Neural Network Part 2: Back Propagation Algorithm
Bài đăng này đã không được cập nhật trong 4 năm
The backpropagation algorithm was commenced in the 1970s, but until 1986 after a paper by David Rumelhart, Geoffrey Hinton, and Ronald Williams was publish, its significance was appreciated. That paper focused several neural networks where backpropagation works far faster than earlier learning approaches. Today, the backpropagation algorithm is the workhorse of learning in neural networks.
Cost Function
Let's first define a few variables that we will need to use:
- L = total number of layers in the network
- sl = number of units (not counting bias unit) in layer l
- K = number of output units/classes
Remember that in neural networks, we may have many output nodes. We denote hΘ(x)k as being a hypothesis that results in the k-th output. Our cost function for neural networks is going to be a generalization of the one we used for logistic regression. Recall that the cost function for regularized logistic regression was:
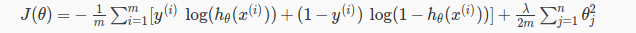
For neural networks, it is going to be slightly more complicated:
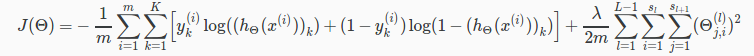
We have added a few nested summations to account for our multiple output nodes. In the first part of the equation, before the square brackets, we have an additional nested summation that loops through the number of output nodes.
In the regularization part, after the square brackets, we must account for multiple theta matrices. The number of columns in our current theta matrix is equal to the number of nodes in our current layer (including the bias unit). The number of rows in our current theta matrix is equal to the number of nodes in the next layer (excluding the bias unit). As before with logistic regression, we square every term.
Note:
- the double sum simply adds up the logistic regression costs calculated for each cell in the output layer
- the triple sum simply adds up the squares of all the individual Θs in the entire network.
- the i in the triple sum does not refer to training example i
Backpropagation Algorithm
"Backpropagation" is neural-network terminology for minimizing our cost function, just like what we were doing with gradient descent in logistic and linear regression. Our goal is to compute:
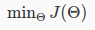
That is, we want to minimize our cost function J using an optimal set of parameters in theta. In this section we'll look at the equations we use to compute the partial derivative of J(Θ):
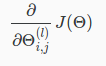
Back propagation Algorithm
Given training set
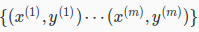
Set Δ(l)i,j := 0 for all (l,i,j), (hence you end up having a matrix full of zeros) For training example t =1 to m:
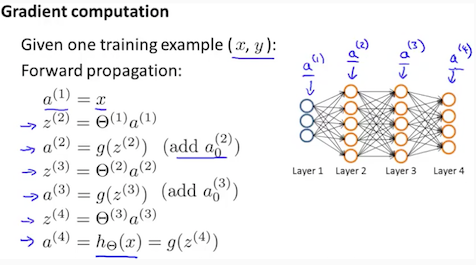
- Set a(1) := x(t)
- Perform forward propagation to compute a(l) for l=2,3,…,L
-
Using y(t), compute δ(L)=a(L)−y(t)
Where L is our total number of layers and a(L) is the vector of outputs of the activation units for the last layer. So our "error values" for the last layer are simply the differences of our actual results in the last layer and the correct outputs in y. To get the delta values of the layers before the last layer, we can use an equation that steps us back from right to left:
-
Compute
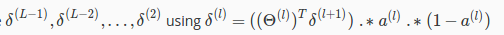 The delta values of layer l are calculated by multiplying the delta values in the next layer with the theta matrix of layer l. We then element-wise multiply that with a function called g', or g-prime, which is the derivative of the activation function g evaluated with the input values given by z(l).
The delta values of layer l are calculated by multiplying the delta values in the next layer with the theta matrix of layer l. We then element-wise multiply that with a function called g', or g-prime, which is the derivative of the activation function g evaluated with the input values given by z(l).The g-prime derivative terms can also be written out as:

-
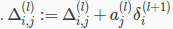 or with vectorization,
or with vectorization, 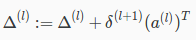 Hence we update our new Δ matrix.
Hence we update our new Δ matrix.
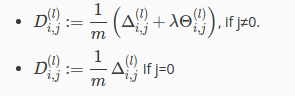
The capital-delta matrix D is used as an "accumulator" to add up our values as we go along and eventually compute our partial derivative. Thus we get
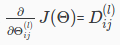
All rights reserved
