồi. Bây giờ vào GPT và order ngay một hàm test cơ bản (viết trong TestHibernate), là lấy tất cả thông tin lên:
<
Và nếu may mắn thì chúng ta được cái này sau khi run:
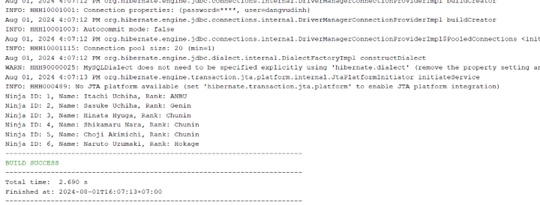
-
- Nhưng nếu không may mắn thì sao

Lỗi do sai chính tả chỗ cấu hình, hay:
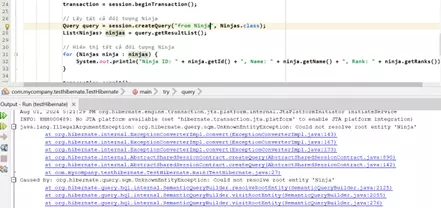
Lỗi sai chính tả chỗ câu lệnh HQL(hả HQL á?)
-
- Thế nên thêm chú ý phần này là phải code thật ĐÚNG CHÍNH TẢ.
MỞ RỘNG QUY MÔ DATABASE
- Đã hết thời gian lười. Bây giờ quay lại database Konoha với vài mqh giữa các bảng.
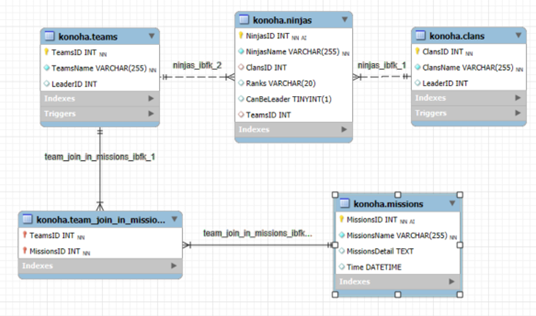
- Mối quan hệ trong Hibernate:
- Trong database chúng ta có 3 mối quan hệ phổ biến: 1:1, 1:n, n:n. Sang bên Hibernate chúng ta chuyển sang 4 mối quan hệ: @OneToOne, @OneToMany, @ManyToOne, @ManyToMany.
Xem xét lại mối quan hệ trong database

- Hãy cùng xem xét lại mối quan hệ trong cơ sở dữ liệu.
- Hãy để ý rằng trong mối quan hệ 1:n rõ ràng có mối quan hệ chủ tớ. Nhưng các mối quan hệ còn lại thì sao? Liệu rằng mối quan hệ 1:1 và n:n có thực sự là bình đẳng?
- Thử lấy ví dụ về mối quan hệ 1:1 trong thực tế: ví dụ như một người chỉ có duy nhất một CCCD. Phân tích mối quan hệ: một người chỉ có một CCCD, một CCCD cũng chỉ thuộc về duy nhất một người. Tuy nhiên khi xét kỹ hơn, một người khi chết đi, CCCD của người đó sẽ bị bỏ chứ không thể tìm một người khác vào thế chỗ cho người đó để sở hữu số CCCD đó được. Nhưng khi một thẻ CCCD mất đi thì người chủ hoàn toàn có thể đi làm lại CCCD mới (ví dụ thế chứ tôi ko rõ luật pháp chỗ này lắm, nhưng về khoa học là có thể). => có thể thấy mối quan hệ 1:1 này không hề bình đẳng.
- Thế thì sẽ xuất hiện một khái niệm mới trong các mqh: bên sở hữu/quản lý và bên bị sở hữu/bị quản lý. Theo suy nghĩ tự nhiên thì chắc chắn sẽ thấy bên con người sẽ là bên sở hữu còn bên CCCD là bên bị sở hữu.
Nhưng không.
Ngại đọc thì xuống phần kết luận và nhớ luôn.
- Tôi đã cố gắng tìm hiểu trên GG và GPT nhưng chẳng nơi nào nói rõ cho tôi tại sao là không. (hoặc tôi chưa tìm hết). Nhưng có một điều quan trọng mà ở đâu tôi cũng thấy nói: bên nào có khóa ngoại bên đó được coi là bên sở hữu. Trong mối quan hệ 1:1 và n:n có thể khó thấy nhưng trong mối quan hệ 1:n có thể thấy rõ ràng, bên nhiều là bên có cột khóa ngoại và theo quy tắc trên đương nhiên nó là bên sở hữu. Nó cũng suy ra một chủ nô có nhiều nô lệ thì bên nô lệ lại là bên sở hữu?! Tại sao lại ngược với tư duy thông thường vậy?
Tôi đã đem toàn bộ gạch đầu dòng trên lên GPT, và sau mấy ngày có lẽ nó cũng đang hiểu tôi nói cái gì, và cũng đưa ra cho tôi một vài ý tưởng để giải thích.

