Neighborhood-based Collaborative Filtering: Phương pháp gợi ý dựa trên láng giềng gần nhất (P1)
Bài đăng này đã không được cập nhật trong 3 năm
Mình đã quay trở lại và ăn hại ... à nhầm lợi hại hơn xưa 
Sau 2 bài về Content-based thì mình sẽ tiếp tục chia sẻ tiếp về Recommend. Cụ thể, trong bài viết này là NBCF (Neighborhood-based Collaborative Filtering) - Phương pháp gợi ý dựa theo láng giềng gần nhất. Sau đó là MF (Matrix Factorixzation), cơ mà không biết bao giờ mới xong =))
1. Muốn bỏ qua khái niệm mà KHÔNG THỂ
Neighborhood-based Collaborative Filtering: Phương pháp gợi ý các items dựa trên sự tương quan (similarity) giữa các users và/hoặc items. Có thể hiểu rằng đây là cách gợi ý tới một user dựa trên những users có hành vi tương tự.
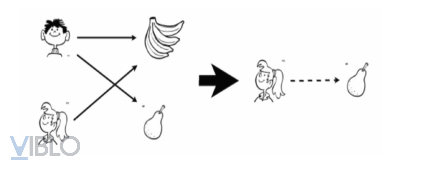
Như ví dụ, có một cậu bé thích chuối và lê, đồng thời, có một cô bé có sở thích tương tự như cậu bé. Khi đó, khả năng cao là cô bé cũng sẽ thích lê giống như cậu bé, vì vậy hệ thống sẽ gợi ý lê cho cô bé. Tương tự, nếu trên một hệ thống xem phim, có user A và B đều cùng xem một số bộ phim. Khi user A đã xem một bộ phim mà user B chưa xem, rất có khả năng là user B cũng sẽ muốn xem bộ phim ấy, do đó, hệ thống sẽ gợi ý bộ phim ấy cho user B.
Phương pháp này được chia thành 2 hướng nhỏ, là User-User Collaborative Filtering (uuCF) và Item-Item Collaborative Filtering (iiCF). Như vầy nè:
uuCF: Tư tưởng của hướng tiếp cận này là tìm ra những nhóm user tương tự nhau. Từ đó, dự đoán mức độ yêu thích của một user dựa trên những users khác cùng nhóm.
Hướng tiếp cận này được thực hiện như sau:
- Biểu diễn mỗi user bằng một vector thuộc tính được xây dựng từ những feedback trong quá khứ của user với các item. Từ đó, tính toán độ tương đồng giữa các user.
- Để tính toán độ yêu thích của user U với một item I, ta sẽ lựa chọn ra k users đã từng đánh giá I và có độ tương đồng với user U là cao nhất. Sau đó, dựa vào những feedback của k user đó với item I để tính toán ra kết quả.
- Cuối cùng, lựa chọn những items được dự đoán user U yêu thích nhất để gợi ý cho U.
iiCF: Tương tự như User-User, phương pháp này sẽ tìm ra những nhóm item tương tự nhau. Sau đó, dự đoán mức độ yêu thích của user với item dựa trên độ yêu thích của user đó với các item khác cùng loại.
Hướng tiếp cận này được thực hiện như sau:
- Biểu diễn mỗi item bằng một vector thuộc tính. Từ đó, tính toán độ tương đồng giữa các item.
- Để tính toán độ yêu thích của user U với một item I, ta sẽ lựa chọn ra k items đã từng được U đánh giá và có độ tương đồng với I là cao nhất. Sau đó, dựa vào những feedback của U với k item đó để tính toán ra kết quả.
- Cuối cùng, lựa chọn những items được dự đoán user U yêu thích nhất để gợi ý cho U. Vì số lượng items thường nhỏ hơn nhiều so với số lượng users. Nên phương pháp việc tính toán độ tương đồng của iiCF sẽ nhanh hơn rất nhiều so với uuCF.
