Bài trước tôi đã trình bày các công thức của back propagation trong bài này tôi sẽ chứng minh các công thức đó
I. Proof d\mathbf{z}^{[L]} = \hat \mathbf{y} - \mathbf{y}
Trước hết ta chứng minh cho trường hợp chỉ 1 training example. Ta sẽ tính đạo hàm riêng đối với zc[L] (phần từ thứ c của output z, sau khi áp dụng hàm softmax) của hàm loss là −logf(x)y (đọc thêm ở bài 3, phân biệt y viết thường và y viết đậm: y là số thứ tự của phần tử mà vector y có giá trị là 1). Trông các bước có vẻ phức tạp nhưng nếu theo dõi từng bước một bạn sẽ thấy cũng khá dễ hiểu và đẹp.
∂zc[L]∂−logf(x)y=∂zc[L]∂−log(softmax(z[L])y)
=∂zc[L]∂−log(∑iezi[L]ezy[L])
=−ezy[L]∑iezi[L]∂zc[L]∂∑iezi[L]ezy[L]
Đến đây để tính đạo hàm riêng của ∂zc[L]∂∑iezi[L]ezy[L] ta áp dụng quy tắc tìm đạo hàm riêng của h(x)g(x)
∂x∂h(x)g(x)=∂x∂g(x)h(x)1−h2(x)g(x)∂x∂h(x)
Nên ta có
∂zc[L]∂−logf(x)y=−ezy[L]∑iezi[L](∂zc[L]∂ezy[L]∑iezi[L]1−∑iezi[L]∑iezi[L]ezy[L]∂zc[L]∂∑iezi[L])
=−ezy[L]∑iezi[L](1(c=y)ezc[L]∑iezi[L]1−∑iezi[L]∑iezi[L]ezy[L]ezc[L] 1(c=y) là hàm indicator trả về 1 nếu c = y và trả về 0 nếu y = c
=−ezy[L]∑iezi[L](1(c=y)∑iezi[L]ezc[L]−∑iezi[L]ezy[L]∑iezi[L]ezc[L]
=−softmax(z[L])y1(1(c=y)softmax(z[L])c−softmax(z[L])ysoftmax(z[L])c)
=−(1(c=y)−softmax(z[L])c)
=−(1(c=y)−y^c)
=y^c−1(c=y)
Do đó nếu đạo hàm riêng cả vector z[L] thì
∂z[L]∂−logf(x)y=y^−y hay \qquad d\mathbf{z}^{[L]} = \hat \mathbf{y} - \mathbf{y}
II. Proof da[l−1]=W[l]Tdz[l]
Giả sử ta đã tính được đạo hàm riêng của z ở lớp thứ l làm sao ta có thể tính tiếp đạo hàm riêng a ở lớp l−1?
Ta nhắc lại phần tử thứ i của z[l] được tính từ a[l−1] như sau
zi[l]=∑jWi,j[l]aj[l−1]+bi[l] (Tích vector của row thứ i của matrix W[l] và vector a[l−1]+ phần tử thứ i của vector bias b[l])
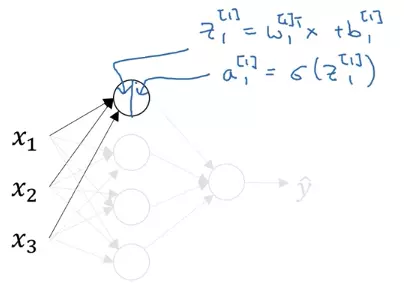 (Trong ảnh thay x bằng a)
(Trong ảnh thay x bằng a)
Ta thấy mỗi phần từ aj[l−1] đều đóng vai trò vào việc tính toán từng phần tử zi[l] mà ta biết hàm loss function là hàm số của z[l], đã biết được đạo hàm riêng của z[l], điều đó gợi ý ta sử dụng chain rule
Chain rule
Nếu hàm số f(a) là hàm số của các hàm số gi(a) thì
∂a∂f(a)=∑i∂gi(a)∂f(a)∂a∂gi(a)
Dùng chain rule ta set f(a) là loss function −logf(x)y, gi(a) là zi[l] còn a là ac[l−1], ta tính đạo hàm riêng đối với phần tử thứ c của a[l−1]
∂ac[l−1]∂−logf(x)y=∑i∂zi[l]∂−logf(x)y∂ac[l−1]∂zi[l](1)