- Đầu tiên, phải nắm rõ JPA sẽ hoạt động theo cách: Bên bị sở hữu không trực tiếp lưu trữ thông tin về mối quan hệ, do đó, các thao tác liên quan đến mối quan hệ cần phải tham chiếu ngược lại tới bên sở hữu để xác định các liên kết. Điều này có thể làm cho các thao tác trở nên phức tạp hơn.
- Với việc truy xuất một phần tử bên nhiều (nô lệ), theo như tư duy tự nhiên chúng ta sẽ đi tìm kiếm chủ của nó và hỏi. Muốn cập nhật một nô lệ, chúng ta cũng phải đi qua chủ nô của nó, để tìm xem nó ở đâu rồi cập nhật. Đó là khi đặt bên sở hữu/quản lý ở bên chủ nô (bên 1 trong mối quan hệ 1:n). Còn nếu làm ngược lại thì sao? Nếu đặt bên sở hữu là bên nô lệ, khi cập nhật hay truy xuất, chương trình sẽ bắt đầu từ bên nô lệ.
- Giờ thử tưởng tượng có 100 chủ nô và mỗi chủ nô có 1000 nô lệ (con số tượng trưng).
- Trường hợp để bên sở hữu là bên chủ nô, muốn cập nhật một nô lệ A, chương trình sẽ xét tất cả chủ nô, sau đó xét từng nô lệ của từng người xem ai là A rồi cập nhật. Khá tốn thời gian, trường hợp xấu nhất có thể là 100 *1000 lần tìm. Nếu muốn cập nhật một chủ nô, thì tìm ra là xong.
- Trường hợp đặt bên nô lệ là bên sở hữu, muốn cập nhật A lập tức truy xuất được A để thực hiện. Tiếp tục đến trường hợp cập nhật một chủ nô, xấu nhất là đi tìm toàn bộ 100 * 999 +1 nô lệ để ra được chủ nô cần tìm.
- Những trường hợp về cập nhật thì có thể nhìn bảng sau:
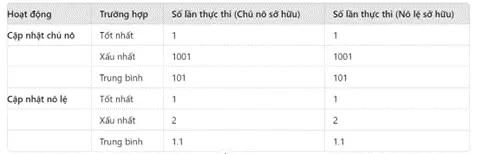
-
- Có thể thấy nếu tính số lượng truy vấn và số lượng thực thi sẽ không khác nhau mấy. Nhưng điều làm nên sự khác biệt, hãy đọc lại cách JPA hoạt động: không có sẵn dữ liệu của bên bị quản lý. Như vậy nếu bỏ ra một ít bộ nhớ để đổi lại sự sẵn sàng cho dữ liệu là sự ưu tiên của JPA. Chúng ta cũng thấy dễ làm việc hơn nếu nắm trong tay toàn bộ dữ liệu của nô lệ, trong đó mỗi nô lệ có một ánh xạ duy nhất tới chủ nô của nó, hơn là nắm trong tay dữ liệu các chủ nô và chỉ có thông tin ánh xạ tới các nô lệ.
- Thêm nữa, nếu xử lý từ phía chủ nô, phải xử lý nhiều ánh xạ phức tạp vì nó là bên 1 trong mqh 1:n – nó có quan hệ trực tiếp tới nhiều thực thể khác. Còn với nô lệ chỉ có thông tin duy nhất, có thể coi là 1:1 (một chiều) tới các chủ nô (1 nô lệ chỉ thuộc về 1 chủ nô).
- Có thể thấy nếu tính số lượng truy vấn và số lượng thực thi sẽ không khác nhau mấy. Nhưng điều làm nên sự khác biệt, hãy đọc lại cách JPA hoạt động: không có sẵn dữ liệu của bên bị quản lý. Như vậy nếu bỏ ra một ít bộ nhớ để đổi lại sự sẵn sàng cho dữ liệu là sự ưu tiên của JPA. Chúng ta cũng thấy dễ làm việc hơn nếu nắm trong tay toàn bộ dữ liệu của nô lệ, trong đó mỗi nô lệ có một ánh xạ duy nhất tới chủ nô của nó, hơn là nắm trong tay dữ liệu các chủ nô và chỉ có thông tin ánh xạ tới các nô lệ.
- Phân tích nãy giờ chỉ để rút ra kết luận rằng: bên nhiều trong mối quan hệ 1:n là bên sở hữu, bên còn lại là bên bị sở hữu (ngược với tư duy thông thường). Các mối quan hệ khác sẽ xây dựng tương tự: ngược lại với quan hệ chủ - tớ theo tư duy thông thường. Từ ngữ “sở hữu” chỉ mang tính chất minh họa cho quan hệ: sở hữu quyền quản lý quan hệ trong chương trình, chứ không phải là sở hữu trong trường hợp thực tế.
@OneToOne
Nó tương đương với mối quan hệ 1:1 trong database.
- Mô tả cách tạo class POJO cho quan hệ 1:1 như sau:
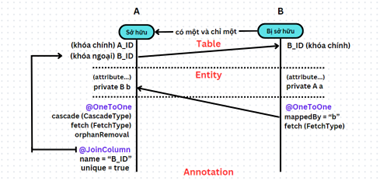
Trong đó: B là chủ sở hữu (thực tế) và là bên bị sở hữu (với JPA). A thì ngược lại.
Giải thích:
Trong class A:
-
- Annotation @OneToOne: đánh dấu mối quan hệ 1:1 đối với class B.
- cascade: Định nghĩa các hành động cascade – mối quan hệ “thác nước” – cái này đổ lên đầu cái kia. Với giá trị CascadeType.ALL, tất cả các hành động (PERSIST, MERGE, REMOVE, REFRESH, DETACH) sẽ được truyền từ thực thể chủ sở hữu thực tế tới các thực thể liên kết. Điều này có nghĩa là khi lưu, cập nhật hoặc xóa một B, các hành động tương tự sẽ được áp dụng cho A liên kết.
