Nghệ Thuật Streamed Responses: Bí Quyết Đằng Sau Tốc Độ "Bàn Thờ" Của ChatGPT
hôm nay chúng ta sẽ giải mã một trong những công nghệ "lên ngôi" mạnh mẽ nhất trong kỷ nguyên AI: Streamed Responses (Phản hồi dạng luồng).
Bạn có bao giờ thắc mắc: Tại sao khi hỏi ChatGPT một câu dài, nó không bắt bạn chờ 10 giây rồi hiện ra cả bài văn, mà lại "gõ" từng chữ một ra màn hình cho bạn xem?
Đó không phải là hiệu ứng animation (hiệu ứng hình ảnh) làm màu của Frontend đâu! Đó là một kiến trúc Backend tối ưu cực độ giúp giảm thiểu
Thời gian chờ byte đầu tiên (TTFB - Time To First Byte). Dưới đây là bài viết mổ xẻ nghệ thuật gửi dữ liệu nhỏ giọt này!
PHẦN 1: TƯ DUY "GÓI MANG VỀ" VÀ CÁI CHẾT CỦA VÒNG TRÒN LOADING
Cách HTTP hoạt động truyền thống (Tư duy Thợ gõ): Mô hình Request-Response cơ bản giống như bạn đi mua một hộp cơm thập cẩm:
- Bạn đưa giấy gọi món (Request).
- Đầu bếp vào bếp, chiên cơm, nướng thịt, xào rau, đóng hộp, đậy nắp thật kín.
- Đầu bếp giao toàn bộ hộp cơm cho bạn (
Response res.send()).
Nếu quá trình nấu mất 10 giây, bạn sẽ phải đứng nhìn cái biển "Loading..." đúng 10 giây. Trình duyệt (Frontend) không thể làm gì khác ngoài việc xoay mòng mòng vì nó chưa nhận được bất kỳ dữ liệu nào. User sẽ tưởng mạng lag hoặc app bị treo và bấm F5 hoặc thoát app.
Kịch bản thực tế: Bạn gọi một API để tạo báo cáo Excel nặng 50MB, hoặc gọi API của OpenAI để viết một bài luận 2000 chữ. Thời gian chờ có thể lên tới 15 - 30 giây. Để User chờ 30 giây nhìn màn hình trắng là một tội ác trong thiết kế UX (Trải nghiệm người dùng)!
PHẦN 2: GIẢI PHÁP VIBE CODER - "ĂN BUFFET" VỚI CHUNKED TRANSFER ENCODING
Thay vì đợi nấu xong cả hộp cơm rồi mới giao, Vibe Coder sử dụng cơ chế Streaming (Luồng). Nó giống như bạn ăn Buffet: Đầu bếp chiên xong miếng thịt nào, gắp thẳng ra đĩa cho bạn ăn ngay miếng đó, trong lúc họ quay lại xào tiếp rau.
Trong thế giới HTTP, kỹ thuật này được kích hoạt bằng một Header có tên là:
Transfer-Encoding: chunked
Cách hoạt động:
- Trình duyệt gửi Request.
- Server không đợi xử lý xong toàn bộ. Ngay khi có đoạn dữ liệu đầu tiên (Chunk), Server gửi luôn xuống Trình duyệt, NHƯNG giữ kết nối mạng (Connection) mở, không đóng lại.
- Cứ 0.1 giây, Server lại "nhỏ giọt" thêm một từ mới xuống.
- Trình duyệt nhận được từ nào, in ngay ra màn hình từ đó.
- Khi xong việc, Server mới chính thức gửi tín hiệu cắt đứt kết nối (
res.end()).
