Neural Network Fundamental 2: Representation and Forward Propagation
Bài đăng này đã không được cập nhật trong 4 năm
I. Neural Network Representation for 2 layers
Dưới đây là biểu diễn của mạng neural với 2 lớp
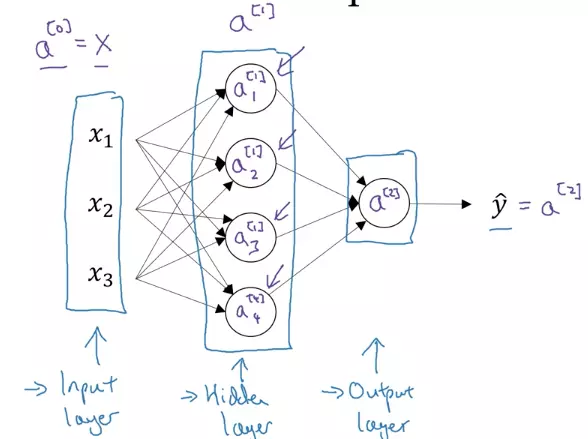
- Các input feature , , ... được xếp chồng lên nhau và được gọi là input layer
- Lớp tiếp theo chứa các node là sự kết hợp của các node trong input layer được gọi là hidden layer
- Lớp cuối cùng chỉ có một node, chứa giá trị dự đoán được gọi là output layer Để tiện cho việc tính toán, ta sẽ vector hóa các node trong mỗi layer bằng các vector
- Số ở trên dấu ngoặc vuông trên đầu của thể hiện số layer. Số layer được đánh số từ 0 ở input layer
- Số ở dưới của thể hiện node thứ mấy trong lớp đó Ví dụ vector ở input layer Mạng neural như trên hình được gọi là mạng neural 2 lớp vì chúng ta không đếm input layer
II.Forward Propagation with 2 layers Neural Network
Forward Propagation hiểu nôm na là bắt đầu từ input, ta sẽ tính toán giá trị các neural của từng lớp một, đến cuối cùng sẽ tính ra giá trị của lớp output.
Như đã nói ở phần Artificial Neural trong phần 1 mỗi giá trị ở một neural (node) sẽ được tính toán qua 2 bước
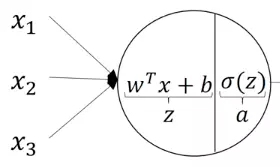 + b
Trong đó z gọi là giá trị pre-activation, còn a gọi là giá trị activation, và là các parameter của neural network. Mục đích cuối cùng của chúng ta là optimize các parameter này sao cho neural network có thể output một cách chính xác nhất
+ b
Trong đó z gọi là giá trị pre-activation, còn a gọi là giá trị activation, và là các parameter của neural network. Mục đích cuối cùng của chúng ta là optimize các parameter này sao cho neural network có thể output một cách chính xác nhất
Tính toán ở hidden layer
Dựa vào nguyên tắc trên, ta bắt đầu tính toán ở neural đầu tiên của hidden layer
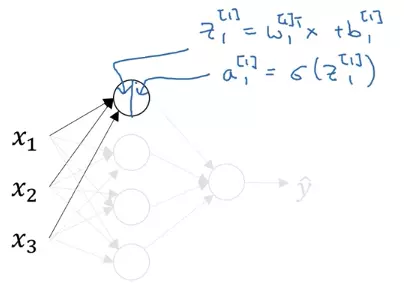
- : số ở trên cho ta biết thuộc lớp thứ 1, số ở dưới thể hiện đây là giá trị pre-activation của neural đầu tiên của lớp này
- : số ở trên thể hiện đây là vector để tính toán lớp thứ 1, số ở dưới thể hiện w này là để tính toán neural thứ 1
- và : cũng thể hiện tương ứng
Tương tự như vậy ta tính toán cho neural thứ 2 của hidden layer
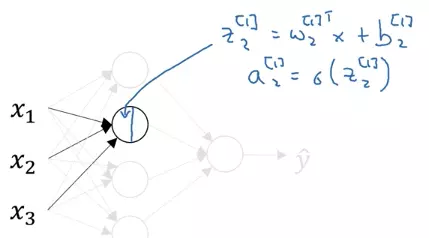 Tính toán hết với cả 4 neural của hidden layer ta được
=
=
=
=
Trong code ta có thể dùng vòng lặp for để tính các giá trị z và a của hidden unit, nhưng làm như vậy mất rất nhiều thời gian. Do đó, ta sẽ vector hóa việc tính toán lại
Đầu tiên ta sẽ xếp các vector , , , lại thành matrix , các giá trị của b thành vector . Số index trên đầu thể hiện đây là các parameter của lớp 1
Ta để ý matrix có chiều là 4 x 3 = số neural của lớp hiện tại (hidden layer) x số neural lớp trước (input layer)