Do zi[l]=∑jWi,j[l]aj[l−1]+bi[l] nên ∂ac[l−1]∂zi[l]=Wi,c[l] thay vào (1)
∂ac[l−1]∂−logf(x)y=∑i∂zi[l]∂−logf(x)yWi,c[l]
= Tích của vector dz[l] và cột thứ i của matrix W[l]
Do đó nếu đạo hàm riêng cả vector a[l−1] thì
∂a[l−1]∂−logf(x)y=W[l]T∂z[l]∂−logf(x)y hay da[l−1]=W[l]Tdz[l]
III. Proof $dW^{[l]} = d\mathbf z^{[l]} \mathbf a^{[l - 1]T} $
Như đã nói ở phần trên, công thức liên hệ giữa lớp l−1 và lớp l là
zi[l]=∑jWi,j[l]aj[l−1]+bi[l]
Để ý thấy Wi,j[l] chỉ đóng góp cho biểu thức của zi[l] mà không xuất hiện trong các phẩn tử khác của z[l], ta áp dụng chain rule để tính đạo hàm riêng của cost function đối với Wi,j[l]
$\dfrac{\partial-logf(x)y}{\partial W^{[l]}{i,j}} = \dfrac{\partial-logf(x)_y}{\partial \mathbf z^{[l]}_i} \dfrac{\partial \mathbf z^{[l]}i}{\partial W^{[l]}{i,j}} $
=∂zi[l]∂−logf(x)yaj[l−1]
Do đó nếu đạo hàm riêng cả matrix W[l] thì
∂W[l]∂−logf(x)y=∂z[l]∂−logf(x)ya[l−1]T hay dW[l]=dz[l]a[l−1]T (Phần tử thứ i, j của W[l] là Wi,j[l] bằng phần tử thứ i của dz[l] nhân với phần tử thứ j của a[l−1])
IV. Proof db[l]=dz[l]
Nhắc lại công thức liên hệ giữa lớp l−1 và lớp l
zi[l]=∑jWi,j[l]aj[l−1]+bi[l]
bi[l] chỉ đóng góp cho biểu thức của zi[l] mà không xuất hiện trong các phẩn tử khác của z[l], ta áp dụng chain rule để tính đạo hàm riêng của cost function đối với phần tử thứ i của b[l]
$\dfrac{\partial-logf(x)_y}{\partial \mathbf b^{[l]}_i} = \dfrac{\partial-logf(x)_y}{\partial \mathbf z^{[l]}_i} \dfrac{\partial \mathbf z^{[l]}_i}{\partial\mathbf b^{[l]}_i} $
=∂zi[l]∂−logf(x)y×1
Do đó nếu đạo hàm riêng cả vector b[l] thì
∂b[l]∂−logf(x)y=∂z[l]∂−logf(x)y hay db[l]=dz[l]
V Proof dz[l]=da[l]∗g[l]′(z[l])
Trong lớp l công thức liên hệ giữa zi[l] và ai[l] là
ai[l]=g[l](zi[l]) trong đó g[l]() là hàm activation của lớp l
Áp dụng chain rule ta có
∂zi[l]∂−logf(x)y=∂ai[l]∂−logf(x)y∂zi[l]∂ai[l]
=∂ai[l]∂−logf(x)y∂zi[l]∂g[l](zi[l])
Tức là đạo hàm riêng đối với phần tử thứ i của z[l] bằng đạo hàm riêng đối với phần tử thứ i của a[l] nhân với đạo hàm riêng của hàm activation đối với phần tử thứ i của z[l]
Do đó nếu đạo hàm riêng cả vector z[l] thì
∂z[l]∂−logf(x)y=∂a[l]∂−logf(x)y∗(elementwise)∂z[l]∂g[l](z[l]) hay dz[l]=da[l]∗g[l]′(z[l]) (nhân 2 phần từ tương ứng của 2 vector da[l] và g[l]′(z[l]) với nhau để ra vector dz[l])
Tham khảo
- Coursera deep learning
- Hugo Larochelle Neural Network