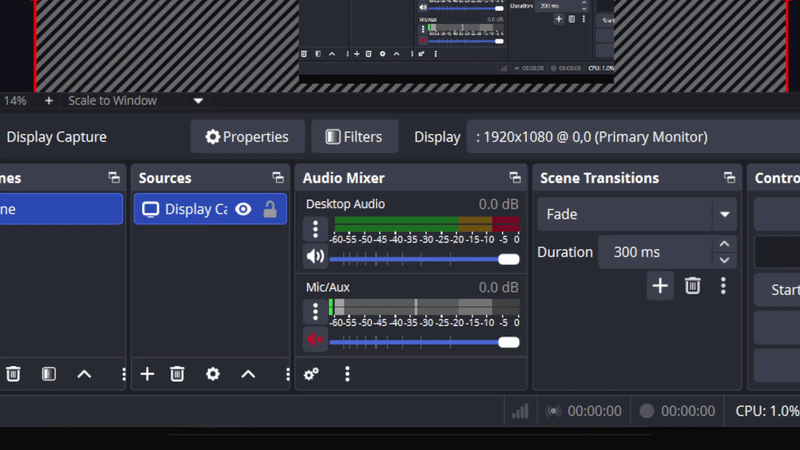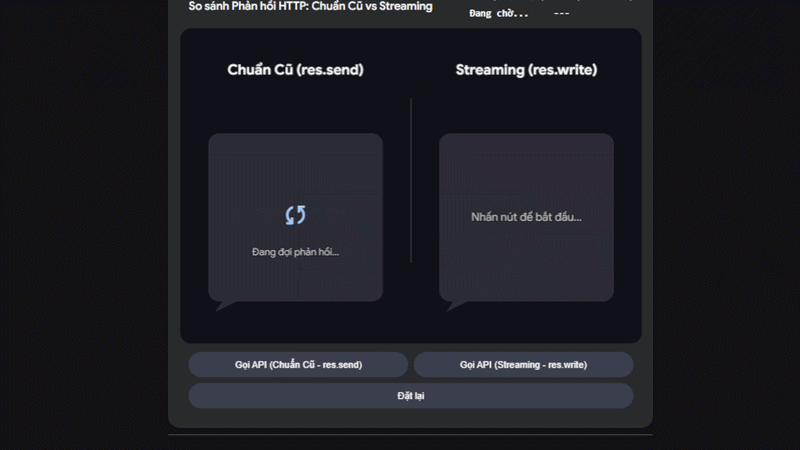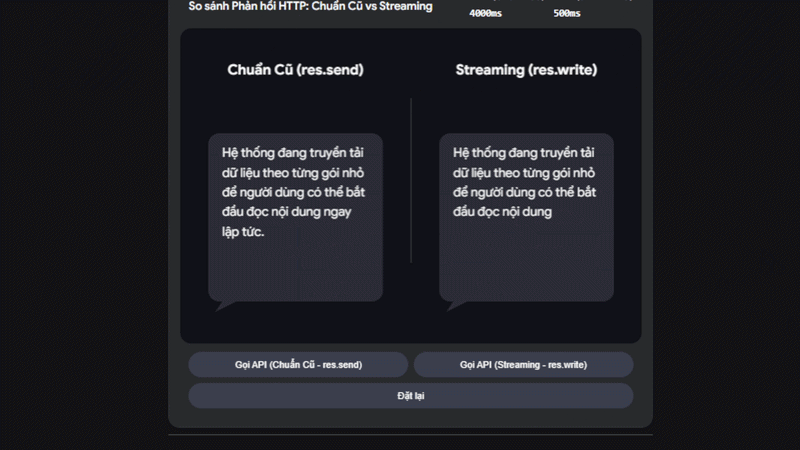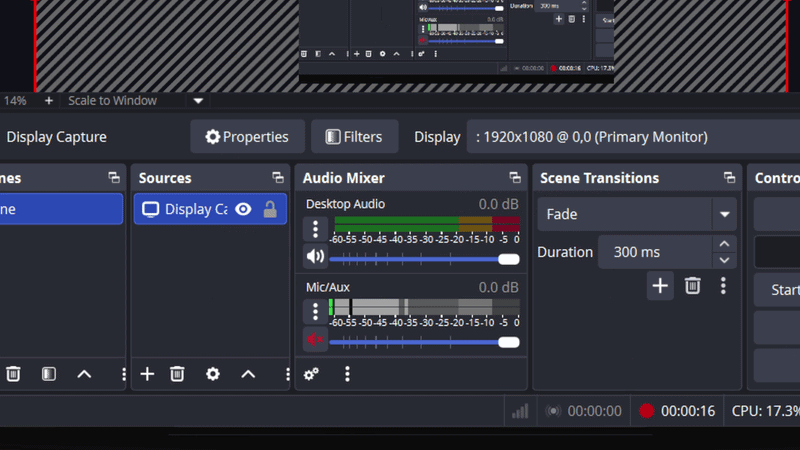
Kết quả: User thấy chữ đầu tiên xuất hiện chỉ sau 0.5 giây thay vì phải chờ 10 giây. Tốc độ cảm nhận (Perceived Performance) tăng lên gấp 20 lần!