Từ đó ta có thể biểu diễn các giá trị của vector
Tính toán hết với cả 4 neural của hidden layer ta được
=
=
=
=
Trong code ta có thể dùng vòng lặp for để tính các giá trị z và a của hidden unit, nhưng làm như vậy mất rất nhiều thời gian. Do đó, ta sẽ vector hóa việc tính toán lại
Đầu tiên ta sẽ xếp các vector , , , lại thành matrix , các giá trị của b thành vector . Số index trên đầu thể hiện đây là các parameter của lớp 1
Ta để ý matrix có chiều là 4 x 3 = số neural của lớp hiện tại (hidden layer) x số neural lớp trước (input layer)
Từ đó ta có thể biểu diễn các giá trị của vector
Và vector
Tính toán ở output layer
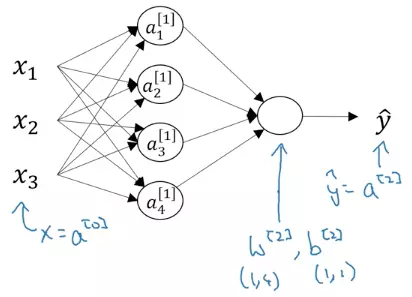 Output layer sẽ nhận vector của hidden layer làm input và thực hiện tính toán tương tự như ở hidden layer ta có
Để ý chiều của là 1 x 4 , còn của là 1 x 1
Tóm tắt lại ở cả 2 bước thì forward propagation thức hiện tính toán như sau
Output layer sẽ nhận vector của hidden layer làm input và thực hiện tính toán tương tự như ở hidden layer ta có
Để ý chiều của là 1 x 4 , còn của là 1 x 1
Tóm tắt lại ở cả 2 bước thì forward propagation thức hiện tính toán như sau
Vector hóa với nhiều training example
Trên đây ta thực hiện forward propagation với một training example từ input tính toán ra giá trị dự đoán : . Thực hiện với m training examples khác nhau ta lặp lại quá trình đó m lần
Trong đó các giá trị trọng () ở trên thể hiện đây là đây là training example thứ mấy. Ví dụ là output của training example thứ 2
Nếu dùng vòng lặp for để thực hiên forward propagation với tất cả training example:
for i = 1 to m:
Chú ý là các parameter và giữ nguyên giá trị với các training example khác nhau
Như trên đã nói việc dùng vòng lặp for rất chậm nên ta phải vector hóa nó. Các training example có thể cho vào 1 matrix như đã nói ở phần 1
$X =\begin{bmatrix}{{\vert\atop x^{(1)}}\atop\vert}{{\vert\atop x^{(2)}}\atop\vert} \cdots {{\vert\atop x^{(m)}}\atop\vert} \end{bmatrix} $
Vector hóa của vòng lặp ở trên sẽ thành như sau
Trong đó là matrix có được khi xếp các vector z của layer 1 của mỗi training example vào mỗi cột
$Z^{[1]} =\begin{bmatrix}{{\vert\atop z^{1}}\atop\vert}{{\vert\atop z^{1}}\atop\vert} \cdots {{\vert\atop z^{1}}\atop\vert} \end{bmatrix} $
Số ở ngoặc vuông biểu diễn index của layer, số trong ngoặc tròn thể hiện training example thứ mấy. Ví dụ giá trị góc trên cùng bên trái của là pre-activation của neural thứ 1 của lớp thứ 1 của training example thứ 1
Tương tự là matrix khi xếp các vector a của layer 1 của mỗi training example vào mỗi cột
$A^{[1]} =\begin{bmatrix}{{\vert\atop a^{1}}\atop\vert}{{\vert\atop a^{1}}\atop\vert} \cdots {{\vert\atop a^{1}}\atop\vert} \end{bmatrix} $
Tham khảo
- Coursera deep learning
- Hugo Larochelle Neural Network
All rights reserved