2. User – User Collaborative Filtering
2.1 Chuẩn hóa ma trận Utility Matrix
Dữ liệu duy nhất chúng ta sử dụng cho phương pháp này là ma trận Utility:
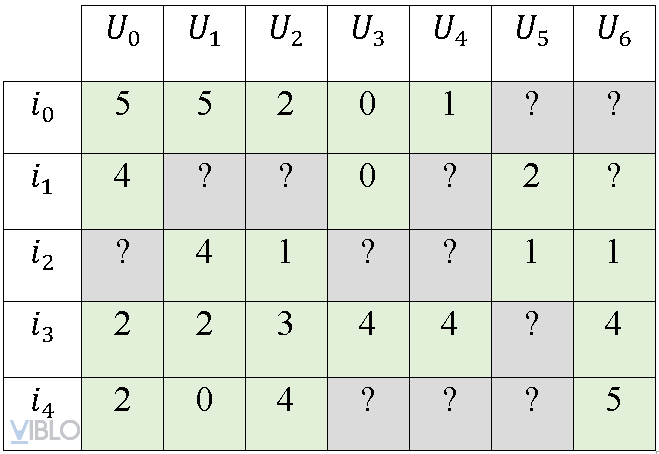
Để có thể sử dụng ma trận này vào việc tính toán, chúng ta cần thay những dấu ‘?’ bởi một giá trị. Đơn giản nhất thì chúng ta có thể thay vào đó giá trị ‘0’. Hoặc dùng một giá trị khác là ‘2.5’ – giá trị trung bình giữa 0 và 5. Tuy nhiên, những cách này không thực sự tốt vì những giá trị này sẽ hạn chế với những users dễ tính hoặc khó tính. Với những users dễ tính, thích tương ứng với 5 sao, không thích sẽ ít sao hơn, như 2 hoặc 3 sao. Khi đó, ‘2.5’ sẽ làm những đánh giá không thích sẽ trở thành negative. Ngược lại, với những user khó tính, họ thậm chí chỉ đánh 3 sao khi thích và dưới 3 khi không thích. Vì vậy, hợp lý hơn cả, chúng ta sẽ sử dụng giá trị trung bình cộng ratings của mỗi user.
Cụ thể, chúng ta sẽ xử lý như sau:
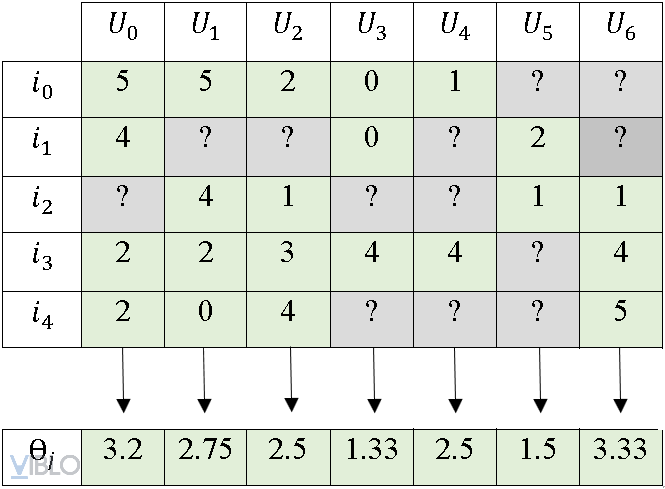
Như trong hình vẽ, chúng ta có một ví dụ về ratings trung bình của mỗi users. Tuy nhiên, thay vì trực tiếp sử dụng các giá trị này thay cho các dấu ‘?’ của mỗi user. Chúng ta sẽ trừ ratings của mỗi user cho giá trị trung bình ratings tương ứng của user đó và thay dấu ‘?’ bằng giá trị 0. Mục đích của cách xử lý này là:
- Phân loại ratings thành 2 loại: giá trị âm (user không thích item) và giá trị dương (user thích item). Các giá trị bằng 0, tương ứng với những item chưa được đánh giá.
- Số chiều của Utility matrix thường rất lớn, trong khi lượng ratings biết trước thường rất nhỏ so với kích thước của toàn bộ ma trận. Nếu thay dấu ‘?’ bằng ‘0’ thì chúng ta có thể sử dụng sparce matrix, tức ma trận chỉ lưu các giá trị khác 0 và vị trí của giá trị đó. Như vậy, việc lưu trữ sẽ tối ưu hơn.
Ma trận sau khi chuẩn hóa được gọi là Normalized Utility Matrix:
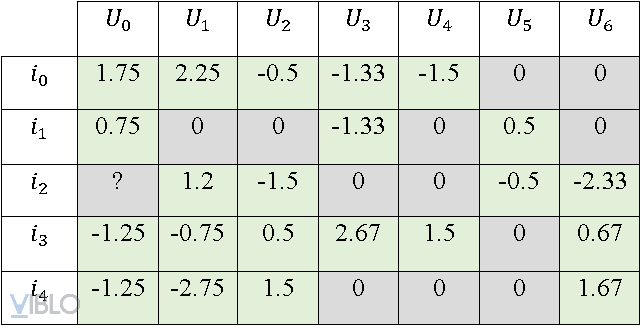
2.2. Similarity Function
Sau khi chuẩn hóa ma trận Utility, chúng ta cần tính toán độ tương đồng giữa các users.