PHẦN 3: CODE THỰC CHIẾN BẰNG NODE.JS
Viết một API Streaming trong Express.js dễ hơn bạn nghĩ rất nhiều. Bí quyết nằm ở việc sử dụng hàm res.write() thay vì res.send().
const express = require('express');
const app = express();
// API tạo bài văn AI giả lập
app.get('/api/generate-story', async (req, res) => {
// 1. Cấu hình Header để báo cho Client biết đây là luồng dữ liệu
res.setHeader('Content-Type', 'text/plain; charset=utf-8');
res.setHeader('Transfer-Encoding', 'chunked');
const story = "Ngày nảy ngày nay, có một Vibe Coder đang ngồi viết code bằng Node.js...";
const words = story.split(' ');
// 2. Dùng vòng lặp để gửi từng chữ một (Giả lập AI đang suy nghĩ)
for (let word of words) {
// Gửi MỘT CHỮ xuống Client ngay lập tức
res.write(word + ' ');
// Dừng 200ms để giả lập độ trễ tính toán của AI
await new Promise(resolve => setTimeout(resolve, 200));
}
// 3. RẤT QUAN TRỌNG: Gửi xong phải chốt sổ.
// Nếu quên gọi res.end(), trình duyệt sẽ quay loading vô tận!
res.end();
});
Ở phía Frontend (JavaScript/React), thay vì dùng await fetch().then(res => res.json()) quen thuộc, bạn sẽ dùng Streams API (cụ thể là res.body.getReader()) để liên tục đọc các mảnh (chunk) dữ liệu khi chúng vừa cập bến.
PHẦN 4: TRẢI NGHIỆM TRỰC QUAN - SỰ KHÁC BIỆT VỀ UX
Để hiểu rõ tại sao Streaming lại mang đến trải nghiệm "như phép thuật" trong kỷ nguyên AI, thử bấm nút gọi API trong bộ mô phỏng dưới đây và quan sát chỉ số TTFB (Time To First Byte) nhé!
PHẦN 5: CÚ LỪA CỦA NGINX (BÀI HỌC MÁU CHÓ CỦA SENIOR)
Code chạy ở máy bạn (localhost) từng chữ nhảy ra rất mượt. Bạn tự hào đem deploy lên Server Production chạy qua Nginx. Và... BÙM! Nó lại xoay loading 4 giây rồi nhả ra cả cục dữ liệu. Streaming bị tắt ngúm!
Tại sao? Bởi vì Nginx (hoặc Cloudflare) đứng chắn giữa Node.js và Trình duyệt có một tính năng gọi là Buffering. Nó thấy Node.js nhả ra từng chữ lẻ tẻ, nó nghĩ: "Gửi lắt nhắt thế này tốn băng thông, để tao gom (buffer) lại thành cục to 4KB rồi tao gửi cho Frontend một thể!"
Giải pháp Vibe Coder: Bạn phải tắt tính năng "nhốt" dữ liệu này của Nginx bằng cách chèn header X-Accel-Buffering: no ở code Node.js, hoặc sửa file cấu hình nginx.conf:
proxy_buffering off;
Lời kết Streamed Responses không sinh ra để thay thế REST API chuẩn. Nếu bạn lấy danh sách User, hãy cứ dùng JSON bình thường. Nhưng nếu bạn xử lý AI, xuất file CSV/Excel khổng lồ, hay truyền Video, Streaming chính là chiếc đũa thần giúp Frontend không bao giờ bị "đứng hình" và Server không bao giờ bị tràn RAM do phải ôm một cục dữ liệu quá lớn trước khi gửi.
Chủ đề tiếp theo: Kẻ Thay Thế Polling - SSE (Server-Sent Events) vs WebSockets
Streamed Responses giải quyết bài toán: Client gọi 1 lần, Server trả lời dần dần. Nhưng nếu bạn muốn làm tính năng Bảng giá chứng khoán realtime hoặc Thông báo Facebook thì sao?
Trình duyệt không thể cứ 1 giây lại gửi Request hỏi Server "Có tin mới chưa?" (Kỹ thuật Polling - đập nát DB). Chúng ta cần một đường ống để Server CHỦ ĐỘNG đẩy dữ liệu xuống Trình duyệt bất cứ lúc nào nó muốn.
Giữa 2 công nghệ thời gian thực: WebSockets (Đường ống 2 chiều, phức tạp) và SSE - Server-Sent Events (Đường ống 1 chiều, siêu nhẹ), bạn nên chọn vũ khí nào? Bạn có muốn mình làm một bài phân tích "đấm nhau" giữa 2 công nghệ này để biết lúc nào xài cái nào không?
All rights reserved