- Annotation @OneToOne: đánh dấu mối quan hệ 1:1 đối với class B.
những hành động này cụ thể là gì, có thể nói sau.
-
- fetch dùng để quyết định xem có load thêm dữ liệu của B tương đương với đối tượng A được gọi đó hay không. Có 2 loại là FetchType.EAGER – có load và FetchType.LAZY – không load thêm.
Vì là mối quan hệ 1:1 nên khi load một A chỉ có một B được load cùng – có thể để là EAGER.
-
- orphanRemoval quyết định các thực thể con sẽ bị xóa tự động khi chúng không còn liên kết với thực thể cha. Giá trị của nó là true/false.
- Annotation @JoinColumn: đánh dấu cột khóa ngoại trỏ sang bên B.
- name = “B_ID”: đánh dấu tên cột ứng với thuộc tính (mà ở đây là đối tượng b trong class A)
- unique = “true”: vì mqh là 1:1 nên phải giữ unique cho khóa ngoại, nghĩa là A khác nhau không thể có B giống nhau.
- orphanRemoval quyết định các thực thể con sẽ bị xóa tự động khi chúng không còn liên kết với thực thể cha. Giá trị của nó là true/false.
Trong class B:
-
- @OneToOne(mappedBy = "b"): Chỉ định rằng B không sở hữu mối quan hệ mà mối quan hệ được ánh xạ bởi thuộc tính b trong thực thể A. Đây là bên không sở hữu, và mappedBy thường sẽ ở bên không sở hữu.
- fetch: như trên.
- @OneToOne(mappedBy = "b"): Chỉ định rằng B không sở hữu mối quan hệ mà mối quan hệ được ánh xạ bởi thuộc tính b trong thực thể A. Đây là bên không sở hữu, và mappedBy thường sẽ ở bên không sở hữu.
- Câu hỏi đặt ra là tại sao quan hệ 1:1 mà mối quan hệ lại có cách thiết lập khác nhau trong mỗi lớp như vậy? Nếu thiết lập giống nhau thì có ổn không?
- Chúng thiết lập khác nhau vì có phân chia giai cấp rõ ràng: chủ - tớ chứ không hề ngang hàng. Khi thiết lập cascade ở bên A trỏ sang bên B thì khi xóa B, A tự động xóa và không có chiều ngược lại.
- Thiết lập 2 bên giống nhau có ổn không? Nếu cho cả 2 bên cùng có cascade thì gây ra lặp mối quan hệ: bị vòng lặp cascade trỏ vô hạn (cái này cũng dễ hiểu).
- Chỉ có cách thiết lập ĐỒNG BỘ CÙNG NHAU: nghĩa là không cần phải công bằng từ bước thiết lập mối quan hệ, nhưng sẽ thiết lập câu lệnh sao cho chúng được bình đẳng (thiết lập thêm trigger hay dùng thẳng câu lệnh, …) cái này nếu có gặp thì nói sau.
@OneToMany và @ManyToOne
Hai mối quan hệ này tương đương với mối quan hệ 1:n trong database.
- Mô tả cách tạo class POJO cho quan hệ 1:n như sau:
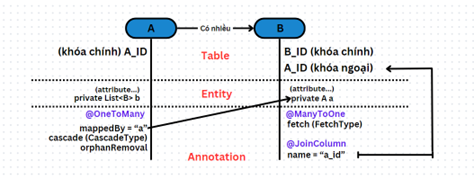
- GIải thích:
- Trong bảng A có A_ID, trong bảng B có B_ID và A_ID làm khóa ngoại. Ở đây B là bên sở hữu còn A là bên bị sở hữu.
Trong class A:
-
-
- Dùng annotation @OneToMany.
- mappedBy dùng để trỏ tới thuộc tính khóa ngoại được đặt trong class B.
- cascade: “thuộc tính thác nước đổ” – như phần trước.
- orphanRemoval quyết định các thực thể con sẽ bị xóa tự động khi chúng không còn liên kết với thực thể cha. Giá trị của nó là true/false.
- Dùng annotation @OneToMany.
-
Trong class B:
-
-
- Dùng annotation @ManyToOne và @JoinColumn.
- fetch dùng để quyết định xem có load thêm dữ liệu của A tương đương với đối tượng B được gọi đó hay không. Có 2 loại là FetchType.EAGER – có load và FetchType.LAZY – không load thêm.
- Dùng annotation @ManyToOne và @JoinColumn.
-
Thuộc tính này cũng có trong A nhưng mặc định để là LAZY, vì A 1:n B nên nếu gọi A và gọi thêm B thì quá nhiều B xuất hiện gây chậm hệ thống. Nên tôi cũng thích để mặc định luôn.
-
-
- name đây là thuộc tính thông thường của mỗi cột. Chú ý trong SQL thì cột này có kiểu dữ liệu tương tự như id bên A nhưng ở class POJO nó có kiểu dữ liệu là đối tượng A luôn. Nên thay vì là private int A_ID như các cột khác thì nó lại là private A a.
- Khi xây dựng class, quy tắc là trong A chứa một List (hoặc Set) các B, còn trong B chứa một thuộc tính của A.
-
VD: ai cũng biết một Teams gồm nhiều Ninjas.
Trong class Teams:

Trong class Ninjas:

@ManyToMany
Đây là / mqh cơ bản / phức tạp nhất.
- Mô tả cách tạo class POJO cho quan hệ n:n như sau:
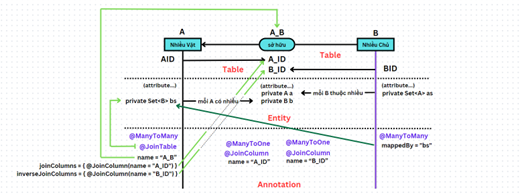
- Giải thích:
A và B có quan hệ n:n trong đó A là vật còn B là chủ, suy ra A là bên sở hữu còn B là bên bị sở hữu.
Trong class A (mang tính sở hữu):
-
-
- Chứa một Set các đối tượng B ứng với mỗi đối tượng A đang xét: private Set<B> bs. (không quan trọng lắm Set hay List tùy thuộc vào người dùng).
- Dùng annotation @ManyToMany để đánh dấu mqh, @JoinTable để xác định bảng quan hệ (bảng thứ 3).
- Thuộc tính trong @JoinTable:
- name: tên bảng thứ 3
- joinColumns = { @JoinColumn(name = "A_ID") }: cột trong bảng thứ 3 trỏ tới bảng A, mang tính sở hữu.
- inverseJoinColumns = { @JoinColumn(name = "B_ID") }: cột trong bảng thứ 3 trỏ tới bảng B, mang tính bị sở hữu.
- Chứa một Set các đối tượng B ứng với mỗi đối tượng A đang xét: private Set<B> bs. (không quan trọng lắm Set hay List tùy thuộc vào người dùng).
-
Trong class B (mang tính bị sở hữu):
-
-
- Chứa một Set các đối tượng A ứng với mỗi đối tượng B đang xét: private Set<A> as.
- Dùng annotation @ManyToMany để đánh dấu mqh. Ở đây KHÔNG CÓ @JoinTable.
- Trong @ManyToMany chỉ chứa một thuộc tính mappedBy.
- mappedBy = “bs”: trỏ tới List bs bên A, nơi mà các đối tượng B được quản lý.
- Chứa một Set các đối tượng A ứng với mỗi đối tượng B đang xét: private Set<A> as.
-
Trong class A_B (bảng liên kết):
-
-
- Đây có thể coi là bảng mà A 1:n nó và B 1:n nó.
- Bảng này có 2 thuộc tính liên kết, đồng thời là 2 khóa chính của bảng.
- Do đó sử dụng 2 annotation @ManyToOne, biểu diễn liên kết với 2 bảng chính nhờ 2 cột khóa ngoại (@JoinColumn) thuộc tính name = “A_ID” và name = “B_ID”.
- Đây có thể coi là bảng mà A 1:n nó và B 1:n nó.
-
VD code:
Mối quan hệ Teams n:n Missions:
Missions:

Teams:

TeamJoinInMissions:
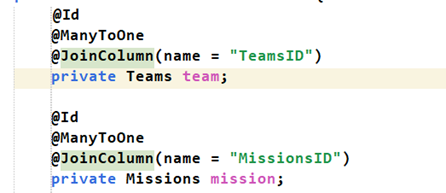
Chưa hiểu lắm? Tại sao những annotation và thuộc tính của chúng lại được sắp xếp như vậy?
THÊM
@JoinColumn và mappedBy
- Bên sở hữu và bên bị sở hữu
Hai cột @JoinColumn và mappedBy nếu để ý thì nó luôn luôn nằm khác phía nhau trong bên sở hữu/ bị sở hữu. Hãy xét mối quan hệ 1:n, để ý tiếp thì JoinColumn luôn nằm trong bên nào có cột khóa ngoại, và bên này được gọi là “bên sở hữu”.
- Sắp xếp các cột
Trước hết hãy xem định nghĩa:
@JoinColumn được sử dụng để chỉ định cột khóa ngoại (foreign key) trong bảng cơ sở dữ liệu mà liên kết đến một bảng khác.
mappedBy được sử dụng trong mối quan hệ hai chiều (bidirectional relationships) để chỉ định rằng thực thể hiện tại là bên bị sở hữu (inverse side) và tên thuộc tính ở bên sở hữu (owning side) mà nó ánh xạ tới.
- Vì vậy @JoinColumn luôn nằm ở bên sở hữu còn mappedBy nằm ở bên bị sở hữu. Hoặc có thể nhớ đơn giản hơn, trong thực tế thì đối tượng nào là chủ thì sẽ có thuộc tính mappedBy trong annotation, còn đối tượng nào là nô lệ thì sẽ có @JoinColumn và những thuộc tính đi kèm để điều khiển đồng bộ.
Các thuộc tính hay gặp và vị trí
| Thuộc tính/Chú thích | Bên sở hữu (Owning Side) | Bên không sở hữu (Inverse Side) | Tác dụng |
|---|---|---|---|
| @JoinColumn | Thường sử dụng | Không sử dụng | Chỉ định cột khóa ngoại trong bảng sở hữu. |
| mappedBy | Không sử dụng | Thường sử dụng | Chỉ ra rằng mối quan hệ này được quản lý bởi bên kia, xác định tên trường bên sở hữu. |
| @OneToMany | Không thường dùng | Thường sử dụng | Xác định mối quan hệ một-nhiều, liên kết với bên sở hữu. |
| @ManyToOne | Thường sử dụng | Không sử dụng | Xác định mối quan hệ nhiều-một, thường dùng với @JoinColumn để chỉ định khóa ngoại. |
| @OneToOne | Có thể sử dụng (tùy thuộc vào thiết kế cụ thể) | Có thể sử dụng (tùy thuộc vào thiết kế cụ thể) | Xác định mối quan hệ một-một, liên kết giữa hai thực thể. |
| @ManyToMany | Thường sử dụng | Thường sử dụng | Xác định mối quan hệ nhiều-nhiều, cần mappedBy để chỉ định bên nào sở hữu mối quan hệ. |
| fetch | Có thể sử dụng | Có thể sử dụng | Chỉ định kiểu tải dữ liệu (FetchType.LAZY hoặc FetchType.EAGER). |
| cascade | Thường sử dụng | Có thể sử dụng | Chỉ định các thao tác cascade (như PERSIST, REMOVE) để áp dụng lên các thực thể liên quan. |
| optional | Thường sử dụng | Không sử dụng | Xác định mối quan hệ là tùy chọn hay không (chỉ áp dụng cho @ManyToOne và @OneToOne). |
5, Sau khi kết nối thành công thì đến việc học cách thao tác với dữ liệu.
(tức là viết file Test_Hibernate.java mà nãy giờ mình nhờ GPT viết).
Nhắc lại các thao tác nãy giờ đã làm:
- Tạo dự án Maven
- Thêm thư viện/gói phục vụ Hibernate và JDBC trong file cấu hình toàn bộ chương trình.
- Xây dựng file Utils, dùng những thư viện trên để kết nối với CSDL
- Xây dựng các file POJO và đánh annotation
- Test chương trình
Sau khi viết hết các bước đầu, chúng ta đến bước cuối cùng là viết test chương trình.
Quy trình:
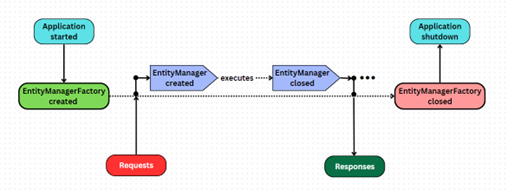
Nhìn lại vòng đời của một chương trình sử dụng JPA (hình này ở bên trên). Tất cả những gì mình cần thực hiện bây giờ là trong phần chữ “executes” kia.
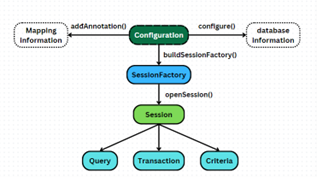
Còn đây là cấu tạo chung của một chương trình Hibernate, nghĩa là phần “executes” kia sẽ tương tự cái này.
- Khi một request đến server, một EntityManager được hình thành. Trong chương trình Hibernate thì nó tương đương với một Session được hình thành.
- Sau đó có thể thực thi các lệnh truy vấn, transaction, … bên trong một Session.
- Sau khi thực thi xong thì đóng EntityManager lại, hay đúng hơn với Hibernate là đóng Session lại.
Tuy nhiên tôi không thích dùng nhiều các lệnh linh tinh bên trong Session. Cộng thêm việc nó hỗ trợ transaction nên tôi thích cách dùng gói tất cả lệnh vào trong transaction, kể cả lệnh query không cần bảo mật.
Vậy nên quy trình trong một hàm main (sau này là một method chức năng nào đó) sẽ như sau:
Mở Session -> Mở Transaction -> CRUD -> commit/rollback transaction -> đóng Session
Code template:
Những bước cơ bản có như sau:
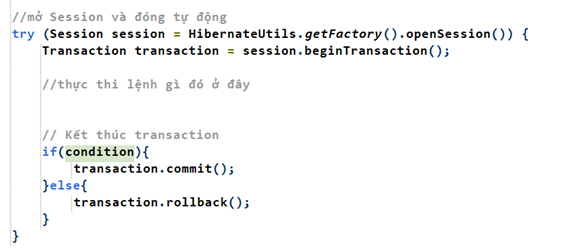
Trong đó:
- Session mở từ Factory.
- Transaction mở từ Session.
Session:
org.hibernate.Session
- Session trong Hibernate là một interface đại diện cho một phiên làm việc giữa ứng dụng Java và cơ sở dữ liệu.
- Nhiệm vụ chính của Session là thực hiện các thao tác tạo, đọc, và xóa trên các đối tượng của các lớp thực thể đã được ánh xạ (mapped entity classes).
- Trong Session chứa transaction thực hiện tất cả câu lệnh tác động đến các thực thể, và các câu lệnh đó cũng do session thực thi. Có thể hiểu như Session mở một Transaction, rồi Session thực hiện tiếp các hành động trong đó, bao gồm việc mở Query, rồi nó đóng Transaction.
Để thực hiện các hành động đó thì Session có các method sau:
https://javadoc.io/doc/org.hibernate/hibernate-core/5.6.15.Final/org/hibernate/Session.html
(docs này chưa có ở phiên bản hiện tại đâu)
Tôi sẽ trích ra vài hàm mà (tôi nghĩ là) sẽ dùng nhiều. Từ trên xuống dưới theo thứ tự thực thi nhé:
- Transaction beginTransaction(): mở transaction. Đóng bằng cách cho transaction commit() hoặc rollback().
- Query<T> createQuery(String hql): tạo một truy vấn HQL. Chỉ tạo thôi chưa làm gì cả.
- void persist(Object object): tạm thời dùng cái này để lưu một đối tượng mới vào CSDL, mặc dù ý định của cái này là đưa đối tượng vào trạng thái được quản lý, nhưng save() lỗi thời.
- Object merge(Object object): copy một đối tượng cũ đã detached vào một đối tượng mới persistent hiện có trong Session. Nó tương đương với UPDATE hoặc INSERT tùy trường hợp, và dùng thay update() lỗi thời.
- void remove(Object object): xóa thực thể ra khỏi CSDL. Đúng hơn là chuyển đối tượng đó từ trạng thái persistent thành transient. Tương đương với một câu lệnh DELETE. Dùng thay delete() lỗi thời.
- <T> get(Class<T> clazz, Serializable id): truy vấn và trả về một đối tượng dựa trên khóa chính (id). Nếu không tìm thấy, nó trả về null. Cái này cũng khá ổn.
- void flush(): đẩy tất cả hành động đang chần chừ (insert update delete) thực hiện ngay.
- void lock(Object entity, LockMode lockMode): Đặt một khóa trên đối tượng entity với chế độ khóa lockMode, kiểm soát việc đồng thời truy cập vào đối tượng. Chắc chắn sẽ dùng.
- clear(), close(),…
Những hàm trên đây khá quan trọng và cần ghi nhớ.
Chi tiết hành động trong Transaction:
Trong Transaction chúng ta phải thực thi các hành động CRUD đối với database thông qua thao tác với Entity. Bây giờ hãy nhìn lại các trạng thái có thể có của một Entity trong vòng đời của Transaction:
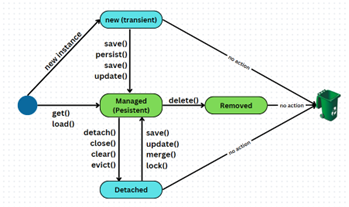
ảnh này có ở phần JPA (Java Persistence API).
Ở trên có nói về phần này rồi nhưng chắc chắn là chưa rõ ràng và chưa đi sát vào chương trình (vì chưa thử code). Bây giờ sẽ nói lại phần này.
Các trạng thái của thực thể trong một Transaction:
- Transient
- Khi tạo mới đối tượng bằng từ khóa new, đối tượng sẽ được sinh ra và ở dưới dạng Transient.
- Khi tạo mới, đối tượng chưa được liên kết với session nào, đồng nghĩa với việc nó chưa được Hibernate quản lý, chưa thể tồn tại trong database.
- Nếu muốn chuyển sang trạng thái Persistent để đồng bộ hóa với database sau commit thì phải dùng lệnh: save, persist, …(tùy phiên bản Hibernate nhưng nội dung lệnh sẽ như thế)
- Nếu không có hành động gì thì những đối tượng dạng này bị xóa khỏi chương trình sau commit.
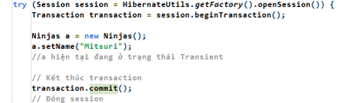
- Code VD:
- Persistent
- Khi gọi lệnh save, persist (từ đối tượng Transient) hay get (từ database), đối tượng sẽ ở dạng Persistent.
- Ở trạng thái này đối tượng được Hibernate để mắt tới và được đồng bộ hóa sau khi transaction commit.
- Sau khi commit, các đối tượng Persistent (sau khi đã đồng bộ hóa với database) sẽ chuyển sang trạng thái Detached – sẵn sàng bị vứt đi nếu không được cứu vớt.
- Code VD:
(đang đợi màn combat giữa save và persist vì chức năng tương tự nhưng :