Xét tiếp ví dụ.
Trong đó, có 7 users lần lượt là u1, u2, u3, u4, u5, u6 và 5 items lầm lượt là i1,i2, i3, i4, i5. Có thể quan sát thấy u0, u1 đều thích i0 và không thích i3, i4lắm, còn các users khác thì ngược lại.
Đặt mức độ giống nhau giữa hai user ui, uj là sim(ui, uj). Khi đó, một similarity function tốt, cần đảm bảo:
![]()
Một số similarity function thường được sử dụng là Cosine Similarity và Pearson Corelation.
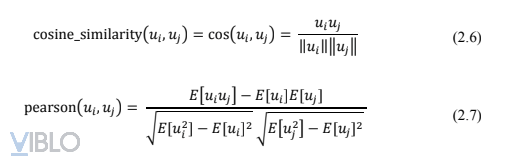
Áp dụng similarity function để tính độ tương đồng giữa các users, ta sẽ thu được ma trận Similarity Matrix.
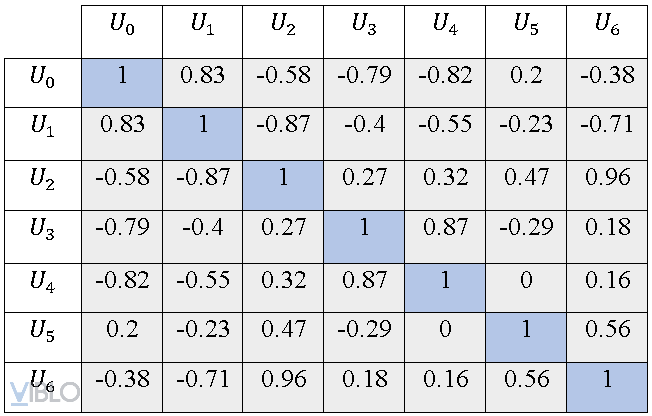
Đây là ví dụ sử dụng hàm khoảng cách cosine similarity.
2.3. Rating Prediction
Chúng ta sẽ dự đoán ratings của một user với mỗi item dựa trên k users gần nhất (neighbor users), tương tự như phương pháp K-nearest neighbors (KNN).
Công thức phổ biến thường được sử dụng để dự đoán rating của u cho i là:
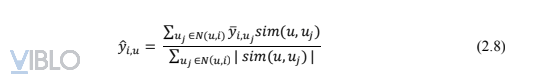
Trong đó, N(u, i) là tập k users gần nhất (có độ tương đồng cao nhất) với user u và đã từng đánh giá item i.
Ví dụ dự đoán normalized rating của user cho item với k = 2 là số users gần nhất.
o Bước 1: Xác định các users đã rated cho , đó là .
o Bước 2: Lấy simalaries của với . Kết quả lần lượt là: {} : {0.83, -0.4, -0.23}.
Với k = 2. Chọn 2 giá trị lớn nhất là 0.83 và -0.23, tương ứng với các users . Hai users này có normalized ratings với là: {} : {0.75, 0.5}
o Bước 3: Tính normalized ratings theo Công thức 2.8:
![]()
Thực hiện dự đoán cho các trường hợp missing ratings (chưa có dự đoán), ta sẽ thu được ma trận normalized ratings matrix như ví dụ:
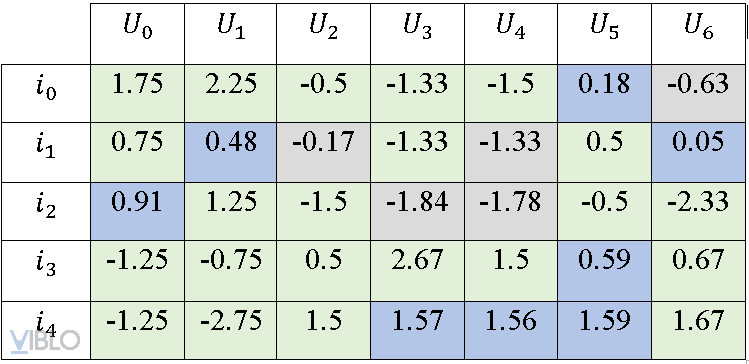
Cuối cùng, cộng lại các giá trị ratings với ratings trung bình (ở bước chuẩn hóa) theo từng cột. Chúng ta sẽ thu được ma trận hoàn thiện.