Theo bản docs mới nhất thì save() đã chết.
https://docs.jboss.org/hibernate/orm/6.6/introduction/html_single/Hibernate_Introduction.html
vậy ở đây sẽ chỉ nói về persist và get.
-
-
- persist(Object): chuyển trạng thái của đối tượng: đang từ transient (tự do) về persistent (được quản lý bởi hibernate).
-
VD:

-
-
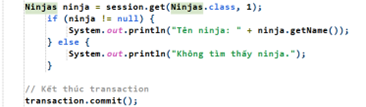
- get(Class, id): lấy đối tượng lên từ database theo id của nó trong database.
-
Còn rất rất nhiều method, hãy tự tìm hiểu/tự tra nếu cần thiết hoặc nếu rảnh.
- Detached
- Khi đóng session, đối tượng hiện tại đang được xử lý sẽ chuyển từ Persistent sang dạng Detached.
- Một đối tượng ở dạng Detached sẽ sẵn sàng cho việc bị xóa khỏi vòng đời của request đó, trừ khi sau khi session1 đóng thì có session2 mở ra và dùng update, merge hoặc saveOrUpdate.
- Nghĩa là session1 đã loại bỏ nó và nó sẽ bị vứt đi nếu không có session khác cứu nó.
- Nói kỹ hơn chút về 3 method trên:
- update(): Khi có một đối tượng Detached và muốn gắn lại nó với session khác để tiếp tục quản lý.
Nếu đối tượng này đã tồn tại trong session hiện tại hoặc có một đối tượng khác cùng ID trong session, sẽ xảy ra lỗi NonUniqueObjectException.
-
-
- merge(): Hibernate tạo ra một bản sao của đối tượng Detached và bản sao này trở thành Persistent. Bản gốc vẫn là Detached.
-
Không yêu cầu đối tượng phải có ID hợp lệ. Nếu ID null, Hibernate sẽ lưu đối tượng như một bản ghi mới.
-
-
- saveOrUpdate(): Nếu đối tượng đã tồn tại trong cơ sở dữ liệu (Detached), nó sẽ được cập nhật (update()). Nếu đối tượng chưa tồn tại (Transient), nó sẽ được lưu mới (save()). (Chắc tôi dùng method này suốt)
- Code VD:
-
Thôi để sau đi, cái này hiểu lý thuyết đã.
HQL:
https://docs.jboss.org/hibernate/orm/6.6/querylanguage/html_single/Hibernate_Query_Language.html
Có rất nhiều thứ phải học ở đây nhưng có lẽ ở đây chỉ viết được một chút.

GIỚI THIỆU: NGÔN NGỮ TRUY VẤN HIBERNATE – HIBERNATE QUERY LANGUAGE
Định nghĩa và tổng quan
- Theo GPT thì: HQL là một ngôn ngữ truy vấn cấp cao được thiết kế để truy vấn các đối tượng trong Hibernate. Thay vì làm việc với các bảng và cột trong cơ sở dữ liệu, HQL làm việc với các đối tượng và thuộc tính của chúng. Điều này giúp bạn giữ cho mã của mình gần gũi với mô hình dữ liệu của ứng dụng và độc lập hơn với cơ sở dữ liệu cụ thể.
- Trong cách kết nối với JDBC thì SQL được viết trực tiếp vào chương trình Java dưới dạng chuỗi:

Thì HQL cũng thế, cũng được đưa vào một String để thực thi như một câu truy vấn SQL.
- Cụ thể hơn thì HQL được dùng ở các class DAO, vv (vì chưa biết nó ở đâu thêm nữa)
- Cú pháp của HQL: chắc sẽ không nói nhiều về cái này vì nó gần gần SQL. Khác biệt lớn nhất là thay vì làm việc trực tiếp với các table của database thì nó làm việc với các entity của hibernate.
Viết mấy cái này với mặc định người đọc đã biết SQL một chút.
Cú pháp
1, Khi nào dùng select và không
-
- Khi dùng HQL cơ bản có 2 trường hợp truy vấn là dùng “select” hoặc không. VD:

Hoặc là:

Hãy tạm bỏ qua phần hàm bị lỗi thời, chú ý đến câu lệnh HQL. Khi dùng “select” thì lấy ra thuộc tính chỉ định còn khi không dùng “select”, viết mỗi ”from” thì lấy ra tất cả dữ liệu của nhóm đối tượng đó.
Trong HQL không hỗ trợ câu lệnh “select *”:
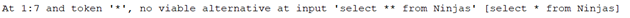
Lý do có thể như sau: HQL làm việc với các đối tượng chứ không phải các bảng. Với SQL, khi truy vấn đến bảng, câu lệnh “from” chỉ trỏ tới tên bảng chứ không đi vào từng thuộc tính. Với HQL khi làm việc với các đối tượng, “from” nghĩa là đã gọi đối tượng đó ra, và trong đối tượng có tất cả thông tin của bảng đó.
2, Interface Query<T>
org.hibernate.query.Query
- Không liên quan đến cú pháp nhưng nêu trước cho các phần VD sau còn hiểu được.
- Trong docs định nghĩa đơn giản: là một interface để quản lý các truy vấn.
- Cụ thể hơn, một Query được sinh ra khi gọi hàm sinh từ Session (createQuery…), sau đó nó có chức năng: thiết lập tham số, thực thi câu lệnh HQL, xử lý xuất kết quả. Sau đó nó bị xóa nếu Session kết thúc.
VD:

- Trong docs có định nghĩa nhiều method nhưng có một số method cơ bản (dựa vào chức năng trên) như sau:
- int executeUpdate(): thực thi câu lệnh update hoặc delete, trả về số thực thể bị ảnh hưởng (~ row affected)
- Query<T> setParameter(): thiết lập tham số cho câu lệnh HQL được truyền vào đối tượng Query đó. Có vẻ chức năng này giống ở bên PreparedStatement để tránh inject trực tiếp vào câu lệnh HQL. Điều này nghiễm nhiên tránh “HQLi” (mà có không ấy nhỉ)
- List list(): thực thi câu lệnh HQL có SELECT và trả về một List.
Vv và vv. Còn nhiều lắm. Nhưng hầu hết đã lỗi thời, còn cơ bản để dùng chắc có 3 cái trên (đoán là) hay được dùng nhất. Đọc thêm ở đây: https://docs.jboss.org/hibernate/orm/5.6/javadocs/org/hibernate/query/Query.html
(tôi thấy hối hận vì xây dựng DB phức tạp không demo nổi, vì tôi quên hết rồi)
(bonus)
Tôi chắc là sẽ xây lại database cho thật đơn giản để demo cho nhanh.
DROP SCHEMA IF EXISTS mf;
CREATE SCHEMA mf;
USE mf;
CREATE TABLE Classes (
classID nvarchar(10) primary key,
className nvarchar(20),
classType nvarchar(5) -- c/cc
);
CREATE TABLE Students (
studentID int primary key auto_increment,
studentName nvarchar(50),
studentGender nvarchar(10),
studentDetails nvarchar(200),
classID nvarchar(10),
foreign key (classID) references Classes(ClassID)
)
3, Tham số trong HQL
- Tham số trong HQL là đại diện cho giá trị trong câu lệnh HQL (chứ không phải cho tên cột hay tên bảng, …) vì HQL không muốn bị injection. Nhớ kỹ cái này.
- Có hai cách để sử dụng tham số trong HQL:
- Tham số vị trí (Positional Parameters): Sử dụng dấu ? và thứ tự chỉ số (bắt đầu từ 1).
- Tham số tên (Named Parameters): Sử dụng dấu : và tên tham số.
- Mỗi loại tham số có một cách truyền khác nhau. Xem VD tự hiểu:

Và

4, Join trong HQL
Mỗi khi viết câu lệnh HQL nào cũng nên nhớ nó dành cho các đối tượng. Và JOIN cũng vậy.
Có 5 loại join trong SQL: inner, left, right, fullouter, cross. HQL cũng có nhưng chia ra thành phần khác một chút:
- Join thường: các loại hay gặp trong SQL như trên. Với cú pháp hơi khác:
SELECT a.property1, b.property2
FROM A a
[INNER | LEFT | RIGHT] JOIN a.B b
- Join Fetch: tải trước (eager fetching) các thực thể liên quan, giảm thiểu số lượng truy vấn cần thực hiện. Chưa rõ nó có liên quan đến phần lựa chọn (fetch=”FetchType.EAGER”) mà trước đó có nói hay không, nhưng sẽ tìm hiểu cái này sau.
SELECT a
FROM A a
JOIN FETCH a.B b
- Implicit join: Join tự động mà không cần dùng từ khóa “Join” trong câu truy vấn. Trong mỗi đối tượng nếu bảng tương ứng có cột khóa ngoại liên kết thì đối tượng đó cũng có thuộc tính liên kết, và dựa vào đó làm thành các câu truy vấn. Loại này thay thế cho Inner Join.
SELECT a.property1, a.B.property2
FROM A a
Cơ bản những thứ khác biệt thông thường là thế. Nếu muốn hãy tìm hiểu thêm: https://docs.jboss.org/hibernate/orm/6.6/querylanguage/html_single/Hibernate_Query_Language.html
Tuy còn phần từ session đến Query nhưng phần này không quan trọng đến thế, có thể xem VD.
Cơ bản đã hết. Sau đây là ví dụ code đơn giản cho phần CRUD:
Vì chưa tìm được mô hình nào tốt hơn nên tôi tạm lấy theo mô hình MVC.
Theo đó tôi sẽ tạo một class DAO dành cho Students để demo:

(Tạm thời không viết Interface các kiểu nữa mà đi thẳng vào DAO luôn)
Nhớ là SessionFactory chỉ được tạo một lần trong cả vòng đời chương trình, nên DAO không khởi tạo nó, chỉ nhận nó. Thêm nữa vì đây là demo nên không thử tất cả các ĐK, cái đó tự xây dựng trong từng chương trình.
Create:

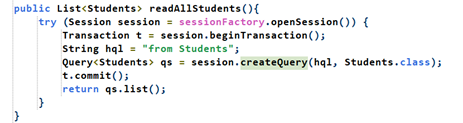
Read:
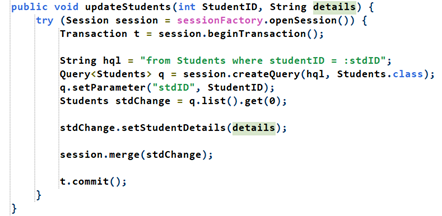
Update: (với details, các thuộc tính hay cách khác tương tự)
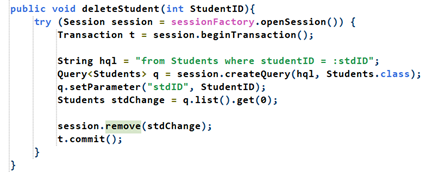
Delete:
Tôi quá lười để viết thêm, thực ra cấu trúc nó cần như thế này:

Hết phần I Hibernate. Cảm ơn ai đọc đến tận đây:))))
All rights reserved