3. Item – Item Collaborative Filtering
Trong phương pháp này, thay vì tính similarity giữa các users như trong uuCF, chúng ta sẽ tính similarity giữa các items, rồi gợi ý cho users những items gần giống với item mà user đó đã thích. Lợi ích của phương pháp này là:
-
Vì số lượng items thường rất nhỏ so với số lượng users nên kích thước ma trận Similarity sẽ nhỏ hơn rất nhiều, giúp tối ưu hơn cả về mặt lưu trữ và tốc độ tính toán.
-
Thường thì mỗi item được đánh giá bởi rất nhiều users, và con số này thường lớn hơn nhiều so với số items mà mỗi user đánh giá. Vì vậy, số giá trị đã biết trong một vector biểu diễn item sẽ lớn hơn nhiều so với một vector biểu diễn user. Trong trường hợp có thêm một số dữ liệu về ratings, giá trị trung bình ratings của iiCF sẽ ít thay đổi hơn so với uuCF, vì vậy sẽ ít phải cập nhật Similarity Matrix hơn.
Về mặt tính toán, iiCF có thể thực hiện theo uuCF bằng cách chuyển vị ma trận Utility, coi như items đánh giá users. Sau khi tính được kết quả, chúng ta lại thực hiện chuyển vị một lần nữa sẽ thu được kết quả cuối cùng.
Về mặt thuật toán, ta sẽ tiến hành iiCF như sau:
Đầu tiên là chuẩn hoán ma trận Utility, thay vì tính trung bình cộng ratings của các users, chúng ta sẽ tính trung bình cộng ratings của các items.
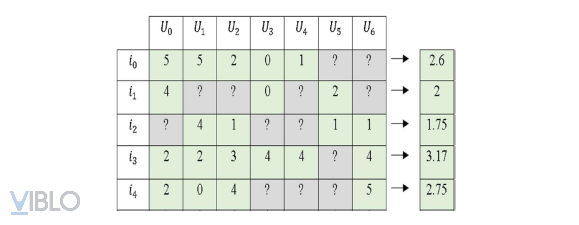
Sau đó thực hiện chuẩn hóa bằng cách trừ các ratings đã biết của item cho trung bình cộng ratings tương ứng của item đó, đồng thời thay các ratings chưa biết bằng 0. Từ đó thu được ma trận Normalized Utility Matrix.
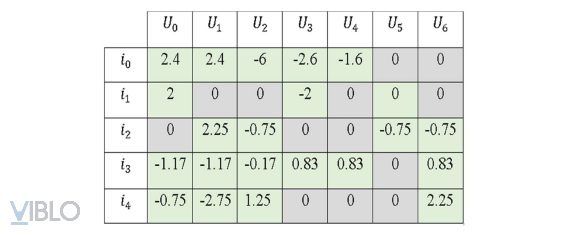
Sau đó, tính Similarity matrix bằng similarity function cho các items tương tự như uuCF:
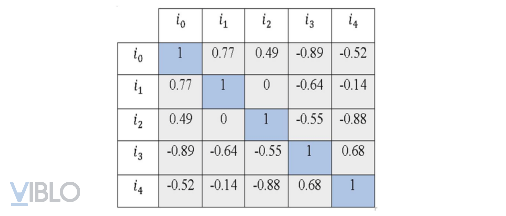
Cuối cùng, sử dụng similarity matrix và normalized utility matrix để dự đoán ra ratings của các users với mỗi items, tương tự như uuCF.
Ví dụ, dự đoán rating của user U cho item I, ta thực hiện:
- Bước 1: Tìm tập N(i, u) các items mà U đã đánh giá.
- Bước 2: Lấy similarites của I với các items trong tập N(u, i). Chọn ra k items gần nhất (có similarity cao nhất) với I.
- Bước 3: Tính rating dự đoán theo công thức
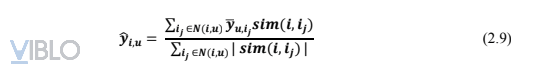
Sau khi dự đoán hết các ratings chưa biết, chúng ta sẽ thu được ma trận Utility đầy đủ:
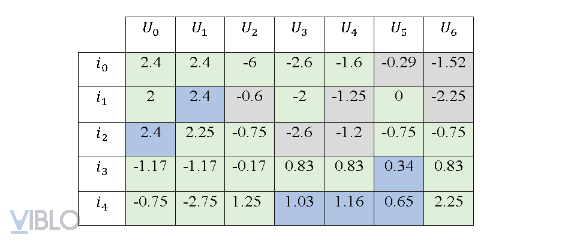
Trên đây là lý thuyết về NBCF, ở bài tiếp theo mình sẽ demo cụ thể thuật toán này. Hẹn gặp các bạn ở bài tiếp theo. Cảm ơn vì đã đọc.
Tài liệu tham khảo:
...
All rights reserved
